
前回のあらすじ
【連載第7回】「アラート疲れ」に終止符を。AIOpsで障害を未然に防ぐ
前回、私たちはAIOpsという「未来を予測する防災センター」の思想を学び、障害の「予兆」を捉えるという、未来予知にも似た強力な武器を手に入れました。AIという名の名探偵が、膨大なデータからインシデントの兆候を突き止め、私たちに警告してくれるようになったのです。
強固な基盤(SRE)、賢明な財政(FinOps)、そして未来を予測する防災センター(AIOps)。私たちのクラウド都市は、これまでにないレベルで強固で、賢く、そしてプロアクティブなインフラを手に入れようとしています。しかし、都市のインフラ管理局(運用チーム)の指令室に耳を澄ませば、予兆を捉えた後にも、こんな悲痛な声が聞こえてきませんか?
「アラート検知から15分…まだ担当エンジニアと連絡がつかない!」
「手順書はどこだ!?え、このパラメータで本当に合ってるのか…プレッシャーで手が震える…」
「やっと復旧できた…。でも、サービス停止時間は結局45分。お客様への報告書が重い…」
それは、どんなに優れた予知能力があっても越えられない「最後の壁」。復旧の最終ステップを「人間」に頼る限り、どうしても避けられない『ヒューマン・レイテンシー(人間であるがゆえの対応遅延)』です。
もし、火災警報と同時に、スプリンクラーが自動で初期消火を始めるように、システム自身が復旧作業を開始してくれたとしたら? もし、エンジニアが障害対応に駆けつけるのではなく、システムからの「復旧完了報告」を受け取る側になるとしたら?
今回お話しするのは、そんな未来を実現するための「自己修復アーキテクチャ」という、クラウド都市における一つの理想形とも言えるインフラ防衛システムの思想です。
この記事でわかること
- なぜ従来の「人による」インシデント対応では、エンジニアが疲弊し、ビジネス機会を損失してしまうのか。
- ITILが定める「正しい復旧ルール」と、SREが追求する「徹底的な自動化」が結びついた時に生まれる「自己修復」というパワフルな概念。
- AWSサービス(CloudWatch, EventBridge, Systems Manager)を組み合わせた「自己修復アーキテクチャ」の具体的な構成例とその仕組み。
- 自己修復がもたらす、単なる工数削減を超えたビジネス価値(MTTRの劇的な短縮、信頼性向上、エンジニアの創造性解放)という未来像。
人の手による復旧がなぜ限界なのか? – 機会損失という「見えないコスト」

「深夜に鳴り響くアラート。飛び起きてPCを開き、チームメンバーを緊急招集。手順書を探し出し、震える手でコマンドを一つ一つ実行。1時間後、なんとか暫定復旧。しかし、本当の戦いはそこから。原因調査と報告書作成で、朝を迎える…」
ITの最前線に立つ皆さんなら、一度ならず経験している光景ではないでしょうか。このプロセスは、エンジニアの心身をすり減らすだけでなく、ビジネスに「機会損失」という見えない、しかし甚大なコストを発生させています。
サービスが停止している1時間は、ECサイトであれば数百万、数千万円の売上損失に直結します。SaaSビジネスであれば、顧客からの信頼を失い、解約に繋がるかもしれません。
問題は、私たち「人間」が対応する限り、復旧にかかる時間(MTTR)をゼロに近づけることには限界がある、というシンプルな事実です。
- 認知の遅れ: アラートに気づくまでの時間
- 判断の遅れ: 状況を把握し、対応方針を決めるまでの時間
- 操作の遅れ: 手順書を確認し、手動でオペレーションする時間
これに加えて、焦りやプレッシャーによるヒューマンエラーのリスクも常に付きまといます。どれだけ優秀なエンジニアがいても、この根本的な課題から逃れることはできません。
思考OSの融合:ITILの「規律」とSREの「自動化」

