
きっかけ
New RelicでGoogle Cloudリソースの監視を試みた際、取得できないメトリクス(UnhealthyHost)があったため、Google Cloudが提供しているサービスを利用した方が良いのでは?と感じて、Google Cloudの監視サービスでどこまで監視できるのかを確かめたいと思ったため
使用するサービス
監視対象リソース及び監視項目・閾値
監視対象リソース
- Compute Engine
- OSはdebian-12-bookworm-v20250812
- サイズはe2-medium
- Cloud SQL
- エンジンバージョンはMySQL 8.0.41
- ロードバランサー
- グローバル外部アプリケーション ロードバランサ
監視項目・閾値
Compute Engine (インスタンス)
死活監視
| 監視するリソース | 監視する内容 | 閾値 |
|---|---|---|
| Compute Engine | エージェント応答 | エージェント応答無し |
リソース監視
| 監視するリソース | 監視する内容 | 閾値 |
|---|---|---|
| Compute Engine | CPU使用率 | 90%超過 |
| Compute Engine | メモリ使用率 | 90%超過 |
| Compute Engine | ディスク使用率 | 90%超過 |
プロセス監視
| 監視するリソース | 監視する内容 | 閾値 |
|---|---|---|
| Compute Engine (Debian) | sshdプロセス | プロセス数 0 |
| Compute Engine (Debian) | systemd-timesyncdプロセス | プロセス数 0 |
| Compute Engine (Debian) | rsyslogdプロセス | プロセス数 0 |
| Compute Engine (Debian) | cronプロセス | プロセス数 0 |
| Compute Engine (Debian) | apache2プロセス | プロセス数 0 |
Cloud SQL
リソース監視
| 監視するリソース | 監視する内容 | 閾値 |
|---|---|---|
| Cloud SQL | CPU使用率 | 90%超過 |
| Cloud SQL | ディスク使用率 | 90%超過 |
| Cloud SQL | メモリ使用率 | 95%超過 |
Load Balancer
| 監視するリソース | 監視する内容 | 閾値 |
|---|---|---|
| Cloud Load Balancer | レイテンシ | 10秒超過 |
| Cloud Load Balancer | UnHealthyHost数 | 0超過(1以上) |
今回の目標
リソース監視を行い、アラート発生時にメールでお知らせするようにすること
