
はじめに
前回の記事では、AWS Summit Japan 2025 で得た学びをきっかけに、生成AIとRAG(検索拡張生成)の重要性に気づき、AWS上でチャットボットを構築することを決めた経緯をご紹介しました。
今回はその続編として、実際にどのような構成でRAGチャットボットを実現するかについて解説していきます。
今回構築するチャットボットの概要
本シリーズで構築するのは、顧客に最適な生命保険プランを提案するRAGチャットボットです。
想定するユースケース
- ユーザー: 35歳会社員、妻と子供2人の家族構成
- 質問: 「私に最適な保険のプランはどれですか?」
- システムの動作:
1. DynamoDBからユーザーの属性情報(年齢、家族構成、収入など)を取得
2. OpenSearchで保険プランのPDFドキュメントから関連情報を検索
3. Bedrockを使って、ユーザーの状況に合わせたパーソナライズされた回答を生成 - 回答例: 「35歳で会社員、妻とお子様2人をお持ちの方には、死亡保障3000万円のプランAをおすすめします。月額8000円で家計に無理のない範囲で、万が一の際にお子様の教育費と生活費をカバーできます。」
このチャットボットの特徴
- パーソナライゼーション – ユーザーごとの属性情報に基づいた提案
- 正確な情報提供 – PDFドキュメントに基づいた回答(ハルシネーション抑制)
- 自然な対話 – LLMによる人間らしい説明
- 情報の鮮度 – PDFを更新すれば最新のプラン情報を即座に反映
なぜ生命保険プランを題材にしたのか
- 複雑な情報 – 多数のプランがあり、個人の状況によって最適解が異なる
- パーソナライゼーションの必要性 – 年齢、家族構成、収入などによって提案内容が変わる
- 文書ベース – PDFなどの文書で管理されることが多く、RAGの強みを活かせる
- 汎用性 – 同じ仕組みで他の商品提案(住宅ローン、投資信託など)にも応用可能
この題材を通して、RAGの実践的な活用方法を学んでいただけます。
システムアーキテクチャ全体図
まずは、構築したRAGチャットボットの全体構成を以下に示します。
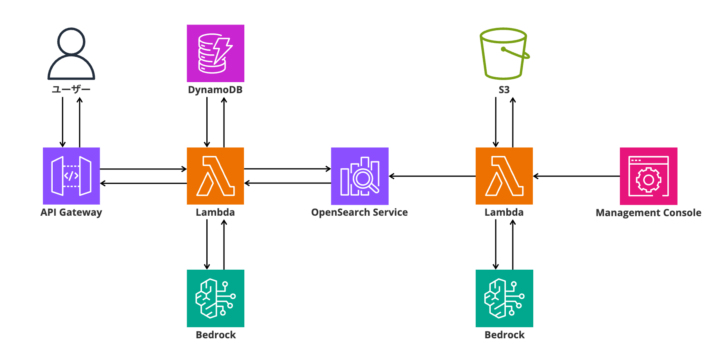
RAGシステムの処理フロー
今回構築するRAGシステムは、以下の2つの主要な処理フローで構成されます。
1. インデックス処理フロー(知識ベース構築)
[S3バケット] PDFファイルを保存
↓
[Lambda] PDFからテキストを抽出
↓
[Lambda] テキストをチャンクに分割
↓
[Bedrock: Titan Embeddings] テキストをベクトル化
↓
[OpenSearch] ベクトルとテキストを保存
↓
[完成] 検索可能な知識ベース2. RAG検索・回答生成フロー(ユーザー対応)
[ユーザー] 質問を入力
↓
[DynamoDB] ユーザー情報を取得
↓
[Bedrock: Titan Embeddings] 質問をベクトル化
↓
[OpenSearch] 類似ドキュメントを検索
↓
[Lambda] プロンプトを構築
↓
[Bedrock: Claude 3.5 Sonnet v2] 回答を生成
↓
[ユーザー] パーソナライズされた回答を受け取る各AWSサービスの選定理由と役割
Amazon Bedrock – 生成AIのハブ
役割
- テキストをベクトルに変換(Titan Embeddings)
- ユーザーの質問と文脈に基づいて自然言語で回答を生成(Claude 3.5 Sonnet v2)
選定理由
- ClaudeやTitanなど複数のLLMを統一APIで利用可能
- モデルホスティング不要で即座に利用開始できる
- 商用利用・セキュリティ面で企業向けに強い
- 従量課金でコスト効率が良い
Amazon OpenSearch Service – ベクトル検索エンジン
役割
