はじめに
AWS Step Functionsでは、2024年にクエリ言語としてJSONataがサポートされました。従来のJSONPath($.variable形式)に代わり、より柔軟で強力な式が書けるようになっています。
本記事では、SQSキューのメッセージを全件処理するステートマシン定義を題材に、JSONata構文の検証で得られた知見をまとめます。
全体のフロー
このステートマシンは、SQSキューからメッセージを取得し、1件ずつJSON化してS3に配置した後、SQSからメッセージを削除する処理をキューが空になるまでループします。
[SQSからメッセージを取得 (SDK統合)]
↓
[メッセージの有無を確認 (Choice)]
├─ (メッセージあり)
│ ↓
│ [メッセージ処理 (Map)]
│ └─ [JSONファイル化して配置 (Lambda)]
│ ↓
│ [メッセージ削除 (SQS SDK統合)]─────↑(処理完了後SQSからメッセージを取得に戻る)
│
└─ (メッセージなし)
↓
[処理終了]JSONata対応のポイント
1. QueryLanguageの宣言
ステートマシン定義のトップレベルでQueryLanguageをJSONataに設定します。
{
"QueryLanguage": "JSONata",
"Comment": "SQSキューのメッセージを全て処理し、JSONファイルをS3に配置する",
"StartAt": "SQSからメッセージを取得"
}
検証結果:QueryLanguageを指定しない場合、デフォルトはJSONPathになります。JSONata構文を使うには必ずトップレベルで宣言が必要です。
2. AWS SDK統合とArguments
SQSの操作はAWS SDK統合を使い、`Arguments`でパラメータを渡します。
"SQSからメッセージを取得": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:sqs:receiveMessage",
"Arguments": {
"QueueUrl": "${queue_url}",
"MaxNumberOfMessages": 5,
"VisibilityTimeout": 300
},
"Next": "メッセージの有無を確認"
}
検証結果:
- 従来のJSONPathモードでは`Parameters`を使っていましたが、JSONataモードでは`Arguments`に変わります
- AWS SDK統合のResourceは`arn:aws:states:::aws-sdk:{サービス}:{API}`の形式で、JSONataモードでも同じです
- `${queue_url}`はTerraformの`templatefile`によって実際のSQS URLに置換されます(JSONata式ではなくTerraform変数)
3. Choice(条件分岐)でのCondition
従来のVariable+比較演算子ではなく、ConditionにJSONata式を直接記述します。
"メッセージの有無を確認": {
"Type": "Choice",
"Choices": [
{
"Condition": "{% $states.input.Messages != null %}",
"Next": "メッセージ処理"
}
],
"Default": "処理終了"
}
従来のJSONPathでの書き方との比較:
// JSONPath(従来)
{
"Variable": "$.Messages",
"IsPresent": true,
"Next": "メッセージ処理"
}
// JSONata(今回)
{
"Condition": "{% $states.input.Messages != null %}",
"Next": "メッセージ処理"
}
検証結果:
- `Condition`にJSONata式を書くことで、条件を一つの式で表現できます
- `$states.input`は現在のステートへの入力データ全体を参照します
- SQSの`receiveMessage`はメッセージがない場合`Messages`フィールド自体を返さないため、`!= null`でチェックしています
4. Map stateでのItemsと配列展開
Map stateで処理する配列をItemsにJSONata式で指定します。
"メッセージ処理": {
"Type": "Map",
"Items": "{% $states.input.Messages[] %}",
"ItemProcessor": { ... },
"Next": "SQSからメッセージを取得"
}
検証結果:
- 従来の`ItemsPath`(JSONPath)の代わりに`Items`にJSONata式を指定します
- `Messages[]`の`[]`はJSONataの配列展開演算子で、配列の各要素を個別に返します
- Map stateの`Next`を「SQSからメッセージを取得」に設定することで、**キューが空になるまでループする**仕組みを実現しています
- `MaxConcurrency`を指定していないため、デフォルトの`0`(無制限)が適用され、**取得した複数メッセージが並列で処理されます**。`receiveMessage`で最大5件を一度に取得するため、最大5件が同時に処理される形になります。Lambdaの同時実行やSQSのスループットに応じて`MaxConcurrency`を設定すれば、並列数を制御することも可能です
5. OutputによるLambda結果の加工
Lambda実行後、Outputで出力データを整形できます。
"JSONファイル化して配置": {
"Type": "Task",
"Resource": "${lambda_put_json_arn}",
"Arguments": {
"Body": "{% $states.input.Body %}"
},
"Output": {
