
セッションタイトル
Best Pracices for evaluating Amazon Bedrock Guardrails for Gen AI Workloads

はじめに
生成AI(GenAI)の導入を検討されているビジネスにおいて、本番移行にあたってのセキュリティは要考慮事項です。本日は、Amazon Bedrockと、そのネイティブなセキュリティ機能であるBedrock Guardrailsが、どのようにGenAIワークロードの安全性を確保し、安心して本番環境へ移行するための支援をするのかについての内容でした。
Amazon Bedrockとは?
Amazon Bedrockは、基盤モデル(Foundation Models: FMs)を大規模に構築・デプロイするためのフルマネージドサービスです。インフラの管理なしに、テキスト生成、画像生成、音声合成など、様々なユースケースに合わせたモデルを選択し、テストすることができます。
さらに、継続的な事前トレーニングやファインチューニングを通じてモデルをカスタマイズし、特定のユースケースに最適化することも可能です。AIエージェントやマルチエージェントのコラボレーション機能も備わっており、インテリジェントな意思決定に基づく多段階ワークフローの構築・実行を支援します。
Bedrock Guardrailsとは?
Amazon BedrockにおけるBedrock Guardrailsは、プロンプトと応答プロセスを保護するためのネイティブセキュリティコントロールです。これは、複数の設定可能なセキュリティポリシーの集合体であり、Bedrockモデル、エージェント、ワークフローに適用できます。最も注目すべきは、Bedrock Guardrail Apply Guard APIがスタンドアロンAPIとしてリリースされたことで、Bedrockでホストされていないモデルの応答プロセスを保護するためにもGuardrailsを使用できるようになった点です。
Guardrailsは、ユーザー入力と基盤モデルの出力の両方を評価するように設定できます。セキュリティポリシーに違反する要素に応じて、以下のようなアクションが実行されます。
- ユーザー入力がポリシーに違反する場合: 事前設定されたブロックメッセージを返したり、承認済みのクエリを推奨したりできます。
- 基盤モデルの出力がポリシーに違反する場合: 事前設定されたブロックメッセージを返すか、機密データ(PIIなど)の検出や特定のワードやフレーズの使用の場合には、関連する要素をリダクトまたはマスクして回答を提供できます。
違反がない場合は、応答はユーザーにそのまま提供されます。
