
こんにちは、アジャイル事業部のみちのすけです。re:Invent 2025 に現地参加しています!
この記事は re:Invent 「Slack securely powers internal AI dev tools with Bedrock and Strands (AIM3309)」のセッションレポートです。
Slack と AWS の開発チームが、開発者向け AI ツールとエージェントの実装について紹介していました。
概要
セッションでは、Slack の Developer Experience(DevXP)チームが Amazon Bedrock を活用して AI ツールを導入し、99% の開発者が AI を採用、25% の PR 数増加という具体的な成果を達成した経緯が語られました。特に印象的だったのは、SageMaker から Bedrock への移行で 98% のコスト削減を実現し、さらにエージェント技術を活用した Escalation Bot で 月 5,000 件以上の問い合わせを処理している点です。
こんな方におすすめ
- 開発チームへの AI ツール導入を検討している方
- Amazon Bedrock や Claude を使った実践的な事例を知りたい方
- エージェント技術(Strands、MCP)の実装に興味がある方
- 開発者生産性の測定方法を学びたい方
登壇者
- Prashant Ganapathy さん(AWS Senior Solutions Architect)
- Shrivani Bepi さん(Slack Staff Software Engineer, DevXP AI team)
- Mani さん(AWS Strategic ISV Accounts, Gen AI)

Slack Developer Experience チームの AI ジャーニー
Slack の DevXP チームは、約 70〜80 名で構成され、Slack 全体のエンジニア(さらには Salesforce 組織)の開発体験を向上させることをミッションとしています。Mani さんから、このチームの特徴について説明がありました。
最大の特徴は、まず内部で試し、小規模なエンジニアチームで検証してから全体に展開するという慎重なアプローチです。何かを構築したら、まず POC として内部で使用し、小規模なエンジニアチームで展開します。成功が証明されたら、より大きなオーディエンスに展開するという流れです。
小さく始めて検証してから広げる、というのは当たり前のようで、実際にやるのは難しいですよね。このアプローチが後の成功につながっていくんだと思います。
AWS のスタック構成
Mani さんから、Slack が活用している AWS のスタックについて説明がありました。
- SageMaker: カスタムモデルの構築、学習、デプロイ(データと MLOps を自分で管理)
- Bedrock: フルマネージドな基盤モデルレイヤー(複数のモデルプロバイダー、ガードレール、RAG 用のナレッジベース、柔軟なホスティングオプション)
- Agent Core: ランタイム、アイデンティティ、メモリ、オブザーバビリティなどのエージェントインフラ
- SDK エージェント: Strands エージェントなどのフレームワーク
- アプリケーション層: Hero、QuickSweep など
簡潔にまとめると、「SageMaker でモデルを構築し、Bedrock で安全にスケールし、Strands でエージェントを実装し、アプリケーションで提供する」という構造です。
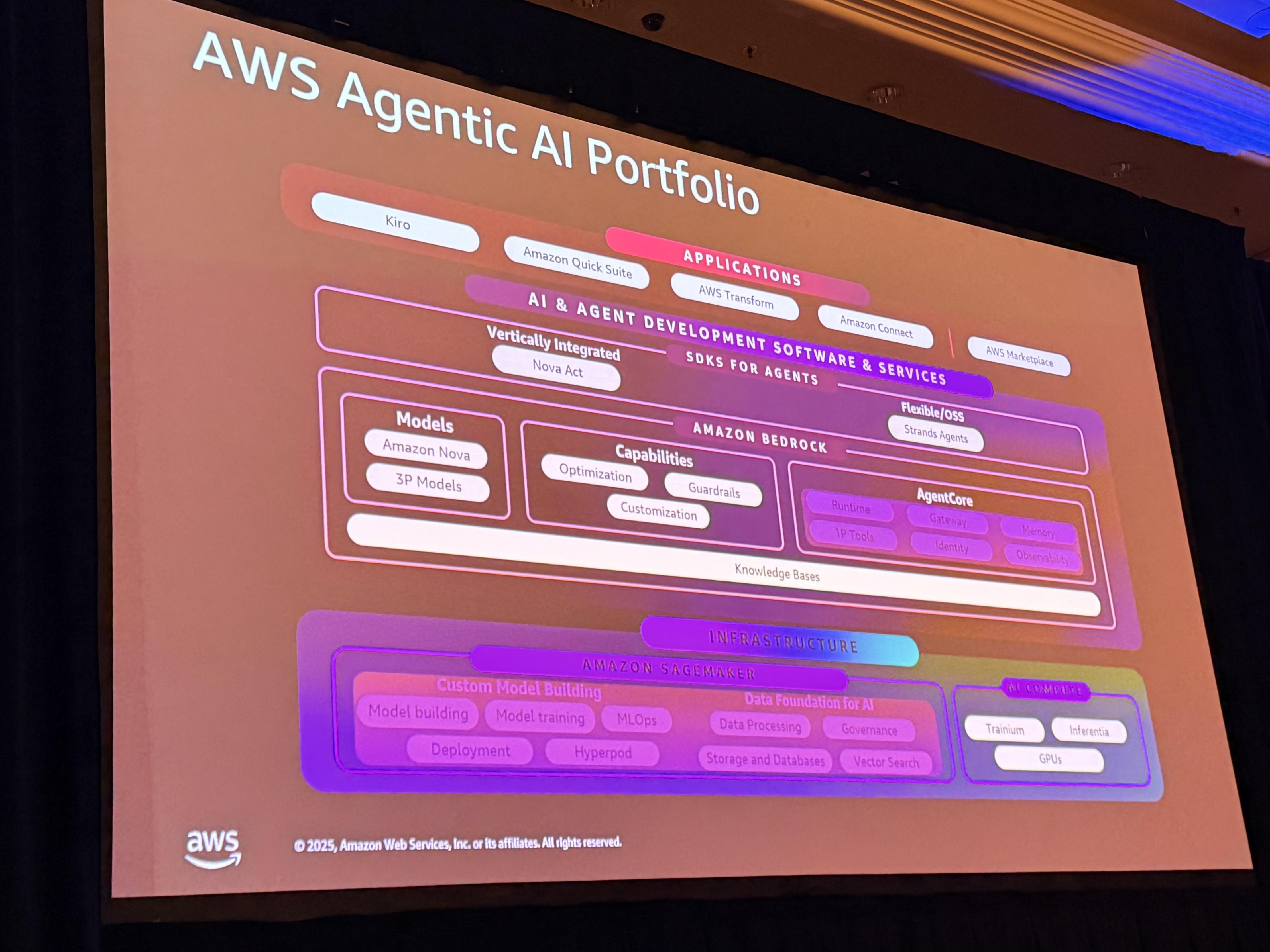
このスタック全体が、Slack の AI 導入を支える基盤となっているということなんですね。開発チームがインフラを気にせず、本質的な開発体験の向上に集中できる環境が整っているという点は、特に参考になりました。
Slack の AI 導入タイムライン
Mani さんの説明によると、Slack の AI ジャーニーは約 2 年前から始まりました。以下、四半期ごとの進化を追ってみましょう。
2023 Q2: SageMaker での学習フェーズ
生成 AI が盛り上がり始めた時期、Slack は SageMaker を使って実験を開始しました。この選択の理由は、Slack が持つ厳格なコンプライアンス要件を満たせたことです。この段階は、学習とプロトタイピングに重点が置かれていました。
2023 Q3: 内部ハッカソンで可能性を証明
チームは内部ハッカソンを開催し、プロトタイプを作成しました。この時期に生まれたのが、Slack の「Huddle Summaries」機能です。この段階は「何ができるのか」を証明するフェーズでした。
2024 Q1: Bedrock への移行
Bedrock が FedRAMP 準拠となり、Anthropic の最新モデルが利用可能になったタイミングで、Slack は Bedrock に移行しました。インフラ管理がはるかに簡単になり、Bedrock ではすべてが面倒を見てくれるとのことです。すべての差別化されていない重労働を Bedrock が引き受けてくれました。
驚くべきことに、この移行により コストは 98% 削減されました。
98% って…ほぼタダみたいなものですよね笑
2024 Q2: BuddyBot の誕生
Bedrock に慣れてきた頃、最初のボット「BuddyBot」が登場しました。これはドキュメント検索を支援するボットで、開発者がより簡単に情報を見つけられるようにするものです。BuddyBot の構築中、Slack はナレッジベースの使用を開始しました。これにより、ベクトルストアの管理が不要になり、開発者はより良い埋め込み、より良いナレッジベース、より速い回答を得られるようになりました。
2025 Q1: コーディング支援ツールの導入
BuddyBot を構築する中で、開発者からコーディング支援のリクエストが増えました。「さらに進めないか?コーディング支援を構築できないか?」という声です。
そこで Anthropic との実験が始まり、Cursor と Claude Code の導入が進みました。Anthropic のモデルは Bedrock 上で利用できたため、Claude Code と Cursor を採用し、Bedrock 上ですぐに導入できました。
2025 Q2: エージェント技術への進出
重要なステップとして、エージェントの構築に進みました。エージェント技術は、MCP(Model Context Protocol)サーバーを通じてデータにアクセスする新しい方法でした。Mani さんは「Slack は A2A(Agent to Agent)に急いで進むことはせず、学習に時間をかけた」と述べていました。最初の MCP サーバーを構築し、エージェント構築の基盤を固めました。
2025 Q3: Strands と Escalation Bot