事前確認
指標の収集の概要 ページを見てみると、Compute Engineの一部メトリクス以外は自動で収集されている様子
自動で収集されないメトリクスは、エージェント(Ops エージェント)をインストールして取得する様子でした
しかし、エージェントに関しては、私の場合はCompute Engineを起動してしばらくすると、画像のようにエージェントが動いているようだったので、使用するOSによってはプリインストールされていると思われます
ひとまず、現状各リソースでGoogle Cloudによって自動収集されているメトリクスと、そのメトリクスで監視項目が満たせるか確認してみます
Compute Engine
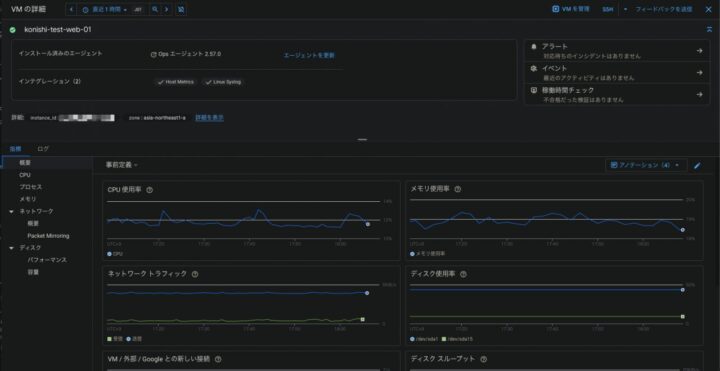
[Monitoring] > [Dashboards] から「VM Instances」を選び、詳細画面を開きます
CPU使用率やプロセスなど、基本的なメトリクスは取れており、Opsエージェントもインストールされているため、特に追加の作業なしでアラート作成に進めそうです
CloudSQL
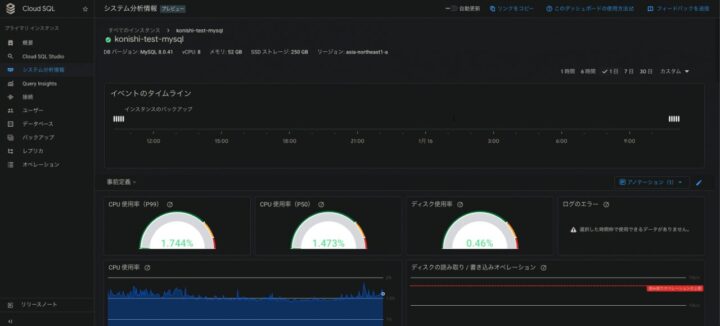
