
Datadog API とは
Datadog は、サーバー/コンテナ/データベース/アプリケーションなど、インフラからアプリケーションまで統合的に監視・可視化できる「可観測性プラットフォーム」です。
その機能をプログラム経由で操作できるのが Datadog API です。
REST API のため、HTTP リクエストを送るだけで以下のような操作ができます。
- メトリクス送信
- ログ送信
- モニター(アラート)作成・更新・削除
- ダッシュボード作成
- SLO 管理
- Synthetic テスト作成
- 組織やユーザー管理
GUI だけでは難しい自動化、再現性のある構成管理を実現するための強力な手段です。
また、Datadog上の情報はCSV化できる情報とできない情報があります。
そんな時、APIを利用すると短時間でリスト化することができ、作業の効率化を図れます。
こんなシーンで Datadog API が役立つ
- インフラ構成やデプロイをコード(IaC)で管理するワークフローにおいて、モニタリング設定まで自動化したい
- 特定のタイミングでメトリクス/ログを送りたい — 例えばバッチ処理後、ジョブ完了後、デプロイ直後など
- ダッシュボードやアラートを環境ごと/チームごとにテンプレート化して、スケールしやすい構成にしたい
- 手動操作や UI 操作を減らし、CI/CD パイプラインに「監視設定」を組み込みたい
- Datadog上でリストができない情報をCSVに落とし込みたい
Datadog API の実例(実際に僕がやったこと)
Datadog API は機能が豊富ですが、実際にどう使うと便利なのかイメージしづらい方も多いと思います。
そこでここでは、僕が Datadog 導入支援プロジェクトや内部検証で 実際に API を使って行った作業 を紹介します。
GUI では難しい作業も、API を使うことで一気に効率化できました。
実例①:Datadog × AWS インテグレーションの整理
Datadog では AWS アカウントとインテグレーションを結ぶことで、CloudWatch メトリクスやログが自動で取り込まれます。
しかし運用していると、以下のようなケースが頻繁に発生します。
- 解約済みの AWS アカウントが Datadog 側に残っている
- インテグレーションが有効なのか無効なのか分からない
- 何百という AWS アカウントのステータス確認を手動でやるのは非現実的
この整理を行うため、Datadog API を活用しました。
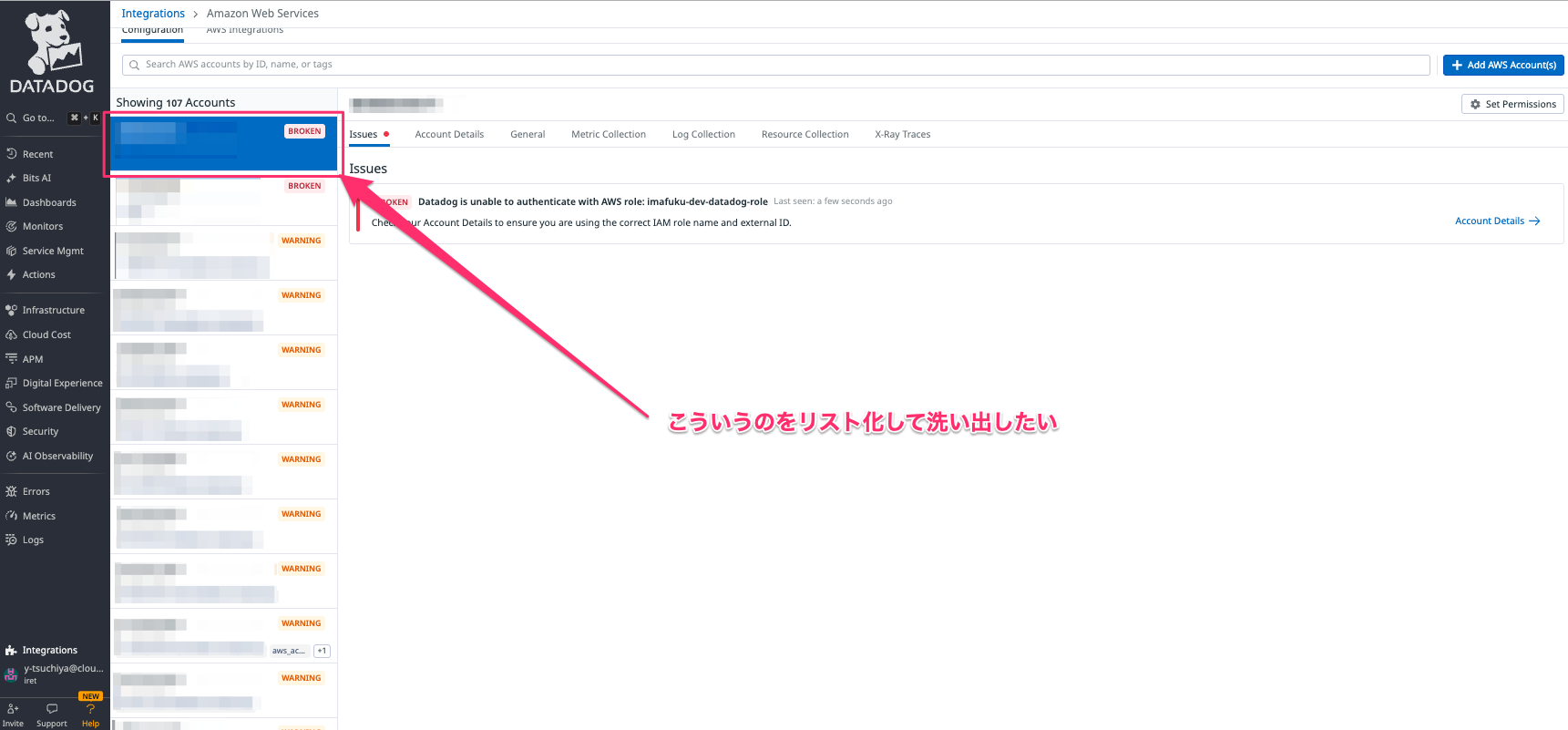
● 取得した情報の例
- Datadog に登録されている AWS アカウント一覧
- それぞれのアカウントが Integration ON か OFF か
- 追加されている RoleArn、ExternalID
- 最終同期日時
- 監視対象サービス(EC2 / RDS / ELB / IAM / CloudTrail…)
API を叩くことで、数百アカウントでも数秒で一覧化できます。
GUI では画面からひとつひとつ確認するしかありませんが、API なら一括取得できるため、
「監視が残っている解約済みアカウント」 や
「意図せず放置されているインテグレーション」 を完全に洗い出せました。
API を使うための準備 ― APIキーとアプリケーションキー
Datadog API を利用するには、以下のキーが必要です:
- API キー:Datadog アカウントを識別し、基本的なデータ送信や API リクエストに使用。
- アプリケーションキー:ユーザーに紐づき、組織や権限範囲を制御。モニター作成や設定変更など、管理系エンドポイントの呼び出し時に必要となる。
API リクエスト時には、HTTP ヘッダー DD-API-KEY, DD-APPLICATION-KEY を使って認証情報を渡します。
実装時には、キーの管理方法も重要 — キーをソースコードに直書きせず、環境変数やシークレットマネージャなどによって安全に保管するのがベストプラクティスです。
公式ドキュメント:API リファレンス
主な API 区域と使える機能
Datadog API は、用途や対象に応じて複数の機能セット(エンドポイント)に分かれています。主なものは次の通りです。
| API 区域 | 概要 |
|---|---|
| メトリクス API | カスタムメトリクスを送信/過去のメトリクスを取得。アプリケーションやインフラのパフォーマンス監視に。 |
| イベント API | デプロイ、データベースのメンテナンス、手動操作などの「イベント」を投稿/取得。 |