Slack は Strands を導入し、Escalation Bot を構築しました。Strands とエージェントを使用して BuddyBot から Escalation Bot への進化を実現したとのことで、この詳細についてはセッションの後半で Shrivani さんから説明がありました。
Strands は、オープンソースのマルチモデル非依存で柔軟なフレームワークです。エージェント技術の旅に出ている方は、ぜひ使ってみてほしいとのことです。
ここまでのタイムラインで最大の学びは、Slack がスピードを保ちながら着実に進化を続けてきたという点です。実験を続け、出荷を続け、学習を続けました。その結果、今日では数十万トークン/分から数百万トークン/分の処理にスケールしています。AI が「ジョギング」から「スプリント」に変わったと Mani さんは表現していました。
この段階的なアプローチは、かなり現実的だと感じました。いきなり完璧なシステムを目指すのではなく、小さく始めて学びながら進化させていく方法は、多くの組織で参考になると思います。

なぜ Bedrock を選んだのか?
Mani さんから、Slack が Bedrock を標準化した理由について説明がありました。
1. 統合されたプラットフォーム
AWS 全体で統一されたプラットフォームとして、構築、スケール、ガバナンスをすべて一箇所で管理できます。
2. セキュリティとコンプライアンス
これは「Job Zero」(最優先事項)だと Mani さんは強調していました。Bedrock にはガードレール、セキュリティ、コンプライアンスが組み込まれています。
3. 大規模なスケーラビリティ
Slack は単一の AI ユースケースだけでなく、複数の組織、数千〜数万の従業員に対して複数の AI ユースケースを実行しています。Bedrock なら、インフラを気にせずスケールできます。SageMaker から Bedrock への移行が、本当に大きな助けになったとのことです。
Bedrock により、本当に重要なこと、つまり素晴らしい開発者体験とユーザー体験の構築に集中できるようになったと Mani さんは語っていました。
負担を減らしながらコストも下がるというのは、理想的ですね。特に、エンジニアが本来やるべき「素晴らしい開発者体験の構築」に集中できるのは良いことだと感じました。

開発者への実際の影響:驚きの数字
Mani さんから Shrivani さんへのバトンタッチの前に、インパクトについて触れられました。Cursor と Claude Code on Amazon Bedrock を使った AI 支援コーディングにより、Slack はアイデアが実際の機能に変わる速度を完全に変えました。
Slack の Staff Software Engineer である Shrivani さんから、具体的なインパクトについて説明がありました。
測定の難しさ
「AI は本当に役立っているのか?」という問いに答えるのは難しい課題です。それに答えるには、何を測定し、どう測定するかを知る必要があります。
Slack は以下の 2 つの基盤メトリクスからスタートしました。
- AI 採用率: エンジニアが AI ツールを採用していれば、ワークフローの痛みを軽減している最初の兆候
- 開発者体験メトリクス: DORA メトリクスや SPACE メトリクスへの影響
これらのメトリクスを測定するには、複数のデータソースからのデータが必要でした。Slack は、すべての AI ツールに OpenTelemetry またはテレメトリを組み込み、使用状況メトリクスと AI ツール呼び出しを取得しました。また、GitHub からプルリクエストやコミットのメトリクスを測定しました。AI が共同作成者となっているものや、AI の署名があるものです。
これらのメトリクスにより、完璧ではありませんが、AI を使用して開発者がどのように影響を受けているかの全体的な良い推定値を得られました。
驚きの成果
現在、99% の開発者が何らかの AI 支援を利用しています。これはかなり大きな数字ですね。
採用数を確認した後、開発者生産性メトリクスを調べ始めました。PR スループットを見たところ、主要なリポジトリでは PR スループットが月次で約 25% 一貫して増加していることが分かったとのことです。他にもメトリクスはありますが、これが一貫しているそうです。
ここで私は「なぜ一貫して増加しているのか?」という疑問を持ちましたが、これは後のセクションで Shrivani さんが説明してくれました。
AI ボット支援
Mani さんが話していた AI ボット支援について、Slack がエンジニアのナレッジ検索とエスカレーション支援のためにロールアウトしたボットがあります。
Slack でのエスカレーションは、ユーザーが質問を持ったときに Escal Channels(問い合わせ用のチャンネルみたいなものですね)に入り、適切なチームにエスカレートするプロセスです。これはエンジニアに多くのオンコール疲労を引き起こしていました。そこで、オンコールの痛みを軽減するために AI 支援をロールアウトしました。
現在、AI 支援ボットは 月に 5,000 件以上のエスカレーションリクエストを支援しています。

定性的なフィードバック
最後のメトリクス、そして最も重要なメトリクスは定性的なメトリクス、つまり「開発者からの直接的なフィードバック」だと Shrivani さんは強調されていました。受け取ったフィードバックは、これらのツールが実際に開発者を助けていることを確認しています。
数字だけじゃなくて、実際に使っている人の声を聞くというのが一番大事ということなんですね。
課題も共有
もちろん、AI は完璧ではありません。Shrivani さんは、PR レビュー時間が増加しているという課題も共有されていました。AI がエンジニアのコード記述を支援することで、レビューする範囲が増加し、開発者に負荷をかけているとのことです。この領域でのレビュー時間を削減するために積極的に取り組んでおり、開発者サイクル全体で開発者の痛みを軽減するために AI を実装することを期待しているそうです。
正直驚きました…。99% という数字と、月次で一貫した 25% の増加は、予想以上の成果ですね。ただし、レビュー時間の増加という課題も率直に共有されている点に、誠実さを感じました。

学びと経験:Bedrock への移行がもたらした変化
Shrivani さんから、AI ジャーニーの学びについて語られました。
ここまでで、99% の採用率と 25% の PR スループットというメトリクスは確認できました。しかし、ここに至る道のりは直線ではなかったとのことです。

SageMaker から Bedrock へ
