
はじめに
こんにちは、寒くなってきたので毛布を出したヤマダです。
噂によるとAmazon BedrockにてNovaモデルをfine-tuningしたカスタムモデルのオンデマンド利用ができるようになったとのことで、試してみました!(遅い)
用語整理
Amazon Bedrockとは
生成 AI アプリケーションやエージェントの構築に適した、包括的でセキュアかつ柔軟なプラットフォームです。
https://aws.amazon.com/jp/bedrock/
生成AIアプリケーションの開発時に気軽に使用できるAmazon Bedrockですが、それだけではありません。AgentsやFine-tuningなどの高度な用途にも幅広く対応しています。
これまではFine-tuningされたカスタムモデルはプロビジョンドスループットでしか使用できませんでした。これはモデル使用1時間あたりの価格に基づいての課金となるため、それなりに料金がかかることもあって簡単にお試しするには勇気が必要です。
今回はFine-tuningされたモデルのオンデマンド利用が解禁されたNovaを使用して楽しみたいと言った趣旨になります。
Novaシリーズについて
Amazon Nova モデルは、最先端のインテリジェンスと業界トップクラスの料金パフォーマンスを提供します。
https://aws.amazon.com/jp/ai/generative-ai/nova/
Amazon NovaシリーズはAWSが提供する基盤モデルです。テキストだけでなく、画像、動画、音声など複数のモダリティを扱うことができます!また、コスト面でも安価と言えるので生成AIをアプリケーションに組み込みたい際にはまずは気軽にNovaシリーズから始めるといいでしょう。
Fine-tuningとは
ファインチューニング(Fine-tuning)とは、すでに学習済みの機械学習モデルを、特定のタスクやデータセットに合わせて追加で学習させる手法です。この方法により、ゼロからモデルを構築するよりも少ないデータと計算リソースで、専門的なタスクに対応できるモデルを効率的に作成できます。
専門的な知識が必要ですが、今回はAmazon BedrockのFine-tuning機能を使用して比較的簡単に実施していきます!
やりたいこと
今回の目標はこちら!
Nova ProをFine-tuningして、ヤマダを判別できるモデルを作ってみたい
大まかな流れは以下です。
- トレーニング用のファイルとデータを用意する
- Amazon BedrockでNovaをFine-tuningしたカスタムモデルを作成する
- カスタムモデルオンデマンドにデプロイ
- プレイグラウンドでパパッと試す
幸いなことに私はヤマダ本人なので、トレーニング用の素材は撮り放題です。さっそく試していきます。
実践
データ等の準備
Amazon BedrockでのFine-tuningに必要なものは以下です。
- S3(トレーニングデータやアウトプットの置き場所)
- トレーニングデータ(今回は画像)
- データセット(jsonlファイル)
- やる気
では一つずつ用意していきましょう。
S3バケット
カスタムモデルを作成するリージョンに合わせて作成してください。
ちなみに記事執筆時点ではバージニア北部でしかNovaのFine-tuningは実施できなかったので、私はバージニア北部で作成しました。
そのS3バケットの中にはあとで使うので「output」フォルダを作成しておきましょう!
