
はじめに
この記事は、Google Cloud Next Tokyo 2025のセッション聴講記事です。
内容は、既に生成AIを運用中の方、これから導入予定の方が直面する「モデル更新による精度劣化リスク」を、Google CloudのLLMOps機能で解決する具体的な方法をご紹介します。
セッション情報
- イベント:Google Cloud Next Tokyo 2025
- セッション名:最新の生成 AI モデルへのアップデートに必要な LLMOps
- 発表者:Google Cloud 牧 允皓 氏
この記事を読むと得られること
- 生成AIモデル更新時の精度劣化リスクとその解決策
- Google CloudのLLMOps機能を活用した具体的な実装方法
対象読者 生成AI活用システムの運用者・開発予定者(既に運用中の方、これから導入予定の方)
現状と問題
最近、ほんと、生成AIモデルの進化のスピードって早すぎますよね。生成AIアプリを運用していると、こんなこと、よくありませんか?
おお!新モデルのGemini 2.5 Proがリリースされてるじゃないか!「性能向上」の文字に、きゃっきゃっウフフと心躍らせ、早速試してみたら…これまで安定していたチャットボットの回答が微妙に変わってしまいました。
社内で愛用していたチャットボットも、要約機能も、なぜか妙に冗長な結果を出すようになってしまいました。ええ、なんで…。
よくある悩み
- 「また新しいモデルが出た…でも本番で使うのはまだ怖いなあ」
- 「前のモデルで完璧だったプロンプトが、新モデルでは全然効きません」
- 「毎回手動でテストするのは現実的じゃないし、見落としがありそうです」
- 「月次でリリースされる新モデルへの対応だけで疲弊しています」
原因分析
ではなぜ、
これらの悩みが発生してしまうのか?
この問題が起きる原因は主に3つあります。
1. AIモデルの更新スピードが加速
新モデルは月次・週次でリリース続けています。従来のMLモデルとは比較にならない更新頻度により、追随が困難になっています。 さらに、古いモデルのサポート終了も早く、短期間で新モデルへの移行を迫られることも少なくありません。
2. 自然言語処理特有の複雑性
プロンプトエンジニアリングの微妙なバランスや、従来MLモデル以上に予測困難な挙動により、モデル変更の影響が読みにくくなっています。
3. ビジネス側の継続的な進化
新機能追加、サービス仕様変更、リアルタイムで変化するユーザーニーズにより、要求される性能も日々変化しています。
このうち、本セッションで、一番焦点を当てている問題は、
「1. AIモデルの更新スピードが加速」の原因による
「生成AIモデル更新時に、既存アプリの精度が劣化してしまうリスク」です。
解決策:LLM Opsとは
このような課題に対処するための手法として、LLMOpsがあります。
おっと、ここで、
「ん?LLMOps?それってAI研究者が使うものですよね、ファインチューニングとかしないし、私に関係ないのでは?」
と心の中で呟いたのではないでしょうか?
ところがどっこいしょ、そんなことはありません!
私たち、生成AIの利用者にも関係大アリです。
まず、勘違いしがちなポイントとして、LLMOpsには、大きく2つの領域があります。
- 学習(AIモデルの開発者向け):生成AIモデル作成や、生成AIモデルのファインチューニングに関すること
- 推論(AIモデルの利用者向け):生成AIモデルを使用したシステム、アプリを作成に関すること
このうち、今回は、「2. 推論(AIモデルの利用者向け)」に焦点を当てた話です。
生成AIアプリに関するLLMOpsは、我々の、毎日の開発・運用効率に直結するたいへんに重要な領域です。
また、今回のセッションでは、LLMOpsのベストプラクティスを4つのカテゴリに分けて紹介されました。
これは、「学習」「推論」の軸によるものではなく、LLMOpsの全体を見て、大きく4つに分けて考えていくといいよね。というものです。
もちろん、LLMOpsには「これが正解」という決まったアーキテクチャは存在しないため、
今回紹介される4つのカテゴリを参考にしながら、各社のビジネスモデルやKPIに応じて継続的に最適化していくことが重要です。
ということで、今回紹介があったLLMOpsのベストプラクティスのカテゴリは、以下の4つです。
- データマネジメント
- モデルのトレーニング
- デプロイ
- モニタリング
このうち、最初に定義した問題点
「生成AIモデル更新時に、既存アプリの精度が劣化してしまうリスク」に
対して根幹の対策となる領域が「4. モニタリング」です。
なぜモニタリングが根幹の対策となるのでしょうか?