| モニター API | CPU使用率やレスポンスタイムなどのしきい値アラートをプログラムで定義・管理。通知やダウンタイム設定も可能。 |
| ダッシュボード API | ダッシュボードの作成、更新、取得。インフラやアプリの状態を可視化する画面をコードで構築。 |
| ログ API | アプリケーションやミドルウェアのログを直接送信/管理。ログ処理のパイプライン構成も可能。 |
| 合成(Synthetic) API | 外部からの監視テスト(Webチェックなど)をスケジュール/管理し、結果取得。 |
| ユーザー/組織管理 API | チーム構成、権限、組織設定の管理。 |
| SLO API | サービスレベル目標 (SLO) の定義・管理。可用性・信頼性指標の追跡。 |
これにより、Datadog を単なる「GUI で使う監視ツール」ではなく、「インフラ/アプリ運用をコードで自動化・構成管理するプラットフォーム」として扱うことができます。
公式ドキュメント:API の使用
使ってみる — Datadog × AWS インテグレーションを API で棚卸し
ここからは、実際に Datadog API を使って AWS インテグレーションの棚卸し を行ったケースを紹介します。
GUI では一覧ダウンロードできない情報でも、API を使うことで短時間でリスト化することができ、作業効率が大きく向上しました。
今回、次のような課題がありました。
- Datadog 上に登録されている AWS アカウントが大量にあるため状態を把握しづらい
- すでに解約済みの AWS アカウントが残っているか確認したい
- どのアカウントのインテグレーションが有効(ON)なのか/無効(OFF)なのかを一覧化したい
これを画面(GUI)で1つずつ確認していくのは現実的ではありません。
そこで Datadog API を利用し、
AWS インテグレーションの設定情報を一括取得 → CSV 化 → スプレッドシートで可視化
というワークフローで棚卸しを実施しました。
棚卸しの流れ(実際に行った作業)
- Datadog API キー/アプリケーションキーを用意し、認証設定を行う
- AWS インテグレーションの情報取得 API にリクエストする
- レスポンス JSON から「AWSアカウントID」「RoleArn」「ExternalID」「有効/無効」「最終同期日時」など必要な情報だけ抽出
- 抽出データを CSV として出力
- CSV を Google スプレッドシートに読み込み、解約済み・運用対象外・無効なアカウントをフィルタリング
この方法により、数百アカウント分の設定状況を数秒〜数十秒ほどで棚卸しできました。
手動では絶対に追いきれない規模の情報でも、API を使うことで正確に洗い出すことができます。
実際に利用した API エンドポイント
棚卸しで使用した主なエンドポイントは以下の通りです。
- GET /api/v1/integration/aws:Datadog に登録されている AWS アカウント一覧を取得
- GET /api/v1/integration/aws/logs:ログ連携(CloudWatch Logs → Datadog)の設定状況を取得
特に /integration/aws では、GUI では見られない「External ID」「RoleArn」「有効フラグ」「同期状況」などの詳細情報まで返されるため、
インテグレーションの棚卸しには必須の API です。
Python での処理イメージ(簡易版)
実際のスクリプトはもう少し複雑ですが、処理のイメージは次のようになります。
import csv
import sys
import requests
# ※URL, HDRS, ORG_LABEL_RAW, SAFE_LABEL などは事前に定義しておく前提です
# URL 例: "https://api.datadoghq.com/api/v2/integration/aws/accounts"
rows = []
cursor = None
while True:
# ページング用のパラメータ(最初の1回は空)
params = {"page[cursor]": cursor} if cursor else {}
r = requests.get(URL, headers=HDRS, params=params, timeout=60)
if r.status_code >= 400:
print("ERROR:", r.status_code, r.text)
sys.exit(1)
j = r.json() or {}
# data 配列を1件ずつ処理
for item in (j.get("data") or []):
