
はじめに
こんにちは!そしてこんばんは
クラウドインテグレーション事業部の大嵩です。
今回はAWS Systems Manager Patch ManagerとBacklogを組み合わせて管理表を作ってみました!
弊社とお客様における運用効率化が目的です。
手動でWikiを更新していくのはかなりの手間ですよね。
そこで自動更新の仕組みも検証します!
また今回は下記の後編となります!
ぜひ前編からご覧ください!!

今回の構成
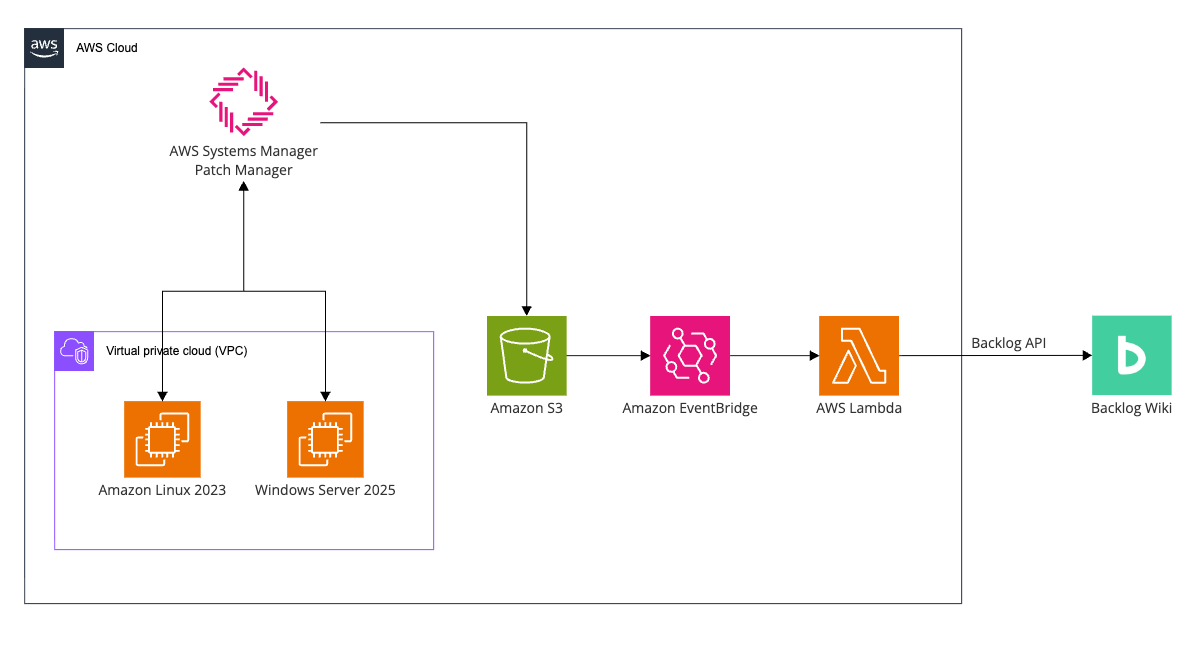
本題のBacklog Wikiへの転送方法を考える
S3へのエクスポートまでできました。
ここからは運用効率化のためにBacklog Wikiへの転送方法を考えてみます。
AWS Lambdaを使うことは頭にありました。
問題はどう使うかというところです。
はじめは下記のように考えていました。
- S3のイベント通知でPut Objectにて Lambdaを発火
- LambdaからWikiを新規作成
- 2度目以降はWikiを更新する
これだと2が1回のみの実行になります。
それよりはWiki自体は手動で作成してそれを更新するプログラムとするほうが良いと思いました。
S3イベント通知で直にLambdaをトリガーする方法もあります。
しかしEventBridgeにしたほうが複数サービスの組み合わせで拡張性が高いです。
そこで下記に変更しました。
- S3のイベント通知をEventBridgeへ転送。ルールにてPutObjectをトリガーとしターゲットにLambdaを指定。
- LambdaからWikiを更新
Lambda を作る
ということでまずはLambdaを作りましょう!
私はプログラミングが得意ではないのでKiroさんに助けてもらいます。
経験のあるPythonで書いてもらいました。
ソースコード(長いので折りたたみ)
import json
import boto3
import csv
import io
import urllib.request
import urllib.parse
from datetime import datetime, timezone, timedelta
import os
# JST タイムゾーン
JST = timezone(timedelta(hours=9))
def get_backlog_api_key(ssm_parameter_name):
"""
Systems Manager Parameter StoreからBacklog APIキーを取得する
"""
ssm = boto3.client('ssm')
try:
print(f"Getting API key from Parameter Store: {ssm_parameter_name}")
response = ssm.get_parameter(
Name=ssm_parameter_name,
WithDecryption=True # SecureStringの場合は復号化
)
api_key = response['Parameter']['Value']
# デバッグ用: APIキーの先頭と末尾の一部を表示(セキュリティのため全体は表示しない)
print(f"API key retrieved: {api_key[:4]}...{api_key[-4:]} (length: {len(api_key)})")
return api_key
except Exception as e:
print(f"Error getting API key from Parameter Store: {e}")
raise
def get_csv_from_s3(bucket, key):
"""
S3からCSVファイルを取得する
"""
s3 = boto3.client('s3')
try:
response = s3.get_object(Bucket=bucket, Key=key)
csv_content = response['Body'].read().decode('utf-8')
return csv_content
except Exception as e:
print(f"Error getting CSV from S3: {e}")
raise
def parse_instance_summary_csv(csv_content):
"""
Patch Managerのインスタンスサマリー CSV を解析する
CSVは1つのセクションで構成:
- 1行目: ヘッダー
- 2行目以降: 各インスタンスのサマリーデータ
戻り値: インスタンスサマリーのリスト
"""
instances = []
reader = csv.DictReader(io.StringIO(csv_content))
for row in reader:
# 空行をスキップ
if not row.get('Instance ID'):
continue
instances.append(row)
print(f"Parsed {len(instances)} instances from CSV")
return instances
def detect_os_from_platform(platform_name):
"""
Platform name からOS種別を判定する
判定ルール:
- 'Windows' が含まれる → windows
- それ以外(Amazon Linux, Red Hat, Ubuntu等) → linux
"""
if not platform_name:
return None
if 'Windows' in platform_name:
return 'windows'
else:
return 'linux'
def get_instance_patches(instance_id):
"""
SSM APIでインスタンスのパッチ詳細を取得する
describe_instance_patches APIを使用して、
指定インスタンスのパッチ一覧を取得する
"""
ssm = boto3.client('ssm')
patches = []
next_token = None
try:
while True:
params = {
'InstanceId': instance_id,
'MaxResults': 50
}
if next_token:
params['NextToken'] = next_token
response = ssm.describe_instance_patches(**params)
patches.extend(response.get('Patches', []))
next_token = response.get('NextToken')
if not next_token:
break
print(f" Retrieved {len(patches)} patches for {instance_id}")
return patches
except Exception as e:
print(f" Error getting patches for {instance_id}: {e}")
return []
def filter_missing_patches(patches):
"""
Missingステータスのパッチのみをフィルタする
"""
return [p for p in patches if p.get('State') == 'Missing']
def convert_summaries_to_backlog_table(summaries):
"""
複数インスタンスのサマリーをBacklog Wiki形式の表に変換する
"""
if not summaries:
return "データがありません。"
# 表示するカラムを定義(実際のCSVカラム名に合わせる)
display_columns = [
('Instance ID', 'インスタンスID'),
('Instance name', 'インスタンス名'),
('Instance IP', 'IP'),
('Platform name', 'プラットフォーム'),
('Compliance status', 'コンプライアンス状態'),
('Compliance severity', '重要度'),
('Noncompliant Critical severity patch count', 'Critical'),
('Noncompliant High severity patch count', 'High'),
('Noncompliant Medium severity patch count', 'Medium'),
('Noncompliant Low severity patch count', 'Low'),
]
# ヘッダー行を作成
header_row = '| ' + ' | '.join([jp_name for _, jp_name in display_columns]) + ' |h'
# 各インスタンスのデータ行を作成
data_rows = []
for summary in summaries:
cells = []
for en_name, _ in display_columns:
value = summary.get(en_name, '-')
# コンプライアンス状態に応じて色付け
if en_name == 'Compliance status':
if value == 'COMPLIANT':
value = '&color(green){COMPLIANT}'
elif value == 'NON_COMPLIANT':
value = '&color(red){NON_COMPLIANT}'
elif not value:
value = '&color(gray){未スキャン}'
# プラットフォーム名にバージョンを結合
if en_name == 'Platform name':
platform_version = summary.get('Platform version', '')
if platform_version:
if 'Windows' in str(value):
# Windowsの場合はビルド番号なので括弧付きで表示
value = f"{value} ({platform_version})"
else:
# Linuxの場合はそのまま結合
value = f"{value} {platform_version}"
cells.append(str(value) if value else '-')
data_rows.append('| ' + ' | '.join(cells) + ' |')
return header_row + '\n' + '\n'.join(data_rows)
def convert_patches_to_backlog_table(patches):
"""
パッチ詳細をBacklog Wiki形式の表に変換する
SSM APIから取得したパッチ情報を変換
"""
if not patches:
return "更新対象のパッチはありません。"
# 表示するカラムを定義(SSM APIのレスポンスに合わせる)
display_columns = [
('Title', 'パッチ名'),
('KBId', 'KB/Patch ID'),
('State', '状態'),
('Severity', '重要度'),
('Classification', '分類'),
('CVEIds', 'CVE ID'),
]
# ヘッダー行を作成
header_row = '| ' + ' | '.join([jp_name for _, jp_name in display_columns]) + ' |h'
# データ行を作成
data_rows = []
for patch in patches:
cells = []
for en_name, _ in display_columns:
value = patch.get(en_name, '-')
# CVEIdsはリストなのでカンマ区切りに変換
if en_name == 'CVEIds' and isinstance(value, list):
value = ', '.join(value) if value else '-'
# 状態に応じて色付け
if en_name == 'State':
if value == 'Missing':
value = '&color(red){Missing}'
elif value == 'Installed':
value = '&color(green){Installed}'
elif value == 'InstalledOther':
value = '&color(blue){InstalledOther}'
# 重要度に応じて色付け
if en_name == 'Severity':
if value == 'Critical':
value = '&color(red){Critical}'
elif value == 'Important':
value = '&color(orange){Important}'
cells.append(str(value) if value else '-')
data_rows.append('| ' + ' | '.join(cells) + ' |')
return header_row + '\n' + '\n'.join(data_rows)
def create_wiki_content(instances_data, os_type, csv_file):
"""
Wikiページのコンテンツ全体を作成する
instances_data: [{'summary': {...}, 'patches': [...]}, ...]
