2025年8月5日(火)に東京ビッグサイトで開催された「Google Cloud Next Tokyo 2025」に現地参加してきましたので、会場の雰囲気やセッションの紹介をしたいと思います。
会場の様子
今年のNext Tokyoの会場は、東京ビッグサイト南展示棟。1F、2Fが吹き抜けになっているので、会場を一望でき、すでに多くの人で賑わっていて、会場の雰囲気に圧倒されました。

アイレットブース
今年のブースはジャングルがテーマになっていて、古代遺跡のような雰囲気が一際目立っていました!
今回のNext Tokyoのために、生成 AI エージェントを活用した「探検隊エージェントデモ」をDX開発事業部で用意しました!

セッション概要
アイレット株式会社 DX開発事業部 事業部長の石川と、同事業部 フルスタックセクションリーダーの牧田による「眠れるマルチモーダルデータを起こす!バンダイナムコエンターテインメント様が実現した生成AIによるデータ活用術」のセッションをご紹介します。
眠れるマルチモーダルデータを起こす!バンダイナムコエンターテインメント様が実現した生成AIによるデータ活用術
社内に眠るマルチモーダルデータ、本当に活用できていますか?テキスト、動画、音声など、様々な形式の組み合わせデータが持つ価値を見出せていない方も多いのではないでしょうか。本セッションでは、株式会社バンダイナムコエンターテインメント様の画期的な事例を紹介します。生成AIを活用することで、膨大なマルチモーダルの中から必要情報を驚くほど短時間で探し出せるようになった、その検索性を劇的に高めた術的アプローチを詳しく解説いたします。
取り上げる主な Google Cloud 製品 / サービス
・Gemini
・Vertex AI

プロジェクトの背景
本セッションでは、バンダイナムコエンターテインメント様における生成AIの開発事例を紹介しました。
バンダイナムコエンターテインメント様には、膨大な動画コンテンツが蓄積されていますが、データ資産の活用には深刻な課題がありました。