attr = (item.get("attributes") or {})
auth = (attr.get("auth_config") or {})
# アカウント情報を優先順で取得
aws_account_id = (
attr.get("aws_account_id")
or auth.get("aws_account_id")
or ""
)
role_name = auth.get("role_name", "")
access_key_id = auth.get("access_key_id", "")
# リージョン設定を「モード」と「値」に整形(実装は別関数とする)
regions_mode, regions_value = flatten_regions(attr.get("aws_regions", {}))
rows.append({
"org": ORG_LABEL_RAW,
"config_id": item.get("id", ""),
"aws_account_id": aws_account_id,
"role_name": role_name,
"access_key_id": access_key_id,
"aws_partition": attr.get("aws_partition", ""),
"regions_mode": regions_mode,
"regions_value": regions_value,
})
# 次ページのカーソルを取得(なければループ終了)
cursor = ((j.get("meta") or {}).get("page") or {}).get("after")
if not cursor:
break
# ---- CSV に出力 ----
out = f"{SAFE_LABEL}_aws_integrations.csv"
with open(out, "w", newline="", encoding="utf-8") as f:
fieldnames = [
"org", "config_id", "aws_account_id",
"role_name", "access_key_id", "aws_partition",
"regions_mode", "regions_value",
]
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for row in rows:
writer.writerow(row)
print(f"🟩 Exported {len(rows)} rows -> {out} (ORG_LABEL={ORG_LABEL_RAW})")
この CSV を Google スプレッドシートに読み込み、色分けやフィルタをかけることで、
「解約済アカウント」「インテグレーション無効」「運用対象外アカウント」などを一覧化して整理しました。
実際に利用したコードはこちら↓
※実際の本番コードでは Datadog API v2 を requests で直接叩き、カーソル付きページングや項目整形などを行っています
while True:
params = {"page[cursor]": cursor} if cursor else {}
r = requests.get(URL, headers=HDRS, params=params, timeout=60)
if r.status_code>=400:
print("ERROR:", r.status_code, r.text); sys.exit(1)
j=r.json() or {}
for item in j.get("data", []) or []:
attr=item.get("attributes", {}) or {}
auth=attr.get("auth_config", {}) or {}
aws_account_id = attr.get("aws_account_id") or auth.get("aws_account_id") or ""
role_name = auth.get("role_name","")
access_key_id = auth.get("access_key_id","")
mode,val = flatten_regions(attr.get("aws_regions", {}))
rows.append({
"org": ORG_LABEL_RAW,
"config_id": item.get("id",""),
"aws_account_id": aws_account_id,
"role_name": role_name,
