
こんにちは、アジャイル事業部のみちのすけです。re:Invent 2025 に現地参加しています!
この記事は re:Invent 「Unified knowledge access: Bridging data with generative AI agents (AIM338)」のセッションレポートです。
AWS の Senior Solutions Architect である Aneel Murari さんと Rafia Tapia さんが、構造化データと非構造化データを AI エージェントで統合的にアクセスする方法について、実際にコードを書きながら紹介しました。
概要
このセッションでは、企業に蓄積された構造化データ(Aurora などのリレーショナルデータベース)と非構造化データ(S3 上の PDF やドキュメント)を、単一の AI エージェントから統合的にアクセスする方法が語られました。
特に印象的だったのは、実際にライブコーディングで動くアプリケーションを構築するというアプローチです。スライドだけではなく、実際に動くコードを目の前で組み立てていく様子を見られたのは、とても参考になりました。
こんな方におすすめ
- AI エージェントの実装に興味がある方
- 企業内の様々なデータソースを統合的に活用したいと考えている方
- Amazon Bedrock と Aurora を使った RAG(Retrieval-Augmented Generation)システムの構築を検討している方
- Strands SDK を使ったエージェント開発に関心がある方
登壇者
- Aneel Murari さん(Senior Solutions Architect, AWS)
- Rafia Tapia さん(Senior Solutions Architect, AWS)

なぜ構造化データと非構造化データの統合が必要なのか
セッションは、会場への質問から始まりました。「AI エージェントを構築している、または本番環境で動かしている方はいますか?」という問いかけに、かなり多くの手が挙がりました。
続いて「どんなデータを使っていますか?」という質問では、S3 のファイルなど非構造化データを使っている方と、リレーショナルデータベースなど構造化データを使っている方に分かれました。
Aneel さんは、企業には過去 15〜20 年分の知識がリレーショナルデータベースに蓄積されており、これが企業における主要なデータストレージメカニズムだと説明しました。同時に、過去 10〜15 年では大量の非構造化データも生成されていると話しました。