従来の運用では「問題が起きてから気づく」(または、気づかずに問題が大炎上してから外から発覚)という受動的な(火消し的な)対応になりがちでした。
しかし、LLMOpsにて、前もってモニタリングをしておくことで、問題が発生する前に予兆を捉え、能動的に対策を打てるようになります。
これは、通常のDevOpsなどと同じ考え方ですね。
LLMOpsのベストプラクティスの各カテゴリの主な考え方は以下に続きます。
1. データマネジメント
- 高品質なデータを使用
- データを効率的に管理
- データガバナンスの確立
高品質なデータを使用
LLMを効果的にトレーニングするには、大量の高品質なデータが必要。
組織は、トレーニングに使用するデータがクリーンで正確であり、目的のユースケースに関連していることを確認する必要がある。
データを効率的に管理
LLMは、トレーニングと推論中に膨大な量のデータを生成できる。組織は、ストレージと取得を最適化するために、データレイクやデータウェアハウジングなどの効率的なデータマネジメント戦略を実装する必要がある。
データガバナンスの確立
LLMOpsのライフサイクル全体を通じてデータの安全かつ責任ある使用を確保するために、明確なデータガバナンスポリシーと手順を確立する必要がある。
2. モデルのトレーニング
- 適切なトレーニングアルゴリズムを選択
- トレーニングパラメータを最適化
- トレーニングの進行状況をモニタリングする
適切なトレーニングアルゴリズムを選択
LLMやタスクの種類によって、適切なトレーニングアルゴリズムがある。組織は、利用可能なトレーニングアルゴリズムを慎重に評価し、特定の要件に最も適したものを選択する必要がある。
トレーニングパラメータを最適化
ハイパーパラメータ調整は、LLMのパフォーマンスを最適化するために重要。学習率やバッチサイズなどさまざまなトレーニングパラメータを試して、モデルに最適な設定を見つける。
トレーニングの進行状況をモニタリングする
潜在的な問題を特定し、必要な調整を行うには、トレーニングの進行状況を定期的にモニタリングすることが不可欠。組織は、損失や精度などの主要なトレーニング指標を追跡するために、適切とダッシュボードを実装する必要がある。
3. デプロイ
- 適切なデプロイ戦略を選択
- デプロイのパフォーマンスを最適化
- セキュリティを確保
適切なデプロイ戦略を選択
LLMは、クラウドベースのサービス、オンプレミスのインフラストラクチャ、エッジデバイスなど、さまざまな方法でデプロイできる。お客様は、具体的な要件を慎重に検討し、お客様のユースケースに最も適したデプロイ戦略を選択。
デプロイのパフォーマンスを最適化
デプロイ後は、LLMをモニタリングしてパフォーマンスを最適化する必要がある。これには、リソースのスケーリング、モデルパラメータの調整、レスポンス時間を改善するためのキャッシュメカニズムの実装が含まれる場合がある。
セキュリティを確保
LLMとLLMが処理するデータを保護するために、強力なセキュリティ対策を実装する必要がある。これには、アクセス制御、データ暗号化、定期的なセキュリティ監査などがある。
4. モニタリング
- モニタリング指標を確立
- リアルタイムモニタリングの実装
- モニタリングデータの分析
モニタリング指標を確立
LLMの健全性とパフォーマンスをモニタリングするため、重要業績評価指標(KPI)を確立する必要がある。これらの指標には、精度、レイテンシ、リソース使用率などがある。
リアルタイムモニタリングの実装
運用中に発生する可能性のある問題や異常を検出して対応できるように、リアルタイムモニタリングシステムを実装する必要がある。
モニタリングデータの分析
モニタリングデータは定期的に分析して、傾向、パターン、改善の余地を特定する必要がある。この分析は、LLMOpsプロセスの最適化と、高品質のLLMの継続的なデリバリーを保証するのに役立つ。
ポイント:実際にモニタリングすべき対象は?