CloudSQLは元々Google Cloudがメトリクスを取得してくれており、CloudSQL > 情報を見たいインスタンスを選んで「システム分析情報」のタブを開くと、画像のようにメトリクスを確認できます。今回、対象の監視項目はすでにメトリクスが取得できているようでした(画像では見切れていますが、このページの下の方にメモリ使用率のグラフがあります)
ロードバランサー
こちらもCloudSQLと同様に、Google Cloudが自動でメトリクスを取得してくれます
レイテンシについては、[Monitoring] > [Dashboards] から「External HTTP(S) Load Balancers」を選び、ロードバランサーの詳細画面を開くと、すでにメトリクスが確認できます
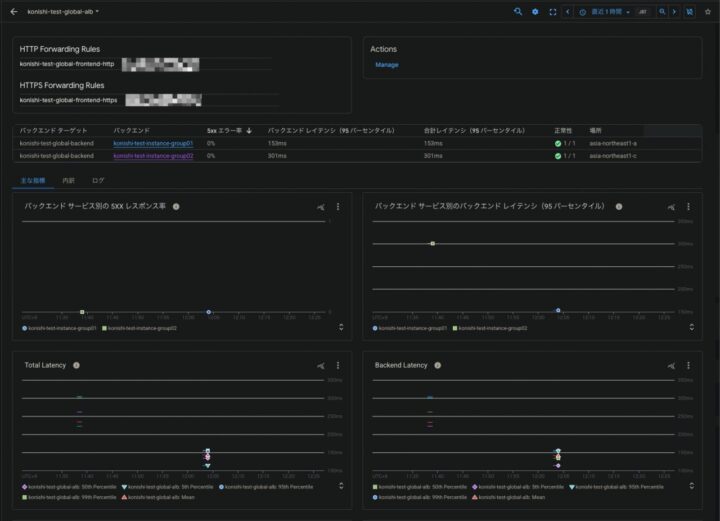
UnHealthyHost監視については、Google Cloudではロードバランサーが使用するバックエンドサービスの稼働の監視がこれに当たると判断しました
こちらはロードバランシング > 情報を見たいロードバランシングを選んで「モニタリング」を開き、詳細を開くとバックエンドサービスの状態が確認できるので、これを監視します
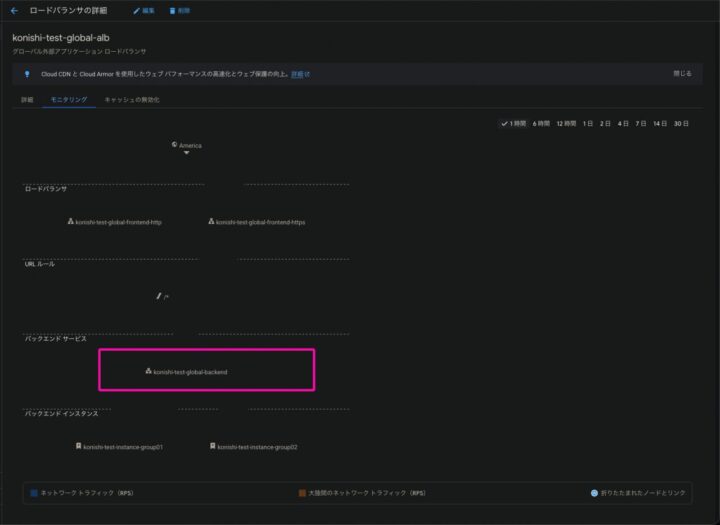
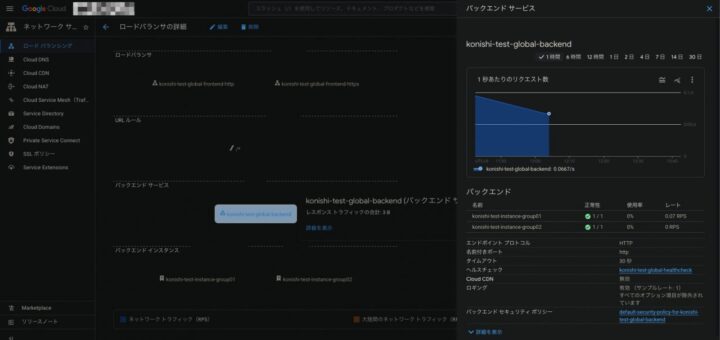
以上で、監視対象となるメトリクスが取得可能である(=監視対象にできる)ことを確認できました
次はアラートポリシーを設定していきます