このセッションのテーマは、まさにこの「異なるサイロに分散したデータを AI エージェントで統合的にアクセスする」ことです。個人的には、多くの企業が抱えている課題だと感じました。データは増え続けているのに、それらが別々のシステムに分散していて、統合的に活用できていないケースは多いと思います。
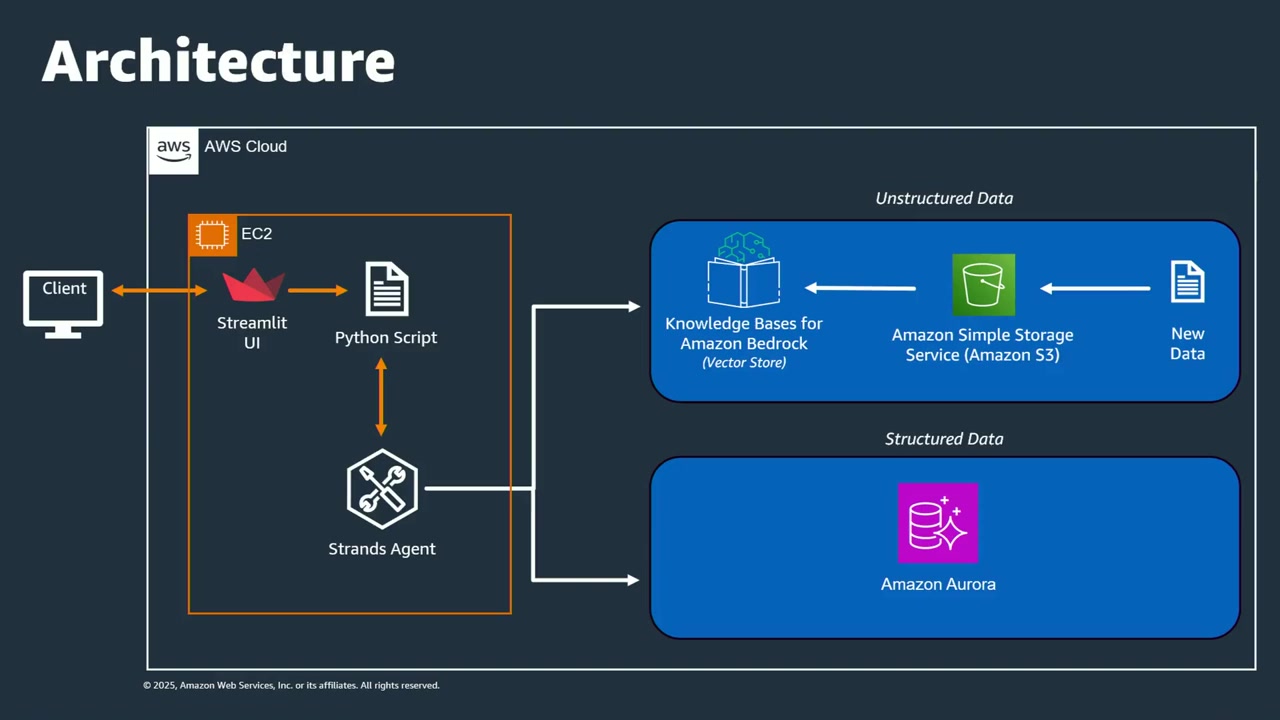
今回構築するアプリケーションのアーキテクチャ
セッションでは、チャリティー団体向けのチャットアシスタントを構築するデモが紹介されました。このアプリケーションは、以下のような構成になっています。
- UI: Streamlit で構築されたシンプルなチャットインターフェース
- 非構造化データ: Amazon Bedrock Knowledge Bases を使って S3 上のドキュメント(キャンペーン情報など)にアクセス
- 構造化データ: Aurora PostgreSQL に保存された会員情報、寄付情報、イベント情報にアクセス
- エージェント: Strands SDK を使って構築され、ユーザーの質問に応じて適切なデータソースを選択して回答を生成
ユーザーが質問を投げると、エージェントが自動的に「この質問には構造化データが必要か、非構造化データが必要か」を判断し、適切なデータソースにアクセスして回答を返すという仕組みです。
これは理想的なアーキテクチャだと思います。ユーザーは「どこにデータがあるか」を意識する必要がなく、自然言語で質問するだけで答えが返ってくるというのは、まさに生成 AI の強みを活かした設計ですね。
Strands SDK とは
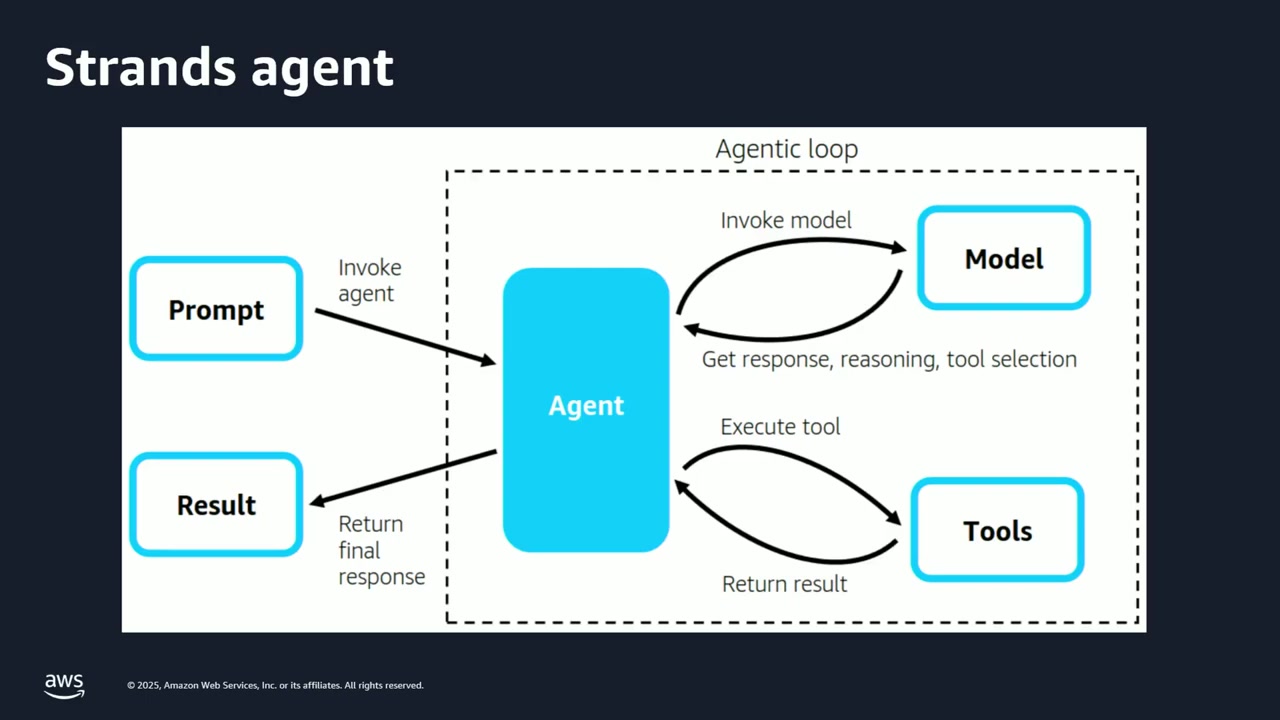
今回のデモでは、エージェントの構築に Strands SDK が使われていました。会場でも「Strands を使ったことがある方は?」という質問に何人かの手が挙がりました。
Rafia さんの説明によると、Strands は単一エージェントだけでなく、複数のエージェントが互いに通信するマルチエージェントシステムも構築できます。また、MCP(Model Context Protocol)や A2A プロトコルもサポートしています。
今回のセッションでは、シンプルな単一エージェントを構築します。ユーザーからプロンプトが送られると、エージェントは内部に持つツールを使って適切なサービスを提供する、という基本的なモデルです。
ちなみに、現在 Strands は Python のみをサポートしているので、セッションでも Python でコードが書かれていました。
Bedrock Knowledge Bases による非構造化データへのアクセス
まず、非構造化データへのアクセス方法について説明がありました。