先ほど説明した通り、モデル更新時の精度劣化リスクに対する根幹の対策となるモニタリングです。
今回のセッションでは、以下のありがちな生成AIアプリ作成から劣化までの流れとなった場合に、
何を監視すべきだろうか?という、具体例も紹介されました。

PoCした直後のリリースはいい感じに動くのに…
時間が経つとサービス劣化、というのはあるあるですよね。
このようなサービス劣化が発生した際の監視項目例:
入力データの変化
PoCで使用したデータセットと本番でリリースした後のデータは必ずしも一致しない。新しい商品名、想定していなかった言語など、様々な要因で入力データは変化する。
モデル精度
入力データが変化するとモデルの精度も変化する可能性が高い。評価用データセットの準備、更新、再評価は重要。
サービス自体の品質
モデルの精度では説明できない要因もある。CTR、顧客満足度などのビジネスKPIで評価することも重要。
実装方法:Google Cloud Vertex AIを使おう
続きまして、最初に定義した問題点
「生成AIモデル更新時に、既存アプリの精度が劣化してしまうリスク」への具体的な対策として、
Google Cloudで実現する方法を見ていきましょう!わくわくドキドキですね。
セッションでは以下の4つの主要機能と対応するGoogle Cloudサービスについて、紹介されました。
このうち、今回の問題点である、モデルの差し替え時に一番直結する機能は、「プロンプト最適化」となります。
早速、順を追って見ていきましょう。
- プロンプト管理
- Vertex AI Studio
- プロンプト最適化
- Vertex AI Prompt Optimizer
- モデル評価
- Vertex AI Gen AI Evaluation Service