では、どうすればこの限界を突破できるのか。ここで、私たちの思考OSであるITILと、その相棒であるSREの思想が、見事な相乗効果を発揮します。
- ITILのインシデント管理は、都市の「交通法規」を定めます。つまり、「どのような状態をインシデントと定義し」「どのような手順で復旧させ」「誰に報告するべきか」という、復旧プロセスの規律(ルール)を定義します。これは、対応の標準化とガバナンスの基盤となります。
- SREの思想は、その法規に従って自律的に走行する「自動運転車」を開発することを目指します。つまり、ITILが定めたルールを、人間ではなく機械に実行させるための自動化(オートメーション)をとことん追求します。
しかし、現実はどうでしょうか。多くの現場では、せっかくの「手順書(法規)」が、深夜に叩き起こされたエンジニアが、手作業で実行するためのものになってはいないでしょうか。
次世代MSPが目指すのは、この二つの思想の完全な融合です。ITILで設計された「洗練された復旧シナリオ(設計図)」を、SREのプラクティスである「自動化コード」によって忠実に実行させることで、システムは自律的に動き出すのです。
AWSで築く「自己修復都市」の設計図 (To-Beモデル)
それでは、この思想をAWSというプラットフォーム上でどう実現するのか。具体的な設計図を見ていきましょう。これは、特定のインシデントに対して、システムが自律的に判断し、修復までを完結させるためのアーキテクチャの一例です。
以下の図は、CloudWatchでのSLO違反検知をトリガーに、EventBridgeを経由してSystems Managerが自動修復を実行する、自己修復アーキテクチャの処理フローを示したものです。
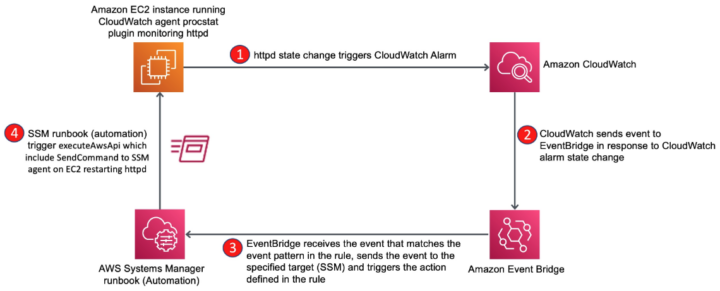
出典:Use Amazon EventBridge rules to run AWS Systems Manager automation in response to CloudWatch alarms
このアーキテクチャは、大きく3つのステップで機能します。
ステップ1: 異常の検知 (都市のセンサー) – Amazon CloudWatch Alarms

まず、都市の至る所に設置された高感度な「異常検知センサー」が必要です。これが Amazon CloudWatch Alarms の役割です。しかし、このセンサーが何を検知するかが極めて重要です。システムの「悲鳴」をあげるだけのセンサーでしょうか? それとも、市民(=ユーザー)の「失望」を直接検知するセンサーでしょうか?
例えば、従来のリソース監視では、以下のようなアラートが一般的でした。
「Webサーバー群のCPU使用率(平均)が、10分間にわたって90%を超過した」
これはシステムの健康状態を知る上で重要な指標ですが、必ずしもユーザー体験の低下に直結するとは限りません。CPU使用率が高くても、サービスが快適に応答しているケースもあるからです。
そこで私たちは、SREのプラクティスであるSLO(Service Level Objective)に基づいてアラームを設定します。これは、ユーザー体験の品質を直接測るための目標値です。
- 可用性SLOの例:
「ALBが処理したリクエストのうち、正常応答(HTTP 2xx, 4xx)の割合が、5分間で99.9%を下回った」 - レイテンシSLOの例:
「主要APIエンドポイントへのリクエストのうち、90%が500ミリ秒以内に完了するという目標に対し、実績値が10分間にわたって目標未達となった」
このように、ビジネスへの影響と直結する明確な条件でアラームを発報させます。これはもはや単なるリソース監視ではなく、サービスの品質低下、すなわちビジネスの損失に繋がる事象を直接検知するためのトリガーなのです。
ステップ2: 指令の発令 (中央指令室) – Amazon EventBridge

センサーがユーザー体験の低下を検知したら、その情報を集約し、適切な対応チームへ指令を出す「中央指令室」が必要です。この役割を担うのが Amazon EventBridge です。
CloudWatch Alarmの状態が ALARM に変化すると、そのイベントがEventBridgeに送られます。EventBridgeは、受信したイベントのパターン(どのSLOに違反したか)を分析し、事前に定義されたルールに基づいて、次に実行すべきアクションを判断します。
「可用性SLO違反(正常応答率の低下)ならば、修復パターンAを実行せよ」「レイテンシSLO違反(応答時間の悪化)ならば、調査パターンBを開始せよ」
このように、イベントに応じた指令を瞬時に振り分ける、極めて優秀な司令塔です。
ステップ3: 自動修復の実行 (自律型ドローン) – AWS Systems Manager Automation

指令を受けたら、現場に急行し、正確に任務を遂行する「自律型ドローン」が必要です。これが AWS Systems Manager Automation の「Runbook」です。 EventBridgeからの指令をトリガーに、指定されたAutomation Runbookが実行されます。Runbookには、ITILで定められた復旧手順がコードとして記述されています。
例:Webサーバーのプロセス再起動
- 対象インスタンスで特定のプロセスが応答不能か確認
- 応答不能であれば、プロセスを安全に再起動
- 再起動後、正常性を確認
- 結果をITSMツールにチケットとして起票し、関係者に通知
これらの処理は、すべて人間を介さずに、数秒から数分で完了します。Systems Managerは、深夜にエンジニアが手順書と格闘する代わりに、冷静沈着に、かつ超高速で修復作業を実行してくれるのです。
自己修復がもたらす真の価値 – MTTR、限りなくゼロの世界へ