"ReceiptHandle": "{% $states.input.ReceiptHandle %}"
},
"Next": "メッセージ削除 (SQS)"
}
検証結果:
- `Output`は従来の`ResultSelector`に相当します – Lambda関数には`Body`(SQSメッセージの本文)だけを渡し、Lambda実行後の出力には`ReceiptHandle`を含めています
- これにより、次の「メッセージ削除」ステートで`ReceiptHandle`を利用できます
- **入力の一部を出力に引き継ぐ**パターンとして、`Output`内で`$states.input`を参照するのがポイントです
6. SQSメッセージの削除(SDK統合)
処理済みメッセージをSQSから削除します。
"メッセージ削除 (SQS)": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:sqs:deleteMessage",
"Arguments": {
"QueueUrl": "${queue_url}",
"ReceiptHandle": "{% $states.input.ReceiptHandle %}"
},
"End": true
}
検証結果:
- 前のステートの`Output`で`ReceiptHandle`を出力に含めたため、`$states.input.ReceiptHandle`でアクセスできます
- SDK統合でSQSのdeleteMessageを直接呼び出すことで、Lambda関数を別途用意する必要がありません —
Terraformとの連携
このステートマシン定義はTerraformのtemplatefile関数でデプロイされます。
resource "aws_sfn_state_machine" "example" {
name = "example_stepfunctions"
role_arn = aws_iam_role.example.arn # Step Functionsに紐づけるIAMロール
definition = templatefile("${path.module}/step_functions/example_jsonata.json", {
queue_url = aws_sqs_queue.example.url,
lambda_put_json_arn = aws_lambda_function.put_json.arn # Json化して、S3に配置するlambda関数のARN
})
}
注意点:JSON内の${queue_url}や${lambda_put_json_arn}はTerraformの変数置換であり、JSONataの{% %}式とは別の仕組みです。混同しないように注意してください。
JSONPath vs JSONata 比較まとめ
| 項目 | JSONPath(従来) | JSONata |
| 入力参照 | `$.variable` | `{% $states.input.variable %}` |
| Lambda引数 | `Parameters` | `Arguments` |
| 結果の加工 | `ResultSelector` | `Output` |
| 結果の格納 | `ResultPath` | `Assign` |
| 入力フィルタ | `InputPath` | 不要(JSONata式で直接制御) |
| 出力フィルタ | `OutputPath` | 不要(JSONata式で直接制御) |
| 条件分岐 | `Variable` + 比較演算子 | `Condition` + JSONata式 |
| Mapの対象 | `ItemsPath` | `Items` |
検証: CSVファイルをS3に配置してSQS経由で処理する
ここでは、実際にCSVデータをS3に配置し、SQSにメッセージを送信してStep Functionsで処理する手順を紹介します。
テストデータ(CSV)
以下のようなCSVファイル test1.csv を用意します。
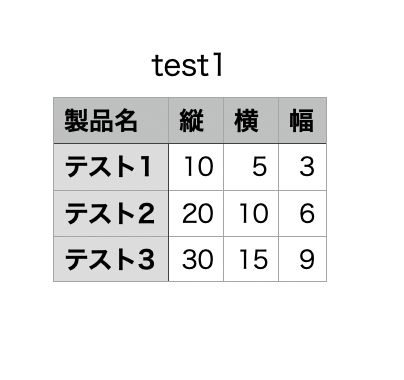
JSON化したあとの結果
[
{
"製品名": "テスト1",
"縦": 10,
"横": 5,
"幅": 3
},
{
"製品名": "テスト2",
"縦": 20,
"横": 10,
"幅": 3
},
{ "製品名": "テスト3",
"縦": 30,
"横": 15,
"幅": 9
}
]
手順1: S3にCSVファイルをアップロード
AWS CLIを使ってS3バケットにCSVファイルをアップロードします。
aws s3 cp test1.csv s3://{バケット名}/csv/test1.csv
本環境では、Terraformで以下のように定義されたS3バケットを使用しています。
resource "aws_s3_bucket" "csv" {
bucket = "csv_bucket"
}
手順2: SQSにメッセージを送信
S3に配置したCSVファイルの情報をSQSメッセージとして送信します。本環境ではFIFOキューを使用しているため、--message-group-idの指定が必要です。
aws sqs send-message \
--queue-url https://sqs.{リージョン}.amazonaws.com/{アカウントID}/{キュー名}.fifo \
--message-body '{
"bucket": "{バケット名}",
"key": "csv/test1.csv",
"file_name": "test1.csv"
}' \
--message-group-id "csv-import"
SQSキューはTerraformで以下のように定義されています。
resource "aws_sqs_queue" "example" {
name = "example-sqs-queue.fifo"