構成:
- 目次(#contents)
- 全インスタンスのサマリー表
- NON_COMPLIANTインスタンスのみパッチ詳細を表示
"""
now = datetime.now(JST).strftime('%Y-%m-%d %H:%M:%S JST')
# サマリー一覧を抽出
summaries = [inst['summary'] for inst in instances_data]
# 統計情報を計算
total_count = len(instances_data)
compliant_count = sum(1 for inst in instances_data if inst['summary'].get('Compliance status') == 'COMPLIANT')
non_compliant_count = sum(1 for inst in instances_data if inst['summary'].get('Compliance status') == 'NON_COMPLIANT')
unscanned_count = total_count - compliant_count - non_compliant_count
# パッチ詳細セクションを生成(NON_COMPLIANTのインスタンスのみ)
patch_sections = []
for inst in instances_data:
summary = inst['summary']
patches = inst.get('patches', [])
compliance_status = summary.get('Compliance status', '')
# NON_COMPLIANTのインスタンスのみ詳細を表示
if compliance_status != 'NON_COMPLIANT':
continue
instance_name = summary.get('Instance name', 'Unknown')
instance_id = summary.get('Instance ID', 'Unknown')
# Missingのパッチのみフィルタ
missing_patches = filter_missing_patches(patches)
section_content = f"""*** {instance_name}({instance_id})
未適用パッチ: {len(missing_patches)}件
{convert_patches_to_backlog_table(missing_patches)}"""
patch_sections.append(section_content)
# OS種別の表示名
os_display_name = 'Linux' if os_type == 'linux' else 'Windows'
# パッチ詳細セクションがない場合のメッセージ
if patch_sections:
patch_detail_content = '\n\n'.join(patch_sections)
else:
patch_detail_content = "すべてのインスタンスがコンプライアンス準拠状態です。未適用のパッチはありません。"
content = f"""* Patch Manager コンプライアンスレポート({os_display_name})
#contents
** 概要
このページはAWS Systems Manager Patch Managerのパッチコンプライアンスレポートを自動更新しています。
- 最終更新日時: {now}
- 対象インスタンス数: {total_count}台
-- &color(green){{COMPLIANT}}: {compliant_count}台
-- &color(red){{NON_COMPLIANT}}: {non_compliant_count}台
-- 未スキャン: {unscanned_count}台
- ソースファイル: {csv_file}
** インスタンス一覧
{convert_summaries_to_backlog_table(summaries)}
** パッチ詳細(NON_COMPLIANTのみ)
{patch_detail_content}
** 凡例
*** コンプライアンス状態
- &color(green){{COMPLIANT}}: パッチが適用されており、コンプライアンス準拠
- &color(red){{NON_COMPLIANT}}: 未適用のパッチがあり、コンプライアンス非準拠
- &color(gray){{未スキャン}}: パッチベースラインが設定されていない、またはスキャン未実施
- Critical/High/Medium/Low: 各重要度の未適用(Missing)パッチ数
*** パッチ状態
- &color(red){{Missing}}: 未適用のパッチ(適用が必要)
- &color(green){{Installed}}: 正常にインストール済みのパッチ
- &color(blue){{InstalledOther}}: ベースライン外でインストールされたパッチ
- NotApplicable: このインスタンスには適用対象外のパッチ
*** パッチ重要度
- &color(red){{Critical}}: 緊急度が最も高いパッチ
- &color(orange){{Important}}: 重要なセキュリティパッチ
- Moderate: 中程度の重要度
- Low: 低い重要度
** 更新履歴
- {now}: 自動更新(Lambda関数による)
"""
return content
def update_backlog_wiki(api_key, backlog_host, wiki_id, content):
"""
Backlog WikiページをAPIで更新する
"""
# APIキーはクエリパラメータに含める
url = f"https://{backlog_host}/api/v2/wikis/{wiki_id}?apiKey={api_key}"
print(f"Updating wiki ID: {wiki_id}")
params = {
'content': content
}
data = urllib.parse.urlencode(params).encode('utf-8')
req = urllib.request.Request(url, data=data, method='PATCH')
req.add_header('Content-Type', 'application/x-www-form-urlencoded')
try:
with urllib.request.urlopen(req) as response:
result = json.loads(response.read().decode('utf-8'))
print(f"Wiki updated successfully: {result.get('name')}")
return result
except urllib.error.HTTPError as e:
error_body = e.read().decode('utf-8')
print(f"Error updating wiki: {e.code} - {error_body}")
print(f"Wiki ID: {wiki_id}")
raise
def get_latest_csv_from_s3(bucket, prefix):
"""
S3から最新のCSVファイルを1つだけ取得する
LastModifiedが最新のCSVファイルを返す。
コンプライアンスレポートが複数回エクスポートされて
サフィックスが付いた場合でも、最新のものだけを処理する。
"""
s3 = boto3.client('s3')
try:
response = s3.list_objects_v2(
Bucket=bucket,
Prefix=prefix
)
if 'Contents' not in response:
raise Exception(f"No CSV files found in s3://{bucket}/{prefix}")
# CSVファイルのみをフィルタし、LastModifiedでソート
csv_objects = [
obj for obj in response['Contents']
if obj['Key'].endswith('.csv')
]
if not csv_objects:
raise Exception(f"No CSV files found in s3://{bucket}/{prefix}")
# LastModifiedで降順ソートして最新のものを取得
csv_objects.sort(key=lambda x: x['LastModified'], reverse=True)
latest_csv = csv_objects[0]
print(f"Found {len(csv_objects)} CSV files, using latest: {latest_csv['Key']} (LastModified: {latest_csv['LastModified']})")
return latest_csv['Key']
except Exception as e:
print(f"Error listing S3 objects: {e}")
raise
def get_wiki_id_for_os(os_type):
"""
OS種別に対応するWiki IDを環境変数から取得する
環境変数:
- BACKLOG_WIKI_ID_LINUX: Linux用WikiページID
- BACKLOG_WIKI_ID_WINDOWS: Windows用WikiページID
"""
if os_type == 'linux':
wiki_id = os.environ.get('BACKLOG_WIKI_ID_LINUX')
if wiki_id:
return wiki_id
raise Exception("BACKLOG_WIKI_ID_LINUX environment variable is required for Linux instances")
elif os_type == 'windows':
wiki_id = os.environ.get('BACKLOG_WIKI_ID_WINDOWS')
if wiki_id:
return wiki_id
raise Exception("BACKLOG_WIKI_ID_WINDOWS environment variable is required for Windows instances")
return None
def process_instances_by_os(api_key, backlog_host, instances, csv_file):
"""
インスタンスをOS種別ごとにグループ化して処理し、Wikiを更新する
1. Platform nameからOS種別を判定
2. NON_COMPLIANTのインスタンスのみパッチ詳細をAPIで取得
3. OS別にWikiを更新
"""
# OS種別ごとにインスタンスをグループ化
os_groups = {
'linux': [],
'windows': []
}
for instance in instances:
platform_name = instance.get('Platform name', '')
os_type = detect_os_from_platform(platform_name)
if os_type is None:
print(f"Skipping instance {instance.get('Instance ID')}: OS type not detected from '{platform_name}'")
continue
os_groups[os_type].append(instance)
results = []
# OS種別ごとに処理
for os_type, group_instances in os_groups.items():
if not group_instances:
print(f"No {os_type} instances found")
continue
wiki_id = get_wiki_id_for_os(os_type)
print(f"Processing {len(group_instances)} {os_type} instances -> Wiki ID: {wiki_id}")
# 各インスタンスのデータを準備
instances_data = []
for instance in group_instances:
instance_data = {
'summary': instance,
'patches': []
}
# NON_COMPLIANTの場合のみパッチ詳細を取得
compliance_status = instance.get('Compliance status', '')
if compliance_status == 'NON_COMPLIANT':
instance_id = instance.get('Instance ID')
print(f" Fetching patches for NON_COMPLIANT instance: {instance.get('Instance name')} ({instance_id})")
patches = get_instance_patches(instance_id)
instance_data['patches'] = patches
instances_data.append(instance_data)
# Wikiコンテンツを生成
wiki_content = create_wiki_content(instances_data, os_type, csv_file)
# Backlog Wikiを更新
try:
result = update_backlog_wiki(api_key, backlog_host, wiki_id, wiki_content)
results.append({
'os_type': os_type,
'wiki_id': result.get('id'),
'wiki_name': result.get('name'),
'instances_count': len(group_instances),
'non_compliant_count': sum(1 for inst in group_instances if inst.get('Compliance status') == 'NON_COMPLIANT')
})
except Exception as e:
print(f"Error updating {os_type} wiki: {e}")
results.append({
'os_type': os_type,
'error': str(e),
'instances_count': len(group_instances)
})
return results
def lambda_handler(event, context):
"""
Lambda関数のメインハンドラー
S3バケット内の最新CSVファイル(インスタンスサマリー)を処理し、
Platform name からOS種別を判定して対応するWikiページを更新する
- 最新のCSVファイル(LastModified基準)のみを処理
- 1つのCSVに複数インスタンス(Linux/Windows混在)対応
- NON_COMPLIANTのインスタンスのみSSM APIでパッチ詳細を取得
- OS別にWikiを更新(Linux用、Windows用)
必要な環境変数:
- BACKLOG_HOST: Backlogのホスト名(例: aws-plus.backlog.jp)
- BACKLOG_WIKI_ID_LINUX: Linux用WikiページID
- BACKLOG_WIKI_ID_WINDOWS: Windows用WikiページID
- SSM_PARAMETER_NAME: APIキーのパラメータストアパス
- S3_BUCKET: CSVが格納されているS3バケット名
- S3_KEY_PREFIX: CSVのプレフィックス(オプション)
"""
print(f"Event received: {json.dumps(event)}")
# 環境変数を取得
backlog_host = os.environ.get('BACKLOG_HOST')
ssm_parameter_name = os.environ.get('SSM_PARAMETER_NAME')
s3_bucket = os.environ.get('S3_BUCKET')
s3_key_prefix = os.environ.get('S3_KEY_PREFIX', '')
# 必須環境変数のチェック
if not backlog_host:
raise Exception("BACKLOG_HOST environment variable is required")
if not ssm_parameter_name:
raise Exception("SSM_PARAMETER_NAME environment variable is required")
if not s3_bucket:
raise Exception("S3_BUCKET environment variable is required")
try:
# 1. Backlog APIキーを取得
api_key = get_backlog_api_key(ssm_parameter_name)
print("Successfully retrieved Backlog API key from Parameter Store")
# 2. S3から最新のCSVファイルを取得
csv_key = get_latest_csv_from_s3(s3_bucket, s3_key_prefix)
csv_filename = csv_key.split('/')[-1]
# 3. CSVを取得してパース
print(f"\nProcessing CSV: {csv_key}")
csv_content = get_csv_from_s3(s3_bucket, csv_key)
instances = parse_instance_summary_csv(csv_content)
if not instances:
raise Exception(f"No instances found in {csv_key}")
# 4. OS種別ごとに処理してWikiを更新
results = process_instances_by_os(api_key, backlog_host, instances, csv_filename)
return {
'statusCode': 200,
'body': json.dumps({
'message': f'Processed {csv_filename}, updated {len(results)} wiki pages',
'csv_file': csv_filename,
'results': results
}, ensure_ascii=False)
}
except Exception as e:
print(f"Error in lambda_handler: {e}")
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e)
}, ensure_ascii=False)
}
プログラムの説明
処理の流れ
S3 (CSV) → Lambda → SSM API → Backlog Wiki
- S3バケットからPatch ManagerのCSVを取得
- 「Platform name」でLinux/Windowsを自動判定
- NON_COMPLIANTのインスタンスだけSSM APIでパッチ詳細を取得
- OS別にBacklog Wikiを更新
対応しているCSV形式
Patch Managerからエクスポートされる標準的なインスタンスサマリーCSVです。
1ファイルに複数インスタンスが入っていても自動で振り分けます。
LinuxとWindows混在もOKです。
Index,Instance ID,Instance name,Platform name,Compliance status,... 0,i-001,server-linux-01,Amazon Linux,COMPLIANT,... 1,i-002,server-windows-01,Microsoft Windows Server 2022,NON_COMPLIANT,... 2,i-003,server-linux-02,Red Hat Enterprise Linux,NON_COMPLIANT,...
ファイル名は何でもOKです。
「Platform name」の値で判定するので名前に「-linux-」とか付けなくて大丈夫です!
また常に最新のCSVファイルを取得するようにしています。
OS判定のロジック
Platform nameにWindowsが含まれるかどうかで判定します。
def detect_os_from_platform(platform_name):
if 'Windows' in platform_name:
return 'windows'
else:
return 'linux'
Amazon LinuxやRed Hat、Ubuntuなど Windows以外は全部Linuxとして扱います。
パッチ詳細の取得
CSVにはインスタンスのサマリー情報しか入っていません。
パッチの詳細はSSM APIで取得します。
全インスタンスのパッチを取得すると時間がかかります。
そこでNON_COMPLIANTのインスタンスだけ取得するようにしています。
if compliance_status == 'NON_COMPLIANT':
patches = get_instance_patches(instance_id)
内部では「ssm:DescribeInstancePatches」を呼び出しています。
Wikiの出力イメージ
目次付きで見やすく整形されます。
* Patch Manager コンプライアンスレポート(Linux) #contents ← 自動で目次が生成される ** 概要 - 対象インスタンス数: 12台 - COMPLIANT: 10台 - NON_COMPLIANT: 2台 ** インスタンス一覧 (全インスタンスのサマリー表) ** パッチ詳細(NON_COMPLIANTのみ) *** otake-test-ansible(i-0a8f35732bd2690f8) 未適用パッチ: 21件 (パッチ詳細の表) ** 凡例 ...
