
DX開発事業部 フルスタックセクションの田村です。
Google Cloud Next 2026 のイベントレポートを現地よりお届けいたします。
今回は「What’s new in Cloud Run」セッションを聴いてきました。
Cloud Runのプロダクトチームに加え、Replitのエンジニアリング副社長Scott Edward氏、そしてAnthropicのエンジニアMimi氏が登壇するという珍しい構成でした。
Cloud Runの今の立ち位置
セッションは「Cloud Run gives you on-demand computers」という一文から始まりました。

10秒で0から1万コンテナまでスケールアップ、使った分だけ100ミリ秒単位の課金、VMもクラスターも不要とし、これが基本の立ち位置として「AIワークロードにもこの原則をそのまま適用する」という方向でセッションの解説がされていました。

2025年の1年間で、外部の月間アクティブ開発者数とアプリケーション数が2倍になったということで、AIエージェント需要にともなうCloud Runの使用数も今後さらに増えていくと思います。
アジェンダは4つのテーマに整理されていました。
- Running vibe coded apps
- Running AI Agents
- Running AI models
- Running scalable apps
Cloud Runのアップデート情報に関するセッションでも、AI関連が上位3つを占めていることからも、Cloud RunにおいてAIエージェントが主戦場になっていることが分かりますね。
Running vibe coded apps
Spend caps(Coming Soon)
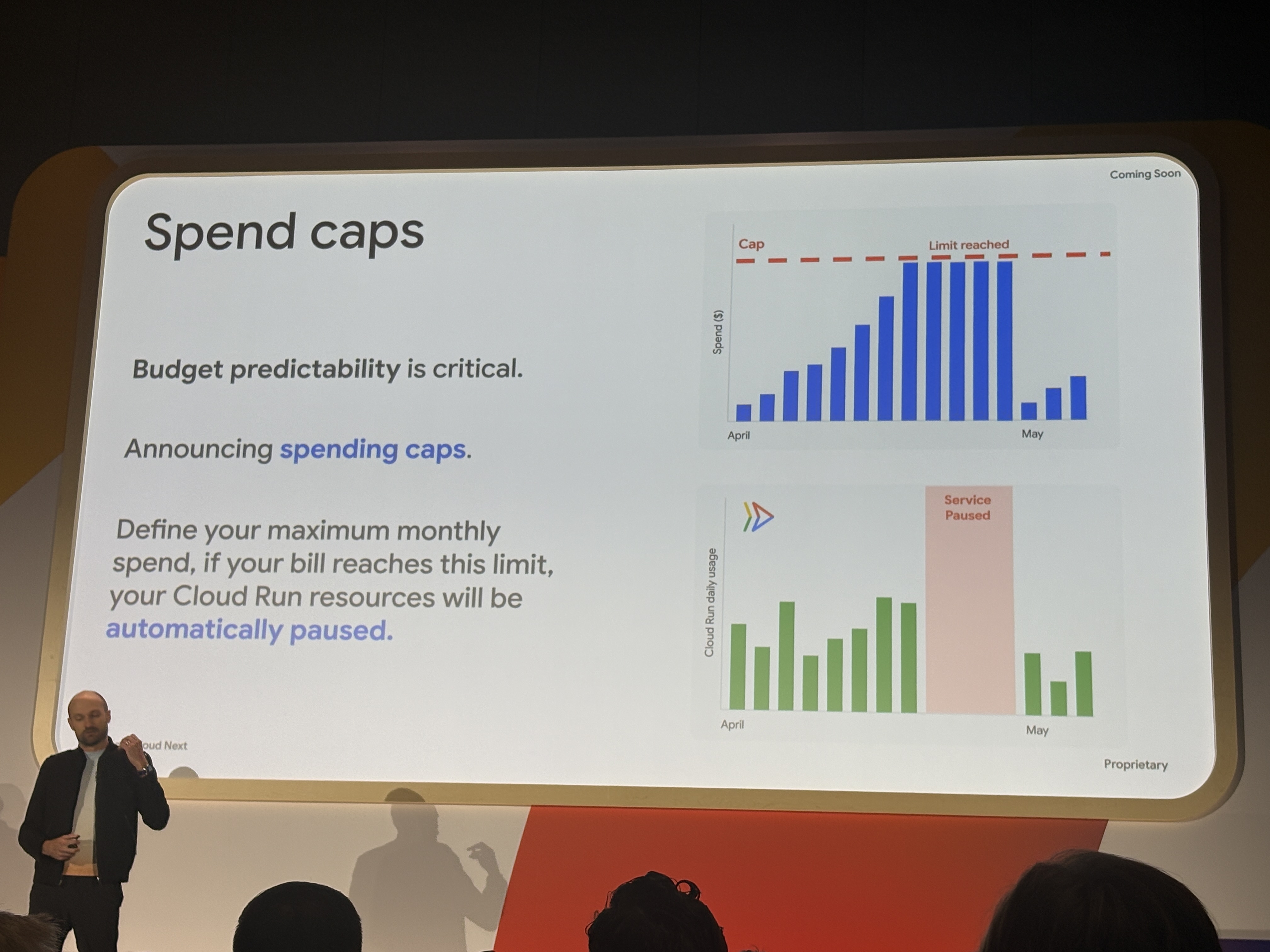
Gemini CLIやClaude Codeに代表されるコーディングAIによってバイブコーディングのアプリを誰でもデプロイできる時代になっています。ゆえに「課金が怖くて使いにくい」といった要望に対応するためSpend caps(支出上限)という機能が発表されました。
請求額がその上限に達した時点でCloud Runのリソースが自動停止します。
そのため例えば、個人開発者や学生がお試しでデプロイする際に、「気づいたら高額請求が来ていた」という最悪のケースを防げます。
Cloud Runは特に従量課金のため無限ループなどが発生したり、不正使用など想定外の利用があった場合に最悪の事態を防げるので有用な機能ですね。
Running AI Agents
AI Agents用の新しいワークロードが発表されました。