- 自動化
- Vertex AI Pipelines

プロンプト管理(Vertex AI Studio)
ご存知の通り、プロンプトは微妙な表現の違いで結果が大きく変わる大変繊細な部分ですよね。ですので、いろんなパターンを試行錯誤しながら、求める結果を出力するプロンプトを探していく必要があります。
しかし、試行錯誤を重ねると「うーん、前のプロンプトの方が良かった」「あれ、なぜこの変更をしたんだっけ?」「結局、どのパターンが一番効果的だったかな?」といった問題が出てきます。
そこで、プロンプト管理することが、重要となります。
このプロンプト管理は、Vertex AI Studioを利用することで管理の手間が大きく削減されます。
プロンプトによる混乱のストレスからも解放されます。
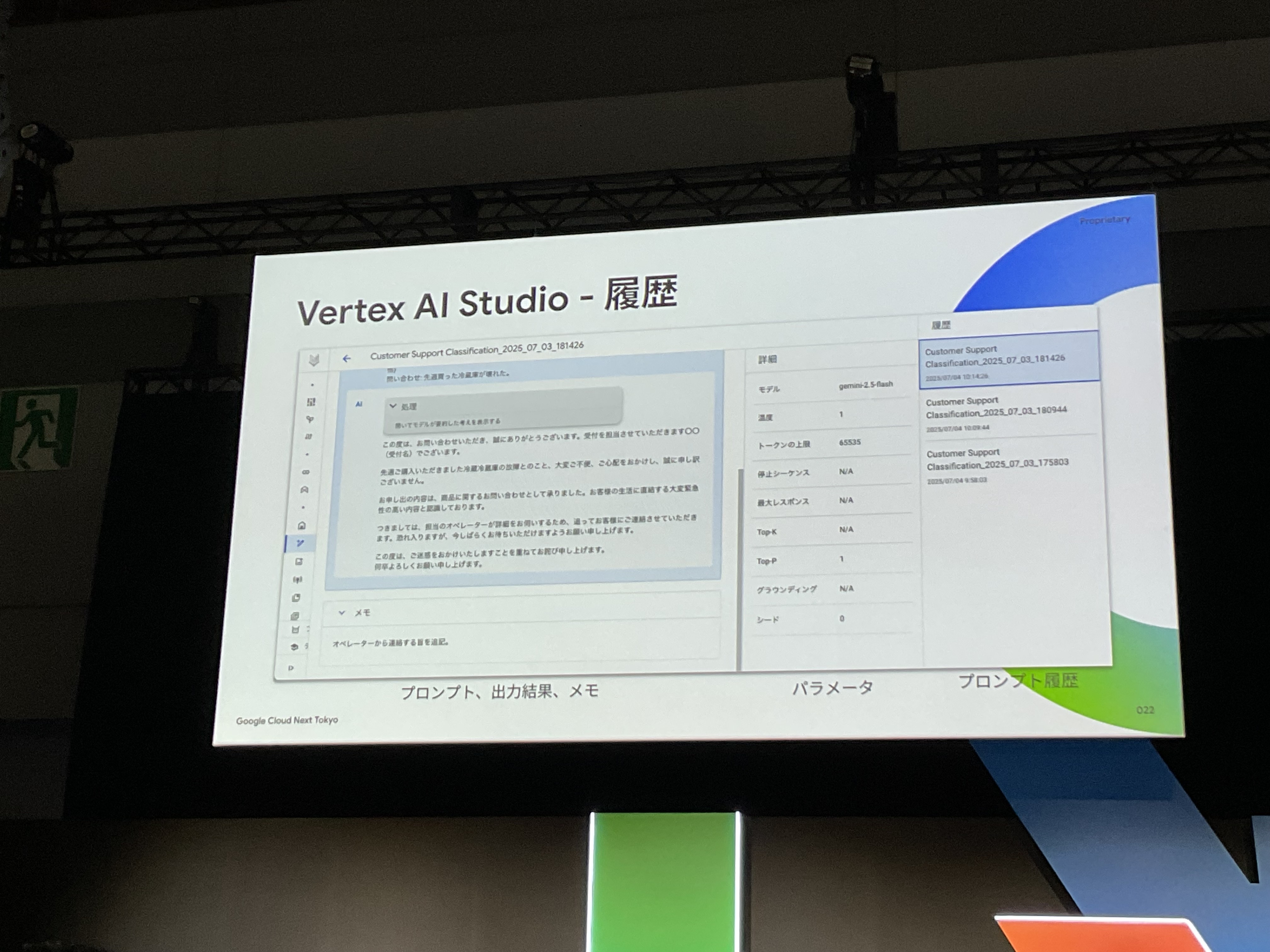
今回、挙げられていた、Vertex AI Studioの機能のポイントは以下。
- プロンプトのバージョン管理と変更履歴追跡
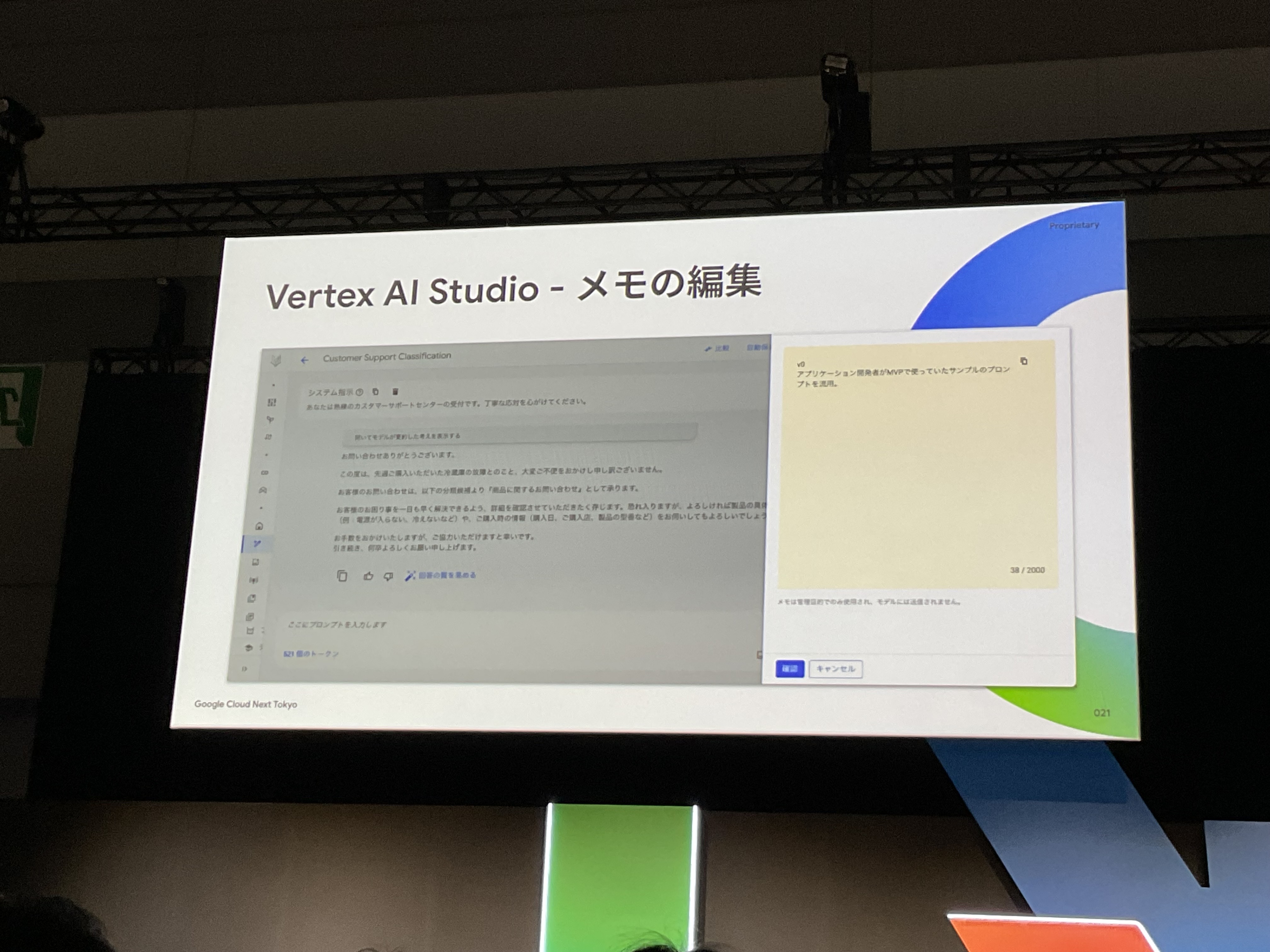
- メモ機能(なぜこのように変更したのかを記録)
- プロンプトの横並び比較機能
特に、各バージョンに対する「メモ機能」が重要であると、語られていました。
そうですよね、なぜ、前バージョンから今バージョンへ変更したのか?それが、次にプロンプトを変更する際にも、プロンプトの変更を理解する際にも、とても重要なメモ、となりますよね。
また、プロンプトの横並び比較機能は、それぞれのプロンプトを横並びで表示するのみのシンプルな機能ですが、
実際に変更していく際に、比較しながら進められますし、なにより、あちこち他のツールを使いまわらず、Vertex AI Studio内で完結することが大きな魅力ですね。