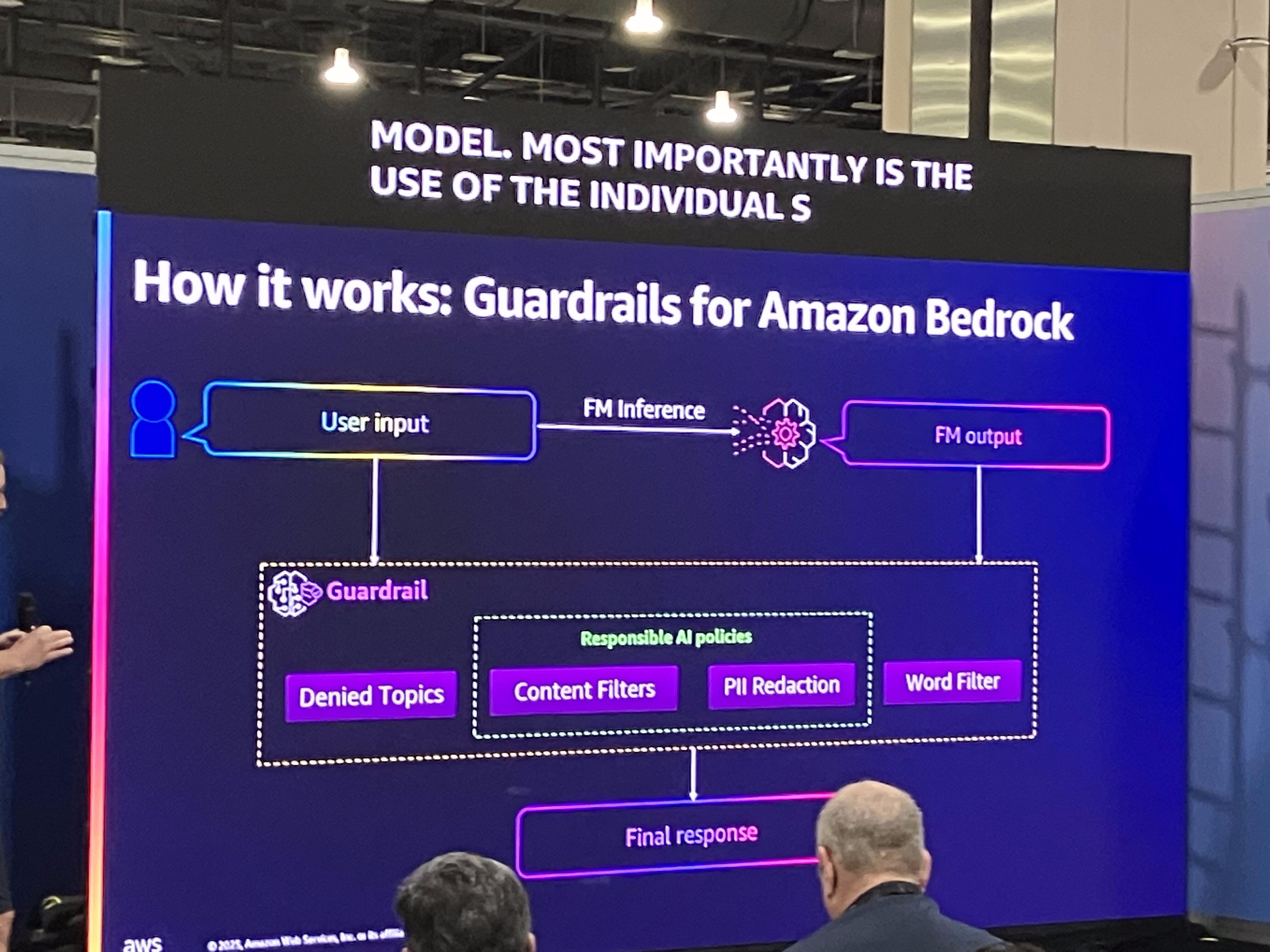
Bedrock Guardrailsのセキュリティポリシーの種類
Guardrailsは、様々な種類のセキュリティポリシーを通じて、コンテンツの安全性と適切性を確保します。
不許可トピック (Denied Topics)
ユースケースに基づいて、モデルが議論すべきでないトピックを定義します。例えば、金融チャットボットが投資アドバイスを提供すべきではない場合、関連する自然言語の例をいくつか提供することで、モデルがそのトピックを認識し、応答をブロックするように学習させることができます。
コンテンツフィルター (Content Filters)
ヘイトスピーチ、性的表現、暴力、犯罪行為、誤報などのカテゴリにわたる広範なリストの中から、個々のコンポーネントを有効にできます。感度レベルを個別に調整することで、評価の信頼度を制御し、最適な構成を見つけるためのテストとログの評価が重要です。
単語フィルター (Word Filters)
既知の不適切ワードリストに加えて、特定の競合他社の名前など、チャットボットで議論されたくないカスタムの単語リストやフレーズリストを作成できます。これらの単語が検出された場合、マスクするか、ブロックメッセージを返すことができます。
機密情報検出 (Sensitive Information Detection)
PII(個人を特定できる情報)の検出をサポートし、米国、英国、カナダの医療、銀行、金融などの業界に特化した様々な種類のPIIを認識します。さらに、独自のユースケースに特化したカスタム正規表現(regex)フィルターを設定することも可能です。
Bedrock Guardrails導入のためのベストプラクティス
Bedrock Guardrailsを効果的に活用するためには、以下のベストプラクティスが推奨されます。
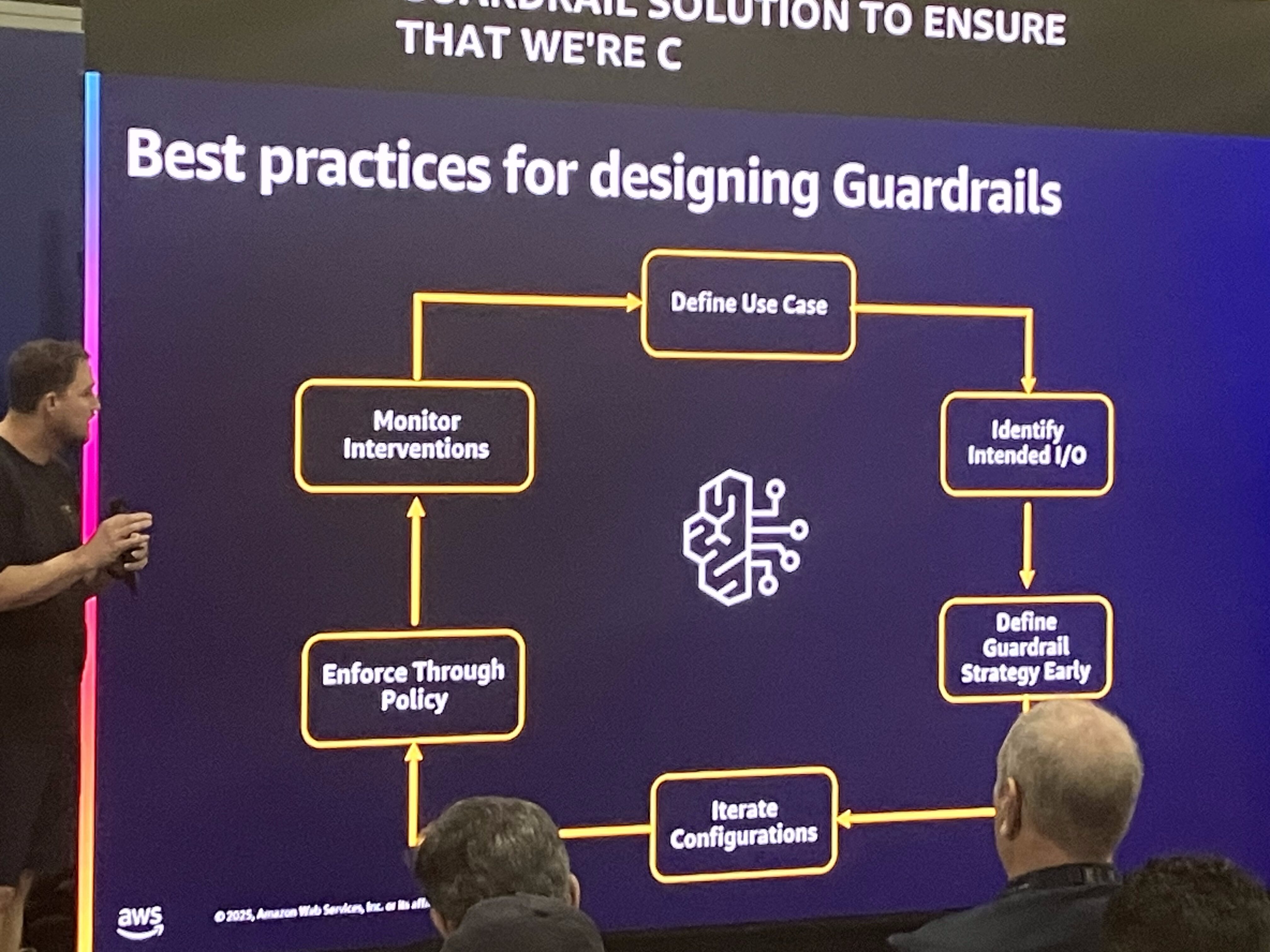
1.Define Use Case (ユースケースの定義)
まず、ユースケースを明確に定義することが重要です。例えば、ウェブサイトで顧客に公開するバンキングチャットボットを作成する場合、どのような入出力があり、それらの入力がどのように収集され、出力がどのように提供されるかを理解する必要があります。これにより、トピック、単語リスト、フレーズリストを作成し、ユースケースに必要な特定の個人情報 (PI) 検出を有効にすることができます。
2.Identity Intended I/O (意図されたI/Oの特定)
ユースケースを定義する過程で、意図される入力と出力を特定します。入力がどのように収集され、出力がどのように提供されるかを理解することは、適切なガードレールを設定するために不可欠です。