膨大な動画データから必要なシーンを探す必要があり、その検索業務がプロデューサーの経験と知識に依存し、知識が属人化してしまっていたという切実な課題を抱えていたようです。

課題へのアプローチ
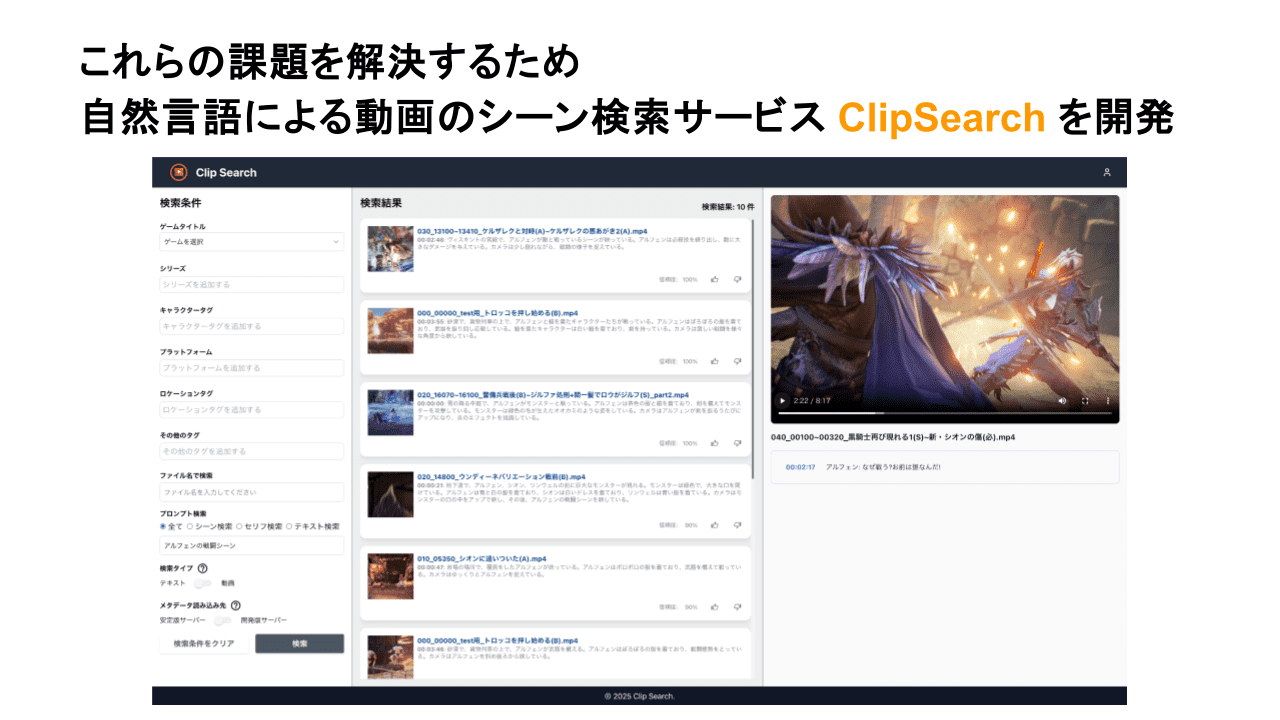
特定シーンの検索や知識の属人化といった課題を解決するために、自然言語で動画のシーンが検索できる「ClipSearch」と呼ばれるアプリケーションを開発し、アイレットはUI開発からサーバーサイド開発、構築までを担当しています。
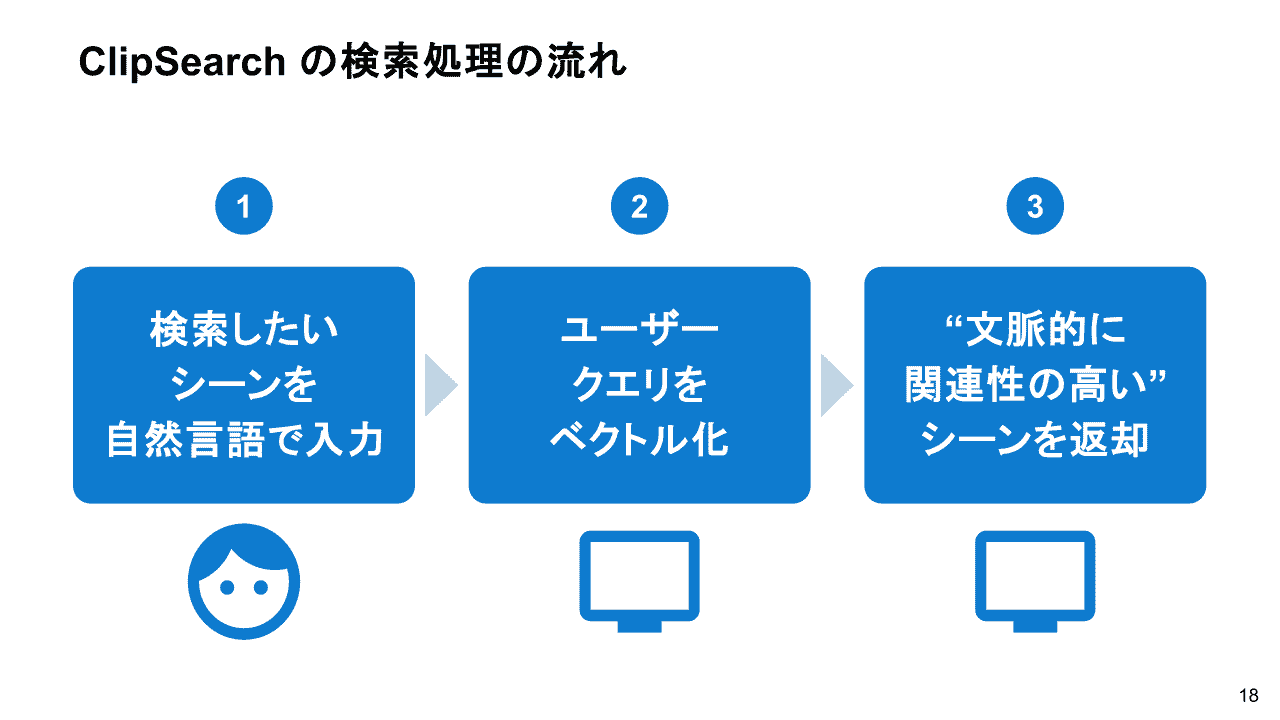
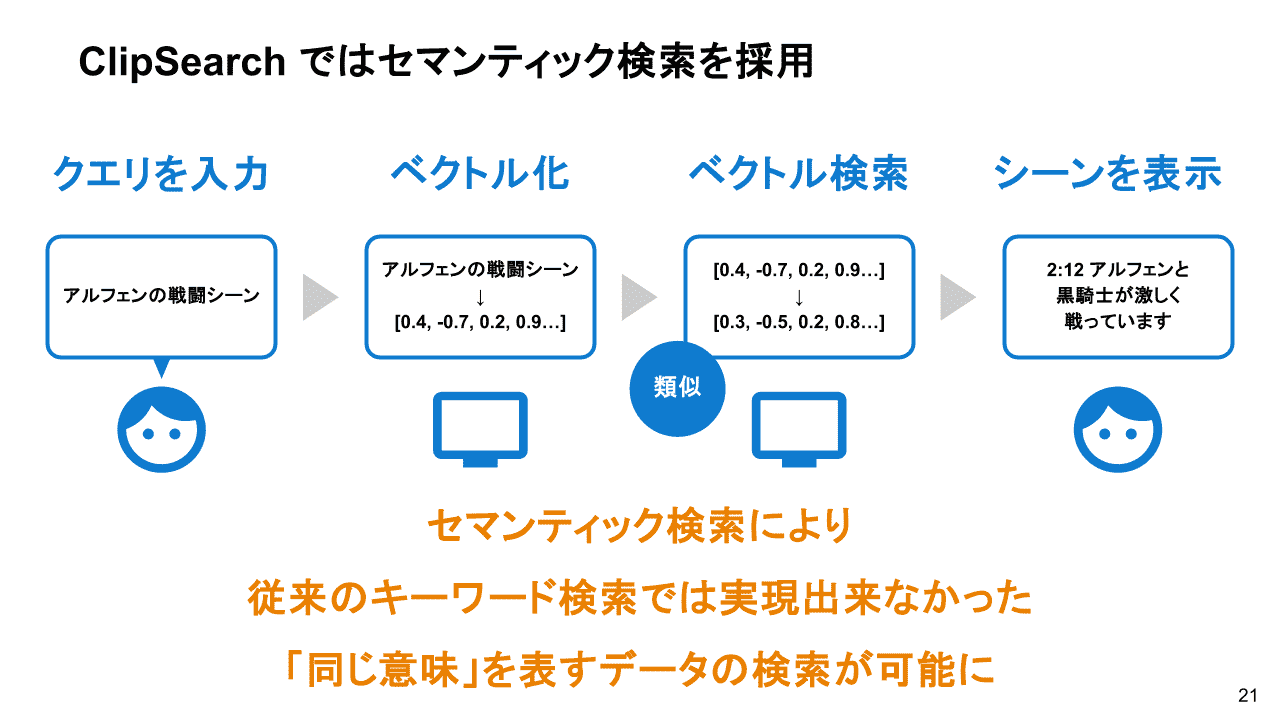
セマンティック検索を採用
セマンティック検索により従来のキーワード検索では実現できなかった、データの検索が可能となりました。
セマンティック検索は、検索クエリの意味や意図を理解し、キーワードとして完全に一致しなくとも、文脈的に関連性の高い結果を返す検索手法のことです。