多くの方と同様、Slack も 3 年前から純粋な実験で AI ジャーニーを開始しました。SageMaker と RAG を使用して初期機能を構築しました。これにより最大限のコントロールが得られましたが、インフラメンテナンスという巨大な隠れたコストも伴いました。
ブレークスルーは、AWS Bedrock を採用したときに訪れました。これは単なる技術的な変更ではなく、哲学的な転換でもあったと Shrivani さんは表現していました。
Bedrock は、LLM のスケールとインフラメンテナンスのすべてを瞬時に簡素化しました。この変更により、採用のための重要な成功要因に即座に対処できました。
Bedrock がもたらした成功要因
セキュリティ: Bedrock により、すべてを AWS アカウント内に安全に保持できるようになりました。
採用のしやすさ: プロキシ API を通じて LLM を利用可能にすることで、すべての開発者に AI を使った実験のための LLM アクセスを提供できました。
オブザーバビリティ: Bedrock の CloudWatch ログ、メトリクス、アラートのネイティブなオブザーバビリティにより、LLM 使用状況に関する洞察を得られました。
実験疲れへの対処
旅を通じて直面した主な課題の一つは、さまざまな LLM やツールでの実験疲れでした。AI の状況はものすごく速く変化しており、追いつくのに苦労していました。
新しい競合する内部機能を次々とロールアウトすることは、開発者に混乱を招き、メンテナンスのオーバーヘッドも増大させるだけだと気づきました。
そこで、高いインパクトが期待できる技術スタックに絞り込むことにしました。Amazon Bedrock と Anthropic のモデル・ツールに集中しました。Claude Code や Cursor を Bedrock と統合することで採用を促進しました。
実際、Slack は 2025 年の Q2 に Claude Code を早期にロールアウトした最初の企業の一つだったそうです。
目標は、スループットを最大化し、開発者の意思決定疲労を軽減するシームレスな体験を作ることでした。
ツールを絞り込むという判断は、かなり賢明だと感じました。すべてを試すのではなく、高いインパクトが期待できる技術スタックに集中することで、開発者の混乱を避けつつ、成果を最大化できたんだと思います。

なぜエージェントなのか?
AWS Senior Solutions Architect の Prashant さんから、エージェントへの移行理由について説明がありました。
「これはエージェントの年です」と Prashant さんは言います。
3 つの理由
1. アドホックから自動化されたワークフローへ
コーディング支援ツールと LLM API を使用していた当初、多くのアクションはアドホックでした。例えば、問題が発生したときにログを Claude Code に貼り付けて「何が起きているのか?」と尋ね、Claude Code が答えてくれます。しかし、これはアドホックなワークフローです。
オンコール担当者は多数のリクエストを受け取ります。自動化されたランブックを実行したいというニーズがありました。エージェントなら、リクエストを処理し、適切なツールを選択し、決定を下し、分析と修復を行う次のステップに進めます。
アドホックから自動化されたワークフローへの移行が理由の一つで、「すでにやっている。拡張すればいいだけだ」という判断でした。
2. 複雑な推論の必要性
単純な LLM 呼び出しとアドホックフローでは、複雑な推論は行われません。LLM の検索と若干の後処理だけです。複雑な推論、計画、適応は行われていません。
それがエージェントに向かう別の理由です。特に、リアルタイムで問題を修正し、対応しなければならない環境では重要です。
3. 標準化されたアクセス
Slack は、AWS サービス上に多くのツールとデータソースを構築しています。データパイプライン、CI/CD ビルド、ログ収集など、すべてに効果的に使用しています。これらすべてを動的に活用するには、何らかの標準化されたアクセスを構築する必要がありました。
エージェントは MCP(Model Context Protocol)のようなものと連携します。標準化されたプロトコルを使用して接続を構築し、これらのツールとデータソースを動的に使用できることが、エージェントを構築する別の理由でした。
これらが主な理由で、「すでにアドホックな形でやっている。標準化して自動化すべきだ」というのがエージェントを構築する主な理由でした。
すでにアドホックな形で実現していたことを、標準化して自動化するという自然な流れだったんですね。エージェントは、単なる流行ではなく、実際のニーズから生まれた選択だったと感じました。
エージェント実装のアプローチ
Prashant さんから、具体的な実装方法について説明がありました。
Claude Code のサブエージェント活用
Slack はすでに Claude Code を重用していました。Claude Code の主要な機能の一つは、今年後半に多くのエージェント機能を追加していることです。Claude Code のサブエージェント、プランニング機能、そして今ではスキルも登場しています。
Claude Code は SDK を構築しており、さまざまなタスクのサブエージェントとして効果的に使用できます。専門タスクを実行できるエージェントをゼロから構築するのはものすごく複雑で、本番環境で完璧にするのは困難です。そこで、遭遇していた多くの専門タスクに対して Claude Code のサブエージェントを使い始めました。これが最初に行ったことです。
MCP サーバーの構築
持っているさまざまなツールやデータソースに標準的にアクセスするため、独自の MCP サーバーの構築を始めました。AWS が EKS 用に MCP サーバーを構築したので、そこからも学びました。
「この API を使わなければ」「あの API を使わなければ」と考える必要なく、標準化したいというアイデアでした。
Strands フレームワークの探求
最後に、統合のためのさまざまなエージェントフレームワークを検討していたとのことです。ここで AWS から Strands についての説明がありました。
現在の取り組み
- 巨大なリープをしてスーパーエージェントを構築するのではなく、LLM 統合で構築した既存のワークフローを取り、これらのエージェントワークフローを使用してより多くの機能を追加して強化している
- DevOps 環境やインシデント管理などの新しいユースケースも探求している
これら 3 つのステップは小さなステップですが、進歩を遂げており、本番環境にも導入しています。これはかなり重要なステップですよね。
小さなステップを着実に踏んでいる点が印象的でした。「巨大なスーパーエージェント」を一気に構築するのではなく、既存のワークフローを強化しながら、学習を続けるアプローチは、現実的で持続可能だと感じます。

なぜ Claude Code を超えて Strands へ?