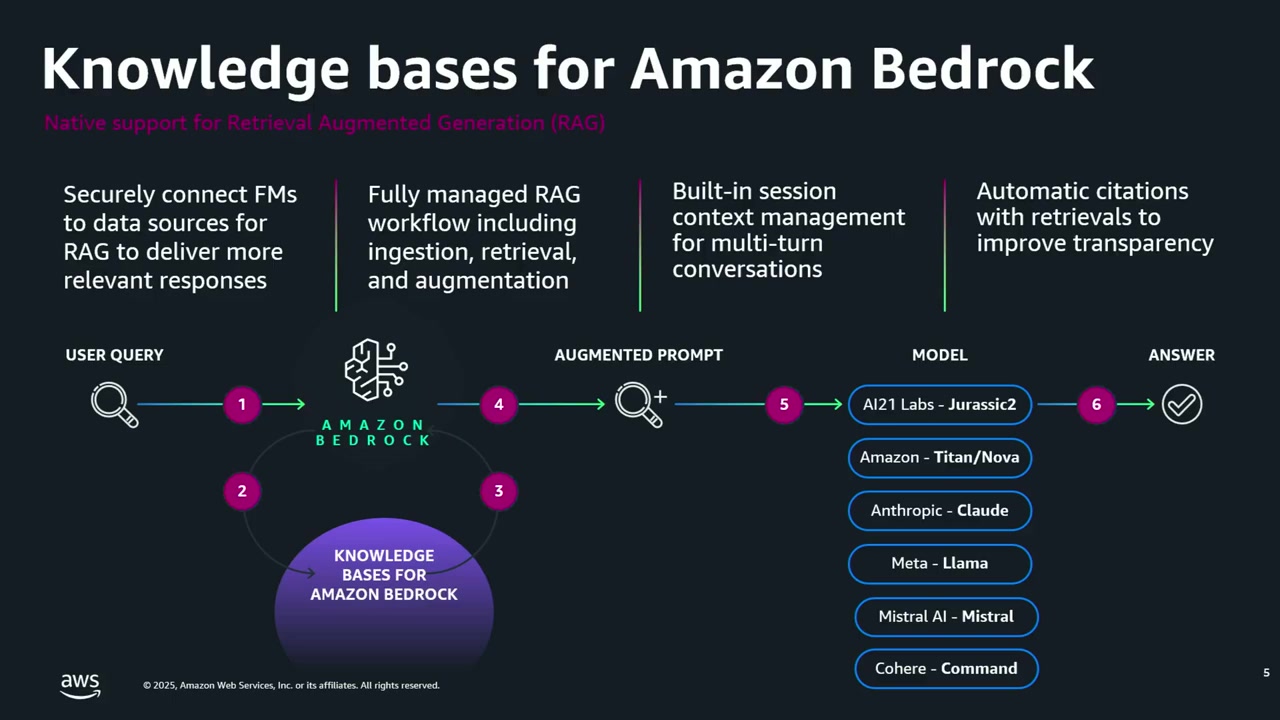
RAG(Retrieval-Augmented Generation)アプリケーションを書いたことがある方は多いと思いますが、基本的な流れは以下の通りです。
- PDF や Word ファイル、ログファイルなどの非構造化データを用意
- それをベクトルに変換(LLM が理解できる形式に変換)
- そのベクトルデータを使って、LLM に質問応答させる
Bedrock Knowledge Bases を使うと、この RAG インフラを効果的かつ簡単に構築できます。
セッションでは、時間の都合上、すでに Knowledge Base は作成済みでしたが、「興味がある方はセッション後に話しかけてください」と案内していました。実際、セッション中にも「Knowledge Base の作り方を知りたい」という声があり、「数クリックで作れます」という回答がありました。
個人的には、この「数クリックで RAG インフラが作れる」というのは大きなメリットだと感じます。自前で RAG を構築しようとすると、ベクトルデータベースの選定から埋め込みモデルの選択、チャンキング戦略の設計など、考慮すべき点が多いですからね。
実際にコードを書いて構築していく過程
ここからは、実際にライブコーディングで AI エージェントを構築していく様子が紹介されました。非常に実践的な内容だったので、ポイントを絞って紹介します。
ステップ 1: UI の骨組みを作る
まず、Aneel さんは VS Code のスニペット機能を使って、Streamlit アプリの基本的な骨組みを作っていきました。「皆さんの前でタイピングする苦痛を与えたくないので、スニペットを使います」と言って、会場からも笑いが起こりました。
この時点では、エージェントの機能はまだ組み込まれておらず、質問を投げてもエラーが返ってくるだけの状態です。
ステップ 2: 基本的なエージェントを作成
次に、agent.py というファイルを作成し、エージェントのコアロジックを書いていきます。
まず、使用する LLM モデルを指定します。今回は Claude モデル(Bedrock 経由)を使用します。Strands SDK は Bedrock 以外の LLM にも対応していますが、今回は Bedrock の LLM を選択しました。
model_id = "claude-model-id"
次に、推論パラメータ(最大トークン数、温度など)を設定し、基本的なエージェントオブジェクトを作成します。
Rafia さんの説明によると、エージェントの作成はわずか数行のコードで完了します。エージェントオブジェクトには、以下の 2 つを渡します。