COMPLIANTのインスタンスはサマリー表にだけ表示されます。
パッチ詳細セクションにはNON_COMPLIANTのインスタンスだけが出ます。
100台あっても問題のあるインスタンスだけピックアップされるので見やすいです!
Backlog Wiki記法への変換
コンプライアンス状態やパッチ重要度に応じて色付けしています。
if value == 'COMPLIANT':
value = '&color(green){COMPLIANT}'
elif value == 'NON_COMPLIANT':
value = '&color(red){NON_COMPLIANT}'
パッチ状態も同様です。
Missingは赤でInstalledは緑で表示します。
APIキーの管理
Backlog APIキーはSystems Manager Parameter StoreにSecureStringで保存します。
Lambda実行時に取得して使う形です。
def get_backlog_api_key(ssm_parameter_name):
ssm = boto3.client('ssm')
response = ssm.get_parameter(
Name=ssm_parameter_name,
WithDecryption=True
)
return response['Parameter']['Value']
必要な環境変数
| 環境変数 | 説明 |
|---|---|
| BACKLOG_HOST | Backlogのホスト名(例: xxx.backlog.jp) |
| BACKLOG_WIKI_ID_LINUX | Linux用WikiページのID |
| BACKLOG_WIKI_ID_WINDOWS | Windows用WikiページのID |
| SSM_PARAMETER_NAME | APIキーのParameter Storeパス |
| S3_BUCKET | CSVが格納されているS3バケット名 |
| S3_KEY_PREFIX | CSVのプレフィックス(オプション) |
必要なIAM権限
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "ssm:GetParameter",
"Resource": "arn:aws:ssm:*:*:parameter/your/parameter/path"
},
{
"Effect": "Allow",
"Action": "ssm:DescribeInstancePatches",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
「ssm:DescribeInstancePatches」がないとパッチ詳細が取得できません。
忘れずに追加しましょう!
実際に動かしてみる
ではLambdaが動くか実際に試してみます!
まずは環境変数を確認しておきます。
問題ないですね!
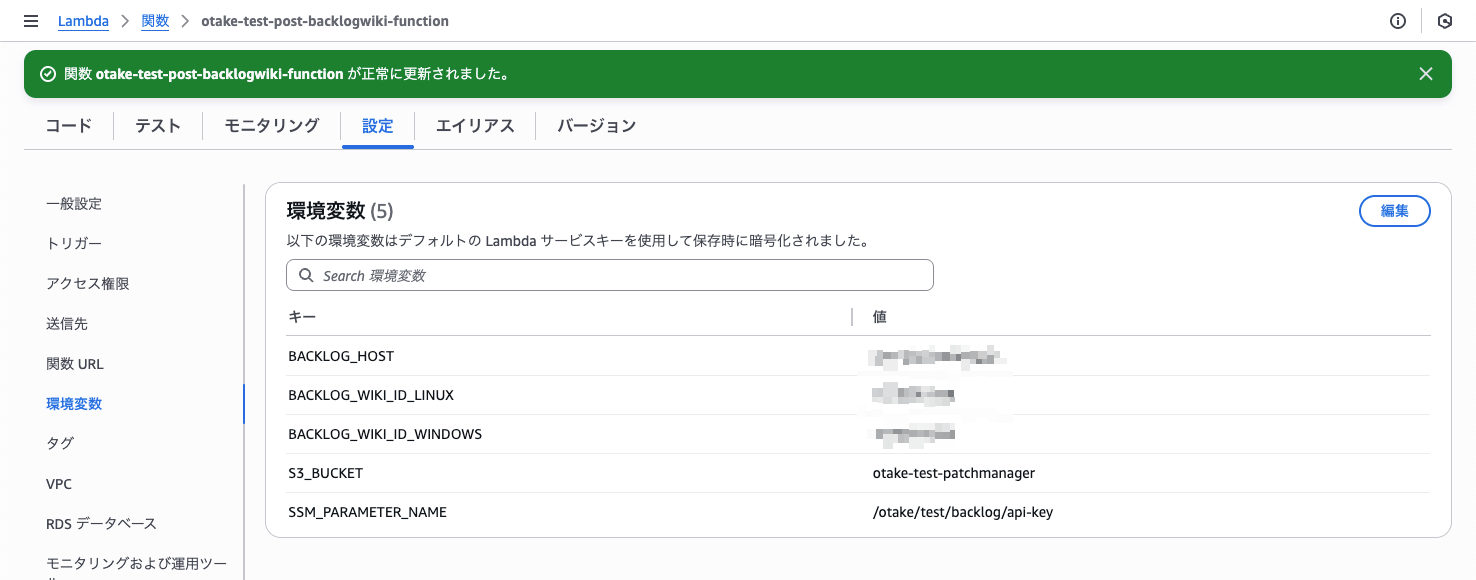
SSMパラメータストアも問題なし。
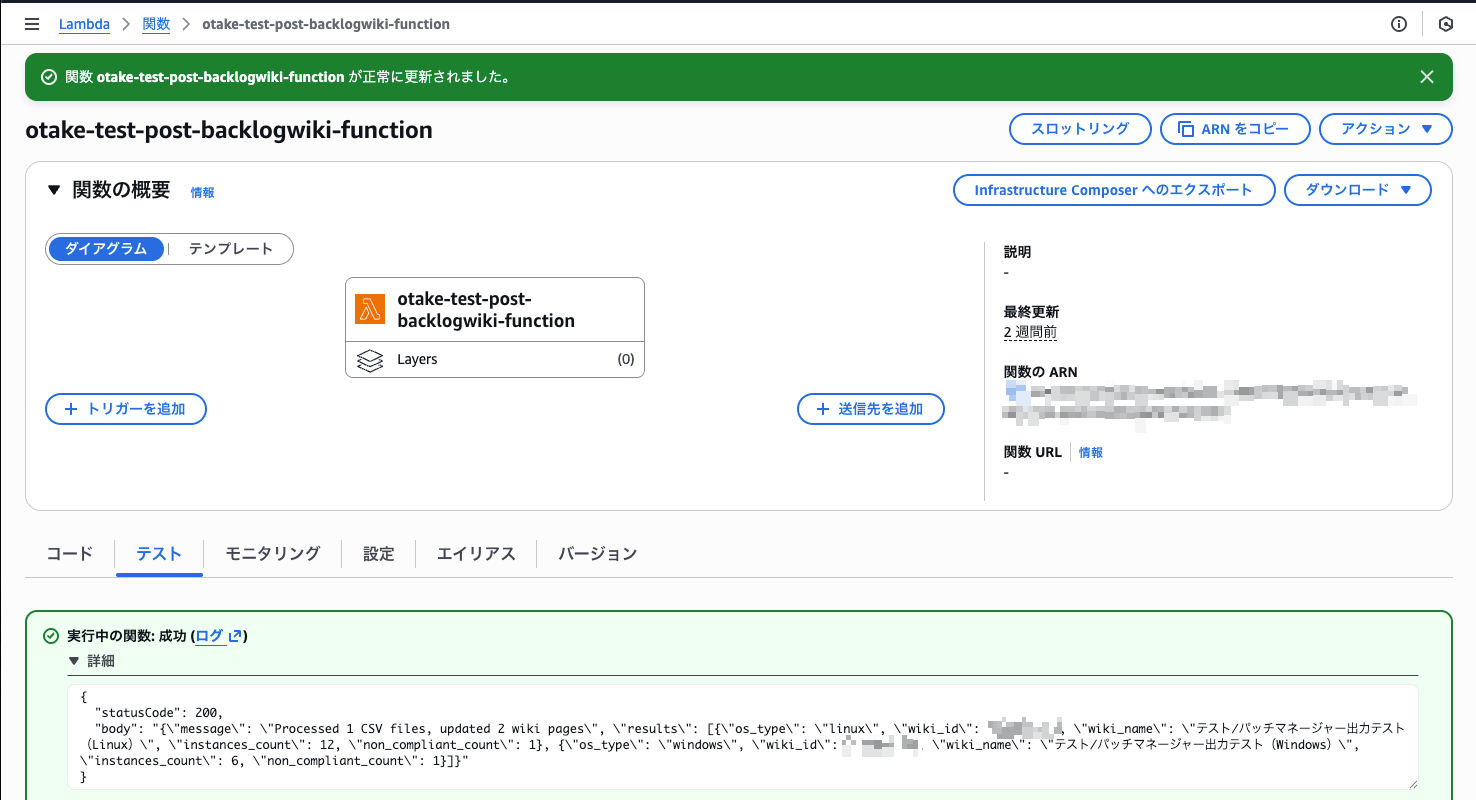
テスト実行!!
無事に成功しました!
ありがとうKiro!!!
Wikiを確認
見てみたらしっかり思った通りの出力になっていました。
実装のスピード感に驚いています。
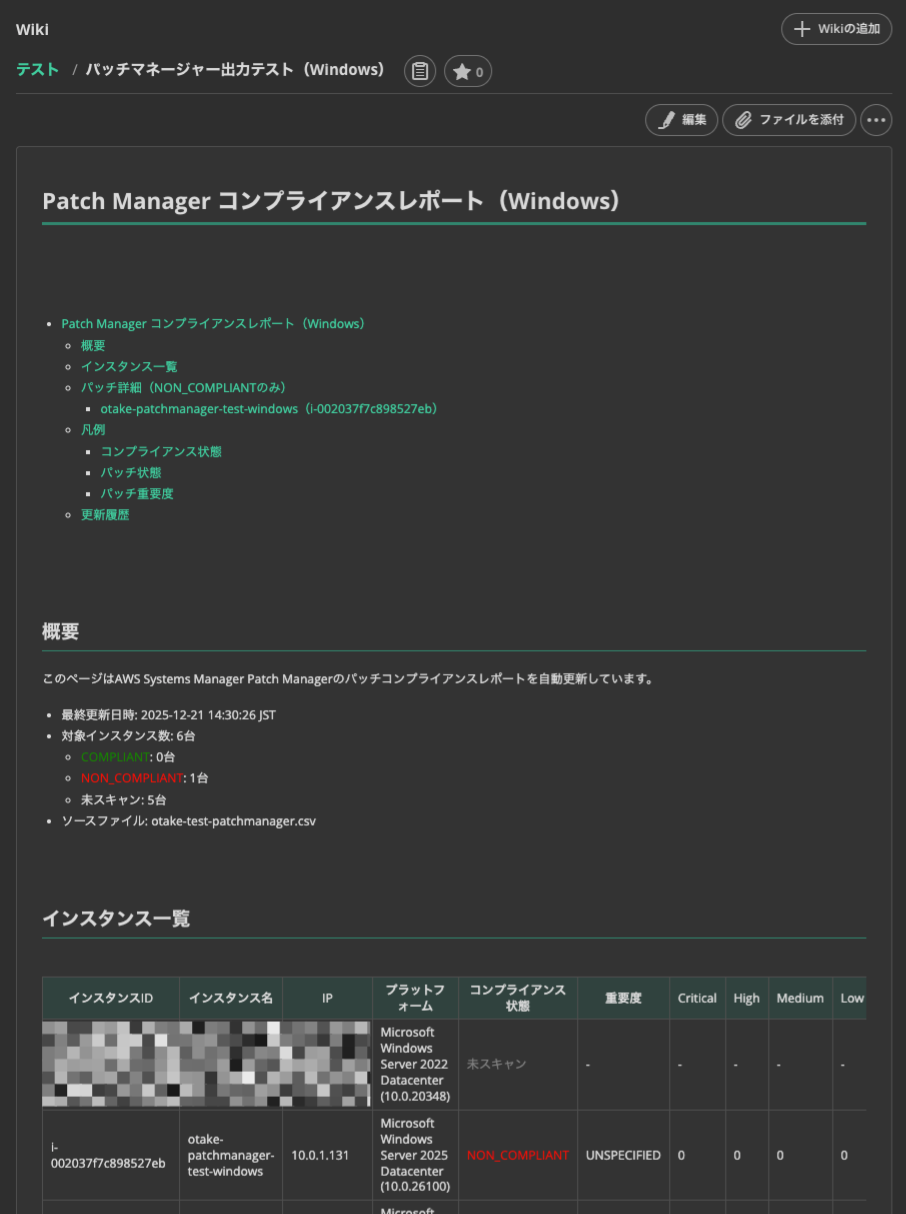
Windows
まずはWindowsの結果を見てみましょう!