Prashant さんから、Claude Code だけでなく Strands を採用した理由について説明がありました。
過去に Prashant さんと Shrivani さんがお話されたとき、Shrivani さんからこのような質問があったとのことです。「Claude Code とサブエージェントはかなり強力で、SDK ベースで、かなり簡単に自動化を作成できます。では、なぜそれ以上のもの、かなり強力で今日のほとんどのニーズを満たしているものを超えて探す必要があるのでしょうか?」
Prashant さんは、これは重要な質問だと強調されていました。単にそこにあるからという理由だけで新しい技術を採用すべきではなく、目的を果たすべきだ、とのことです。
4 つの理由
1. コストと予測可能性
素晴らしいツールですが、高価になる可能性があります。独自のシステムプロンプトがあり、ユーザーの指示でプロンプトできますが、何を依頼するかによっては予測しにくくなる可能性があります。
2. モデル非依存性
Slack にとっても、すべての人にとっても、モデル非依存であるべき、という考え方とのことです。今日は Anthropic ですが、明日は別のものかもしれません。AI のジャーニーはまだかなり初期段階であり、何が登場するかわかりません。一つの技術にロックインされるべきではない、という方針です。
3. 本番環境でのコスト最適化
現在は探索フェーズなのでコストはそれほど考慮されていませんが、本番環境にロールアウトして使用量が増えると、コストは大きな要因になります。「この専門タスクに対してなぜこんなにお金をかけているのか?もっと安価な LLM を使いたい」と思うことがあると思います。Claude Code に固執していると、それができないかもしれません。
4. オーケストレーターの抽象化
Prashant さんが説明されていたアイデアの一つは、オーケストレーターエージェントの抽象化です(この詳細は後ほど Shrivani さんから説明がありました)。
Claude 自体、Claude Code には独自のオーケストレーター、プランニング、思考能力があり、サブエージェントを指示できます。しかし今、あなたはすべて Claude Code の中にいます。
それを抽象化したらどうでしょう?オーケストレーターを Claude Code から抽象化し、本当に得意なこと、つまり特定のタスクを実行するサブエージェントに使用します。
そうすれば、オープンソース技術を使用してゼロから構築したこのオーケストレーターエージェントは、今日は Claude Code のサブエージェントを指し示すことができますが、明日は別のものを指し示すこともできます。それが鍵です。
抽象化し、何にアクセスするか、いつアクセスするかをコントロールし、それをフレームワーク内に保持します。それが別の理由でした。
最終的に、これらすべてを行うことで、モデル非依存のエージェントフレームワークを作成でき、本番デプロイを将来にわたって保護できます。それが鍵でした。
この議論を経て、エージェントの世界への旅に入りました。
Claude Code の力を認めながらも、柔軟性と将来性を確保するための戦略的な選択だったんですね。ベンダーロックインを避け、コストを最適化し、長期的な拡張性を確保するという考え方は、エンタープライズでの AI 活用においてかなり重要だと感じました。

Strands とは?
AWS Senior Solutions Architect の Prashant さんから、Strands の詳細について説明がありました。
AWS が Strands をオープンソース化した理由
Strands について話す前に、なぜ AWS が Strands を構築し、オープンソース化したのかを話したかったとのことです。
エージェントの可能性は魅力的です。みんながエージェントを構築したがっており、Prashant さん自身もエージェントを構築しようとしましたし、みんなエージェントを構築しようとしています。ある時点で、想像以上に複雑だと気づきます。みんなその経験をしています。
信頼性の高いエージェントを構築する開発者の領域における主な課題は何でしょうか?
学習曲線が急:顧客と協力する中で、シンプルなユースケースは動作させられても、複雑になると、新しい機能や技術が毎週登場するという事実もあって、追いつくのがものすごく困難で、「これで十分なのか、それともあれが登場するのを待つべきか」と決めるのが難しいということがよくありました。
エンタープライズと本番準備: 構築すると、ほとんどが POC やデモでは素晴らしく動作します。しかし、本番環境に持っていくとすぐに、満たすべき別の基準があり、それにははるかに長いサイクルがかかります。
複雑なオーケストレーションロジック: 単一のエージェントやオーケストレーターが 1、2 個のツールを持つエージェントを呼び出すのは素晴らしく動作します。数千のエージェントに達するとすぐに、企業としてエージェントを構築することが目標でない場合、はるかに複雑になります。マルチエージェントパターンについて話しますが、その段階で複雑になり、本番環境では困難になる可能性があります。
可視性の欠如、コントロールの欠如、十分な柔軟性がない: これらは、ほとんどの分散システムにおける共通の課題であり、エージェントでも同様です。
これは技術的にまだかなり初期段階なので、多くをオープンソースのフレームワークに保持したい。そのため Strands をオープンソース化しました。
Strands の特徴
Strands は、わずか数行のコードでエージェントを構築できるオープンソースの Python SDK です。最初に Python SDK をリリースしましたが、re:Invent でいくつかの発表があるかもしれません。
- シンプルで使いやすい
- 複雑なエージェントオーケストレーションの必要性を排除
- コードファーストのソリューション