このワークロードは具体的に以下の要素で構成されています。
- ハーネス(モデルを呼び出す脳)
- 永続メモリ
- ツール(ローカルまたはリモート)
- サンドボックス(作業用のコンピューター)
Fully Managed MCP Server(GA)
Cloud Run上のサービスをエージェントから直接操作するためのMCPサーバーがGAになりました。

コンテナイメージ・ソースアーカイブ・ファイル内容の3つのデプロイ方法に加え、サービスの一覧取得・詳細確認が可能です。
会場のデモではClaude CodeがこのMCPを使ってNode.jsアプリをリアルタイムでデプロイするシーンが示されていて、「エージェントがコードを書いてそのままデプロイまで完結する」フローが実用レベルになったのを実感しました。
Gemini Enterprise Agent Platform連携(Private Preview)

Cloud Runにデプロイしたサービスに --functional-type AGENT を付けるだけで、Gemini Enterprise Agent Platformのエージェントレジストリに自動登録されます。(Gemini Enterprise Agent Platformは同日に発表されたVertex AIのリネーム後のサービスです)
専用のAgent Identityが付与され、中央集権的に保護されるようです。またMCPサーバーとして登録することも同じコマンドで可能とのことです(--functional-type MCP_SERVER)。
Cloud Run Sandboxes(Coming Soon)
エージェントが生成したコードを安全に実行するための専用機能が発表されました。

Cloud RunリソースからmicroVMベースの隔離サンドボックスを起動して、エージェントが生成したPythonコードやシェルスクリプト、さらにChromiumも実行可能とする機能です。
使い方もシンプルで、exec('sandbox do -- /usr/bin/python3 -c "..."') のように呼び出すだけで、ソースコードにも簡単に組み込むことができそうですね。
Coming Soonということですが早く試してみたいですね。
Cloud Run Instances(Private Preview)
インスタンスを個別に管理するための機能が発表されました。