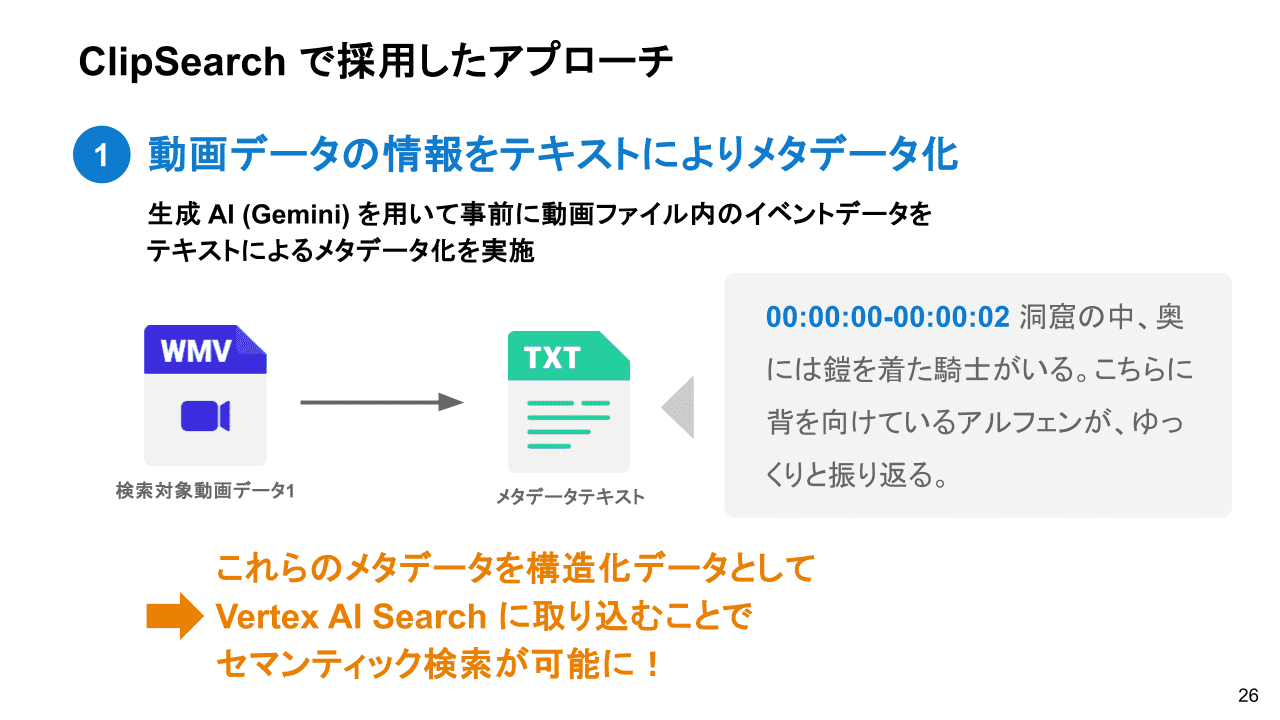
ClipSearch で採用したアプローチ
動画データ内の情報をGeminiを利用してテキスト形式のメタデータへ変換し、Vertex AI Searchへ取り込むという手法を採用しました。
開発時に発生した問題
開発を進めるにあたって、複数の問題が発生しました。
開発時に発生した問題①
メタデータ作成時にGeminiが動画内のキャラクターの特定を誤ってしまい、誤ったメタデータが作成されることがありました。

解決方法
メタデータ作成時にキャラクターごとの画像や音声などの補足情報をGeminiに与えました。

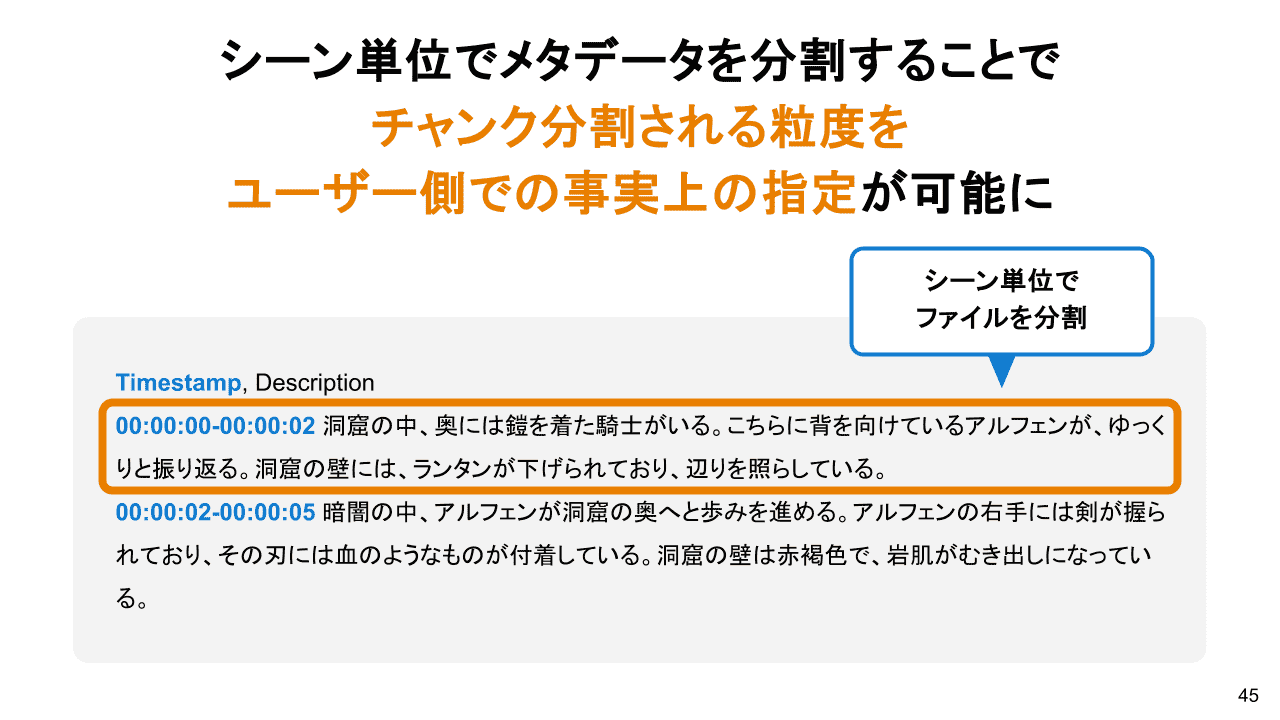
開発時に発生した問題②
ベクトル化する際のアルゴリズムがブラックボックスとなっているため、精度が出ない場合の問題の切り分けが困難でした。

解決方法
シーン単位でメタデータのテキストファイルを分割することで検索時の精度が向上しました。
