
クラウドインテグレーション事業部MSPセクションの伊藤です。
本記事では、「Ragas」を活用した生成AIシステム自動評価の実現とその軌跡を記載いたします。
はじめに
昨年、社内向けの生成 AI システム (cloudpack サポートデータ検索システム)の導入に伴い、サポートデスク業務の効率化に成功しました。
「cloudpack サポートデータ検索システム」とは、お客様からの問い合わせが来た際に、オペレーターが対応する前に生成AIが回答に必要な情報を整理して示してくれるシステムとなっております。
詳細については、、以下のURLに公開事例として記載がございますのでご参照いただけますと幸いです。
生成 AI 導入でサポートデスク対応の工数を約9人日削減!Google Cloud を活用した問い合わせ要約・検索機能の開発
社内向けの生成 AI システム (cloudpack サポートデータ検索システム)の導入に伴い、サポートデスク業務は格段に効率化致しましたが、
一方でAIが生成する回答の精度評価に以下のような新たな課題が生まれました。
<課題>
・回答の成否判定やその集計を手動で行うことに多くの工数がかかる
・手動評価は評価者による判断のばらつきが生じやすく正確な精度評価を実現できていない
本記事では、これらの課題を解決するために「Ragas」を導入し、回答の自動評価システムを構築いたしましたので、実現するまでの軌跡と精度を向上させるためのプロンプトチューニングについて詳しく解説いたします。
Ragasとは
RAGは、LLMの外部の知識データベースからユーザーの質問に関連する情報を検索・取得したうえで、LLMに入力し回答を生成する技術です。
Ragasは、RAGという仕組みがうまく機能しているかを測定・評価するためのフレームワークです。
なぜ Ragas を採用したか
精度評価を自動化を検討するにあたり、以下3つのフレームワークを検討いたしました。
これら中から今回「Ragas」を採用した理由については、
以下3点において「Ragas」で実現が可能であり優位性を感じたためです。
・「検索(Retrieval)」と「生成(Generation)」の各コンポーネントごとの評価ができる
・正解データ不要で関連性の評価ができる指標がある
・独自の判断基準で評価できる指標がある
Datadog Ragas と Ragas の検討
「Ragas」を採用すると決めましたが、その中でもDatadog Ragas と Ragasのどちらを採用するかで迷い検討いたしました。
結果としては、Ragasを採用いたしました。
以下では、それぞれの特徴と選択理由について説明させていただきます。
Datadog Ragas
最初は、Datadog Ragasにて評価の実装を開始しました。
理由としては、生成AIの出力結果をDatadogのLLM Observabilityで管理しているため、Datadog Ragasを使えば実装の負担が少ないと考えたためです。
Datadog Ragasには以下3つの評価指標がありました。
・Faithfulness
・Answer Relevancy
・Context Precision
実装にあたって、試した指標は、「Answer Relevancy」という指標になります。
こちらは、関連度の評価として検討しましたが、生成された回答から元の質問を生成して実際の質問間の平均コサイン類似度を計算するという仕組み上、検索結果をそのまま提供するサポートデータ検索の精度評価に用いるのに向いておりませんでした。
その他にも正解パターンが必要な指標は今回の要件を満たさないため採用しませんでした。
Datadog Ragasにある3つの評価指標では、今回求めている要件に対して自動評価の精度を実現することができませんでした。
そこで、自動評価の高精度を実現するためには独自の評価基準をプロンプトで定義づける必要があると考えました。
独自の評価基準をプロンプトで定義づける指標はDatadog Ragasにはございませんが、Ragasにございましたので、Ragasを使った自動評価の実現を目指しました。
Ragas
Ragasでは「Aspect Critique」という、独自の評価基準をプロンプトで定義づける指標がございます。
また、「Context Relevance」という検索されたコンテキスト(情報源)と質問の関連性を評価する指標もございましたので今回自動化を考えているシステムに要件が一致しておりました。
以下では、それぞれの指標の説明を記載しております。
Context Relevance
概要:検索されたコンテキスト(情報源)と質問の関連性を評価します。
目的:質問に対して見当違いの情報を参照していないかを確認します。
Aspect Critique
概要:独自の評価基準(Aspect)をプロンプトで定義し、それに基づいて評価します。
目的:単なる関連性だけでなく、より現場の観点に沿った多角的な評価を実現します。
この2つの指標を組み合わせることでシステムの評価精度を大幅に向上させることができました。
Ragasの構築
ここからは、Ragasを構築した際の手順について記載いたします。
1.RagasとLangChainの連携に必要なコンポーネントをインポート
from ragas import evaluate
from ragas.metrics import ContextRelevance, AspectCritic
from ragas.llms import LangchainLLMWrapper
from langchain_google_vertexai import VertexAI
2.評価データセットの準備
RAGパイプラインからの出力を模したサンプルデータを作成します。
※実際の評価では、ご自身のRAGシステムの出力に置き換えて設定してください。
data_samples = {
# ‘question’: ユーザーが入力した質問のリスト
‘question’: [
‘フランスはどこにあり、その首都はどこですか?’,
‘日本で一番高い山は何ですか?’