アラートポリシーの作成
アラートポリシーの作り方はアラート ポリシーを作成する方法 を参考にします
[Monitoring] > 「Create Policy」からポリシーを作成します
Compute Engine
死活監視
“Monitoring/Logging Agent Uptime”というメトリクスを使用します
VM Instance > agent > Monitoring/Logging Agent Uptime と選んでいきます
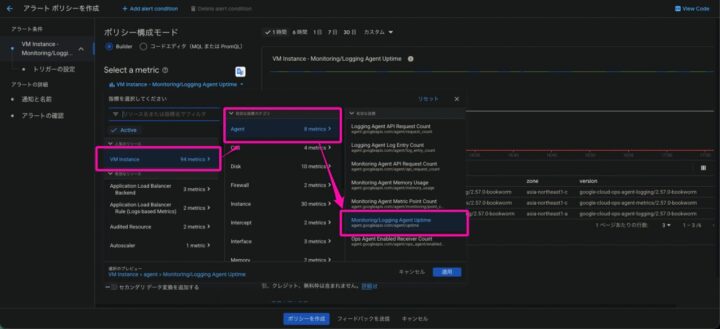
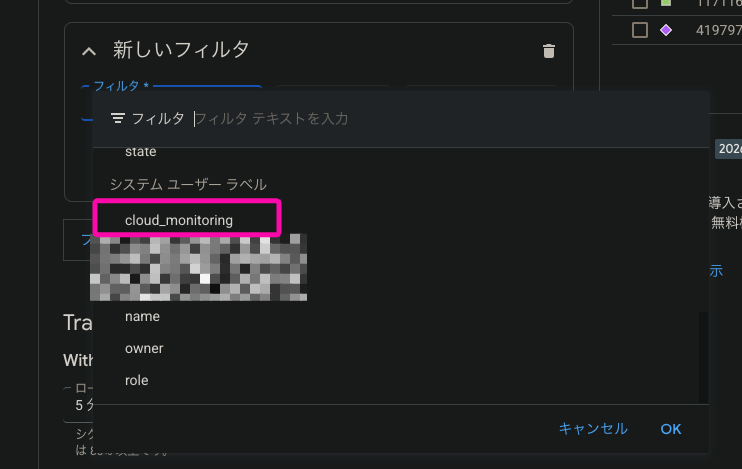
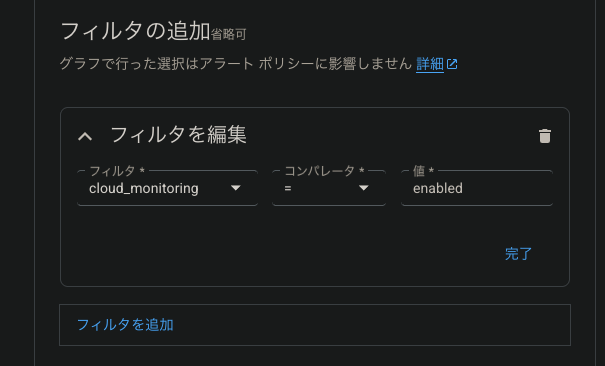
今回は監視対象のリソースにはcloud_monitoring:enabledのラベルをつけて、ラベルで監視対象の絞り込みを行います
そのため、「システムユーザーラベル」でフィルタを追加し、ラベルで絞り込みを行います
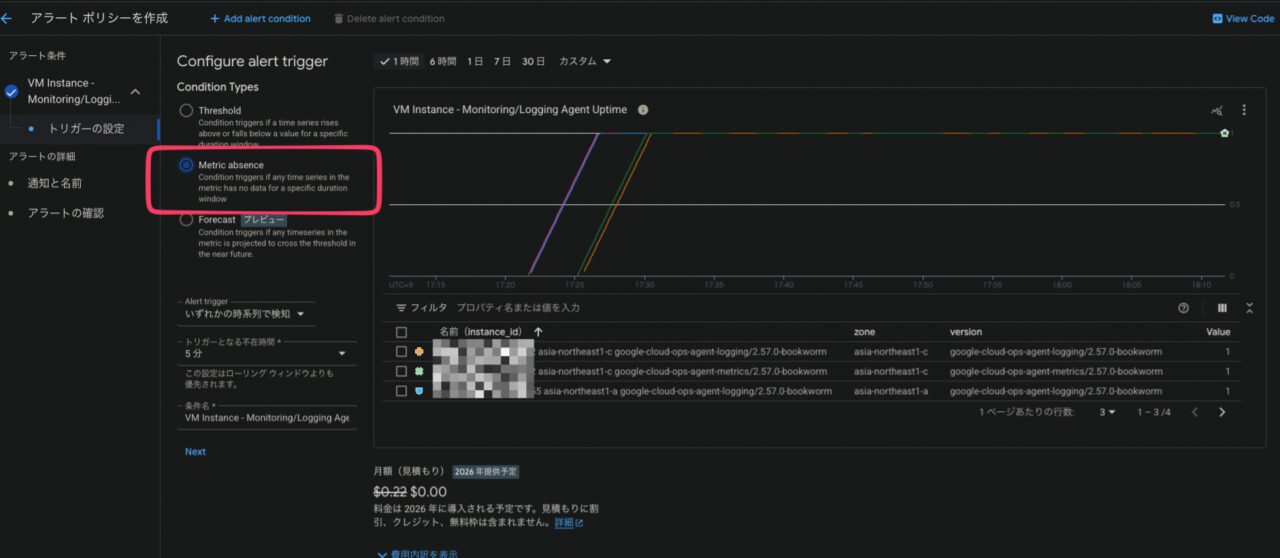
次は閾値ですが、今回は死活監視なので、”Metric absence”を選びます
閾値(x分メトリクスが送られていなければアラート発報)は5分にします
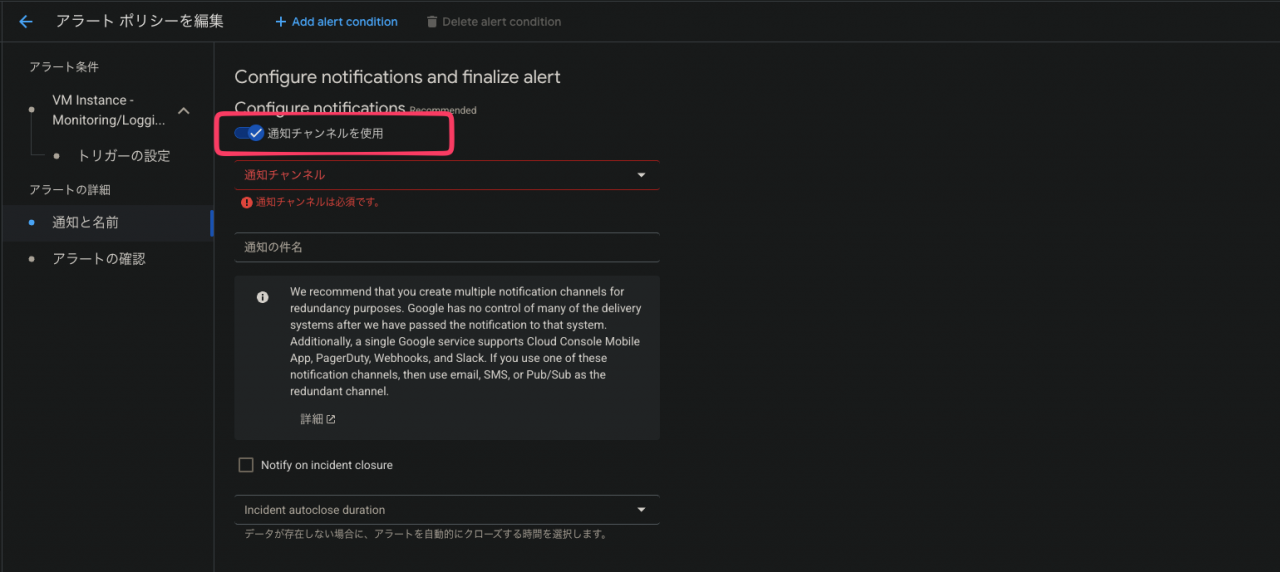