眠っているマルチモーダルデータ活用のコツ
“コツ”として、以下をご紹介しました。



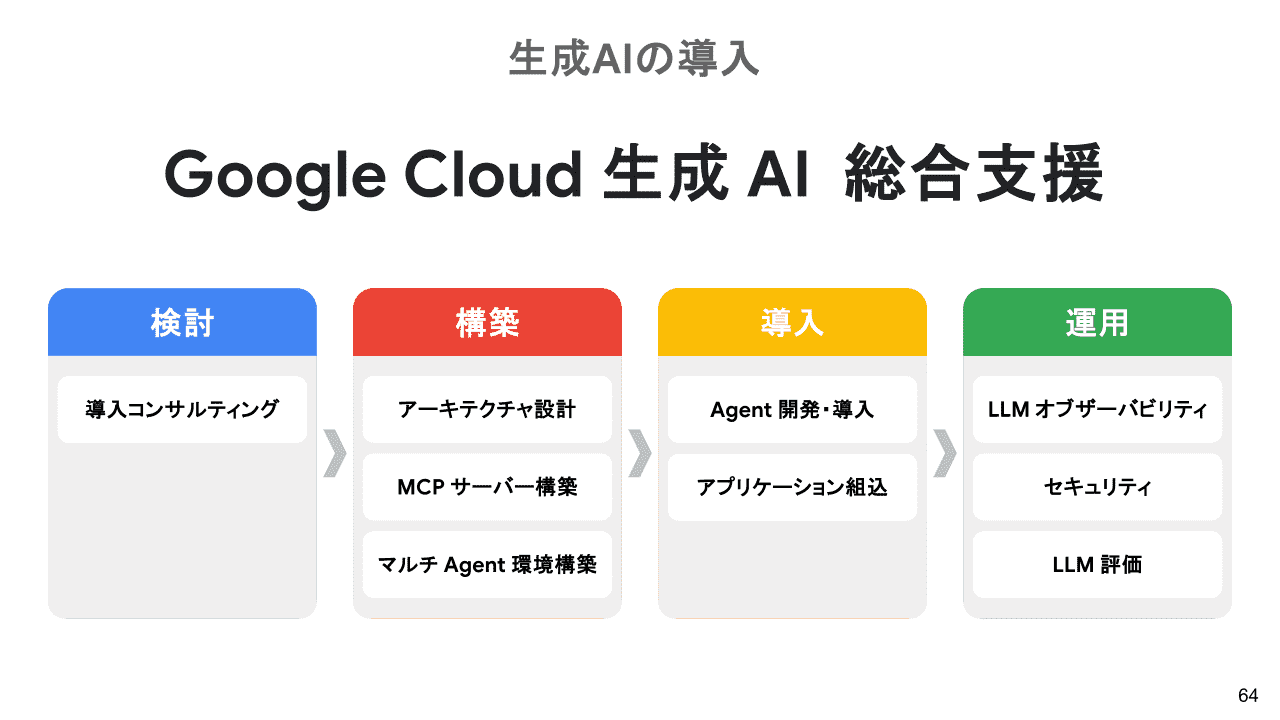
アイレットの Google Cloud 生成 AI 総合支援
生成AIを実ビジネスに導入し、運用するためには、単にAIモデルを使うだけでなく、そのユーザーインターフェースから、バックエンド、そして安定稼働を支えるインフラ、精度向上、オブザーバビリティなど多岐にわたる専門知識と総合的な力が不可欠です。アイレットは、まさにその生成AI導入における全てのフェーズを一貫して支援する、真のワンストップソリューションを実現しています。DX推進や生成AIの導入・活用にお困りの方は、ぜひお気軽にご相談ください。
Google Cloud 生成 AI 導入支援サービス
Google Cloud かんたん AI パック
EC サイト向け AI 検索ソリューション
Google Agentspace 導入支援サービス