パッチ名とKBも出力されるので管理が容易ですね!
お客様もRDPしている可能性があります。
セッションの取り合いにならないのは非常にありがたいです。

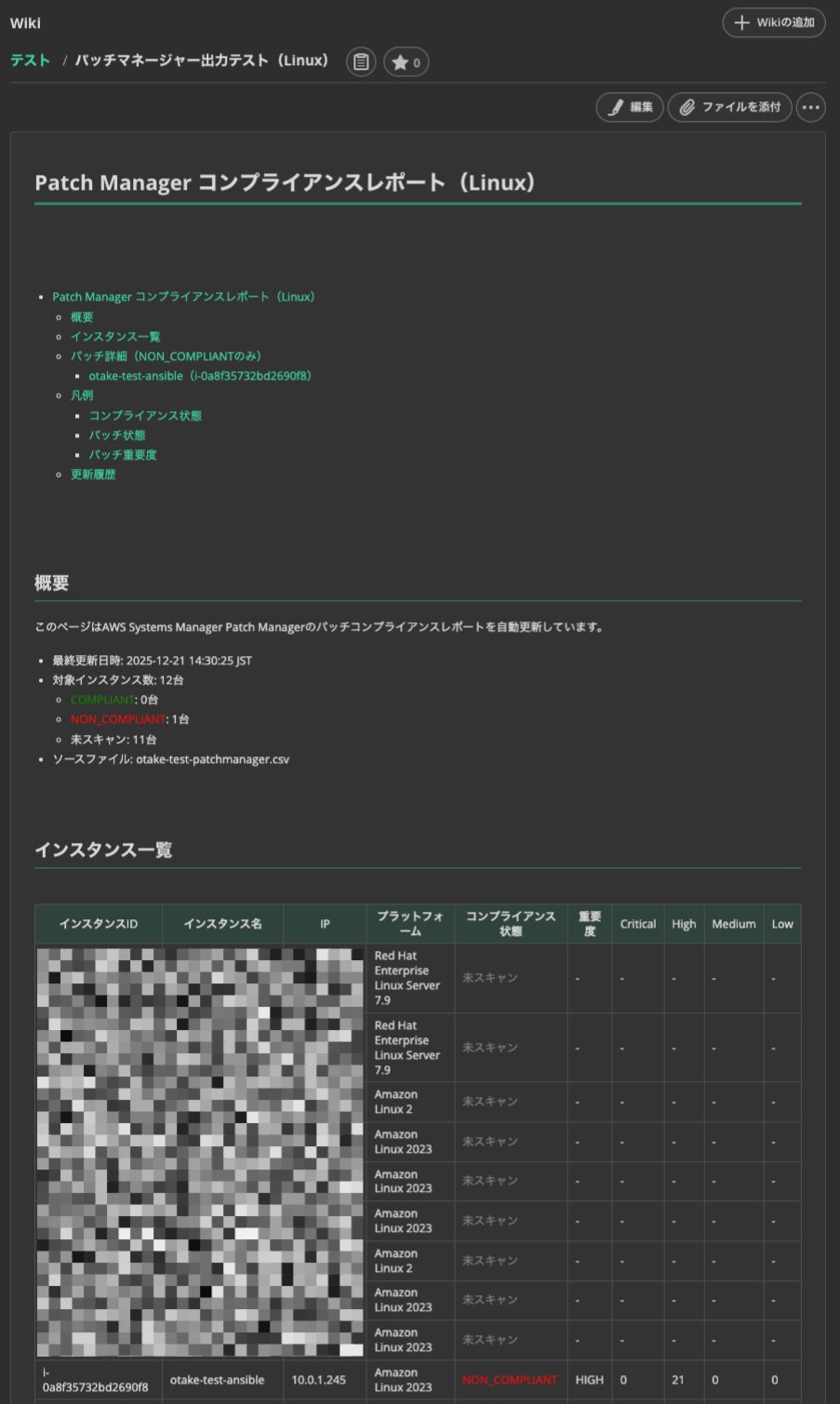
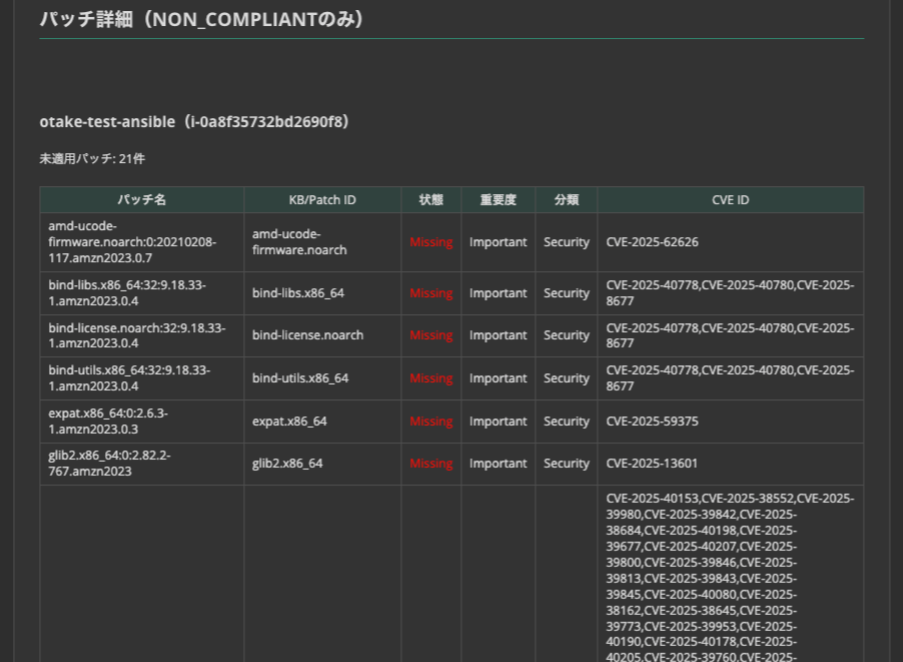
Linux
セッションマネージャー接続なしでもこれだけの情報が出てきます!
CVEと紐づいているのはありがたいですね。
Backlogならお客様も閲覧可能です。
双方で確認しつつ適用を進められそうです!
自動実行のためにAmazon EventBridgeを実装する
手動のテストで問題ないことが確認できました。
定期的に実行してもらうためにS3バケットのイベント通知を設定しましょう!
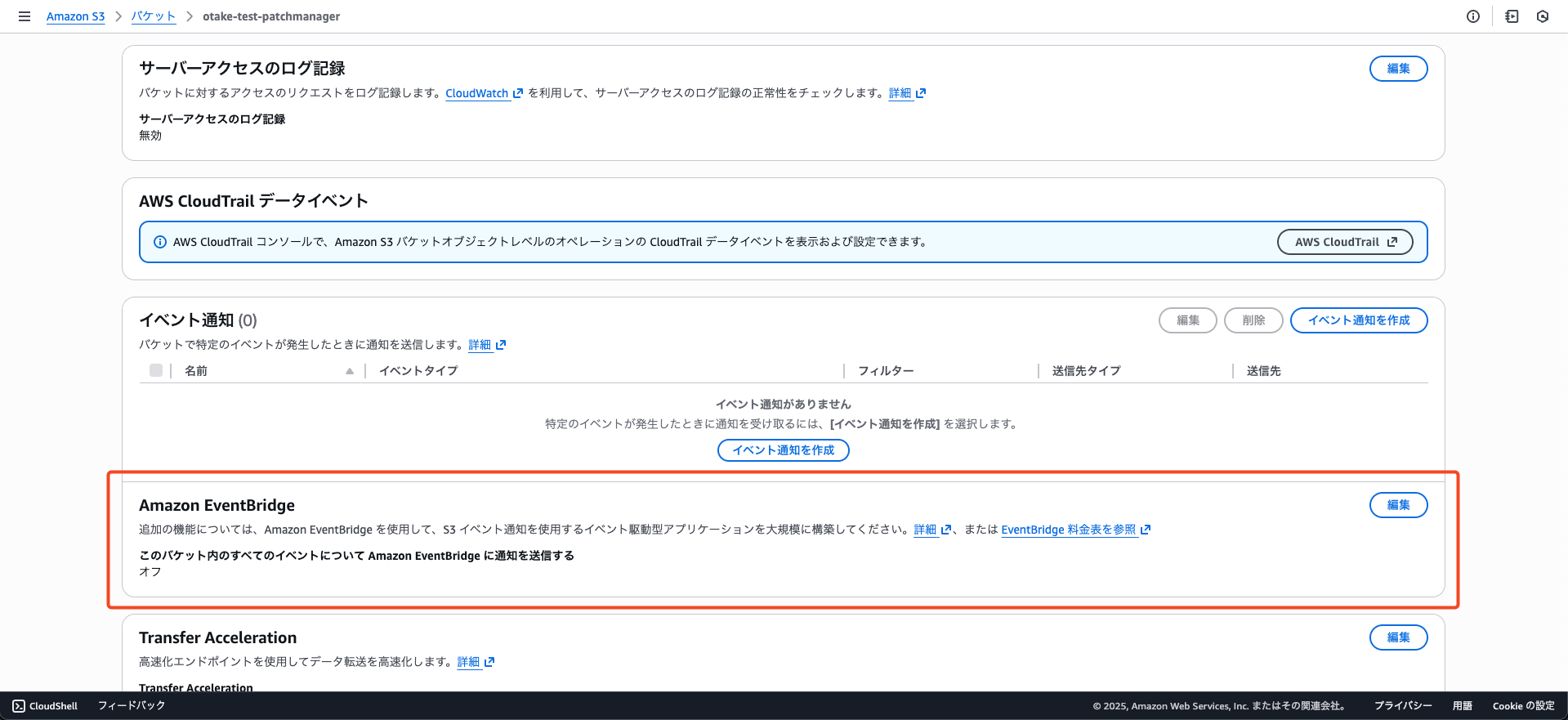