- Bedrockで埋め込んだベクトルを元に類似文書を高速検索
- 文書チャンクごとにインデックスされており、クエリに近い内容を取得
- k近傍法(kNN)によるセマンティック検索を実現
選定理由
- ベクトル検索(kNN)をネイティブにサポート
- マネージドサービスでスケーラブル
- JSONでの操作が可能でLambdaとの親和性が高い
- 高速なレスポンスタイム(ミリ秒単位)
Amazon DynamoDB – ユーザー情報の保存
役割
- ユーザーごとの属性情報(年齢、家族構成、職業など)を保存
- プロンプトに「状況コンテキスト」として組み込むための情報源
- パーソナライズされた回答を実現するための基盤
選定理由
- サーバーレスかつ高速(ミリ秒単位のレスポンス)
- キーアクセス前提のシンプルな用途に最適
- Lambdaとの統合がスムーズ
- 低コストで運用可能(少量アクセスであればほぼ無料)
Amazon S3 – ナレッジの格納
役割
- インデックス対象となるPDFやテキストなどの非構造データの保管場所
- Lambdaから定期的に読み込み、ベクトル化・インデックス化
- 生命保険プランなどのドキュメントを一元管理
選定理由
- 非構造データの格納に最適
- サーバーレス連携が容易(Lambdaトリガー等も対応可能)
- 高い耐久性と可用性
- 低コストで大量のドキュメントを保存可能
AWS Lambda – 全ての処理の実行基盤
役割
- OpenSearchへのインデックス登録処理
- ベクトル検索・Bedrockによる応答生成処理
- PDF抽出・ベクトル生成などの一連の処理をサーバーレスで実行
選定理由
- サーバーの管理が不要
- 小規模〜中規模ワークロードに最適
- IAMやAPI Gateway、S3、Bedrockとの連携がスムーズ
- イベント駆動で必要な時だけ起動(コスト効率が高い)
なぜサーバーレス構成なのか
RAGのようなチャットボット処理は「イベント駆動・軽量処理」が多く、常時稼働型である必要はありません。そのため、サーバーレス構成には以下のメリットがあります。
- コスト効率が高い(リクエストごとの課金で、アイドル時のコストがゼロ)
- スケーリングが自動(急激なアクセス増にも対応)
- インフラ管理が不要(パッチ適用、OS管理などが不要)
- コードの更新・デプロイが容易(CDK + Lambdaで効率化)
特に、PoCから本番環境への移行をスムーズに行いたい場合、サーバーレスは非常に適した選択肢です。
設計のポイント
今回の構成で特に重視したポイントは以下の3つです。
1. モジュール化された設計
インデックス処理とRAG検索処理を別々のLambda関数として分離することで、それぞれ独立して開発・テスト・デプロイが可能になっています。
2. スケーラビリティ
すべてマネージドサービスで構成することで、アクセス増加に対して自動的にスケールする仕組みを実現しています。
3. コスト最適化
サーバーレス構成により、使用した分だけの課金となり、PoCフェーズでは非常に低コストで運用できます。
まとめ
RAGの構成にはいくつかの選択肢がありますが、AWSでは主要な要素(生成AI・ベクトル検索・ストレージ・ステート管理)をすべてマネージドでカバーできます。
特に以下の組み合わせは、小規模なPoCから本番運用までシームレスにスケールできる柔軟な設計です。
- Amazon Bedrock – LLMとEmbeddings
- Amazon OpenSearch Service – ベクトル検索
- Amazon DynamoDB – ユーザー情報管理
- Amazon S3 – ドキュメント保存
- AWS Lambda – 処理実行基盤
次回の記事では、実際にS3に保存されたPDFを処理し、ベクトル化してOpenSearchに登録する方法について、具体的なコードとともに解説します。