通常のCloud Runサービス・ジョブとは異なり、個々のCloud Runインスタンスを直接作成・管理できます。
長時間実行・非同期・バックグラウンドエージェントに適した設計で、価格は$5.70/月(1CPU shared + 1GiB)。@google-cloud/run のSDKからも操作できます。
特に注目したのはSSHのサポートです。

gcloud run services ssh frontend の一行で稼働中のCloud RunコンテナにSSH接続できます。
IAPとOS Loginで認証されるため、セキュリティが担保された上でのログインができますし、「コンテナの中で何が起きているかわからない」というログだけでは追いづらい本番デバッグの辛さに直接応える機能かと思います。
Built-in dev loop 機能も近日公開として発表されました。

これはコマンドでローカルフォルダとCloud Run間を同期させて、変更がCloud Runインスタンスにリアルタイムに反映される様になります
通信上の問題等でCloud Runにデプロイしつつ開発をしたい場合に使用可能な便利な機能ですね。
Running AI models
NVIDIA RTX PRO 6000 Blackwell(GA)
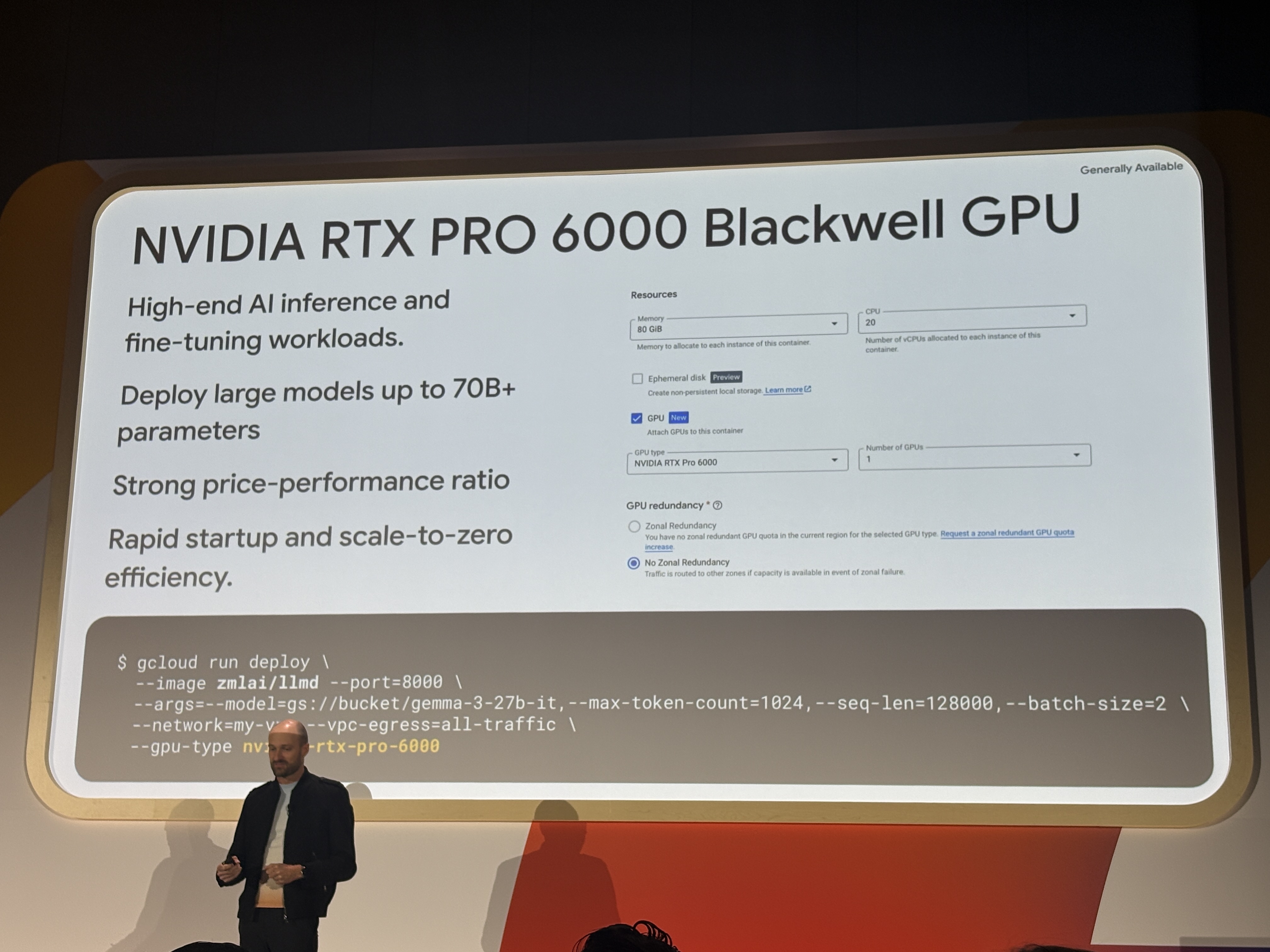
VRAM 80GiB、20 vCPUのNVIDIA RTX PRO 6000 BlackwellがCloud RunのGPUオプションとしてGAになりました。70B以上のパラメータを持つモデルをデプロイできるサイズです。
--gpu-type nvidia-rtx-pro-6000 の一行を追加するだけで、スケールtoゼロ・秒単位課金のCloud RunのメリットをそのままGPU推論に使えます。
最近はCloud Runにもモデルを搭載するケースでGPU需要がありますので、よりこのユースケースにおいて高性能なリソースを使えるようになりますね。
GPU Jobs + Delayed Jobs(Private Preview)