S3バケットの設定
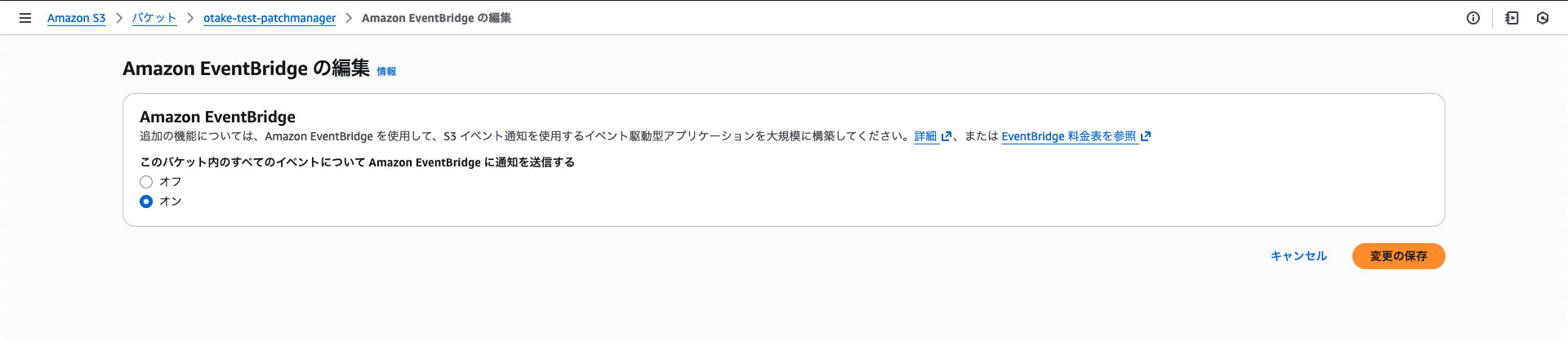
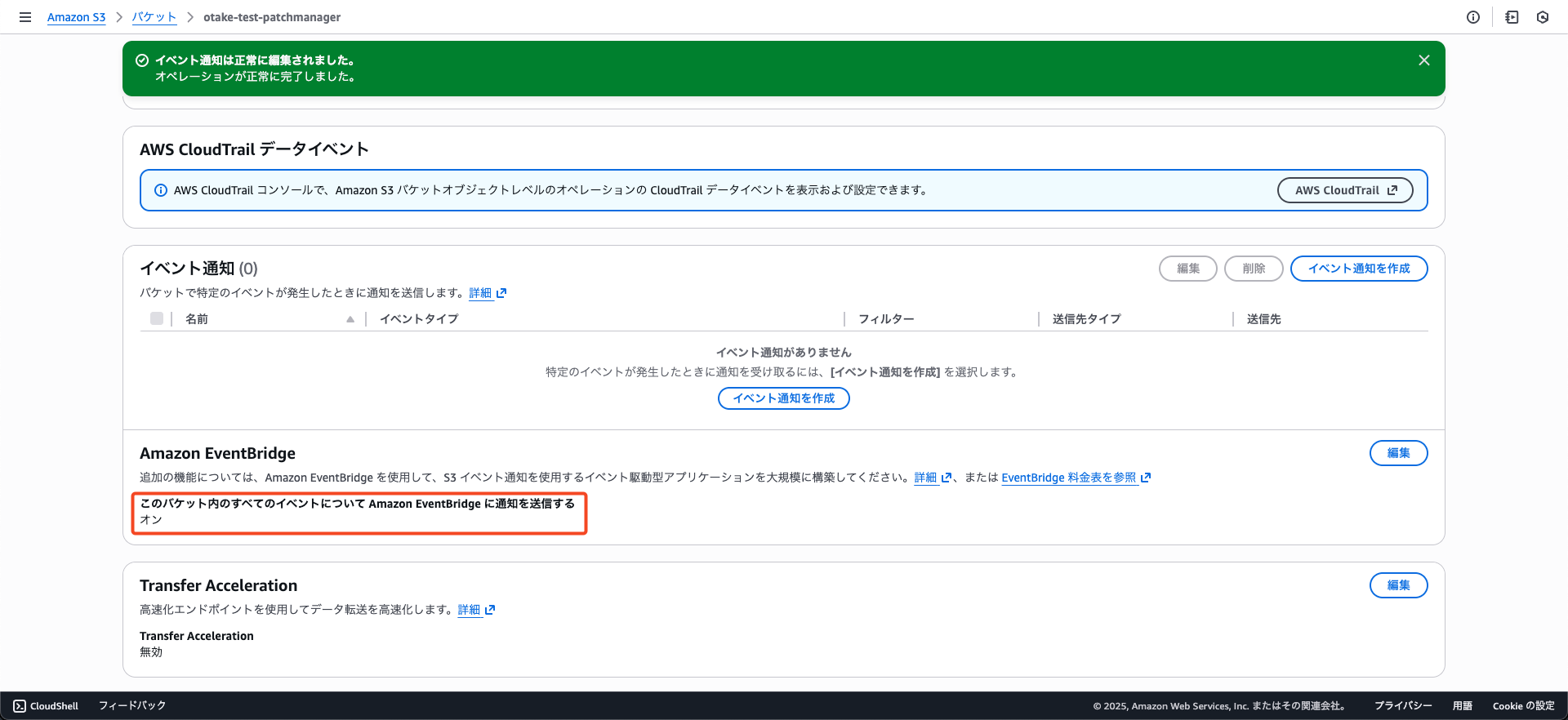
まずはプロパティタブからAmazon EventBridgeをONにしましょう!
なぜイベント通知ではないのかは前編をご覧ください!
Amazon EventBridge ルールを作成
S3バケットからのイベント転送設定ができました。
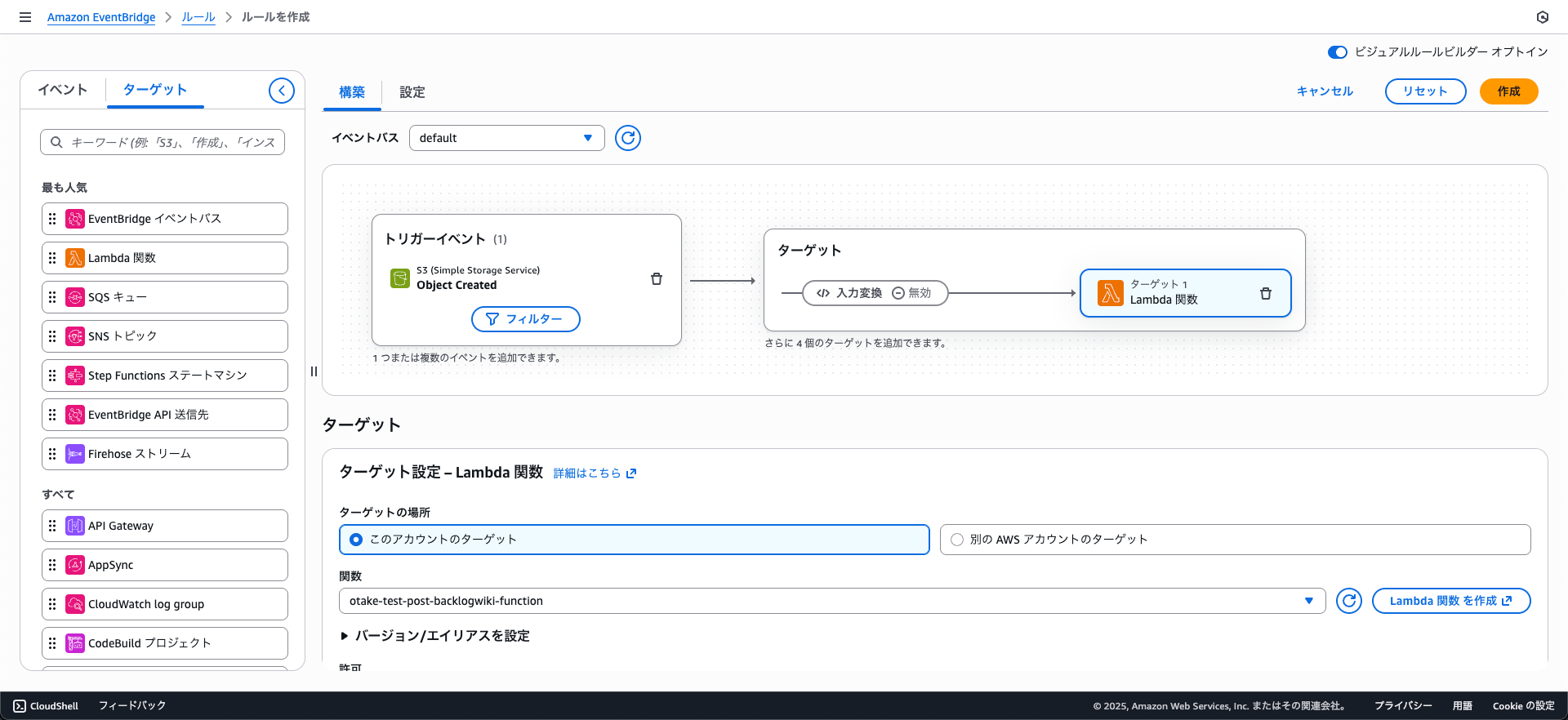
次に動かすためにAmazon EventBridgeのルールを作成します!
コンソールの設定がStepFunctionみたくなっていて非常にわかりやすくなってました!!
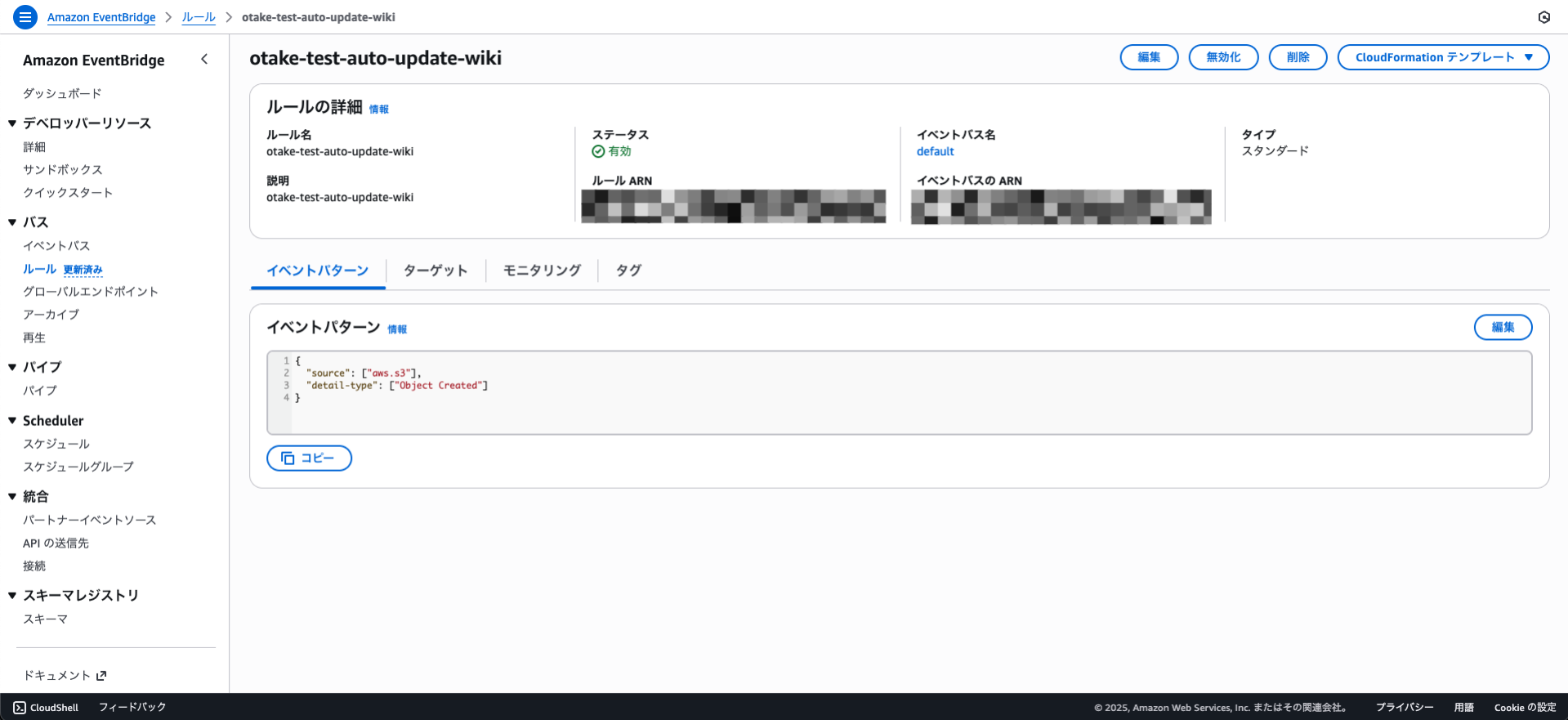
設定変更が必要です!