fifo_queue = true
content_based_deduplication = true
}
FIFOキューのポイント:
- `content_based_deduplication = true` により、メッセージ本文のハッシュで重複排除が自動的に行われます
- 同じ内容のメッセージを短時間に2回送信しても、1回だけ処理されます
- `–message-group-id` でメッセージグループを指定し、グループ内の順序が保証されます
手順3: Step Functionsの実行
SQSにメッセージが入った状態でStep Functionsを実行します。
aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:{リージョン}:{アカウントID}:stateMachine:{ステートマシン名} \
--input '{}'実行すると、example_jsonata.jsonで定義したフローに沿って以下の処理が行われます。
1. SQSからメッセージを取得 — `receiveMessage`でCSVファイル情報を含むメッセージを取得
2. メッセージの有無を確認 — JSONata式`{% $states.input.Messages != null %}`で判定
3. メッセージ処理(Map) — 取得したメッセージごとにLambdaでJSONファイル化
4. メッセージ削除 — 処理済みメッセージをSQSから削除
5. ループ — SQSにメッセージが残っていれば再度取得(キューが空になるまで繰り返し)処理の流れ(図解)
[S3] test1.csv をアップロード
↓
[SQS] {"bucket": "...", "key": "csv/test1.csv"} を送信
↓
[Step Functions] 実行開始
↓
[SQS receiveMessage] メッセージを取得
↓
[Lambda] Body(CSVファイル情報)を受け取りJSON化してS3に配置
↓
[SQS deleteMessage] 処理済みメッセージを削除
↓
[ループ] キューが空になるまで繰り返し
↓
[処理終了]設計パターンまとめ
本ステートマシンで活用されているJSONataの設計パターンをまとめます。
パターン1: SQSポーリングループ
Map stateのNextをSQS受信ステートに戻すことで、キューが空になるまで自動ループします。Lambda関数でのポーリング実装が不要になり、Step Functions側で制御できるのが利点です。
パターン2: Outputによる入力引き継ぎ
Lambda実行後、Lambdaの結果ではなく入力データの一部(ReceiptHandle)を次のステートに渡すパターンです。Output内で$states.inputを参照することで実現しています。
おまけ: Assignによる変数の格納
JSONataモードではAssignを使うことで、ステートの処理結果や任意の値を変数に格納し、後続のステートから参照できます。
基本的な使い方
例えば、Passステートで変数を初期化する場合
"変数を初期化": {
"Type": "Pass",
"Assign": {
"import_code": "example",
"import_id": 1
},
"Next": "次のステート"
}
Assignで定義した変数は、以降のどのステートからでも{% $import_code %}のように参照可能です。
Taskステートでの活用
Taskステート(Lambda実行やSDK統合)でもAssignが使えます。Lambda実行結果の一部を変数に格納しつつ、次のステートに処理を渡すことができます。
"データを取得": {
"Type": "Task",
"Resource": "${lambda_arn}",
"Arguments": {
"id": "{% $import_id %}"
},
"Assign": {
"result_count": "{% $states.result.count %}",
"fetched_items": "{% $states.result.items %}"
},
"Next": "次のステート"
}
- `$states.result` でLambdaの実行結果を参照できます
- 必要な値だけを変数に取り出せるため、後続ステートで扱うデータがシンプルになります
JSONPathとの比較
| 方式 | 変数格納の方法 | 参照の方法 |
| JSONPath(従来) | `ResultPath: “$.myVar”` で入力JSONに結果をマージ | `$.myVar` |
| JSONata | `Assign: { “myVar”: “{% … %}” }` で変数に格納 | `{% $myVar %}` |
JSONPathでは入力JSONのツリー構造に結果を埋め込む形だったため、ネストが深くなりがちでした。JSONataのAssignは独立した変数として管理できるため、直感的でわかりやすくなっています。
まとめ
JSONataの検証を通じて、以下の知見が得られました。
1. JSONata式は`{% %}`で囲む — `$states.input`で入力を参照し、直感的にデータ操作ができる
2. Outputで出力を自由に整形 — Lambda結果に依存せず、入力データの引き継ぎが簡単
3. Choiceの条件式がシンプル — `Condition`一つで複雑な条件も表現できる
4. SDK統合との相性が良い — SQS操作をLambdaなしで直接実行でき、Argumentsで柔軟にパラメータ指定
5. Mapステートの並列処理できる — バッチ処理で時間短縮できるJSONataの採用により、ステートマシン定義が従来のJSONPathに比べてシンプルかつ読みやすくなります。新規のStep Functions構築にはJSONataの採用をおすすめします。