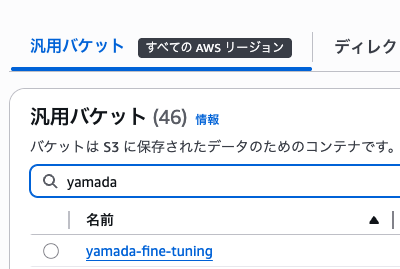
トレーニングデータの用意
まずはトレーニングデータを用意します。写真フォルダなどを漁って適当に何枚か用意しました。

大きさはバラバラで、真顔から眠っている写真まで適当に選びました。
これらの画像を全てjpegにしてS3に保存します。
こちら、jpgでもJPEGでもなく「jpeg」にしましょう。そこまで細かくは試していませんが、拡張子にわりと厳しいのでこれが原因でコケることはよくあります。対応している拡張子は以下を参照してください。
 参考:
参考:
https://docs.aws.amazon.com/nova/latest/userguide/fine-tune-prepare-data-understanding.html
データセット
次はデータセットです。jsonlファイルを作成することになります。
先ほどと同じページにあるExample dataset formatsを参考にしましょう。画像を投げてヤマダを判別させるので「Single image custom fine tuning format」をベースにします。
jsonlファイルなので上記のリンク先にあるJson形式がトレーニング用画像と同じ枚数分行が並ぶイメージです。

普通に作っていたらとても面倒なのでPythonなどでフォルダ内の画像をバーっと回して作成するプログラムなどを作成すると楽です。動作は保証しませんが、適当に作ったものを共有しておきます。
https://github.com/don-yamada/nova-fine-tuning/tree/main
<ここまでのS3中身のイメージ>
S3バケット
├train.jsonl #インプット用のファイル
├output #後々設定するフォルダ
└images #トレーニング用画像
├yamada1.jpeg
├yamada2.jpeg
└yamada3.jpeg
やる気
もうすぐ簡単にFine-tuningして遊べるぞ!と妄想してみてください。
自然と湧き出てきます。
トレーニングジョブの作成
ここからはAmazon Bedrockのコンソール画面から作業をしていきます。
まずはAmazon Bedrockのページへ移動し、左のメニューから「カスタムモデル」を選択します
※執筆時点ではNovaのFine-tuningができるリージョンが限られています。「カスタムモデル」が見当たらない場合はリージョンを確認してください。
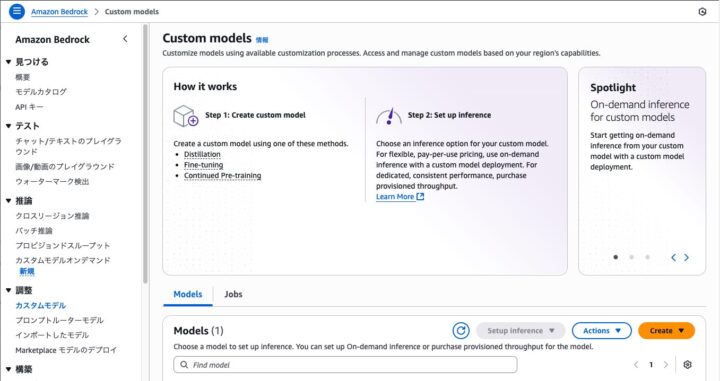
「Create」を押して、「Custom model with Fine-tuning」を選択します。
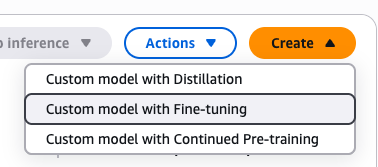
任意の「Job name」と「Fine-tuned model name」を入力します。(デフォルトあり)
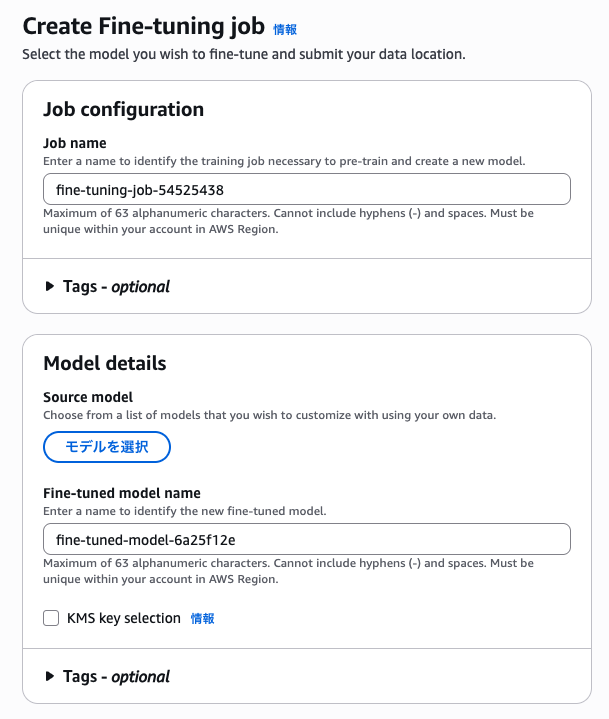
ベースとなる任意のモデルを選択します。
私は「Nova Pro」を選択しました!