- モデルオブジェクト(先ほど作成した Claude モデル)
- システムプロンプト
この時点でのシステムプロンプトは非常にシンプルで、「答えを作り上げないでください。分からない場合は分からないと言ってください」という内容です。
この段階では、エージェントは「空白のキャンバス」のような状態で、まだ知能は組み込まれていません。実際に動かしてみると、「あなたの組織の会員データにアクセスできません」という回答が返ってきます。エラーは出ませんが、まだ実用的ではない状態ですね。
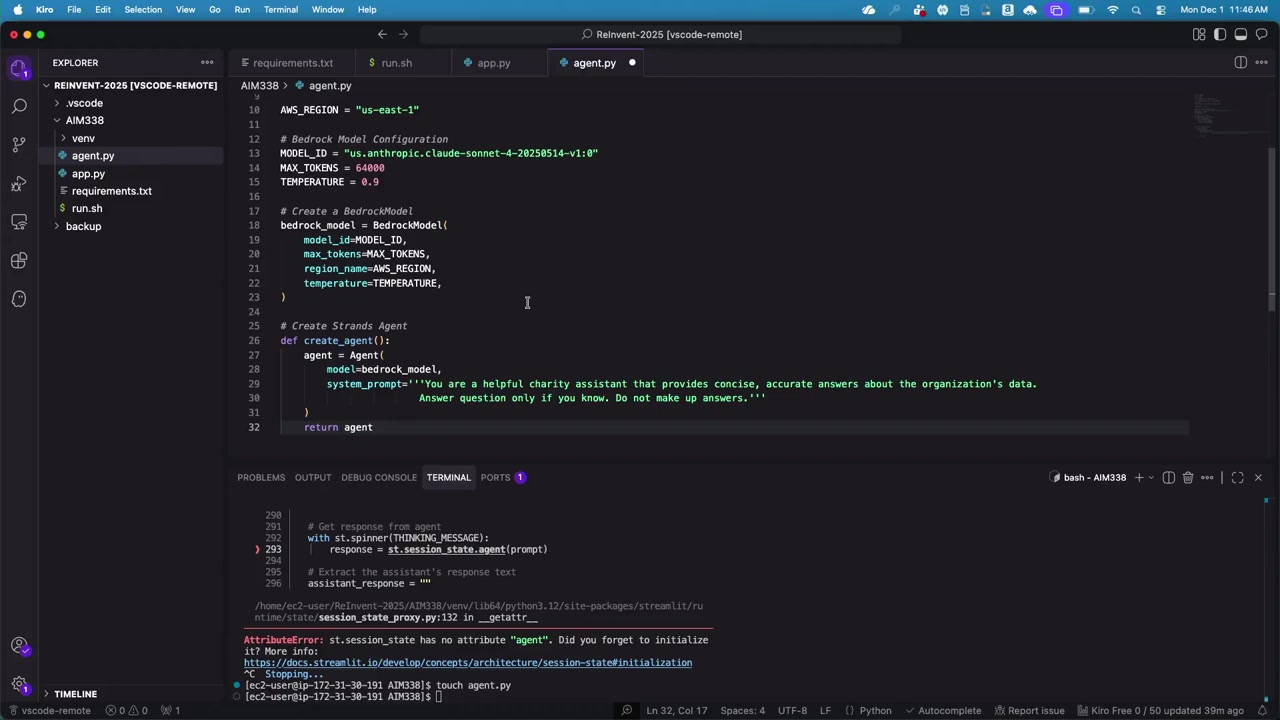
ステップ 3: Knowledge Base からデータを取得するツールを追加
次に、非構造化データにアクセスするためのツールを追加します。
Strands SDK には、カスタムツールを作成できる機能と、すぐに使える既製のツールが用意されています。今回は、retrieve ツールという既製のツールを使用します。
この retrieve ツールは、Bedrock Knowledge Base にクエリを投げるためのツールで、カスタムコードを書く必要はありません。必要なのは、Knowledge Base の ID だけです。
knowledge_base_id = "your-knowledge-base-id"
この ID は、Knowledge Base を作成したときに自動的に発行されるもので、retrieve ツールはこの ID を使ってどの Knowledge Base にアクセスすればよいかを判断します。
また、この情報は環境変数として渡すこともできるので、実際のコードでは環境変数を使って Knowledge Base ID とリージョン情報を渡していました。
ここで質問があり、「OpenSearch など他のベクトルストアにも接続できるのか?」という内容でした。回答としては、「retrieve ツールは Bedrock Knowledge Base 専用だが、Strands のツールはコミュニティ開発されているので、他のデータソース向けのツールも日々追加されている」と答えていました。
この retrieve ツールを追加した状態で再度アプリを起動し、「会員は何人いますか?」という質問を投げると、今度は Knowledge Base から情報を取得して回答が返ってきました。ただし、この時点では非構造化データからの情報なので、正確な数字ではない可能性があります。
正確な数字は、リレーショナルデータベースに保存されています。そこで次のステップでは、構造化データにアクセスするカスタムツールを作成します。
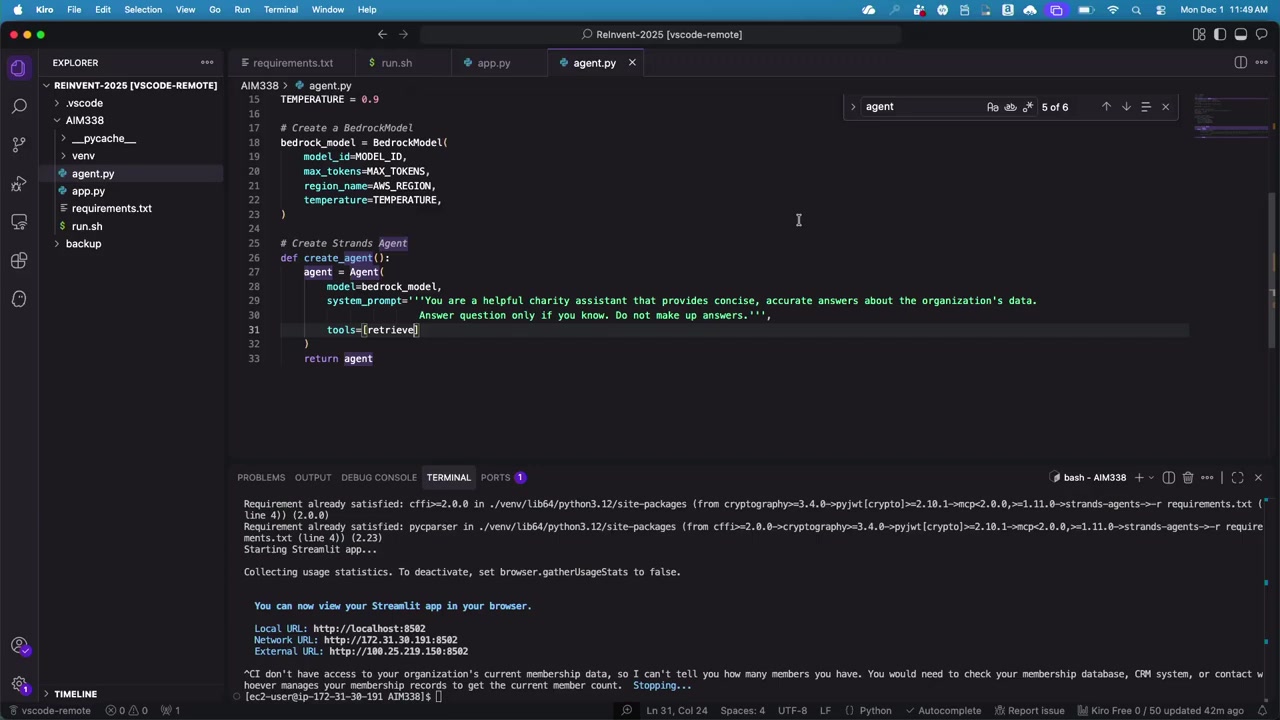