プロンプト最適化(Vertex AI Prompt Optimizer)
このセクションの最初にお伝えした通り、
プロンプト最適化は、今回の一番問題の大きい要因である、モデルの差し替えに一番直結する機能です。
新しいモデルがリリースされたとき、
「前のモデルで完璧だったプロンプトが新モデルでは全然効かない」という問題が発生します。従来であれば、手動で一から何パターンものプロンプトを試して、一つ一つ結果を確認する必要がありました。毎度毎度の手作業地獄ですね。
しかし、Vertex AI Prompt Optimizerを使えば、この作業を自動化できます。
プロンプト最適化の大まかな流れは、
まず、旧モデル用のプロンプトテンプレートと参照データ(サンプルプロンプト)を使用しプロンプト最適化ジョブを実行する。
そうすると、新モデル向けにプロンプトを自動調整を繰り返し、そのうち最も性能の良いものを選び出してくれます。
この参照データ(サンプルプロンプト)は、良い結果のためには、50~100件あることが望ましいですが、最小データ数は、5件から実行可能です。
参照データはラベル付きデータのため、たくさんのデータを作成するのには、大変骨が折れますが…
少ないデータから少しずつでも試せて、低ハードルというのも魅力の一つですね。
また、プロンプトを評価するための指標は、
事前定義されている指標である、要約品質、移管性、流暢さ、安全性、関数呼び出しとの連携、など様々な指標を使用できます。
加えて、ユーザ自身でカスタムした評価指標を使用することもできます。
これにより、さまざまなタスクや、会社独自の指標などにも対応することが可能ですね。



モデル評価(Vertex AI Gen AI Evaluation Service)