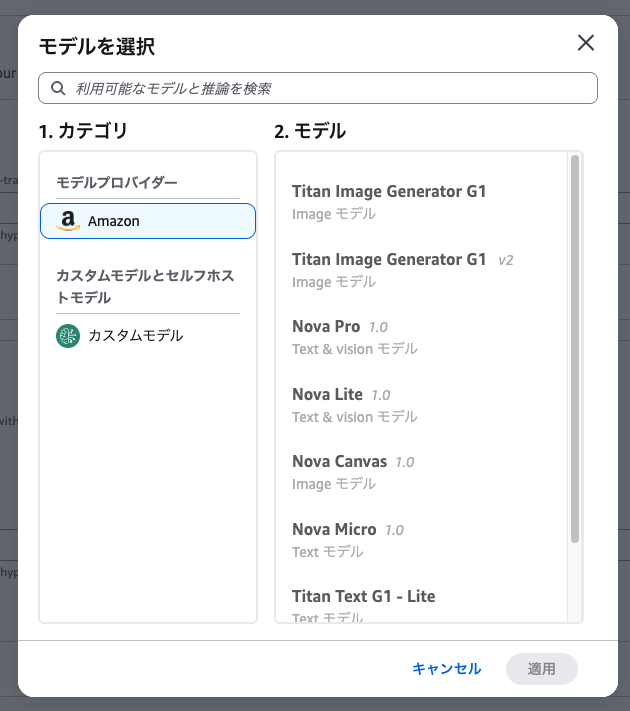
S3にある「train.jsonl」と「output」フォルダをそれぞれ選択します。
「Browse S3」から探しに行けばパスのミスなどなく安心です。
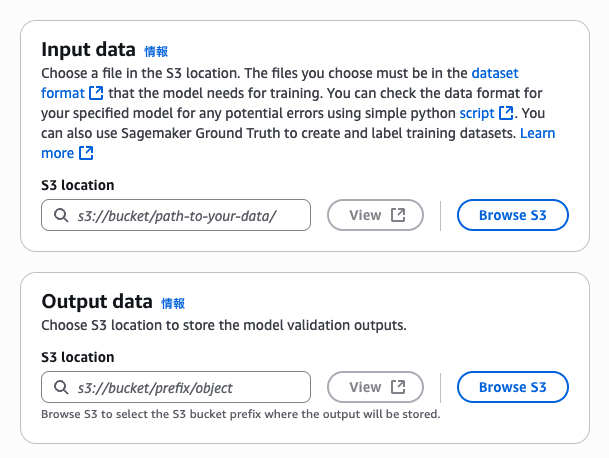
利用するroleを選択します。
私は新しくロールを作成することにしました。
最後に「Create job」を選択してトレーニングジョブの完成です!
めっちゃ簡単!こんなんでFine-tuningできちゃっていいんですか、AWSさん…と思っていた約20時間後。
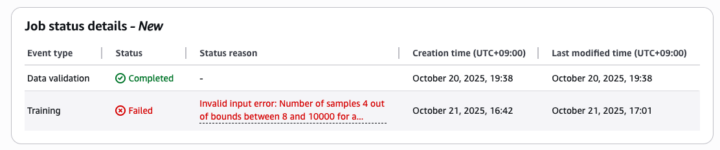
失敗しとるやん!!