- ビルダー、開発者を念頭に構築
プロンプトを定義し、ツールのリストを選択し、LLM を選択して、実行するだけです。それほど簡単です。
オープンソース化により、急速に進化するエージェント環境でエージェントを構築するための強力で柔軟なツールを開発者に提供することを目指しています。

Strands の主要機能
1. モデルとデプロイの選択肢
オープンソースであり、デフォルトの LLM は Bedrock ですが、エージェントの一部として LLM として使用する任意のサードパーティやカスタムプロバイダーを選択できます。リストがあり、さらに追加しています。選択する LLM の選択肢を制限していません。また、どこにでも、任意の本番エージェントフレームワークにデプロイできます。それも制限していません。
2. 高い柔軟性
- 組み込みのガードレールがあります。AWS のガードレール機能に接続しますが、外部の他のガードレール機能にも接続します
- 組み込みのネイティブなオブザーバビリティとモニタリング、ストリーミング可能な OpenTelemetry メトリクス
- Agent Core を使用すると、これらのメトリクスで自動的に接続されます
- 発生する複雑なエージェントフローの可視性とトレースを取得するのがかなり簡単です
3. MCP 統合
Model Context Protocol が業界標準になりつつある中、データソースやツールへの接続のために MCP を提供しています。また、Strands 自体に多くのビルトインツールがあり、多くのタスクに使用できます。
4. カスタムツール追加と統合
統合について見ると、Mem0、Raga、Stavely、Temporal との統合があります。他の場所の re:Invent で、AWS の Temporal に関するオープンソースセッションがあります。ぜひ参加してください。
そこにある多くのサードパーティサービスと統合し、高い柔軟性を持たせています。これらが Strands が持つ広範な機能の一部です。
Strands は、開発者がエージェントを簡単に始められる一方で、本番環境に必要な柔軟性と拡張性も提供しているんですね。オープンソースという点も、長期的な信頼性を高める要素だと感じました。

Strands のマルチエージェントパターン
Prashant さんから、Strands に存在する 4 つのマルチエージェントパターンについて説明がありました。
セッションでは、スライドに 4 つのパターンが示されていました。Swarm とその右側の 2 つから始めて、それから Agent as Tools について説明がありました。
1. Swarm(群れ)
想像できるように、複数のエージェント間の協力です。コミュニケーションパターン、共有メモリシステム、調整メカニズムがあり、多数のエージェントが互いに話し合って複雑な問題を解決します。
2. Graph(グラフ)
名前が示すように、エージェントがノードであり、他のエージェントとの通信方法がエッジです。どのように通信するかを明示的に定義します。グラフワークフローパターンを構築できます。
3. Workflow(ワークフロー)
本質的に、あるエージェントが 1 つのタスクを実行し、次のエージェントに渡す、という構造化された方法です。以降も同様です。これが 3 つのパターンです。
4. Agent as Tools(ツールとしてのエージェント)
左側の 4 番目、Agent as Tools は、今最も興味深いものです。なぜなら、それが Slack が使用しているものだからです。
オーケストレーターエージェントについて話しました。Agent as Tools では、ユーザーのインタラクションを処理するオーケストレーターエージェントを使用し、どの専用ツールを呼び出すかを決定します。これらのツールは他のエージェントである可能性があります。だから Agent as Tools なのです。
専用エージェントがそれらのタスクを実行し、オーケストレーションツール、オーケストレーションエージェントに答えを返します。オーケストレーションエージェントは、ユーザーにどのように答えるかを決定します。
このパターンについて、セッションの後半では Shrivani さんから、Strands をオーケストレーターエージェントとして使用し、専用タスクを実行するために Claude Code のサブエージェントを専用エージェントとして使用する具体的な実装例が紹介されました。
「Agent as Tools」というパターンは、かなり実用的ですね。オーケストレーターと専用エージェントを分離することで、それぞれの強みを活かせるのが理解できました。
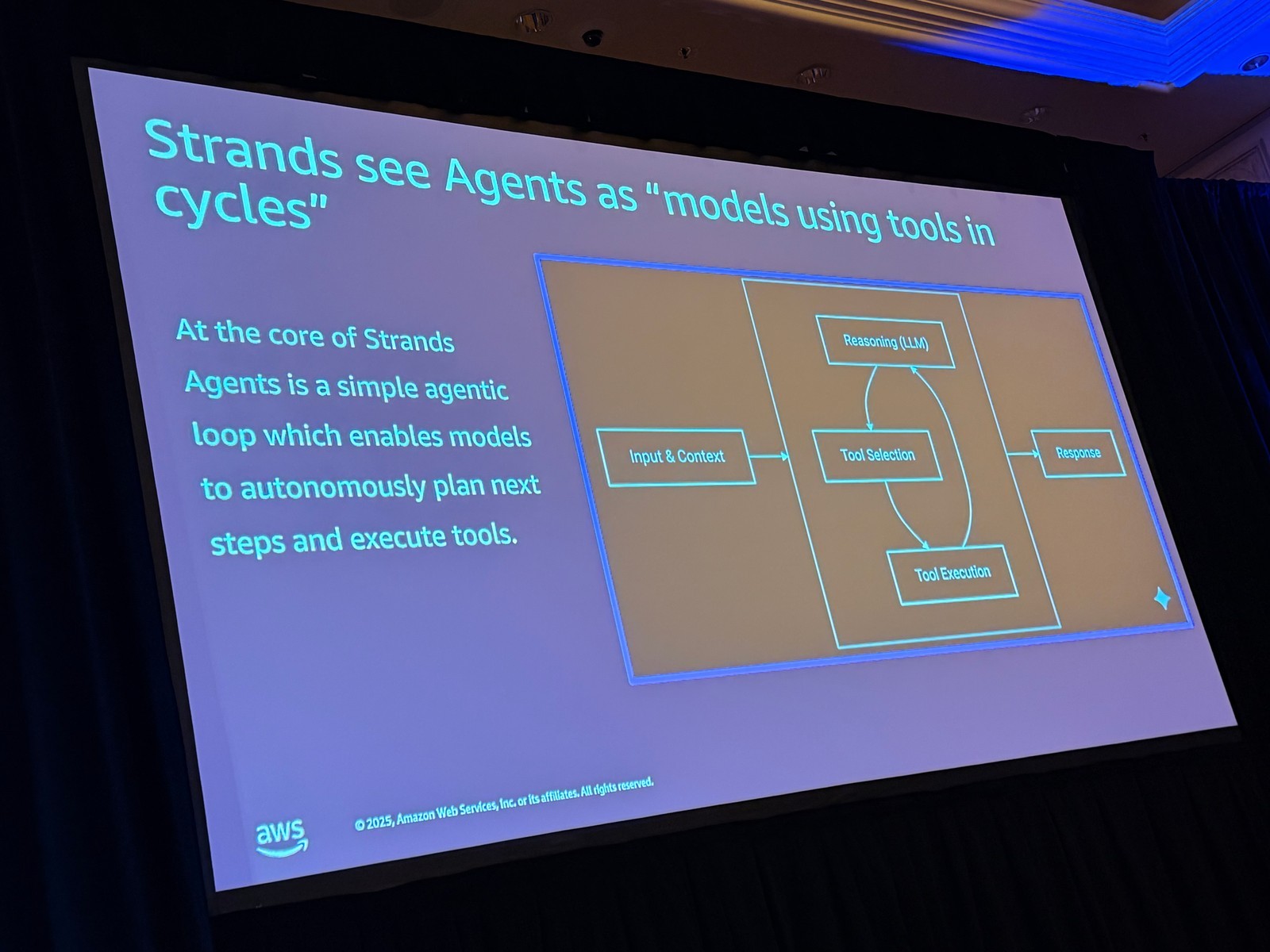
Strands エージェントの仕組み
Prashant さんから、Strands エージェントの基本的な動作について説明がありました。
Prashant さんは、Shrivani さんによるアーキテクチャの詳細説明の前に、Strands エージェントの基本概念について触れておきたいとのことでした。かなりシンプルな概念とのことです。
エージェントループ
Strands は「エージェントループ」と呼ぶもので、機能の中核を形成しています。
プロンプトとコンテキスト、利用可能なツールの説明を受け取ります。次に、モデルがタスクについて推論し、直接応答するかどうかを決定します。
直接応答できる場合は、ツールに応答する必要はありません。そうでない場合は、一連のステップを適用します。以前のアクションを振り返り、必要なツールを選択し、これらのステップのいずれかを実行します。
ツールや要求したタスクから応答を取得すると、タスクが実際に完了したかどうかを決定します。そうでない場合は、完了するまでサイクルを再び繰り返します。
それが Strands の基本的な性質であり、Strands エージェントとマルチエージェントパターンを作成する方法です。