サービスだけでなくジョブにもGPUサポートが追加されました。
具体的にRTX PRO 6000を使った長時間ファインチューニングのユースケースが想定されているようです。
またDelayed Jobsという機能も発表されています。
最大12時間の遅延実行で以下の様なケースでコスト最適化を行うことが可能になります。
- GPUリソースが安い時間帯に実行する
- 時間感度の低いAI/MLバッチ処理をスケジューリングする
Ephemeral disk(Preview)
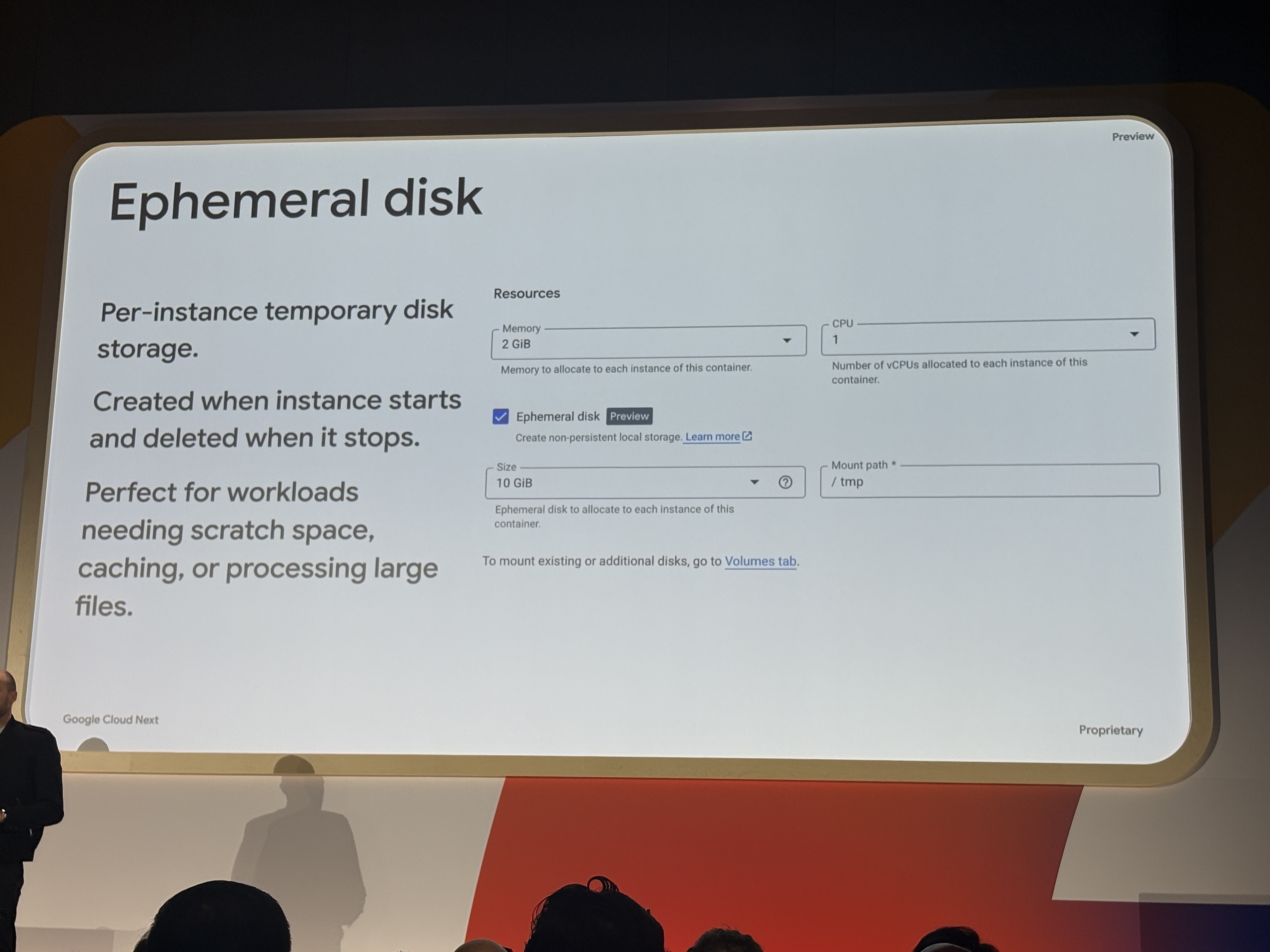
インスタンスが起動すると作成され、停止すると削除される一時ディスクをマウントできます。
こちらのアップデート自体はNextの3日前に公開されていた機能です。
推論の中間ファイル処理、大きなファイルのキャッシュ、スクラッチスペースとして使用可能です。
Cloud Runでサイズの大きなファイルを扱ったり、大量のファイルを操作しているとメモリ枯渇(OOM)によく遭遇します。これまでは「メモリだけでは乗りきれない大きなファイルを扱いたい」というファイル処理の解決策になる重要なアップデートだと思います。
Running scalable apps
Scaling controls(Preview)