次はアラート発報先を設定します(なお、アラート発報先を設定しなくてもアラート自体は作成可能です)
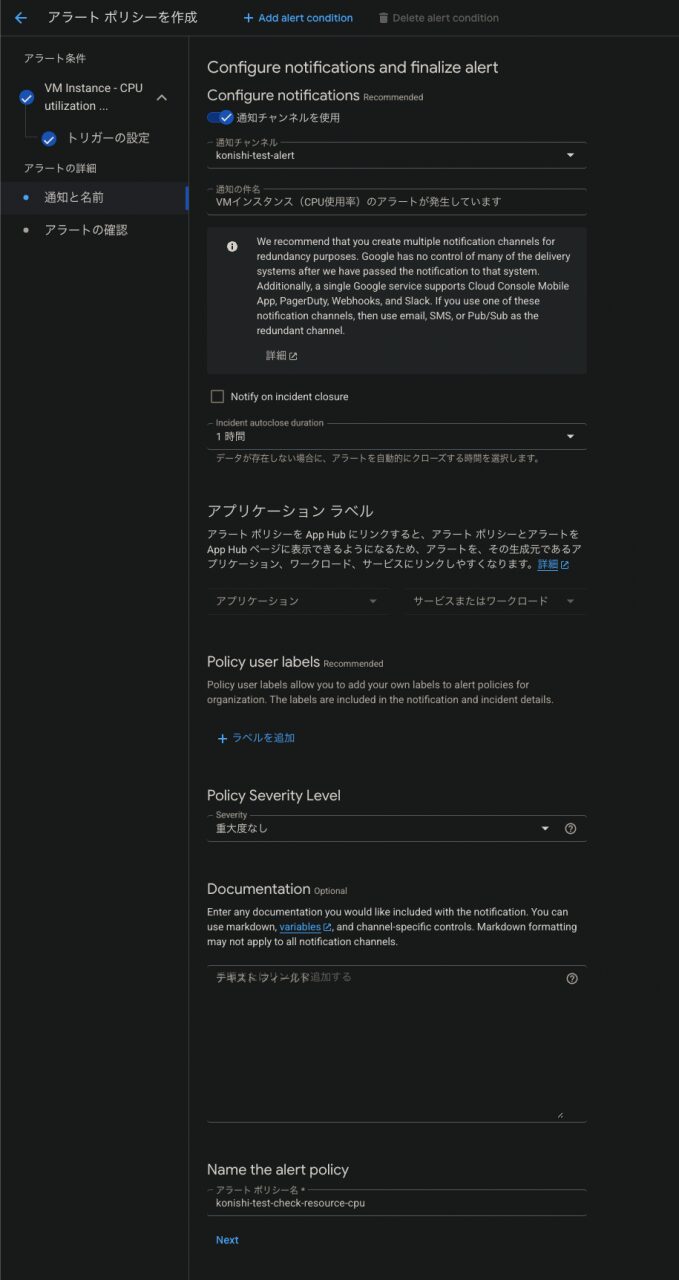
まず、「通知チャンネルを使用」ボタンをONにします
新規で通知チャンネルを設定する場合は、通知チャンネルの欄を開き、「Manage Notification Channels」を開きます
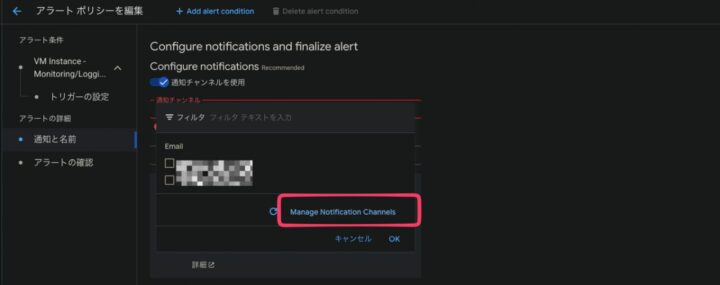
画像のように、PagerDutyやSlack、メールなどを通知先として設定できます
今回はメールを設定します
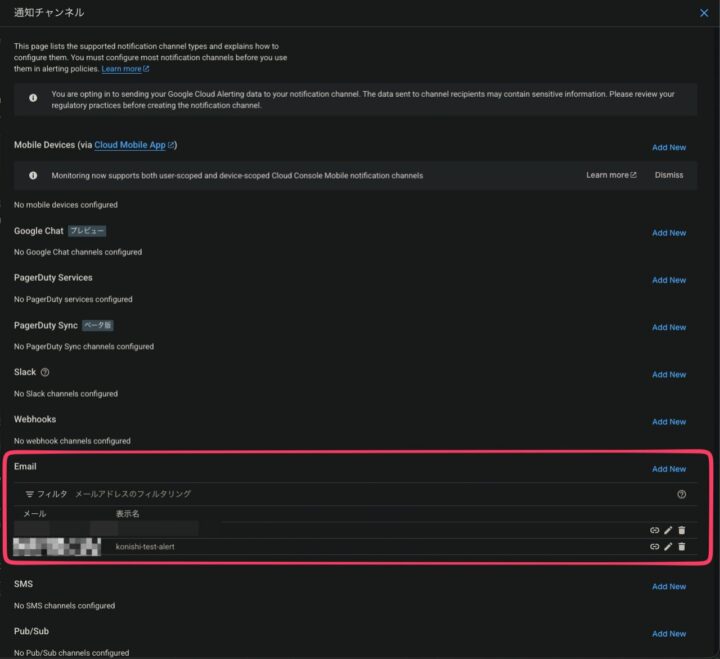
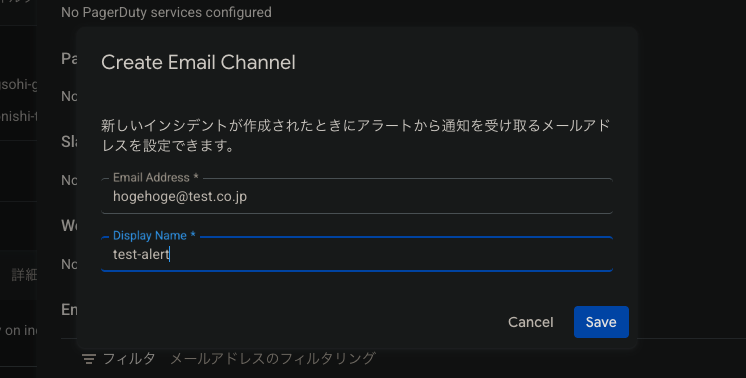
メールの追加をする際は、右端の「Add New」をクリックし、メールアドレスと表示名を設定します
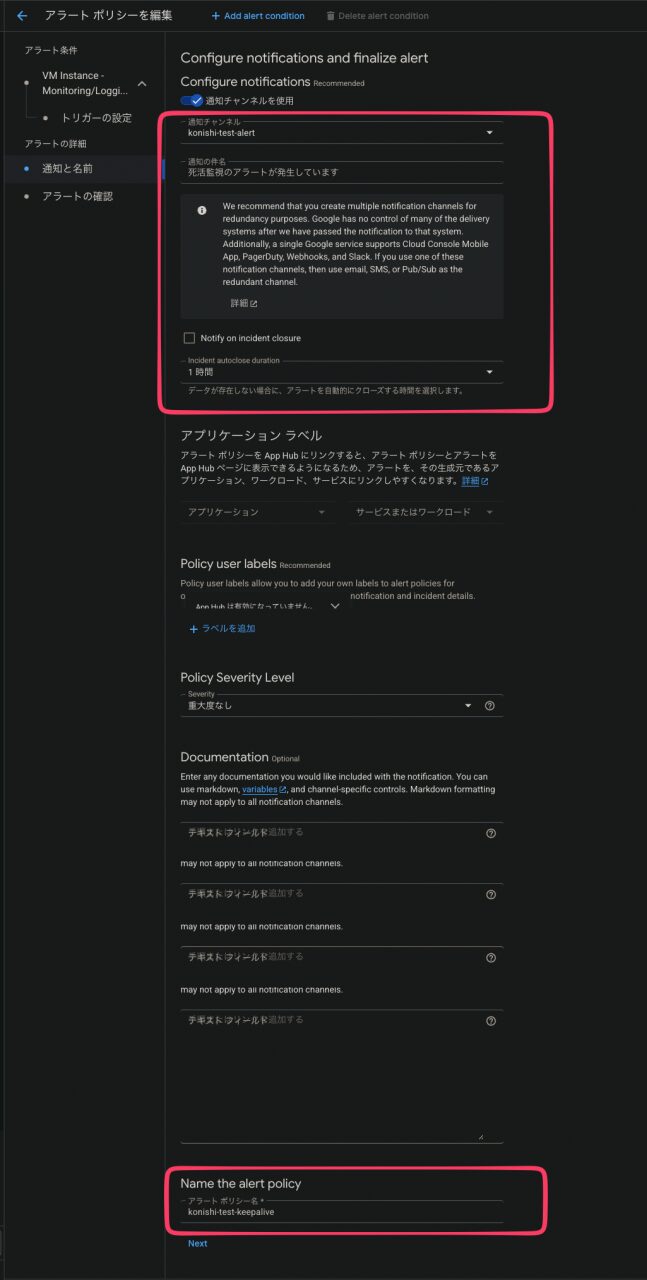
作成した通知チャンネルと通知件名、Incident autoclose duration(一定期間メトリクスが届かなければアラートをクローズする)、アラートポリシー名を設定します
Incident autoclose durationは今回1時間で設定します
リソース監視
CPU使用率
メトリクスはVM Instance > instance > CPU utilizationを選びます