コード例
Prashant さんは、Shrivani さんにバトンタッチする前に、いくつかのシンプルなコード例を示してくれました。Strands エージェントの作成、モデルの選択、そしてツールの使用例です。
# デフォルトの選択肢(Bedrock)を使用してエージェントを作成
from strands import Agent
agent = Agent(
model="bedrock/nova",
prompt="あなたの質問"
)
response = agent.run()
ここでは、数行のコードでエージェントを作成できることがわかります。この場合はデフォルトの選択肢、Bedrock を使用し、Nova モデルを使用してエージェントを作成し、その質問をします。
# ツールを追加
from strands import Agent
from strands.tools import HTTPRequestTool
agent = Agent(
model="bedrock/nova",
tools=[HTTPRequestTool()],
prompt="特定の質問"
)
response = agent.run()
同様に、ツールを添付できます。利用可能な多数のツールカテゴリがあることがわかります。これらのツールから、これらのツールをエージェントに添付し、シンプルなエージェントを作成できます。この場合、HTTP リクエストツールを使用して特定の質問をします。
これらはシンプルな例ですが、始めるのに必要なコード行数がかなり少ないことがわかります。Strands を始めるのがいかに簡単かを強調したかったのです。
Prashant さんは、ここまでの説明で、Slack がなぜエージェントワークフローに向かったのか、なぜ Strands を選択したのか、そして Strands が何を解決しているのかが理解できたのではないか、と締めくくられていました。
コードがシンプルで、すぐに試せそうですね。エージェントループの概念も明確で、理解しやすいと感じました。
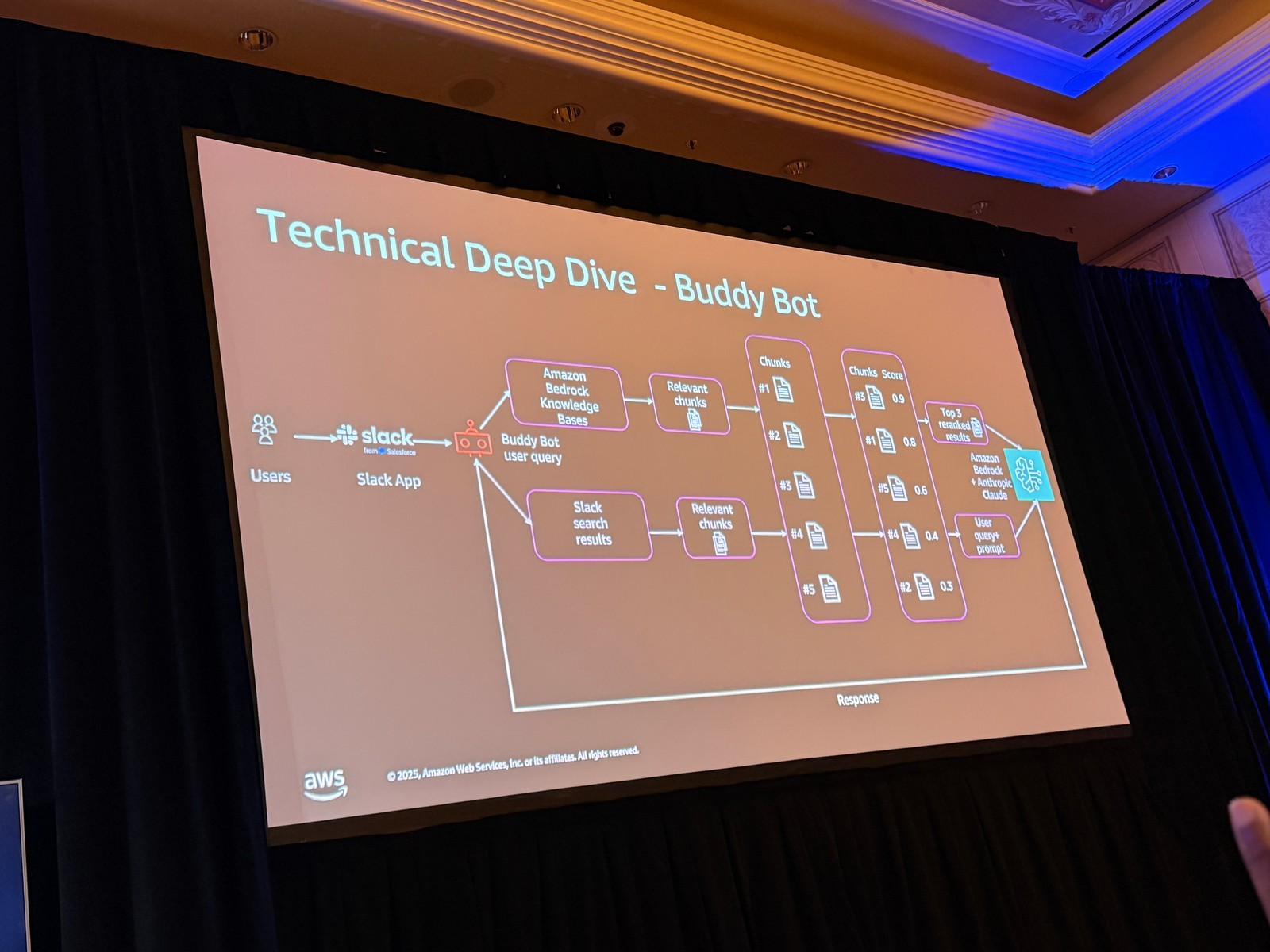
BuddyBot から Escalation Bot への進化
Slack の Staff Software Engineer である Shrivani さんから、BuddyBot の技術的な進化について説明がありました。
Shrivani さんは、ここまでが Prashant さんのパートだったとした上で、BuddyBot の技術的な深掘りと、初期バージョンから Strands を使用した進化について説明を始められました。
初期の BuddyBot アーキテクチャ
Shrivani さんによると、ストーリーは、エンジニアがエスカレーション(S-CAL)に多くの時間を費やしているという根本的な問題点から始まったとのことです。
セッションで示されたスライドによると、初期の BuddyBot アーキテクチャは、さまざまなデータソースに分散した知識を使用して基本的なエスカレーションを処理するように設計されていました。
データソース:
– Slack データ、Slack のメッセージとファイル
– GitHub リポジトリ(技術設計、ドキュメント)に分散したデータ
プロセス:
1. 最初に行ったのはハイブリッド検索です。これらすべてのデータソースから適切な関連情報を収集しました
2. それらのデータをリランク(再順位付け)して、ナレッジソース全体でより正確または関連性の高いデータを取得しました
3. 最も関連性の高いドキュメントを、ユーザークエリとともに LLM に提供し、エスカレーションに対してより正確な回答を提供しました
これが最初の設計で、素晴らしく機能していましたが、初期設計では会話履歴の維持と外部アクションの実行に関する課題に直面しました。
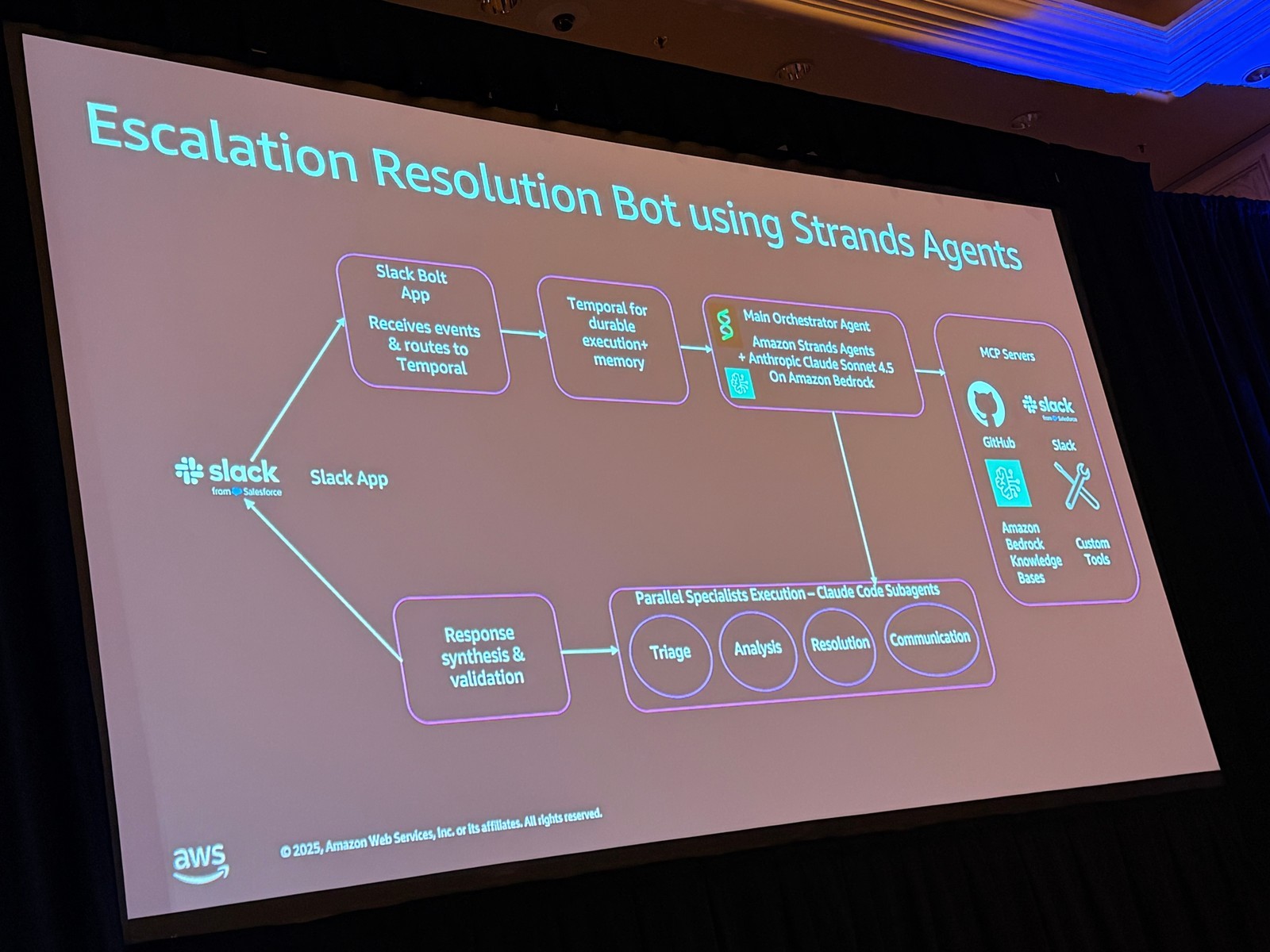
新しいアーキテクチャ:Strands + Temporal
そこで進化したのが、セッションで示された新しいバージョンの Buddy です。Slack が構築・探求している強力なエージェントとのことでした。
フロー:
1. ユーザーがメッセージを送信すると、バックエンドがイベントを受信します
2. その周りに Temporal ワークフローオーケストレーションを開始します
– 耐久性を提供
– エスカレーションが解決されるまで、Slack スレッドで発生するすべてのエスカレーションの会話状態を維持
– アプリケーション内のすべての ESCAL の会話を維持する負担を軽減
3. Temporal ワークフローが メインの Strands オーケストレーターを呼び出します
4. Strands オーケストレーターエージェントは、Anthropic および Anthropic Claude モデルも使用して構築されています
– どのサブエージェントを呼び出すかを決定
– サブエージェントは MCP サーバーにアクセスして、内部サービスと対話します
5. ここに見えるすべてのサブエージェントは、Claude SDK を使用して構築されています
– サブエージェントは Claude です
– オーケストレーションエージェントは Strands です
– サブエージェントは Claude Code です
6. すべてのサブエージェントが実行を完了すると、メインエージェント、オーケストレーションエージェントがコンテキストまたは応答を受け取ります
7. Slack チャンネルに送り返す前に、その応答を統合、処理、検証します
Strands をオーケストレーターとして選んだ理由: さまざまな LLM を探求するためです。Claude Code のサブエージェントだけを使用するのではなく、他の競合モデルも積極的に探求しているとのことです。
Temporal の役割