Cloud Runのスケーリング部分にもカスタム設定を適用できるようになりました。これまではCloud Runのオートスケーラーが自動で判断してましたが、スケーリングに柔軟性が出てきました。
ほとんどのユーザーはそのままのオートスケーラーで十分ですが、コスト最適化や特殊なトラフィックパターンを持つワークロードで使う場面がありそうですね。
Worker Pools(GA)
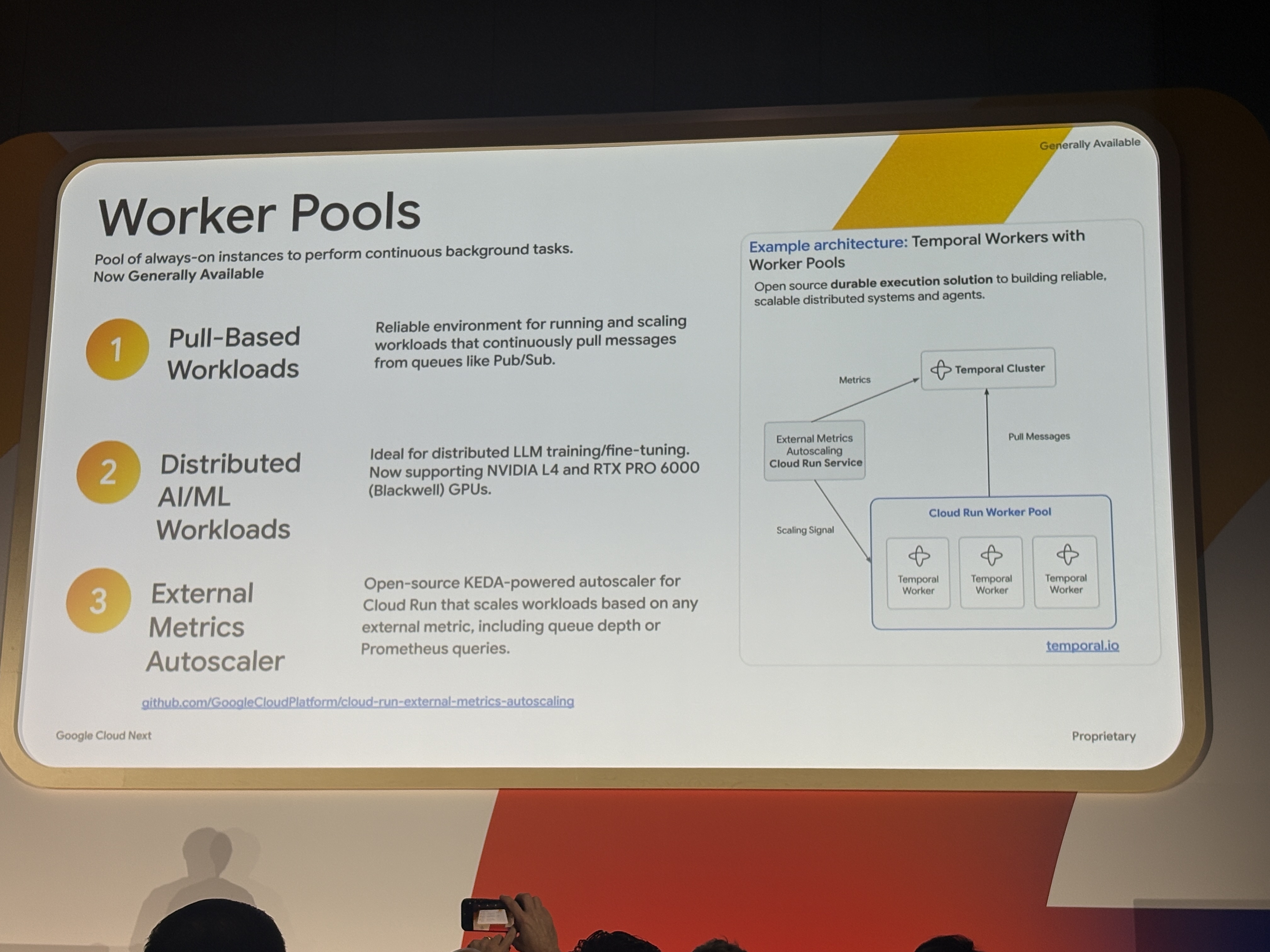
リクエストベースではない常時稼働インスタンスプールがGAになりました。
こちらは昨年のGoogle Cloud Nextで発表された機能ですがついに一般公開です。
主に3つのユースケースで整理されています。
- Pull-Based Workloads:Pub/Subなどからメッセージを継続的にpullするキュー処理
- Distributed AI/ML Workloads:分散LLMトレーニング・ファインチューニング(NVIDIA L4・RTX PRO 6000対応)
- External Metrics Autoscaler:KEDAベースのオープンソース自動スケーラー、キュー深度やPrometheusクエリで動的スケール
Temporalとの連携事例が紹介されていて、TemporalワーカーがCloud Run Worker Poolsの上でKEDAを使って動的スケールするアーキテクチャが示されていました。
Kubernetesクラスターなどを管理せずにこれができるのがポイントですね。
Service Bindings(Private Preview)

Cloud Run同士のサービス間通信を簡略化する機能です。
gcloud network-services service-bindings create でソース・デスティネーションを紐付けると、JWTの注入と監視が自動化されます。
バックエンドサービスを `curl https://backend` のようなシンプルなURLで呼べるようになり、複雑なネットワーク設定や手動の認証構成が不要になるのはマイクロサービス運用者には嬉しいです。
セッション全体を振り返って
個人的に一番興味深かったのはCloud Run Instancesです。「インスタンスを個別に管理できる」「SSHで入れる」「ローカルとリアルタイム同期できる」という機能群は、今後のAIエージェントの更なる需要増加を見越してより開発しやすく、より運用しやすくという点でサポートが強化されていますね。
Cloud Run SandboxesとInstancesが揃えば、エージェントのハーネス・サンドボックス・ツールを全部Cloud Runで完結させるアーキテクチャが現実的になりそうですね。




