
はじめに
AIエージェントの開発は、今や「いかにデータを効率よく扱うか」のフェーズへと進化しています。
先日、GoogleからリリースされたGoogle マネージドのBigQuery MCP(Model Context Protocol)サーバー。これを利用することで、今まで手動で定義していたSQL実行処理などをAI側に任せ、よりスマートなエージェント構築が可能になりました。
今回は、Google CloudのオープンソースフレームワークであるADK(Agent Development Kit)と組み合わせ、BigQueryから直接データを取得・分析するエージェントの作成手順を詳しくご紹介します。
1. BigQuery MCPとADKの基本をおさらい
構築に入る前に、今回使用する主要なテクノロジーについて簡単に解説します。
BigQueryとは
Google Cloudが提供するフルマネージドのクラウド型データウェアハウス(DWH)です。膨大なデータを高速に分析できるだけでなく、近年ではGeminiとの連携により、AIアシスタント機能を通じたデータ操作も可能になっています。
ADK (Agent Development Kit) とは
Googleが提供するオープンソースのAIエージェント開発フレームワークです。GeminiモデルやVertex AIとシームレスに連携し、単一のエージェントから複雑なマルチエージェントシステムまで、直感的に構築できるのが特徴です。
なぜこの組み合わせが画期的なのか
従来の開発では、DBにアクセスするための関数(Tool)定義を一つひとつ手動で実装する必要がありました。しかし、BigQuery MCPサーバーをADKに組み込むことで、AIが自らスキーマを理解し、ユーザーの問いかけに合わせて最適なSQLを生成・実行してくれるようになります。
最大の革新点は、その導入の手軽さです。
これまではMCPサーバーを自前で構築・運用(ホスティング)する必要がありましたが、現在はこれがマネージドサービスとして提供されています。さらに「Cloud API Registry」を活用すれば、わずかな設定でADKに組み込むことが可能になりました!!
2. 事前準備:BigQuery MCPの有効化
まずは、Google CloudプロジェクトでMCPサーバーを有効化しましょう。gcloud SDKがインストールされ、認証が完了していることを前提とします。
APIの有効化
以下のコマンドを実行して、Cloud API RegistryとBigQuery MCPを有効にします。
# Cloud API Registry の有効化 % gcloud services enable cloudapiregistry.googleapis.com --project=<your-project-id> # BigQuery MCP の有効化 % gcloud beta services mcp enable bigquery.googleapis.com --project=<your-project-id>
有効化状態の確認
次に、MCPサーバーが正しく有効化されているか確認します。(2025年12月現在、この機能はPreview版のため、将来的にコマンドが変更される可能性がある点にご注意ください。)
% gcloud beta api-registry mcp servers list --project=<your-project-id>
出力結果の中で、stateが ENABLED になっていることを確認してください。その際、name(例: projects/…/mcpServers/…)の値を控えておきます。
{
"description": "BigQuery MCP server provides tools to interact with BigQuery",
"displayName": "bigquery.googleapis.com",
"name": "projects/<your-project-id>/locations/global/mcpServers/google-bigquery.googleapis.com-mcp",
"state": "ENABLED",
"urls": [
"[bigquery.googleapis.com/mcp](https://bigquery.googleapis.com/mcp)"
]
},・・・
3. エージェントの実装手順
それでは、実際にADKを使用してエージェントを構成していきましょう。
プロジェクト構成
プロジェクトの階層構造は以下のように準備します。
. ├──bq_mcp_agent │ ├── __init__.py │ └── agent.py └── .env
環境設定 (.env)
Vertex AIを利用するための設定を環境変数に記述します。
GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT=<YOUR_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_LOCATION>
コードの実装 (agent.py)
以下が、BigQuery MCPサーバーを呼び出すエージェントの核となるコードです。
from google.adk.agents import Agent
from google.adk.tools.api_registry import ApiRegistry
# 設定情報
PROJECT_ID = "<your-project-id>"
MCP_SERVER_NAME = "projects/<your-project-id>/locations/global/mcpServers/google-bigquery.googleapis.com-mcp"
# ヘッダープロバイダーの定義
def header_provider(context):
return {"x-goog-user-project": PROJECT_ID}
# API Registryの初期化
api_registry = ApiRegistry(
api_registry_project_id=PROJECT_ID,
header_provider=header_provider
)
# BigQuery MCPのツールセットを取得
registry_tools = api_registry.get_toolset(
mcp_server_name=MCP_SERVER_NAME,
)
# エージェントの定義
root_agent = Agent(
model='gemini-3-flash-preview', # または最新のPreviewモデルを指定
name='root_agent',
description='ユーザーの質問をサポートする便利なアシスタントです。',
instruction='API Registryツールを使用してユーザーがBigQueryデータにアクセスできるよう支援してください。',
tools=[registry_tools],
)
ADK開発UIの起動
下記コマンドを実行して、会話を試みてください!
これで画像のようにBigQueryの情報が返却されてきたら成功です!!
% adk web
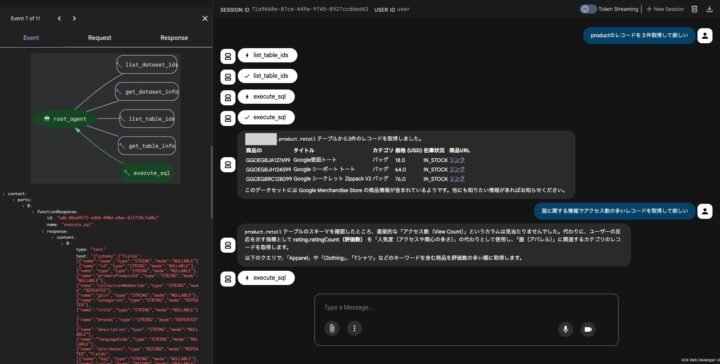
4. BigQuery MCPサーバーに備わっている標準ツール
この構成を構築すると、エージェントは自動的に以下の強力なツールを自律的に扱えるようになります。
- execute_sql: SQL ステートメントを実行します。
- get_dataset_info: データセットのメタデータを取得します。
- get_table_info: テーブルのメタデータを取得します。
- list_dataset_ids: データセットを一覧表示します。
- list_table_ids: テーブルを一覧表示します。
開発者は「どのテーブルを見ればいいか」を軽く教えるだけで、AIが「スキーマ確認 → SQL生成 → 実行 → 回答」のサイクルを回してくれます。
まとめ
Google マネージド BigQuery MCPサーバーとADKを組み合わせることで、従来のデータ分析エージェント開発の手間が大幅に削減されます。
また、ADKとMCPを組み合わせる利点として、エージェントがチャットの意図を理解し、MCP側で定義されたスキーマに基づいてデータを取得・整形してくれる点が挙げられます。これにより構造化されたデータが保証されるため、ハルシネーションや予期せぬエラーが減り、期待通りの結果を安定して得ることができます。
特に、アドホックなデータ分析(その場での思いつきの分析)が求められるシーンでは、この「ツールを自動で取得・実行する」仕組みが非常に強力な武器になります。次世代のAIエージェントを構築してみましょう!
最後まで読んでいただきありがとうございました。この記事が、あなたのAIエージェント開発の参考になれば幸いです!