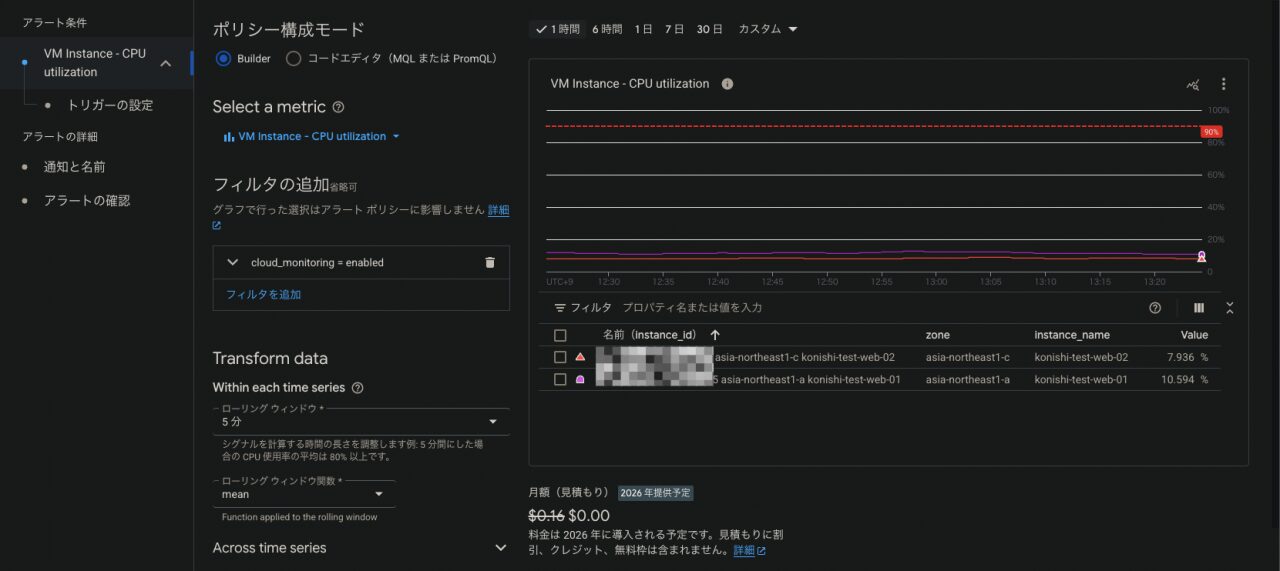
閾値は90%以上で設定します
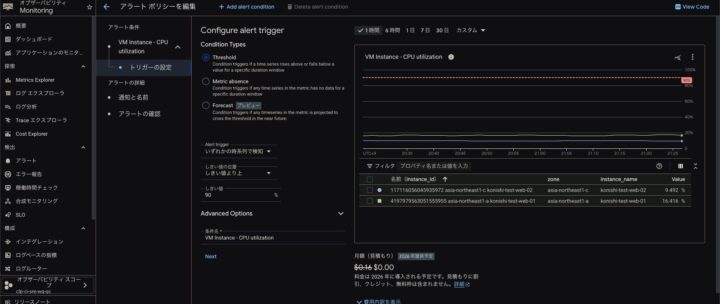
通知チャンネルとIncident autoclose durationは死活監視と同じ、通知件名とアラートポリシー名は適宜設定します
メモリ使用率
- メトリクス:VM Instance > memory > Memory utilization
— フィルタ:ラベルと、「state=used」で絞る
— タグのみだと「使用されているメモリの割合」は絞りきれません
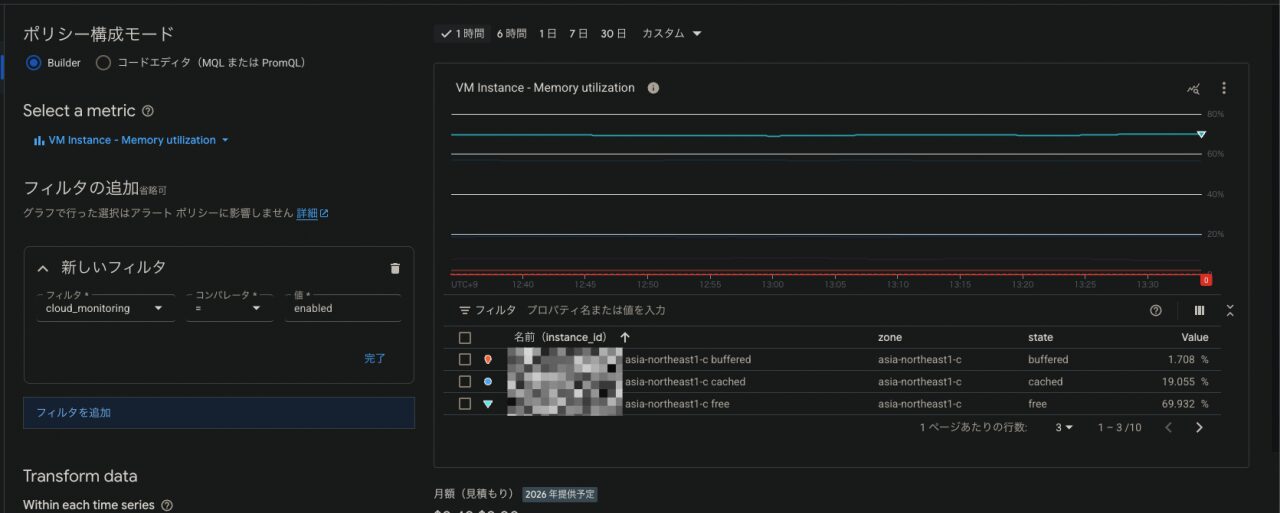
- 「state=used」で絞ると、メモリ使用率が確認できます
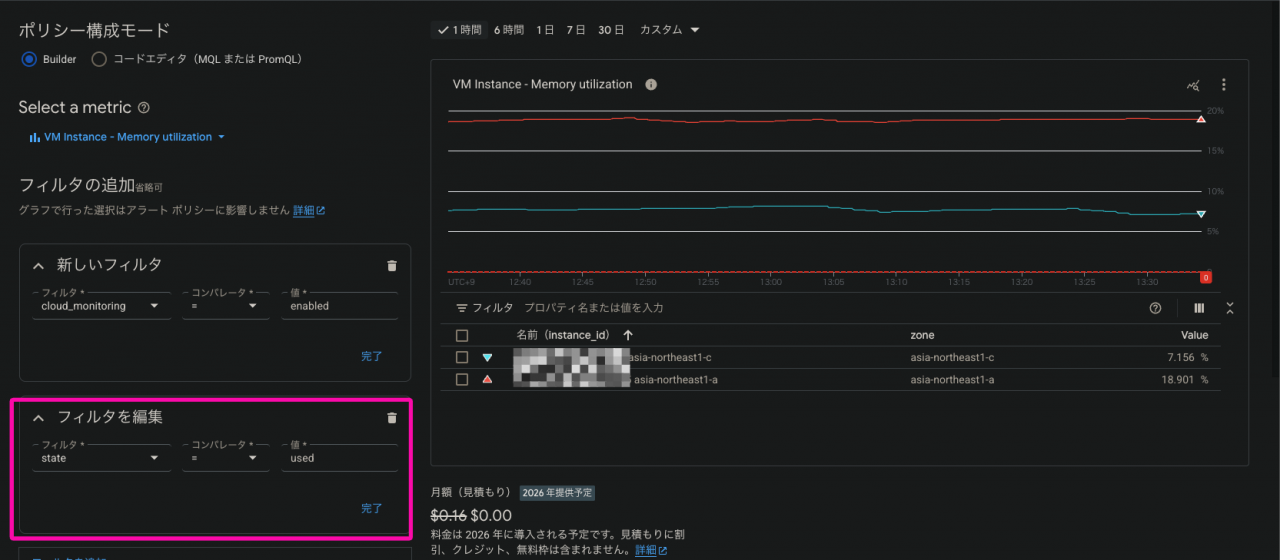
- 閾値:90%以上
- その他の設定は他の監視項目と同様
ディスク使用率
- メトリクス:VM Instance > disk > Disk utilization
- フィルタ:ラベルと「state=used」で絞る
- 閾値:90%以上
- その他の設定は他の監視項目と同様
プロセス監視
sshdプロセス0
- メトリクス:VM Instance > processes > Process CPU
- フィルタ:ラベルと「command=sshd」で絞る