ユーザーがフォローアップの質問をすると、以前の会話のすべてのコンテキストが実際に Temporal によって維持されます。会話履歴と状態を維持する負担がアプリケーション自体から解放されます。
Temporal は、ユーザーが Slack スレッドで会話を続けるたびに、ワークフローを再開するだけです。
このワークフローにより、会話履歴と耐久性のあるリトライを Temporal が提供してくれるため、コードがかなり簡素化されました。すべて Temporal によって提供されます。
ここでアーキテクチャの全体像が見えてきたんですが、Temporal と Strands の組み合わせがかなり強力だということがわかりますね。
ライブデモ
セッションでは、Slack での実際の動作がデモされました。
ユーザーが Slack チャンネルで質問またはエスカレーションを送信すると、バックエンドがイベントを取得し、Temporal ワークフローを起動します。デモ画面では、Slack スレッドで発生するすべての会話のコンテキストを持つ Temporal ワークフローが表示されていました。
次に、Strands を使用して書かれたオーケストレーターエージェントが開始されます。このオーケストレーターエージェントがリクエストを受信すると、Prashant さんが説明していたツール呼び出しを通じて、サブエージェントを起動します。
デモでは、実際に Triage Agent と KB Agent が呼び出されていました。これらはすべて、Claude Code を使用して構築されたサブエージェントとのことです。
Shrivani さんによると、Temporal の良い点は、すべての呼び出しと追跡可能性の可視性も提供することだそうです。
メインのオーケストレーターエージェントがすべてを処理すると、Slack チャンネルに応答が送り返されます。
ユーザーがフォローアップの質問をすると、以前の会話のすべてのコンテキストが Temporal によって維持されます。デモ画面では、Temporal がユーザーが Slack スレッドで会話を続けるたびに、同じワークフローを再開する様子が示されていました。
フローが終了すると、応答がユーザーに送り返されます。
Shrivani さんは、技術アーキテクチャの概要として、シンプルな検索ボットから強力なエージェントへと Buddy ボットをアップグレードしたと説明されていました。
Temporal と Strands を組み合わせることで、会話の永続性とエージェントの柔軟性を両立しているんですね。特に、バックエンドが落ちても Temporal が状態を保持してくれるという点は、本番環境ではかなり重要だと感じました。
信頼性、効率性、セキュリティへの配慮
Shrivani さんから、BuddyBot を強化する際に考慮した点について説明がありました。
構築する際に考慮したことは、信頼性と効率性です。
1. 安定した基盤:Temporal による信頼性
まず、安定した基盤を構築しました。信頼性のために Temporal を使用しました。ボットは会話を決して忘れません。障害中でも決して忘れません。
バックエンドが停止しても、Temporal はデータベースに状態を維持します。中断したところから再開します。
Temporal は自動リトライもサポートしています。アプリケーション内でツール呼び出しの失敗やすべてをリトライする必要がなかったため、コードがかなり簡素化されました。
2. セキュリティの課題を解決
次に、重要なセキュリティの課題を解決しました。
OAuth サービスと統合されたリモート MCP サーバーを作成しました。これは Uber Proxy というネットワークシステムと統合されています。
これにより、ボットは適切な権限で GitHub のような機密性の高い内部システムに安全にアクセスできます。
3. ボットの高速化
最後に、ボットを高速化することに焦点を当てました。
- これらすべてのサブエージェントを並列実行しました
- トークン使用量の管理を最適化しました
- 要約して LLM に送信して応答を確認する前に、Strands サブエージェントは、サブエージェントからの各応答を要約して、ものすごく高価な LLM に送信する際のトークン管理を削減しました
Strands は、将来的に LLM 非依存であるための拡張性も提供してくれました。
並列実行やトークン最適化など、実践的な工夫が多く取り入れられていますね。特に OAuth を使った権限管理は、エンタープライズ環境では必須の要件だと感じました。

今後のロードマップ
Shrivani さんから、今後の展望について語られました。
先を見据えると、アーキテクチャを安定化させ、セキュリティの問題を解決し、パフォーマンスを最適化しました。しかし、これはあくまで基盤です。ビジョンは単一のエスカレーションボットよりもはるかに大きいものです。
長期的な目標
開発サイクル全体にわたる完全に自動化されたエージェントワークフローを確立することを目指しています。
具体的な取り組み
- エスカレーションを超えた Strands のユースケースを実験したい
- MCP 経由でより多くの内部ツールを統合し、ボットまたはエージェントをより強力にしたい
- Agent Core を探求している
- Temporal と Strands エージェントとのネイティブ統合を希望
- よりスムーズな実行とより細かいリトライを実現
長期目標はシンプルですが野心的です。開発サイクル全体にわたる完全に自動化されたエージェントワークフローです。
野心的でありながら、現実的なステップを踏んで進めているのが印象的でした。開発サイクル全体の自動化は、多くの開発チームが目指すべき方向性だと思います。

Q&A
セッション後の質疑応答から、特に参考になったやり取りをいくつか紹介します。
なぜ Agent Core ではなく Strands から始めたのか?