鋭い方はお気づきかもしれません。
この状態だとS3が発するすべてのイベントをトリガーとして発火してしまいます。
今回はコンプライアンスレポート出力時にLambdaを実行してほしいです。
以下のようにイベントパターンを修正します。
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["bucket1", "bucket2", "bucket3"]
}
}
}

実行の確認
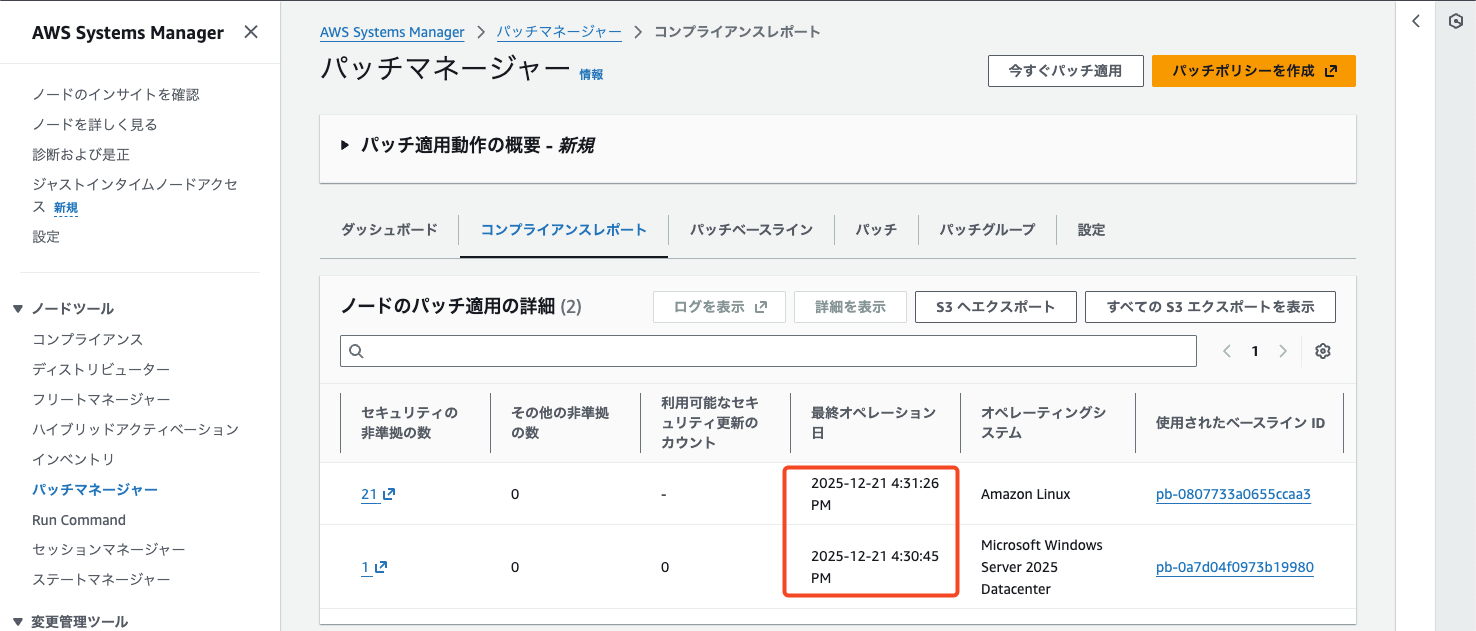
2025/12/21 の PM3:49(15:49)にレポートが出力されました。
それに反応するか見てみましょう。
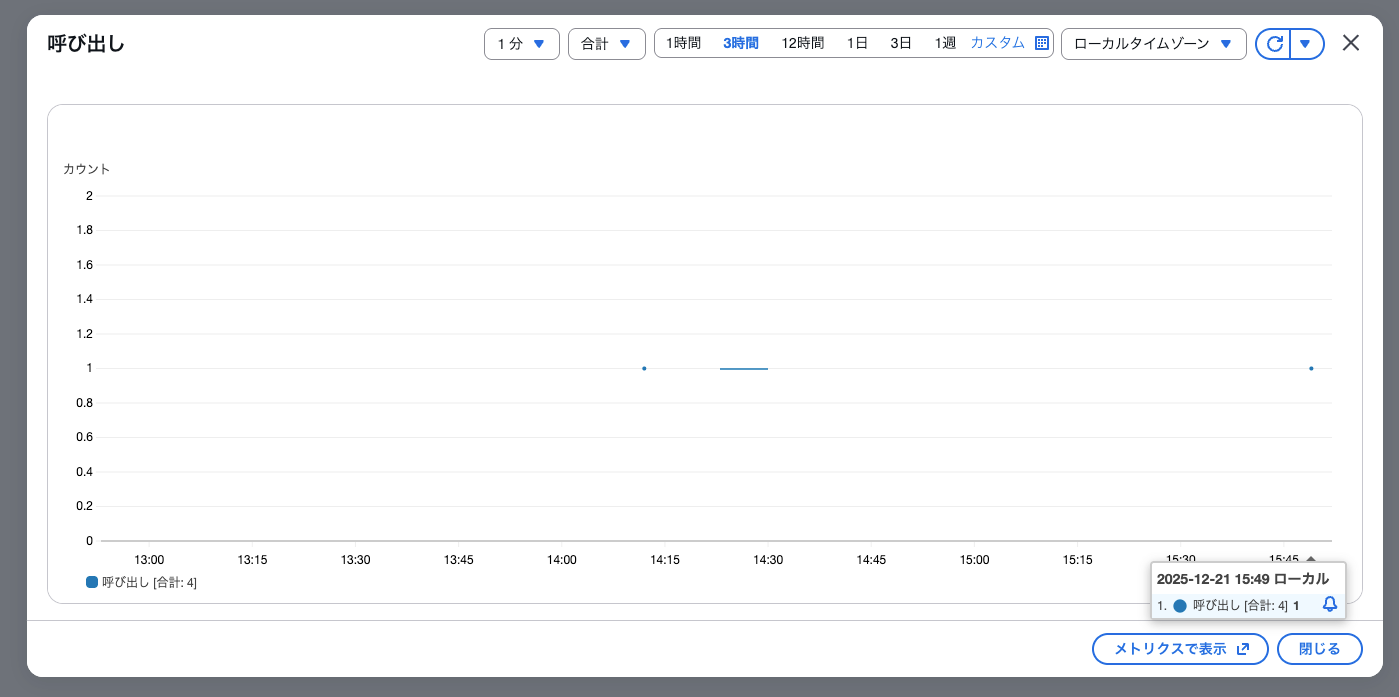
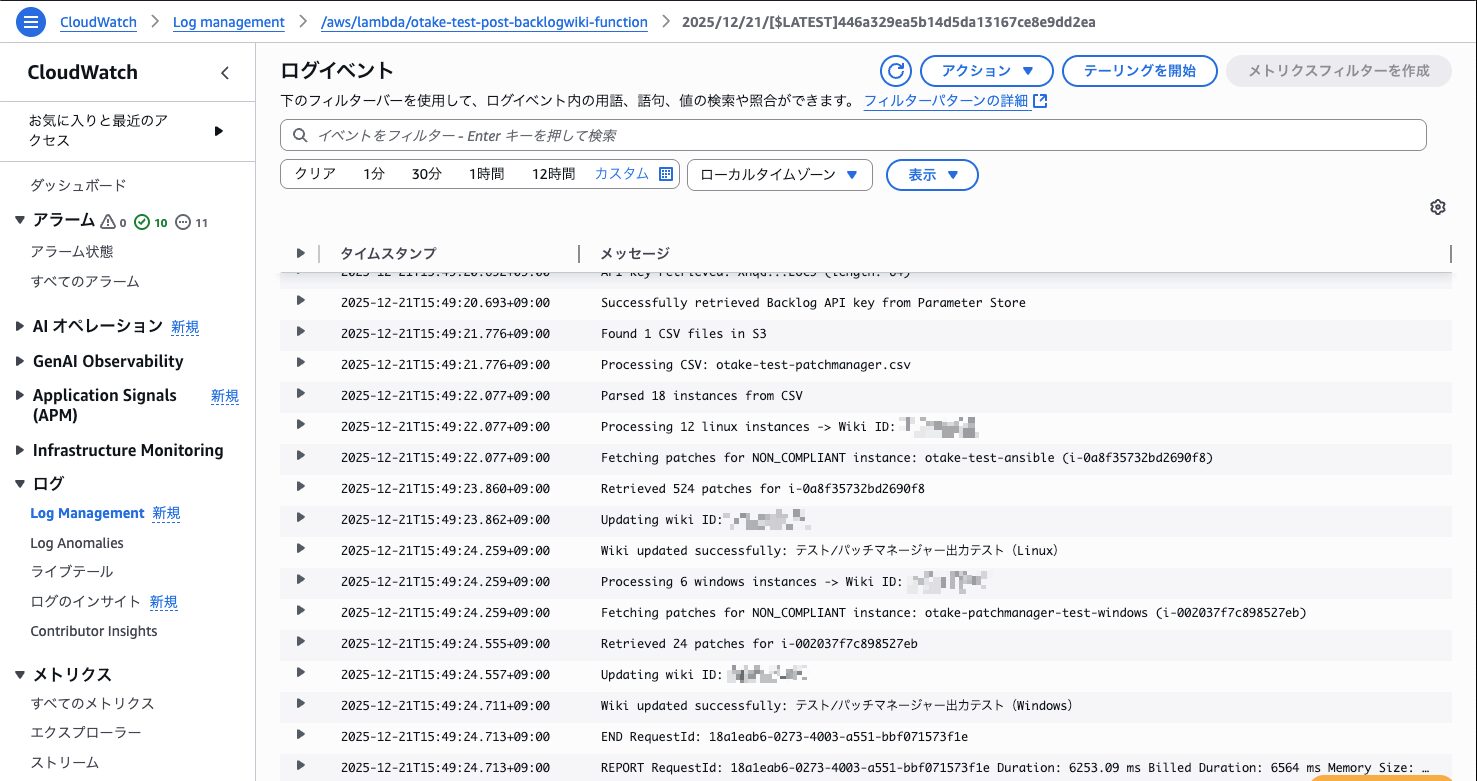
メトリクス上でもログ上でもしっかりと実行できています!!!
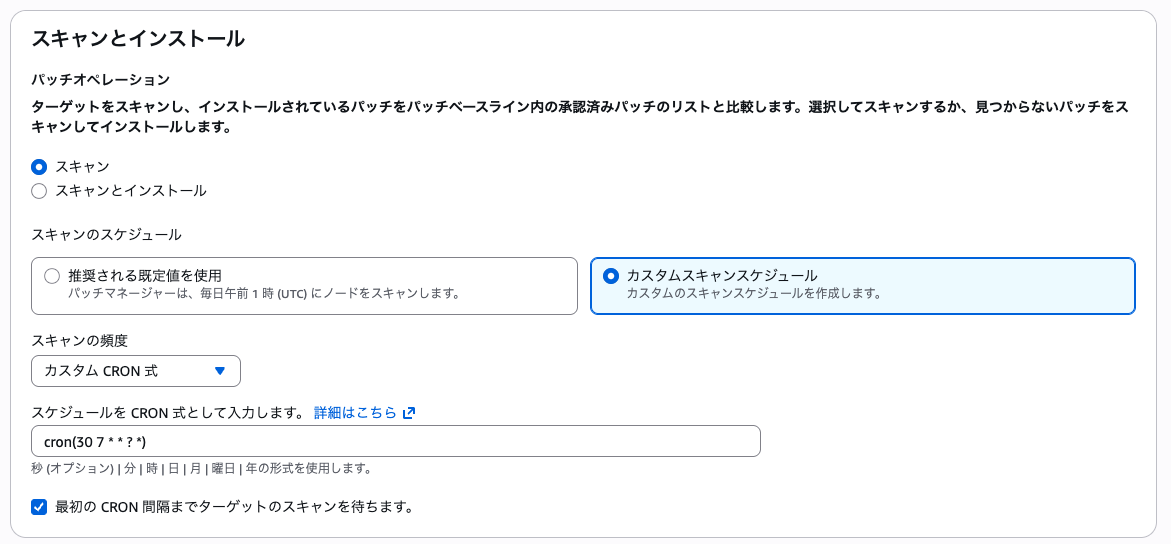
スキャンの自動実行スケジューリング
前編で紹介したQuick Setup > 設定にてcronを指定してみます。
すぐ動くか見たいので近い時間で設定してみましょう!