ステップ 4: 構造化データにアクセスするカスタムツールを作成
ここからが、セッションの中でも特に興味深い部分でした。
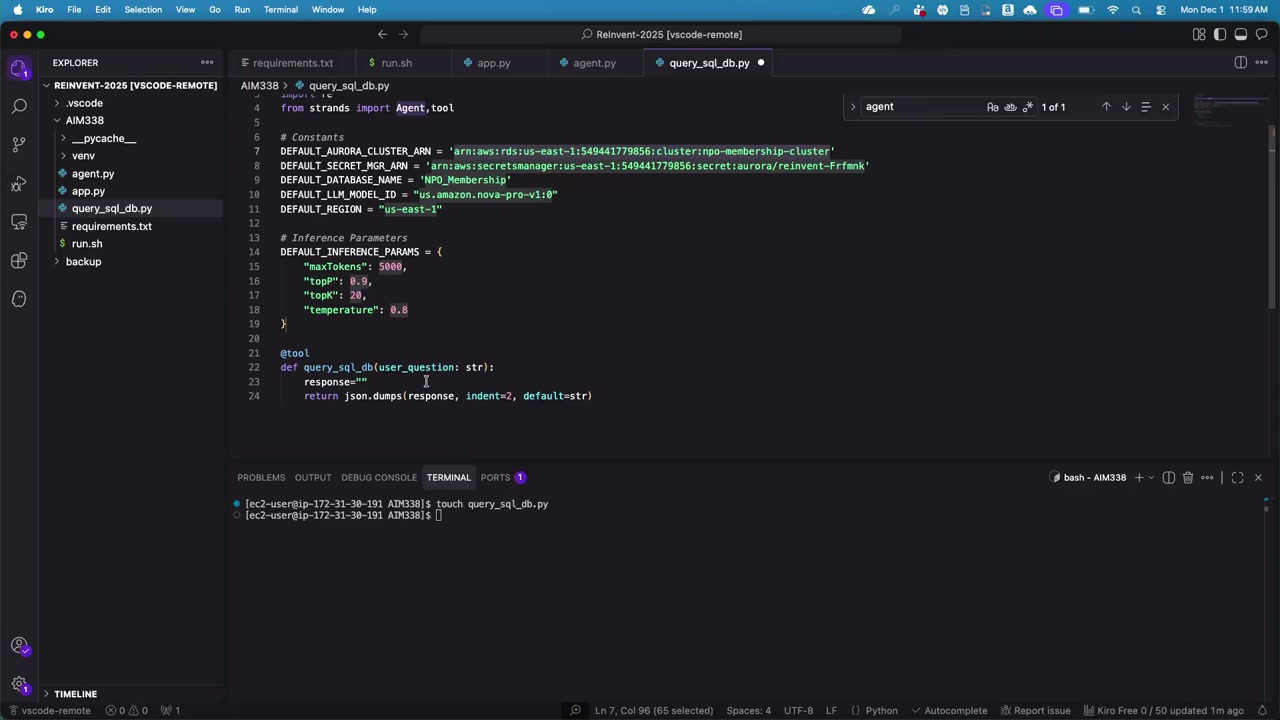
カスタムツールを作成するために、query_SQL_DB.py というファイルを新たに作成します。このツールの役割は、以下の通りです。
- ユーザーのプロンプトを受け取る
- そのプロンプトがリレーショナルデータベースのデータで答えられるか判断する
- 答えられる場合、適切な SQL クエリに変換する
- SQL を実行してデータを取得する
カスタムツールを Strands で使えるようにする方法
Rafia さんが強調したのは、「カスタムツールを Strands で使えるようにするのは非常に簡単」という点です。
必要なのは、関数を作成し、@tool というアノテーションを付けるだけです。
@tool
def query_sql_db(question: str):
# ツールのロジック
pass
このアノテーションを付けることで、Strands はこの関数をツールとして認識し、必要に応じて実行するようになります。
実際のロジックは、サポートクラス(DBStructuredDataAgent)に分けて実装していました。このクラスのコンストラクタでは、以下の情報を渡します。
- Aurora データベースの ARN
- Secrets Manager の ARN(データベースの認証情報を保存)
- データベース名
- 使用する LLM モデル
ここで面白いのは、ツール内で使用する LLM として、エージェント本体とは異なる Nova モデルを使っているという点です。
Rafia さんの説明によると、「エージェント本体は Claude を使い、ツール内では Nova を使う」という設計にしたのは、「複数のモデルを用途に応じて使い分けられることを示すため」です。モデルの評価は AI アプリケーション構築における重要な要素なので、あえて異なるモデルを使ったデモにしました。
実際には、同じモデルを使っても問題ありません。
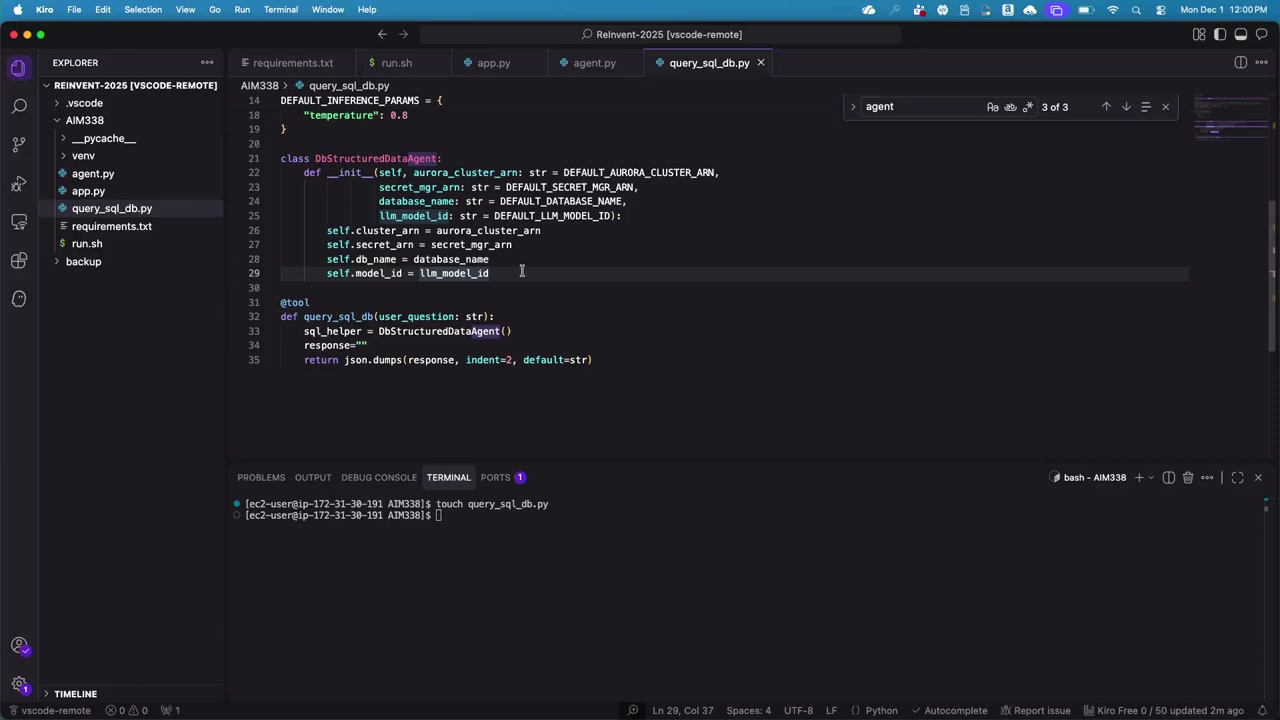
データベーススキーマを LLM に理解させる
カスタムツールの中で最初にやることは、LLM にデータベースのスキーマを理解させることです。
PostgreSQL には、システムテーブルを使ってデータベースのメタデータ(テーブル名、カラム名、データ型など)を取得する仕組みがあります。これを利用して、スキーマ情報を JSON 形式で取得します。
-- PostgreSQL のシステムテーブルからスキーマ情報を取得するクエリ -- (実際のクエリは省略)