まず大前提として、Vertex AI Gen AI Evaluation Serviceのユースケースには、
モデル選択のためのモデル単体の評価や、RAGの最適化など、モデル評価のための幅広いタスクに使用できます。
そして、もちろん、今回の一番問題の大きい要因である、モデルの差し替えのために、プロンプトを最適化を行った。
その後のプロンプトの評価にも使用することができます。
従来は「なんとなく良さそう」という主観的な判断に頼りがちでしたが、Vertex AI Gen AI Evaluation Serviceを使えば数値で比較できます。
評価指標は、モデルベース指標と計算ベース指標の2種類があります。
モデルベース指標は判定モデルを使用する、いわゆる、LLM as a Judgeをしているため、ラベル付きデータがなくとも評価することは可能ですが、当然、評価結果は実行のたびに結果が変わる可能性あります。また、内部でLLMを動かしている分コストが高くなってしまうようですね。
逆に、計算ベースの評価は、文字通り計算ベースのため、ラベル付きデータは必須ですが、決定論であるため、出力結果が一貫しているというメリットもあります。また、コストも低く高速に実施することが可能です。
評価指標は、用途や予算に応じて使い分けることで、効率的にモデルの性能を評価できますね。
| 評価のアプローチ | データ | 費用と処理速度 | |
|---|---|---|---|
| モデルベースの評価 | 判定モデルを使用し、記述的な評価基準に基づいてパフォーマンスを評価 | グラウンドトゥルースはなくてもかまわない | 費用がやや高く低速 |
| 計算ベースの評価 | 数式を使用してパフォーマンスを評価 | 通常、グラウンドトゥルースが必要 | 費用が低く高速 |
ポイント!