タイムゾーン指定はないのでお決まりのUTCで指定します。
cron(30 7 * * ? *)
レポート出力もスケジューリングする
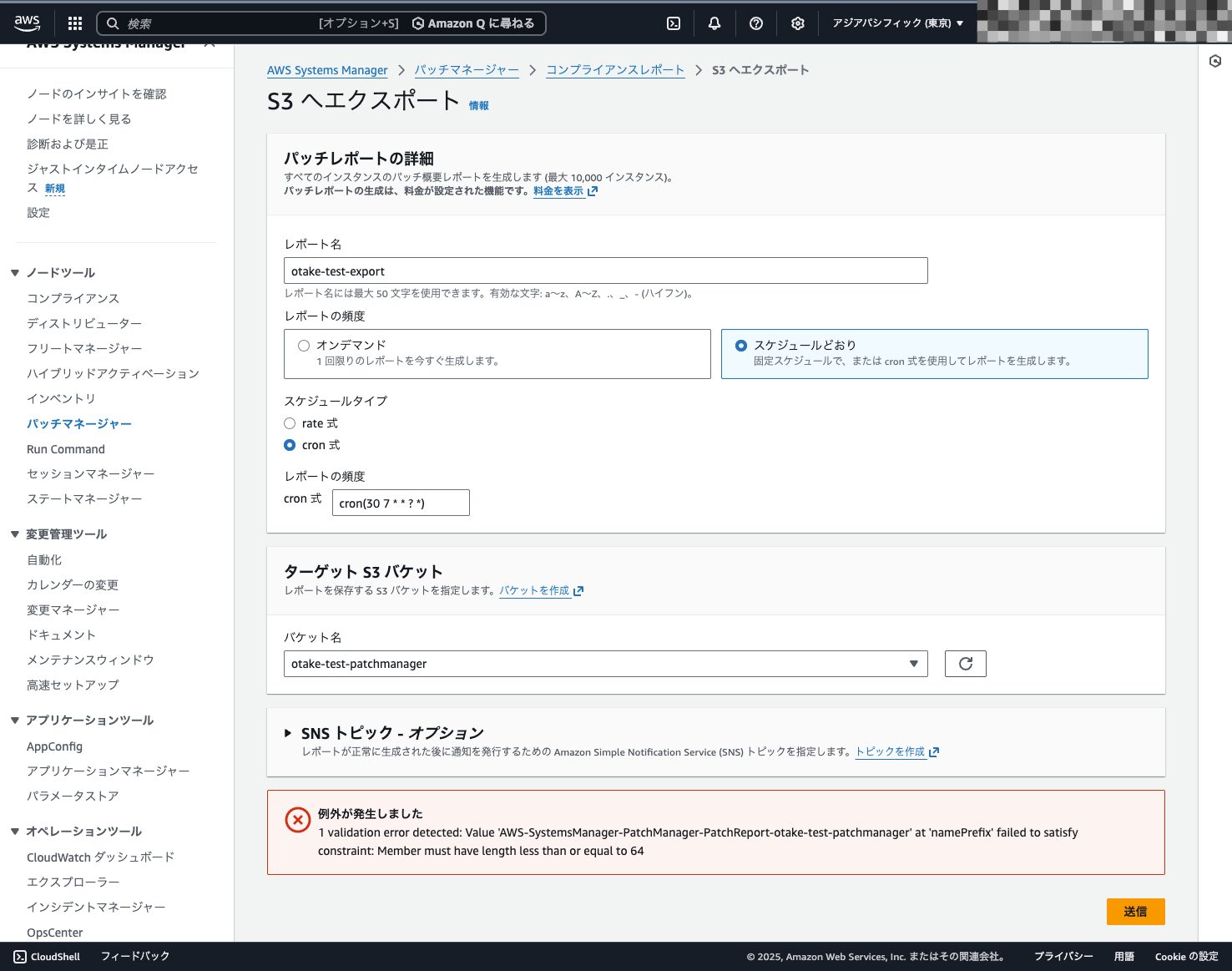
レポートの出力も一緒にスケジューリングします。
最初レポート名を適当につけたら文字数エラーが出ました。
指定するレポート名の前に「AWS-SystemsManager-PatchManager-PatchReport-」というプレフィックスがつくようです。

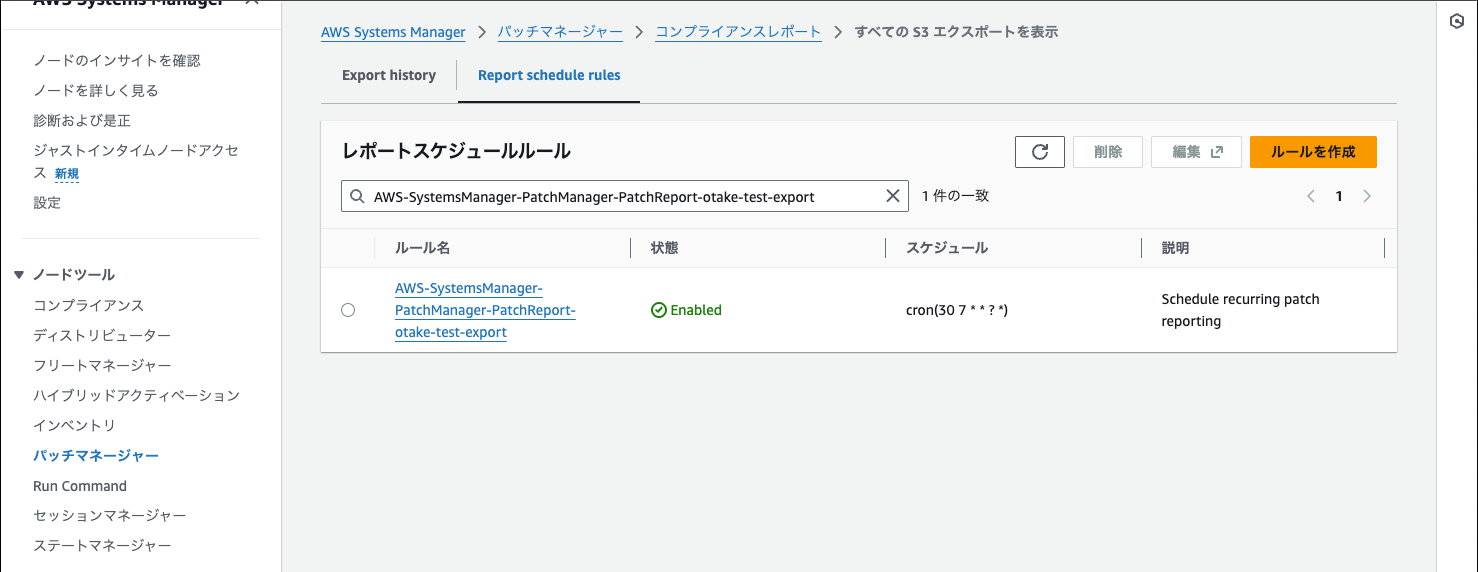
注意
作ったあとに気づきました。
スキャンは実行に時間がかかるのでエクスポートの時間指定をずらす必要がありました!
あとから修正しましたが実体としてはEventBridgeのルールが自動作成されているものでした!!
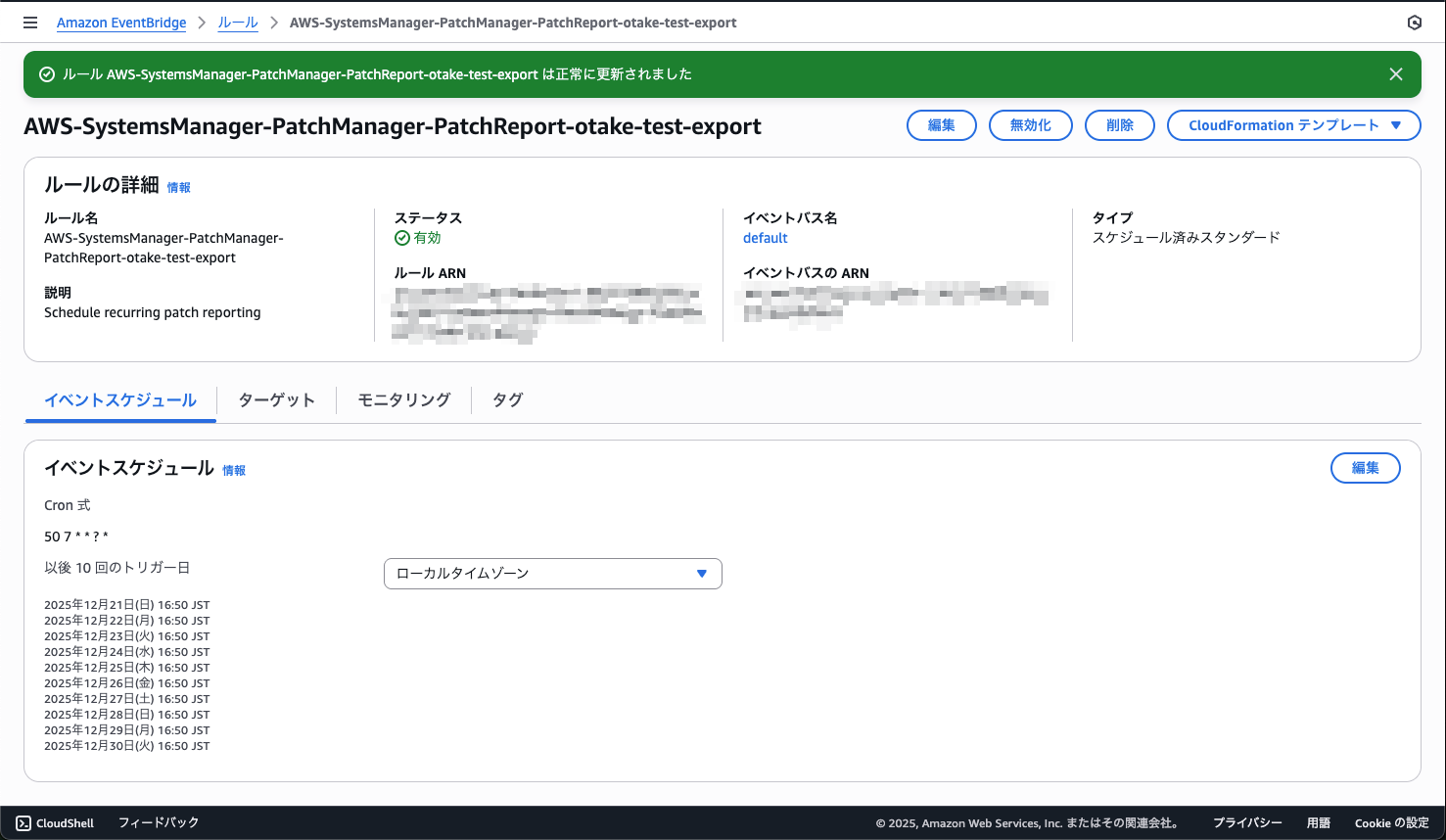
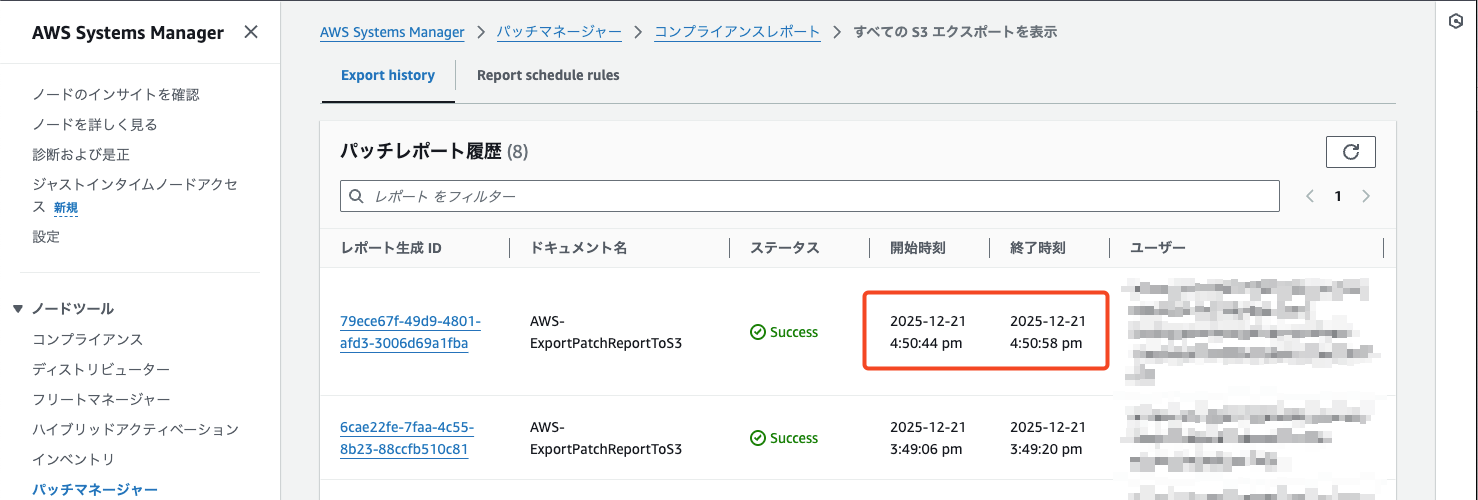
スケジューリング実行を確認
スキャンとレポートのエクスポートともに指定したスケジュールでの実行が確認できました!