このクエリを実行して得られたスキーマ情報を変数に保存します。
ここで質問があり、「スキーマだけで十分なのか、サンプルデータも必要ではないか?」という内容でした。回答としては、「プロンプトの書き方次第で、サンプルデータなしでも十分に機能する」と答えていました。
システムプロンプトの生成
次に、取得したスキーマ情報を使って、システムプロンプトを動的に生成します。
ここが特に工夫されている部分だと感じました。システムプロンプトを手動で書くのではなく、LLM に生成させるという発想です。
具体的には、Nova モデルに対して以下のようなプロンプトを送ります。
「あなたは、データベースクエリ用のシステムプロンプトを作成する AI システムです。このデータベーススキーマ(JSON 形式)を使って、ユーザーの質問に答えるための賢いプロンプトを作成してください。」
こうして生成されたプロンプトには、データベースのスキーマ情報が埋め込まれています。このプロンプトを、次のステップでユーザーの質問と組み合わせて Claude モデルに送ることになります。
この「プロンプトを LLM に生成させる」というアプローチは、非常に興味深いと思いました。スキーマが変更されても、自動的に新しいプロンプトが生成されるので、メンテナンスが楽になりそうですね。
SQL クエリの生成
次に、ユーザーの質問とスキーマ情報を組み合わせて、有効な SQL クエリを生成します。
ここでのポイントは、「すべての質問が SQL で答えられるわけではない」という点です。
例えば、データベースには会員情報やイベント情報が保存されていますが、「フランスの首都は?」という質問には答えられません。LLM は、ユーザーの質問とデータベーススキーマを照らし合わせて、「この質問は SQL で答えられるか?」を判断します。
答えられる場合は、適切な SQL クエリを生成します。生成された SQL は、特定のデリミタ(SQL_START と SQL_END)で囲まれた形で返されます。これにより、LLM の出力から SQL 部分だけを簡単に抽出できます。
SQL の実行
最後に、生成された SQL を実行してデータを取得します。
これは特に複雑なことはなく、Python の psycopg2 などのライブラリを使って PostgreSQL にクエリを投げるだけです。
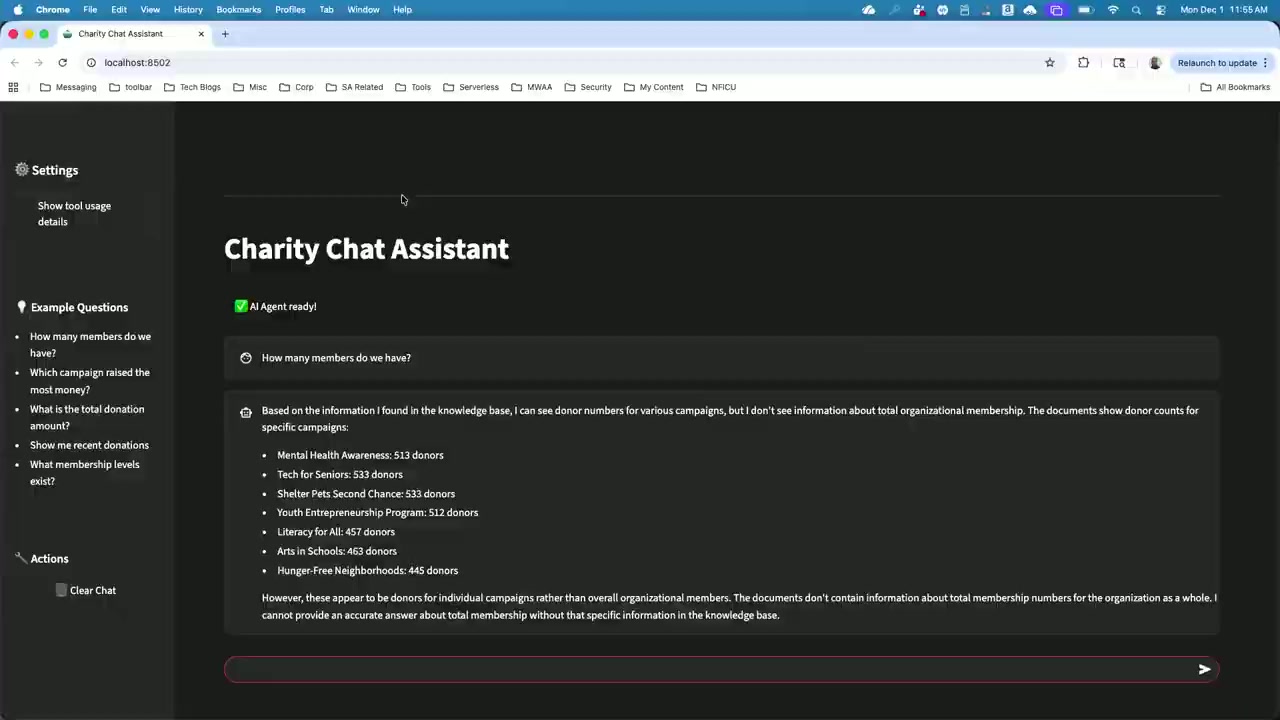
セッションでは、「会員は何人いますか?」という質問を再度投げると、今度は正確な数字(5000 人)が返ってきました。この数字は、Aurora データベースから取得されたものです。