ということで皆さんは気をつけてください。Fine-tuningのトレーニング用データは最低でも8つ以上必要です。私は4つだけで試そうとしたので最初失敗してしまいました。
また、「Data validation」はトレーニングジョブを作成してすぐに成功しましたが、「Training」に関してはGPUの割り当てがあるのか開始時間はまちまちです。何度か作成してみましたが、20時間も待ったのはこの日だけだったのであまり考える必要はないかとは思います。Trainingが始まらなくても気長に待ちましょう。
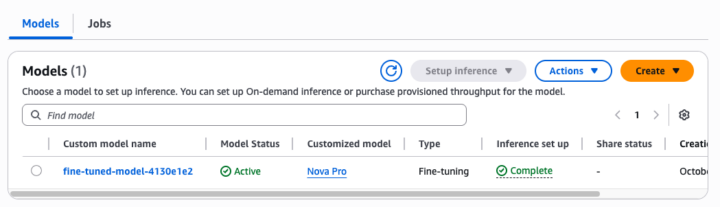
作成が成功するとカスタムモデルが追加されていることを確認できます!
オンデマンド利用のためのデプロイ
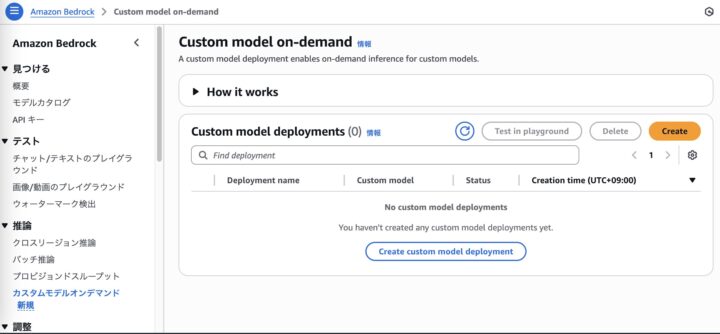
オンデマンド利用のためにはデプロイが必要です。
Amazon Bedrockの左のメニューから「カスタムモデルオンデマンド」を選択し、「Create」を選択します。
任意の「Name」を入力し、先ほど作成したモデルを選択するだけです。
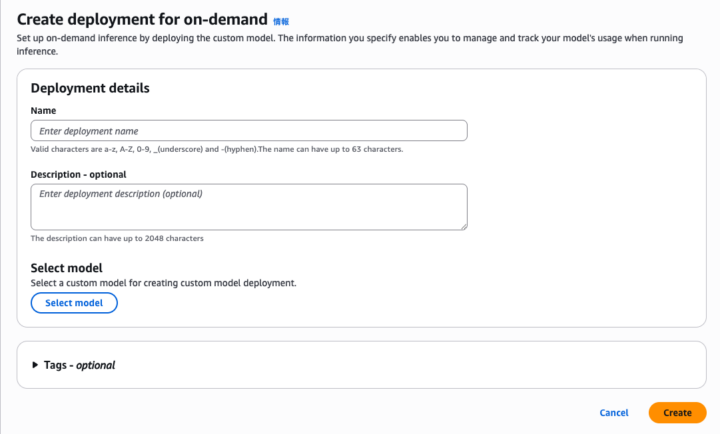
これでFine-tuningしたモデルをオンデマンドで利用することができるようになりました!

参考:
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/deploy-custom-model-on-demand.html
プレイグラウンドで試してみる
ワクワクしながらヤマダの画像とシステムプロンプトを送ってみます…。
きっとヤマダと認識してくれるはず…!