"access_key_id": access_key_id,
"aws_partition": attr.get("aws_partition",""),
"regions_mode": mode,
"regions_value": val,
"filter_tags": ",".join(attr.get("filter_tags", []) or []),
"account_tags": ",".join(attr.get("account_tags", []) or []),
"account_specific_namespace_rules": ns_rules_to_str(attr.get("account_specific_namespace_rules", {})),
"extended_resource_collection_enabled": str(attr.get("extended_resource_collection_enabled","")),
"cspm_resource_collection_enabled": str(attr.get("cspm_resource_collection_enabled","")),
})
cursor = (j.get("meta") or {}).get("page", {}).get("after")
if not cursor: break
out=f"{SAFE_LABEL}_aws_integrations.csv"
with open(out,"w",newline="",encoding="utf-8") as f:
flds=list(rows[0].keys()) if rows else [
"org","config_id","aws_account_id","role_name","access_key_id","aws_partition",
"regions_mode","regions_value","filter_tags","account_tags",
"account_specific_namespace_rules","extended_resource_collection_enabled","cspm_resource_collection_enabled"
]
w=csv.DictWriter(f, fieldnames=flds); w.writeheader()
for row in rows: w.writerow(row)
print(f"🟩 [aws-accounts] Exported {len(rows)} rows -> {out} (ORG_LABEL={ORG_LABEL_RAW})")
API を使うことで、GUI では取得できない“裏側の設定情報”まで含めて、
環境の棚卸し・コスト最適化・監視の健全化
に役立つことを実感しました。
API 利用時の注意点とベストプラクティス
- キー管理は厳重に:API キー/アプリケーションキーは安全に保管し、環境変数やシークレットマネージャを使う。ソースコードに直書きしない。
- タグ設計を事前に統一する:環境(production/staging)、サービス名、バージョン、リージョン など。タグが散在すると可視化/検索/フィルタが煩雑に。
- リクエストのエラーハンドリングとリトライ:API 利用時はステータスコードのチェック、429(レート制限)対応、タイムアウト設定などを含めた堅牢なコードを。
- 用途に合わせてエンドポイントを使い分ける:単にメトリクスを送りたい/ログを送りたい/モニターを作りたい/ダッシュボードを構成したい、など目的ごとに API を適切に使い分ける。
- 本番/ステージングでキーを分ける:テスト用と本番用で別アカウントまたは少なくとも別キーを使い、誤操作や意図しないデータ送信を防ぐ。
終わりに
Datadog API を使えば、GUI に頼るのではなく、コードベースでモニタリング/可観測性の仕組みを整えられるため、開発・運用の効率化、ミスの削減、構成の再現性確保につながります。
特に、インフラ as コード/継続的デリバリ/自動化を重視する環境では、API を活用した運用は大きな価値を持つでしょう。
Information
以下のような課題でお困りのお客様はぜひ当社にご相談ください。
- サービス障害時にインフラ観点だけでなく、俯瞰的なボトルネック調査を行い、問題の特定・解決を早めたい
- Daadog の導入は決まったものの、ノウハウもなくどうしたらいいかわからない
お客様の課題に合わせて、当社が提供するサービスをご提案させていただきます。
ぜひお気軽にアイレットへご相談ください。