UI には「ツール使用状況」を展開できるトグルがあり、それを見ると「SQL ツールを使ってデータベースにアクセスした」という情報が表示されていました。
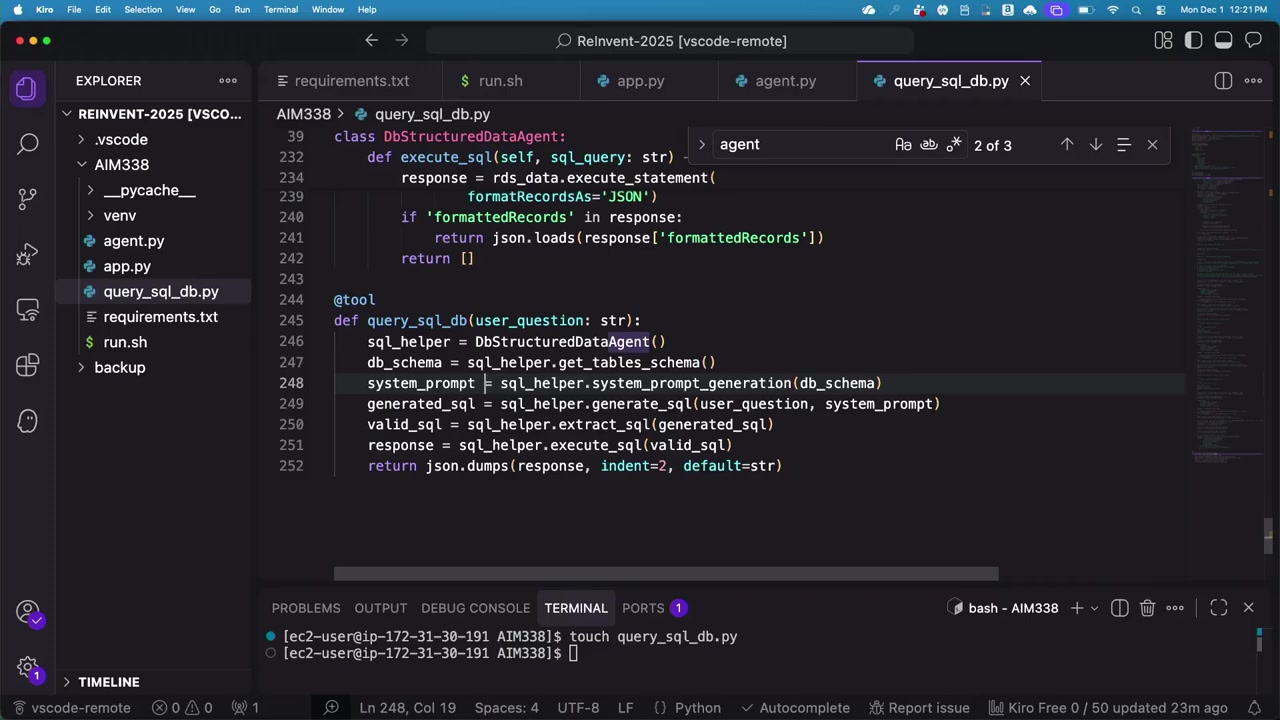
エージェントがデータソースを自動的に選択する仕組み
ここまでで、2 つのツール(retrieve ツールと SQL ツール)が揃いました。次の疑問は、「エージェントはどうやって適切なツールを選ぶのか?」という点です。
セッションでは、「高齢者支援のイベントを実施しましたか?」という質問を投げると、今度は Knowledge Base にアクセスして回答が返ってきました。ツール使用状況を見ると、retrieve ツールが使われていることが分かります。
Rafia さんによると、Claude モデルがツールの選択を行っているとのことです。ユーザーの質問を受け取った Claude は、「この質問にはどのツールが適しているか?」を判断し、適切なツールを呼び出します。
ただし、今回のデモではシステムプロンプトが非常にシンプルだったため、アプリケーション自体がシンプルだったこともあり、LLM が自動的に判断できました。
実際の本番環境では、複数の Knowledge Base や複数のデータベース、さらにはデータ変換やデータディクショナリなど、より複雑な要素が絡んできます。そのような場合には、システムプロンプトが非常に重要になると強調していました。
システムプロンプトに「このツールはこういう時に使う」「このデータソースにはこういう情報がある」といった詳細な情報を含めることで、Claude がより賢くツールを選択できるようになると話していました。
セッションの最後に、より堅牢なシステムプロンプトに置き換える様子も紹介していました。システムプロンプトは、エージェントの「パーソナリティを定義するもの」と表現されており、非常に重要な要素だということが伝わってきました。
セッション中の質疑応答
セッション中には、参加者から多くの質問が飛び交っていました。いくつか印象的だったものを紹介します。
Q: カラム名が暗号的な場合(例: CTY)、どう対処するか?
A: LLM はセマンティックな意味を理解できるため、ある程度は推測できます。例えば、テーブル名が「campaign」でも、ユーザーが「event」という言葉を使った場合、LLM は両者の意味的な関連性を理解して適切な SQL を生成できます。
ただし、カラム名が「column1」「column2」のように完全に意味不明な場合は、データディクショナリ(データの説明書)をプロンプトに含めることで対処できると答えていました。
Q: スキーマに外部キーなどのリレーションシップがある場合、複数のクエリが必要になる場合はどうするか?