3.Define Guardrail Strategy Early (ガードレール戦略の早期定義)
ガードレール戦略の策定は、「デイゼロ活動(day zero activity)」として、ソリューションの設計段階から行うべきです。本番稼働時にガードレールを有効にするのではなく、開発ライフサイクル (SDLC) 全体を通して、ガードレールがどのように構築され、テストされ、検証されるかを理解する必要があります。これにより、ガードレールの構成がアプリケーションにどのような影響を与えるかを把握できます。
4.Iterate Configurations (構成の繰り返し)
ガードレール戦略を定義した後、ブロッカー、トピック、コンテンツフィルターなどの設定を行います。最適な設定はユースケースによって異なるため、セキュリティポリシーを設計する際には、反復的なアプローチが推奨されます。これを支援するためには、テストフレームワークが必要です。テストケースをガードレールに対して実行し、期待される結果が得られていることを検証します。期待とは異なる結果が出た場合は、不許可トピックの感度、コンテンツフィルターの感度、または冒涜語などの設定を調整します。
5.Enforce Through Policy (ポリシーによる強制)
ガードレールがテストされ、ユースケースに適していると判断されたら、ポリシーを通じてその使用を強制します。AWS Identity and Access Management (IAM) ポリシーの条件文を使用することで、特定のガードレールバージョンを強制的に使用できます。ガードレールをバージョン管理し、高品質でテスト済みのものがソリューションに使用されていることを確認することが重要です。
6.Monitor Interventions (介入の監視)
ガードレールが構築され、テストされ、エンタープライズ全体で強制されたら、監視段階に移ります。Bedrock Guardrailsには、サービスから提供される多くの監視メトリクスが含まれています。特に重要なのは、ガードレールの介入(Guardrail Interventions)です。ガードレールがいつ、どのように、なぜ介入したかを特定でき、これらのデータポイントを使用して結果をさらに調整できます。介入が多数発生している場合、アプリケーションのシステムを調査する機会となる可能性があります。
これらすべてを監視しながら、ユースケースを継続的に再評価し、ガードレールソリューションを継続的に評価および革新して、効果を維持することが重要です。
テストアーキテクチャの概要
継続的な提供のためには、テストは自動化する必要があります。