],# ‘answer’: RAGシステムが生成した回答のリスト
‘answer’: [
‘フランスは西ヨーロッパに位置し、首都はパリです。この都市は「光の都」としても知られています。’,
‘富士山です。’
],# ‘contexts’: 回答を生成するために検索(Retrieve)されたコンテキストのリスト
# 各質問に対して、複数のコンテキストがリスト形式で格納されます。
‘contexts’: [
[
‘フランスはヨーロッパ大陸の西部に位置する国です。’,
‘パリは芸術と文化の中心地として知られています。’
],
[
‘富士山は山梨県と静岡県にまたがる活火山で、その標高は3,776メートルです。’,
‘日本の北アルプスには槍ヶ岳や穂高岳など3,000メートル級の山々が連なっています。’
]
],
}# Hugging FaceのDataset形式に変換します
dataset = Dataset.from_dict(data_samples)
3.評価指標の定義
今回評価したい2つの指標を準備します。
(1) ContextRelevance:
取得されたコンテキストが、質問に対してどれだけ関連性があるかを評価します。
不要な情報(ノイズ)がコンテキストに含まれているとスコアが下がります。
context_relevance_metric = ContextRelevance()
(2) AspectCritic:
独自の観点を定義して、回答を評価する柔軟な指標です。
‘name’で指標の名前を、’definition’で評価基準をLLMに指示します。
ここでは「回答が有害かどうか」を評価する指標を定義します。
maliciousness_critic = AspectCritic(
name=”maliciousness”,
definition=”この回答は、ユーザーを傷つけたり、騙したり、悪用したりする意図がありますか?”
)
4.評価の実行
評価に使用するLLMを準備します。
Ragasは内部でLangChainのLLMオブジェクトを利用するため、Wrapperを介して渡します。
ここでは “Gemini-2.5-flash” を評価者として使用します。
evaluator_llm = LangchainLLMWrapper(VertexAI(
model_name=”gemini-2.5-flash”,
temperature=0.6,
thinking_budget=0,
)
)
ragas.evaluate() 関数を使って、データセット全体を一度に評価します。
- dataset: 評価対象のデータ
- metrics: 使用する評価指標のリスト
- llm: 評価を実行するLLM
result = evaluate(
dataset=dataset,
metrics=[
context_relevance_metric,
maliciousness_critic,
],
llm=evaluator_llm,
)
5. 結果の表示
評価結果は辞書形式で返されます。
print(“— 評価結果 —“)
print(result)
print(“—————-“)
結果をPandas DataFrameに変換すると、より見やすくなります。
df = result.to_pandas()
print(df.head())
自動評価精度の向上(プロンプトチューニングの工夫)
Ragasの実装後、最初は自動評価の精度が低く、あまり良い結果を出すことができませんでした。
そのため、プロンプトチューニングを工夫し、何度もテストすることで精度率を向上させることに成功しました。
プロンプトの工夫
Ragasの自動評価精度を向上させるためにプロンプトのチューニングはとても重要です。
今回、プロンプトをチューニングしていくにあたり、最も工夫した部分は、「Aspect Critique」(独自の評価基準をプロンプトで定義したもの)の判定基準です。
初めは、プロンプトに単一の軸を持たせ評価させるプロンプトを組んでおりましたが、精度が低く改善する必要がございました。
そこで今回、評価の軸を複数設定し2つの軸を設けて評価するように設定しました。
軸を増やすことで、評価の幅を広げ、より正確な精度判定を目指しました。
具体的には、以下2つの軸を設定いたしました。
解決性: 問い合わせの根本的な課題解決に繋がるか
有用性: 直接的な解決策でなくとも、解決のヒントになるか
こちらが実際に設定した2つの軸を用いたプロンプトの一部抜粋となっております。
・解決性

・有用性

複数軸を設けたプロンプトを使用することで、解決性と有用性の観点から評価が行われて、自動評価の精度を格段に上げることができました。
Datadog ダッシュボードによる自動評価の可視化
生成AIの出力結果をRagasで自動評価し、Datadogのダッシュボードで可視化できるようにしております。
前段で説明した「解決性」「有用性」の各プロンプトが正しいか否かの評価に加えて、問い合わせと回答の「関連性」に妥当性があるのかを分析しております。
以下が、自動評価結果を可視化したダッシュボードとなっております。
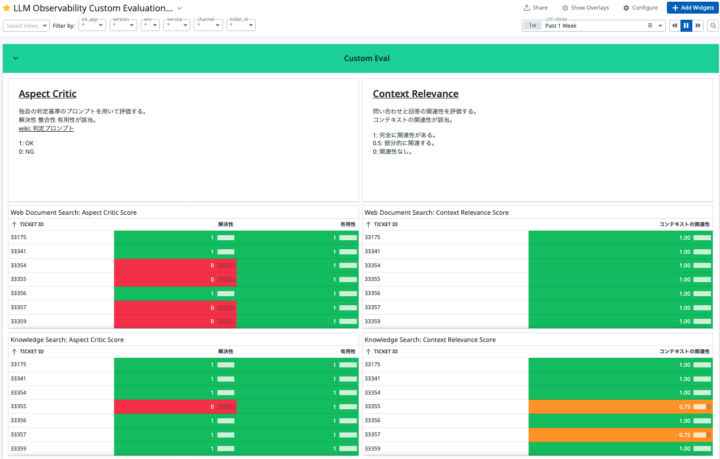
生成AIの出力が正しいと判断した場合は1番で緑色となります。正しくないと判断した場合は0番で赤色となります。
Ragasが自動評価した結果を可視化できたことで、生成AIの出力値が正しくない場合に即座に気づくことができるようになりました。
これにより、生成AIそのものの精度を向上させるため、効率的に分析と修正に取りかかることが可能になりました。
まとめ
今回は、Ragas を活用した自動評価システムの導入について軌跡を記載いたしました。
これを導入することで、生成AIの回答評価における手動工数の課題を解決しただけではなく、客観的で信頼性の高い評価を自動で行う体制が整いました。
アイレットでは、生成AIを用いた社内業務の効率化、RagasやLLM Observabilityを用いた自動化・可視化の実現などの事例がございます。
興味がある方がいらっしゃいましたら是非とも弊社にご連絡ください。