A: 今回のデモでは、シンプルなスキーマを使ったため、ほとんどの質問が単一のテーブルで答えられましたが、実際にはリレーションシップ情報もプロンプトに含めることで、JOIN を含む SQL を生成できると答えていました。
Q: スキーマやシステムプロンプトを毎回生成するのは効率的ではないのでは?
A: その通りで、本番環境ではメモリツールを使ってキャッシュすることが推奨されます。
例えば、Amazon Agent Core(AI エージェントを実行するためのサービス)には、メモリ機能が備わっており、スキーマやデータディクショナリのような頻繁に変わらない情報をキャッシュできます。
今回のデモは「理解しやすさ」を優先したため、本番環境向けの最適化は省略されていましたが、実際に運用する際にはこのようなキャッシュ機能を活用すべきと話していました。
デプロイメントの選択肢
セッションの最後に、このアプリケーションを AWS 上にデプロイする場合の選択肢が紹介されました。
- AWS Lambda: サーバーレスで実行
- ECS / EKS: コンテナサービスで実行
- Agent Core: 生成 AI アプリケーション専用のランタイム(最新のサービス)
今回のデモでは、EC2 インスタンス上で実行していましたが、理論的にはどの選択肢でもデプロイ可能です。Python で書かれているため、基本的にはどのコンピューティング環境でも動かせると話していました。
まとめ
このセッションでは、構造化データと非構造化データを AI エージェントで統合的にアクセスする方法を、実際にコードを書きながら学ぶことができました。
特に印象的だったのは、以下の 3 点です。
- Strands SDK を使えば、わずか数行でエージェントが構築できること
- カスタムツールの作成が非常にシンプル(
@toolアノテーションを付けるだけ) - 複数の LLM を用途に応じて使い分けられること
また、システムプロンプトの重要性についても改めて認識しました。エージェントの「パーソナリティ」を定義し、適切なツールを選択させるためには、詳細で明確なシステムプロンプトが不可欠です。
個人的には、「プロンプトを LLM に生成させる」というアプローチが非常に興味深かったです。スキーマ情報を動的に取得し、それを元にプロンプトを自動生成することで、メンテナンス性が高まると感じました。
このセッションで紹介された手法は、企業内の様々なデータソースを統合的に活用したいと考えている方にとって、非常に参考になると思います。特に、RAG システムと従来のデータベースを組み合わせたいというニーズは多いはずなので、実践的なアプローチとして試してみる価値があるのではないでしょうか。