この自己修復アーキテクチャがもたらす価値は、単なる「運用工数の削減」に留まりません。
- MTTR(平均修復時間)の劇的な短縮
- 人間の認知、判断、操作にかかる時間をほぼ完全に排除することで、MTTRをこれまでの人手による対応とは比較にならないレベルまで短縮し、ゼロに近づけることを目指します。これまで30分かかっていた定型的な復旧作業が、5分以内に自動で完了する世界。これは、機会損失を最小化し、ビジネスの収益性に直接貢献します。
- サービス信頼性の向上 (Error Budgetの節約)
- システムが自律的に安定性を維持するため、SLOの達成率が格段に向上します。これは、SREでいうところの「エラーバジェット」(サービスが停止しても許される時間の上限)の消費を抑え、顧客満足度の向上と、より挑戦的な新機能開発への投資を可能にします。
- エンジニアをヒーローに:創造性を解放する役割変革
- おそらく、最も本質的な変化は、エンジニアの役割です。彼らは、インシデントに追われる「修復作業者」から、システムの回復力を高める「修復ロジックを設計・改善する開発者」へと進化します。トイル(無価値な繰り返し作業)から解放されたエンジニアは、その創造性を、再発防止策の検討やパフォーマンスチューニングといった、より本質的な価値創造活動に注力できるようになるのです。
私たちが目指すのは、例えば「この自己修復の仕組み化により、特定インシデントの対応工数を月間40時間削減し、その創出された時間を新機能開発に再投資することで、プロダクトのリリースサイクルを15%短縮する」といった、具体的かつ測定可能なビジネス成果をお客様と共に実現することです。
まとめ:魂は、ツールではなく「設計図」に宿る

まずは、最も頻繁に発生し、かつ手順が完全に定型化されているアラート一つから、この自己修復の仕組みを試してみませんか?
例えば、『特定のWebサーバープロセスの停止』や『ディスク使用率の超過』といった、原因と復旧手順が1対1で明確に決まっているものから始めるのが定石です。
このアーキテクチャの成功の鍵は、AWSのサービス知識そのものよりも、ITILに基づいて標準化された『優れた復旧シナリオ』を設計できるかにあります。
どんなに優れた自動化ツールも、魂のない道具に過ぎません。その価値は、「何を」「どのような順番で」「どう判断させるか」という、私たちの知見が込められた「設計図(=Automation Runbook)」によって初めて引き出されます。
これまでの運用は、個人の経験や勘といった「属人化した職人技」に支えられていたかもしれません。自己修復とは、その暗黙知を誰もが再現可能な「形式知」へと昇華させ、システム自身に実行させる取り組みです。
職人技に依存し、ヒーローの登場を待つだけのインフラ。それとも、優れた設計図に基づき、自律的に安定稼働を続けるインフラ。
あなたがこれから描く最初の「自動復旧の設計図」は、どのようなものでしょうか? 私たちの役割は、もはやツールの番人ではありません。お客様のビジネスを成功に導く最高の設計図を描き、育て続けるアーキテクトなのです。
補足資料:自己修復アーキテクチャの原則
この記事で解説した自己修復の考え方は、AWSが公式に推奨するベストプラクティスに基づいています。
出典:AWS Well-Architected フレームワーク: REL11-BP03 Automate healing on all layers
次回予告
優れた復旧の「設計図」をコードとしてシステムに組み込み、インフラの自己治癒力を高める方法論を手に入れました。これにより、エンジニアは繰り返される障害対応から解放され、より創造的な仕事に集中できる環境が整い始めます。
しかし、この「設計図」が生み出す本当の価値は、どうすればビジネスサイドや経営層に伝わるのでしょうか? 「インシデント対応時間を5分に短縮した」という技術的な成果報告だけでは、そのビジネスインパクトの全てを語ることはできません。
私たちの成果を、顧客満足度や事業の売上といった「ビジネスの言葉」に翻訳する。そのための強力な羅針盤が「SLO(サービスレベル目標)」です。
次回は、単なるシステム稼働率ではない、ビジネス価値に直結する新しい指標「SLO」に焦点を当てます。エンジニアの貢献を、誰もが理解できる共通のダッシュボードで可視化し、技術とビジネスが同じ目標に向かうための世界観をお話しします。
【第9回】技術指標が「売上」に変わる?SLOでビジネス価値を可視化する。
過去の連載はこちら
これまでのバックナンバーを見逃した方は、こちらからご覧いただけます。
- 【連載第1回】AWSという都市は、なぜ「カオス」と化すのか?
- 【連載第2回】ITILはクラウド運用の「標準OS」。AWS公式が示す、その深い関係性
- 【連載第3回】あなたのMSPは「サポーター」? それとも「戦略的パートナー」? 未来を共創する関係性の見極め方
- 【連載第4回】ITILの心臓部「SVS」をAWSで動かす設計図
- 【連載第5回】なぜ障害対応は「モグラ叩き」で終わるのか? 災害に強い都市を造るITILインシデント管理術
- 【連載第6回】 「クラウド貧乏」を卒業。コストを価値に変えるFinOps文化
- 【連載第7回】 「アラート疲れ」に終止符を。AIOpsで障害を未然に防ぐ
クラウド運用に関するお悩みや、これからのパートナーシップのあり方にご興味をお持ちでしたら、どうぞお気軽にお声がけください。あなたのビジネスが直面している課題について、ぜひお聞かせいただけませんか。