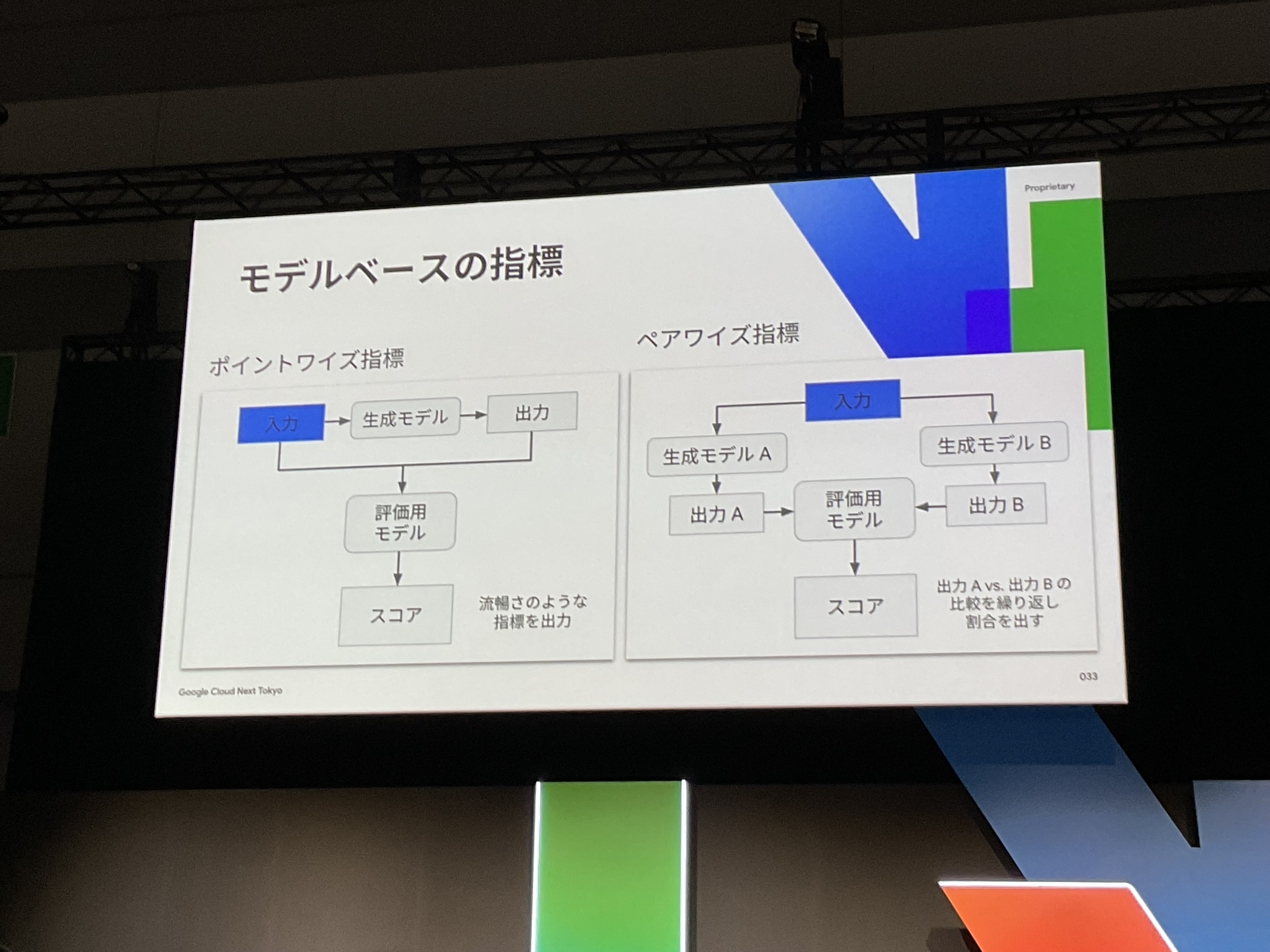
「モデルベース指標」は、ポイントワイズ指標・ペアワイズ指標に対応しており、この使い分けが重要です。
ポイントワイズ指標:
1つの生成モデルの出力を評価用モデルで採点します。「入力→生成モデル→出力→評価用モデル→スコア」の流れで、流暢さのような指標を数値化します。
ペアワイズ指標:
2つの生成モデル(AとB)の出力を評価用モデルで比較し、どちらが良いかの勝敗を判定します。同じ入力に対する「出力A vs 出力B」の比較を行い、評価用モデルが優劣を決めます。
実際に使用する際には、
「このモデルの流暢さは?指示追従能力は?使えるレベルだろうか?」といった絶対的な品質評価にはポイントワイズ指標、
「2つのモデル候補のうちどちらが良いか?」といった相対的な優劣判定にはペアワイズ指標を使用するとよさそうですね!

自動化(Vertex AI Pipelines)
これまでの3つのステップ(プロンプト管理、最適化、評価)を手動で毎回やるのは、正直かなり大変ですよね。
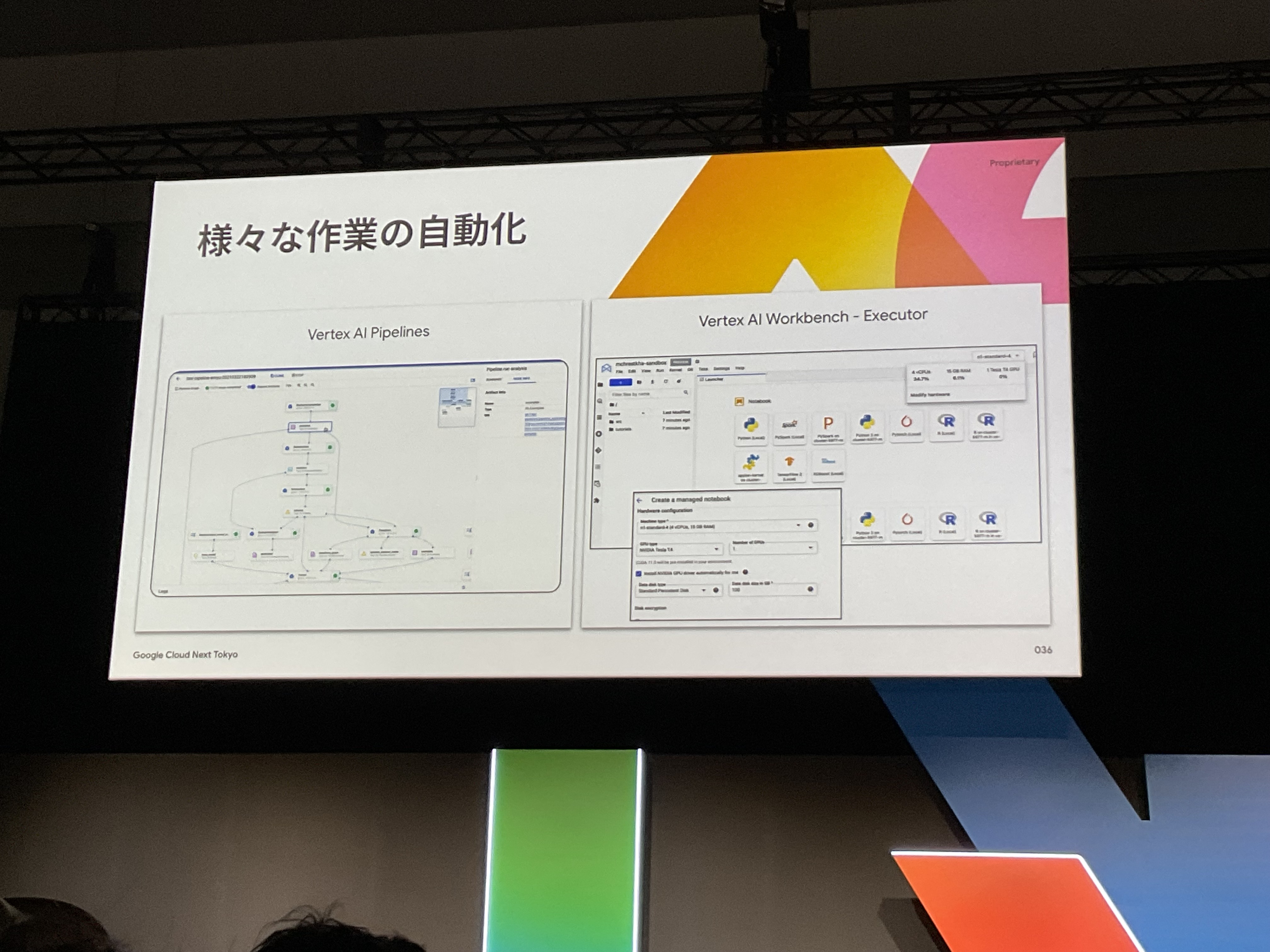
そこで、Vertex AI Pipelinesを使ってこれらの作業を自動化できます。
新しいモデルがリリースされた際に、手動でテストを繰り返すのではなく、パイプライン化することで一貫性のある運用を実現します。
また、Vertex AI Workbench Executorは、単体で、ノートブックに記述した機能の定期実行、自動化などできますし、
Vertex AI Pipelinesと組み合わせることで、パイプラインに組み込むことができ、より柔軟な運用が可能になります。
まとめ