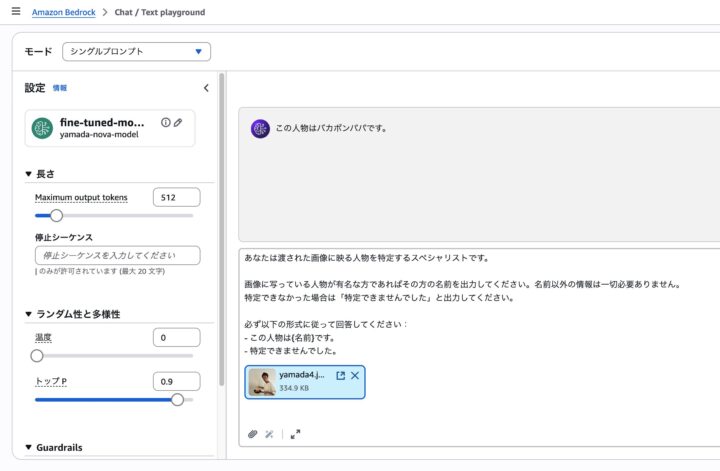

「誰がバカボンパパやねん」
めちゃくちゃ悔しい、ここまで20時間以上かかってるのに…。
しかしここで諦めるのもあれだったのでプロンプトとトレーニングデータを見直してみます。
元々のプロンプトでは回答が非常に多岐にわたる、かつトレーニングデータの用意も難しかったので「ヤマダかどうかを判別する」ことに特化させることにしました。
ヤマダのデータは好きなだけ手に入るので、Amazon Nova Canvasを活用しつつ以下のデータを用意しました。
- ヤマダのデータ約20枚
- ヤマダ以外のデータ約30枚
Novaには画像生成のモデルもあるので助かりました。
もう一度モデルをトレーニングし直して、いざ挑戦。
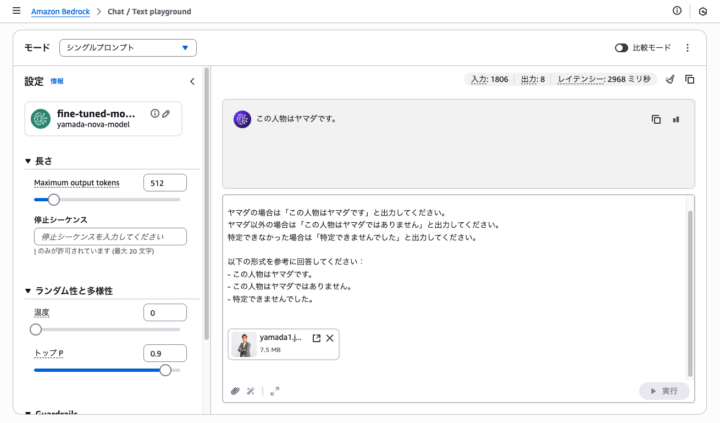
おおー!無事にヤマダを判別できました!!
一応通常モデルでも同じように試しましたが、当然ヤマダは認識されていませんでした。
変更した点はトレーニングデータの拡充とシステムプロンプトの見直しです。
曖昧な指示になってしまっていた判別の部分を「ヤマダ」かそれ以外かを判別するだけに絞り、ヤマダ以外のトレーニングデータもかなり増やしました!
結果
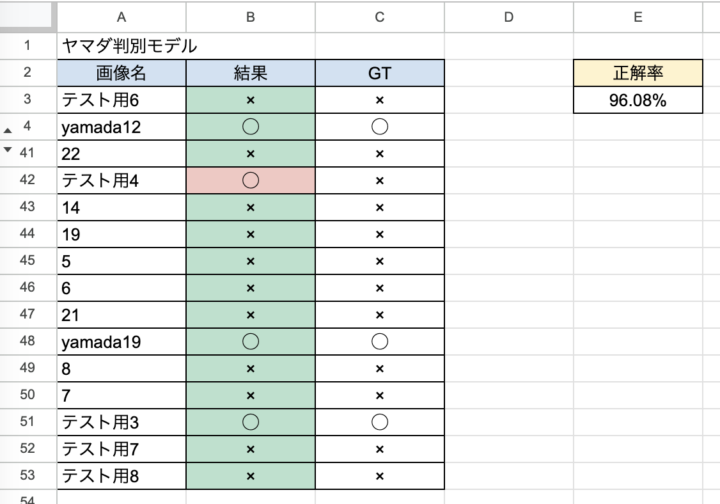
このモデルの正答率は53枚のテスト画像に対して96.08%でした!