アーキテクチャ例をもとに解説いただきました。

テストケースの設定ファイル
S3バケットに、テストプロンプトとその期待されるターゲットを含む設定ファイル(例:3つのプロンプトと2つのターゲット)をアップロードします。
メッセージ生成
S3にアップロードされると、Lambda関数がトリガーされ、設定ファイルを読み込み、各プロンプトを各ターゲットにマッピングしたメッセージを生成します。
SQSキュー
生成された各メッセージは、Amazon SQSキューに送信されます。
Guardrail適用API呼び出し
別のLambda関数がSQSキューからメッセージをピックアップし、Guardrail適用APIを呼び出します。これにより、プロンプトがGuardrailによって評価され、評価結果が返されます。
結果の保存と可視化
評価結果は分析され、DynamoDBに保存された後、Amazon QuickSightダッシュボードで可視化されます。
テストと反復の例
例えば、金融チャットボットのためにGuardrailを設定し、コンテンツフィルター(性的暴力、ヘイトスピーチなど)、不適切ワードリスト、不許可トピック(投資に関するアドバイスの提供)、「住所」「メールアドレス」「IPアドレス」「氏名」などのPIIエンティティを構成したとします。
初期テストでは、金融チャットボットにとって想定外の「ヘルスケア関連のプロンプト」に対してGuardrailが何もアクションを取らなかったとします。これは、金融チャットボットのユースケース外であるため、修正が必要です。
そこで、Guardrailの設定を更新し、「ヘルスケア」という不許可トピック(医療記録、病気の診断などに関する情報の提供を禁止)を追加し、PII設定に「米国社会保障番号(US Social Security Number)」も追加します。
この変更後、再度テストを実行すると、「米国社会保障番号」と「ヘルスケア関連のトピック」の両方が検出され、Guardrailが介入したことが確認できます。このように、プロンプトは単一のルールではなく、複数の指定された基準に対して包括的に評価されます。
まとめ
Amazon Bedrock Guardrailsは、生成AIワークロードにおけるセキュリティと安全性の不確実性を解消し、安心して本番環境へ移行するための強力なツールです。
適切なユースケースの定義、初期段階からの戦略的な導入、反復的な設定、IAMによる強制、そして継続的なモニタリングとテストを通じて、GenAIアプリケーションの安全な運用を実現できます。ぜひ、今日のワークフローのセキュリティを強化するために、Bedrock Guardrailsの活用を検討してみてください。