これで自動的にWikiの更新も動くようになります!!
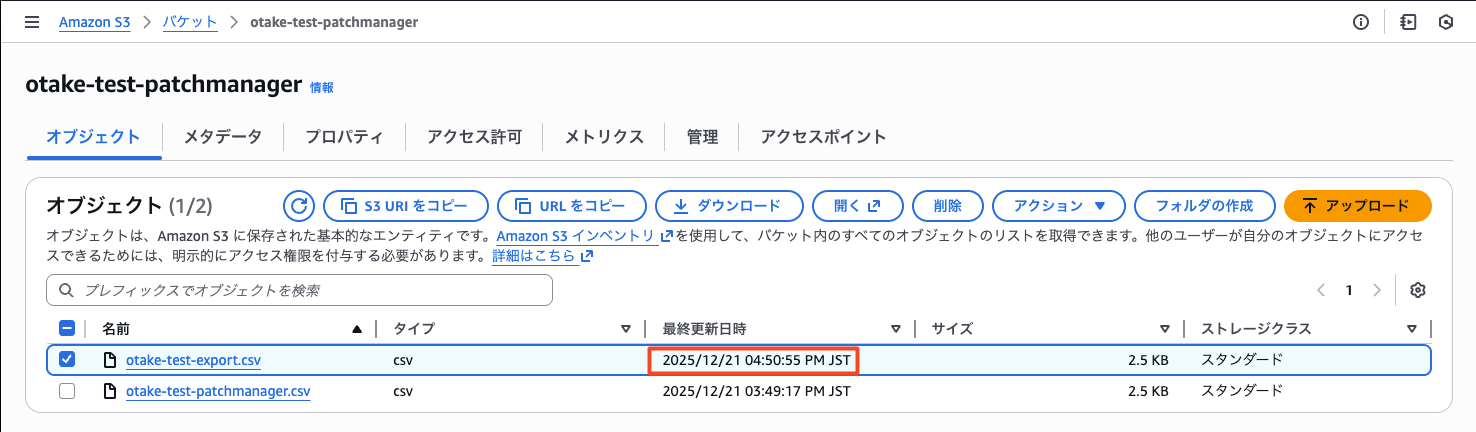
指定する名前を変えたためオブジェクト名が変わっています。
しかしLambdaコードは最新のCSVファイルを見るように作っているので考慮不要です!
Wikiの更新も確認してみよう
しっかり更新されてます!
これで完成です!!

なぜこの設計にしたか
ここまでで、Backlog Wikiへ転記する仕組みについてご紹介しましたが、最後に今回仕組みを作るに当たって構想した設計思想について説明します。
SSM API と「最新 CSV のみ」の理由
Patch Manager のコンプライアンスレポートを S3 にエクスポートすると、スケジュールのたびに新しい CSV が Put されます。Lambdaではlist_objects_v2でプレフィックス配下を取ってきて、LastModified が一番新しい 1 ファイルだけを処理するようにしています。
なぜ1ファイルかというと、レポート出力が短い間に複数回走ると、同じプレフィックス配下に CSV が何本も並ぶことがあります。そのとき「どれが今回のスキャン結果か」をファイル名だけでは判別できません。だから「更新日時が最新のもの=直近のエクスポート」とみなして処理しています。レポート名には「AWS-SystemsManager-PatchManager-PatchReport-」というプレフィックスが付くので、プレフィックス検索で十分絞れます。
「DescribeInstancePatches」はインスタンスごとに 1 リクエスト必要なので、NON_COMPLIANT のインスタンスだけ 呼ぶようにしています。たとえば100台中5台が「NON_COMPLIANT」なら、APIは最大5回で済みます。Lambdaの実行時間も抑えられます。パッチ一覧は「MaxResults / NextToken」でページネーションできるので、1台あたりのパッチ数が多くても全件取れます。
EventBridge を選んだ理由(S3 イベント通知との比較)
S3のイベント通知をLambdaに直接渡すやり方でも同じことはできます。それでもEventBridgeにした理由は主に3つです。
まず、イベントパターンを細かく指定できることです。「detail-type: Object Created」と「bucket.name」で「どのバケットのPutで発火するか」を限定できます。S3 イベント通知だけだと、同じバケットの別プレフィックスや他のイベント種別もまとめて飛んでくる可能性があります。
次に、リトライと DLQです。EventBridgeはデフォルトでリトライしてくれますし、失敗したイベントをDead Letter Queue(SQS など)に飛ばせます。あとから原因を追ったり、メッセージを戻して再実行したりしやすくなります。
あとは拡張性です。将来「レポートが来たらSlackに通知」「別のLambdaで集計」といったターゲットを足すとき、ルールを1本追加するだけで済みます。
小規模で「S3イベントで十分」という構成ならS3通知でも問題ありません。運用や拡張を考えるならEventBridgeの方が扱いやすくなります。
パフォーマンスとスケーラビリティ
Lambda の制限とインスタンス数
Lambda は最大 15 分まで実行できます。処理時間を決めるのはだいたい次の 3 つです。
- S3 から CSV を取ってパースする部分:インスタンス数にあまり依存しません。
- NON_COMPLIANTなインスタンスに対するDescribeInstancePatches:1 台あたり数秒程度です。ここが台数に比例して効きます。
- Backlog API(Wiki 更新):Linux/Windows で合わせて 2 回程度です。
NON_COMPLIANTが 20~30 台程度まで なら、1つのLambda関数で15分以内に収まることが多いです。それ以上になりそうな場合は、Step Functionsでインスタンスを分割して複数Lambdaを並列実行するか、NON_COMPLIANTのIDリストをSQSに積んでワーカーLambdaが順に処理する形にすると安全です。
メモリは256MBでも動きますが、CSV が大きいときやパッチ数が多いときは512MB~1GBにしておくとパースやJSON処理が安定しやすくなります。タイムアウトは「スキャン+エクスポートの間隔」より短く設定し、それでも足りないようなら上記の分割構成を検討してください。
スキャンとエクスポートの時間差
Patch Manager のスキャンは、インスタンス数によって 数分~十数分 かかることがあります。Quick Setupで「スキャン」と「レポートのエクスポート」の両方をスケジュールしている場合、エクスポートの実行時刻を、スキャン完了より十分あとにずらす必要があります。
例えばスキャンが毎日0:30 UTC、レポートエクスポートが0:35 UTCだと、スキャンがまだ終わっていないうちにエクスポートが走り、古い結果がS3に出てしまいます。スキャンに 10 分かかる想定なら、エクスポートは0:45 UTCのように10~15 分以上あとにしておくのが無難です。後編で「スキャンは時間がかかるのでエクスポートの時刻をずらした」と書いている部分の、一般化した目安として使えます。
エラーハンドリングとトラブルシューティング
Lambda 失敗時のリトライと DLQ
EventBridgeのルールでLambdaをターゲットにするときは、リトライとDead Letter Queue(DLQ)を付けておくと運用が楽になります。
リトライは最大2回などにしておけば、Backlog APIの一時的な503やネットワークの揺らぎで成功することもあります。DLQにはSQSキューを指定します。リトライしても失敗したイベントがDLQに届くので、CloudWatch Alarm で DLQ のメッセージ数を監視しておき、失敗時にアラートを上げるのがおすすめです。
よくある事象と原因
| 事象 | 想定原因 | 確認方法・対処 |
|---|---|---|
| 特定インスタンスのパッチが0件でWikiに載らない | そのインスタンスがSSMの管理下にない、またはAgentが動いていない | SSMコンソールの「マネージドノード」で対象インスタンスの状態を確認。ネットワーク・IAM・Agent バージョンを確認。 |
| OS判定が「Linux」になるはずがWikiに反映されない | Platform nameに想定外の文字列が入っている | CSVのPlatform name列を確認。detect_os_from_platformは「Windows」を含むかで判定しているので、表記ゆれ(小文字windowsなど)があるとLinux扱いになります。必要なら判定ロジックを拡張する必要があります。 |
| Backlog Wikiが403/401 | APIキーやWiki IDの誤り、または権限不足 | Parameter Storeの値と環境変数BACKLOG_WIKI_ID_*を確認。BacklogのAPIキーにWiki更新権限があるか、対象プロジェクトを確認してください。 |
設計判断の整理
Wiki は手動作成し、Lambda は「更新」だけにする理由
WikiをLambdaから新規作成すると、「初回だけ作成、2 回目以降は更新」という分岐が必要になり、作成失敗時のリトライや冪等性の考慮がややこしくなります。あらかじめ Backlog上でWikiページを2つ作っておき、そのWikiIDを環境変数で渡して更新だけする設計にすると、Lambdaの役割は「内容の生成と更新」に絞れます。権限も既存Wikiの更新だけに限定できます。
API キーを Parameter Store で持つ理由
BacklogのAPIキーをLambdaの環境変数に直書きすると、コードや設定のバージョン管理に機密が含まれるし、ローテーションのたびに複数箇所を触ることになります。Systems Manager Parameter Store(SecureString)に置いて、Lambda 実行時に GetParameterで取る形にすれば、キーを変えるときはParameter Storeの更新だけで済み、Lambdaの再デプロイは不要です。IAMでは「ssm:GetParameter」を当該パスにだけ付けておくのがよいでしょう。
今後必要な運用は?
業務としてもお客様としても嬉しいものができたと思います!
しかしこの仕組みは継続的に最新化する必要があります。
そのため運用を見据えてLambdaコード以外はマネージドサービスで完結させています。
基本的に考えられる運用作業は下記のみです。
- Lambdaに使用しているPythonのバージョンアップデート作業
マネージドサービスで完結させることで少ない工数で効率よく運用できます!
また発表があった通り、Wiki機能の廃止があるので今後作り変えが必要になります。
まとめ
今回は前後編を通してPatch Managerのコンプライアンスレポートを自動でBacklog Wikiに転記する仕組みを構築しました!
SSHやRDP接続せずにパッチ状況を可視化できます。
顧客とBacklog上で共有可能になるのがポイントです!
ほとんどをマネージドサービスで完結させています。
定期的なPythonのバージョンアップのみという少ない工数で運用が可能です!
みなさんもパッチ管理の手間を減らしつつセキュリティを維持していきましょう!
最後までお読みいただきありがとうございました!
次回は更に運用を考えた番外編を計画中!
お楽しみに!