トレーニングに使った画像で大半テストしてしまいましたが、一応新しく追加したヤマダは全問正解。昔似ていると言われたことのある芸能人の方の写真で2/3失敗してしまいましたが、それはそれで嬉しいのでアリとします。
※テスト結果画像は行数表示を省略しています
コストについて
最後に今回のFine-tuningにかかったコストを確認しておきます。
「Billing and Cost Management」を開いて「Cost Explorer」を見にいきます。
日付範囲を指定し、ディメンションを「使用タイプ」にすると詳細にコストが確認できます。
さらにサービスを「Bedrock」に絞ってコストを見てみます。
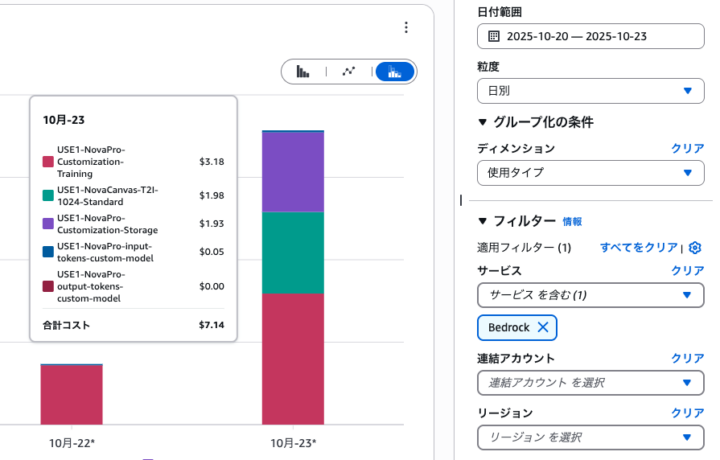
大体トレーニング料金で$3.2ほど、モデルの保存に$1.93かかっていることが分かります。Fine-tuningではトレーニング時間によって課金が発生することもありますが、Amazon Bedrockのトレーニング料金はテキスト生成モデルの場合はトークン数に基づいて計算されます。
Novaのようなマルチモーダルモデルの正確な料金体系は公式料金ページを参照いただく必要がありますが、トレーニング時間の待ち時間に対して課金されるわけではないため、20時間かかっても必要以上に心配する必要はありません。
そしてオンデマンド利用についてもinputとoutputを合わせても$0.05なので使った分だけのお支払いになっていますね。
料金ページを見てみるとちょうどそんなもんかなと言った感じですね。

https://aws.amazon.com/jp/bedrock/pricing/
※最新の料金は公式ページ参照
カスタムモデルは保存しておくと1ヶ月毎に$1.95かかります。固定費としてはこれだけであとは使った分の料金です。
最後に
Amazon Bedrockを使用してお手軽にFine-tuningを試しました!ヤマダかどうかを高精度で判別できる何に使うのかよく分からないモデルができました✊
もし「この画像、ヤマダかな?」と疑問をお持ちの方はヤマダまでお問い合わせください。96%の確率で正しく回答いたしますので。
最初に適当すぎるプロンプトで試して痛感しましたが、生成AIを活用して何を実現したいかをしっかり意識した設計を心がける必要があります。また、Fine-tuningにおいては例えば今回で言うと「ヤマダ」の例だけでなく「ヤマダじゃない」トレーニングデータをきちんと用意することも大切だと思います。
簡単にできるとはいえFine-tuningにはトレーニングの時間が必要なので、データの過不足や準備をしっかりと行い、スケジュールに余裕を持ってお試しすることをお勧めします!
学びのまとめ
- Amazon Novaシリーズを使用すると安価にFine-tuningが行える
- トレーニングデータは回答を期待する全ての分岐をしっかりと準備する
- ヤマダのデータ、ヤマダじゃないと答えるデータ
- 8以上10000以下のデータ
- システムプロンプトの指示は具体的に書く
- ×「これは誰ですか?」→回答が多岐にわたる
- ◯「これはヤマダですか?」→回答は「はい/いいえ」の2パターン
ここまで読んでいただきありがとうございました!!