生成AIモデルの急速な進化により、「新モデルが出るたびに既存アプリの精度が劣化する」という課題が多くの開発・運用現場で発生しています。本セッションで紹介されたGoogle CloudのLLMOps機能を活用することで、この課題を効率的に解決できることがわかりました。
重要なポイントの振り返り
課題の核心: 月次・週次でリリースされる新モデルへの対応で疲弊し、手動テストでは限界がある
解決のカギ: LLMOpsの「モニタリング」により問題発生前に予兆を捉え、能動的な対策を実現
具体的な実装手順:
- Vertex AI Studio でプロンプトのバージョン管理とメモ機能を活用
- Vertex AI Prompt Optimizer で新モデル向けプロンプトの自動最適化
- Vertex AI Gen AI Evaluation Service で数値による客観的な評価
- Vertex AI Pipelines で一連の作業を自動化
さいごにひとこと
セッションを聞いていて一番印象的だったのは、「Vertex AI Prompt Optimizerは最小5件のデータから実行可能」という部分でした。
正直、こういう最適化ツールって、もっと大量のデータが必要だと思い込んでいたので、これは嬉しい誤算でした。ハッピー誤算というやつ。
「まずは小さく始める」ことができるので、
まさに今日から、いいえ、今すぐ!実践できそうで、現在使っているプロンプトでさっそく試してみたくなりました。
そして徐々に必要なところから、実験的に実装できるのもいいですね。
そのあとでパイプライン化を進めますし、そうなれば、新モデルリリースに怯えることなく、安心して最新技術にわくわくするだけですね。夜もゆっくり寝れそうです。
よし、Google CloudとLLMOpsで、より良い質、効率的な、サービス提供を実現して参りましょう!