Q: なぜ Agent Core ではなく Strands から始めたのですか?
A: Strands は、開発者がエージェントを構築・探求するための入り口です。簡単に始められるのが特徴です。
ユースケースができて、うまく機能したら、次は本番環境で動かしたい。そのときに Agent Core が登場します。
Strands のコードを取り、Agent Core でラップします。ランタイム、オブザーバビリティ、認証など、より本番グレードの構成要素がすべてあります。
つまり、Strands は実験用、Agent Core は本番化用と考えるべきです。
この回答はかなりわかりやすいですね。実験と本番でツールを使い分けるという考え方は、多くのプロジェクトで参考になると思います。
ナレッジベースのデータ同期について
Q: ナレッジベースに適切な出力を得るために、どれくらいの作業が必要でしたか?
A: 2 種類のナレッジベースを使用しています。
1 つ目は、AWS ナレッジベース上に構築したものです。特定のドキュメントソース(Slack データ以外)をナレッジベースに同期するパイプラインがあります。
2 つ目は Hound MCP です。これはすべての GitHub リポジトリを横断する検索ツールです。
MCP の Hound と AWS Bedrock のナレッジベースを組み合わせて使用しています。
複数のナレッジソースを組み合わせているんですね。ドキュメントだけでなく、GitHub 全体を検索できる仕組みは、開発チームにとってかなり便利だと感じました。
データセキュリティの確保方法
Q: データセキュリティをどのように確保していますか?例えば、あるチームに制限された GitHub リポジトリがある場合、エージェントがその情報を他の人に共有しないようにするにはどうしていますか?
A: 内部の OAuth サービスと統合しています。
ユーザーが MCP をエージェントに追加する際に認証を行うと、確認と承認が必要になります。
OAuth サービスは JWT トークンを生成します。サービス、Uber Proxy(リバースプロキシのような)がそのトークンを取得すると、ユーザーを検証し、ユーザーのアクセス権に基づいて承認します。ユーザーがアクセス権を持っている場合、GitHub へのアクセスが許可されます。
また、2 種類の認証があります。ローカルのクライアントからエージェント(または MCP)へのものと、Shrivani さんが話したオーバーレイレイヤーを介したマシン間認証です。マシン間認証もそのオーバーレイレイヤーを通じて行われます。
OAuth と JWT を使った細かいアクセス制御が実装されているんですね。これなら、エージェントが不適切な情報にアクセスするリスクを最小限に抑えられそうです。
PR メトリクスの測定について
Q: 測定インパクトのスライドで、PR の量を測定していると述べていました。純粋に量だけを測定しているのですか、それとも PR の内容も測定していますか?KPI を満たすためだけに無意味な PR を作成することを止めるものは何ですか?
A: 両方を測定しています。
定性的なものは測定が少し難しいです。例えば、コード行数の増加を見ているかというようなサブメトリクスを調べています。
また、月次や年次で測定しています。多くのことが変わるため、他の変数も調べています。
ここでは PR スループットを強調しましたが、それだけを測定しているわけではありません。コメント、コードレビュー、実際にかなり多くのメトリクスを測定しています。
すべての DORA と SPACE メトリクスを調べると、すべてのメトリクスが整っています。これらのツールのいずれかをロールアウトすると、その影響を見ます。プラスの影響もあれば、マイナスの影響もあります。
例えば、コードレビューについて Shrivani さんが指摘したように、それは見始めたことで、より多くの時間がかかっているというものです。
量と質の両方を測定し、多角的に評価しているんですね。単一のメトリクスに頼らず、全体像を把握しようとする姿勢が印象的でした。
まとめ
Slack の Developer Experience チームは、約 2 年間かけて AI ツールとエージェントを段階的に導入し、99% の開発者採用率と 25% の PR スループット向上という驚異的な成果を達成しました。
主要なポイント
- 段階的なアプローチ: SageMaker での学習から始め、Bedrock への移行で 98% のコスト削減を実現。小さく始めて、学びながら進化させるアプローチが成功の要因でした。
- Bedrock の選択: 統合されたプラットフォーム、セキュリティ、スケーラビリティが決め手となり、インフラの負担を大幅に軽減しました。
- 測定の重要性: AI 採用率、DORA メトリクス、開発者からの定性的フィードバックを組み合わせて、AI の効果を多面的に測定しています。
- エージェント技術の活用: Claude Code のサブエージェントと Strands オーケストレーターを組み合わせ、柔軟性とコスト最適化を両立。Temporal による会話の永続性も実現しました。
- 課題も共有: PR レビュー時間の増加など、課題も率直に共有し、改善に取り組む姿勢が印象的でした。
全体的な感想
このセッションで特に印象的だったのは、技術的な詳細だけでなく、実際のビジネスインパクトや開発者体験への影響まで包括的に語られていた点です。
99% という採用率は、ツールが本当に開発者にとって価値があることを示していると思います。同時に、レビュー時間の増加という課題も率直に共有されており、AI 導入のリアルな側面が垣間見えました。
また、すべてを一度に完璧にしようとせず、小さく始めて段階的に進化させるアプローチは、多くの組織で参考になると思います。特に、ツールを絞り込んで「実験疲れ」を避けるという判断は賢明だと感じました。
Strands と Agent Core の使い分け(実験用と本番用)、Temporal による会話の永続性、OAuth によるきめ細かいアクセス制御など、実践的な技術選択も多く学べる内容でした。
開発者生産性の向上は、多くの組織が目指すテーマです。Slack の事例は、AI とエージェント技術を活用して、それを実現する具体的な道筋を示してくれていると感じました。