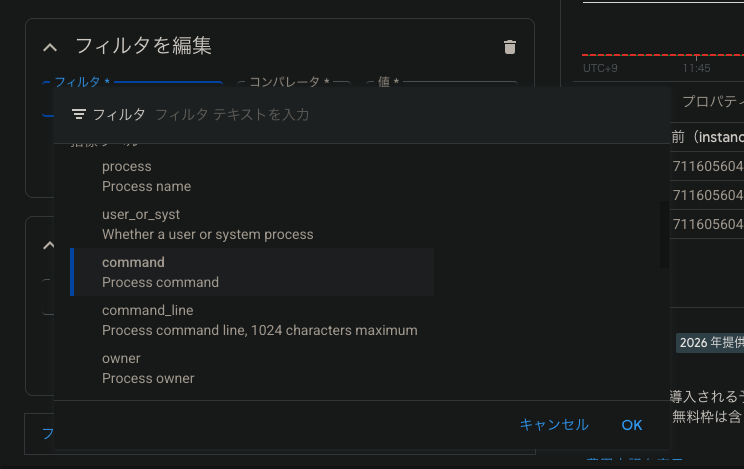
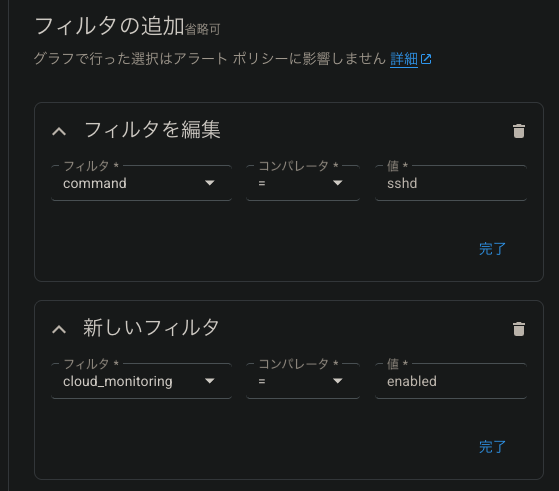
- 閾値:プロセスが停止=ログがない、でアラートを上げたいので「Metric absence」を選択
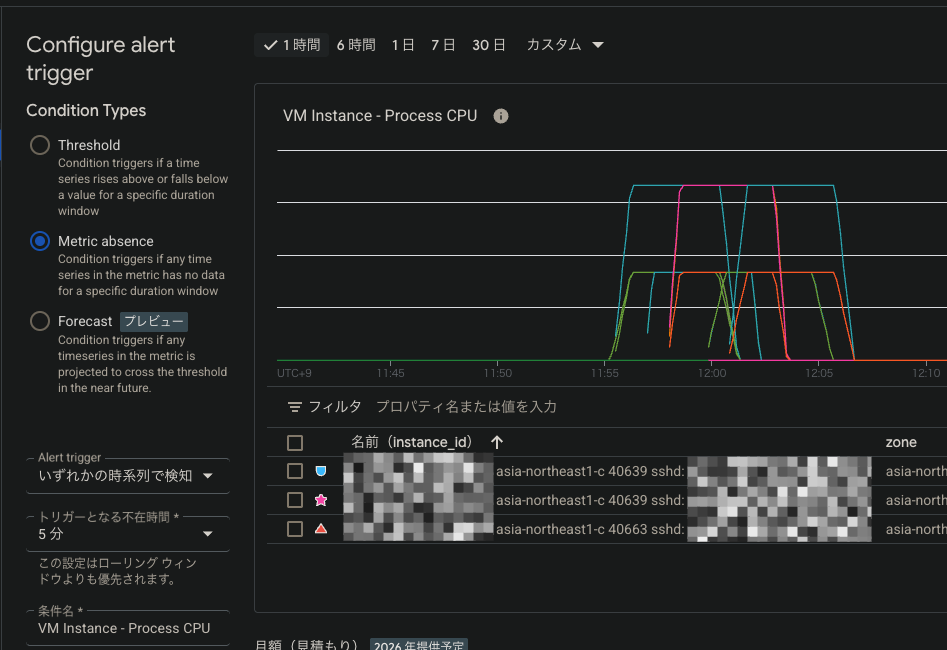
- その他の設定は他の監視項目と同様
systemd-timesyncdプロセス0
- メトリクス:VM Instance > processes > Process CPU
- フィルタ:ラベルと「command=systemd-timesyncd」で絞る
- 閾値:Metric absence
- その他の設定は他の監視項目と同様
rsyslogプロセス0
- メトリクス:VM Instance > processes > Process CPU
- フィルタ:ラベルと「command=rsyslogd」で絞る
- 閾値:Metric absence
- その他の設定は他の監視項目と同様
cronプロセス0
- メトリクス:VM Instance > processes > Process CPU
- フィルタ:ラベルと「command=cron」で絞る
- 閾値:Metric absence
- その他の設定は他の監視項目と同様
apache2プロセス0
- メトリクス:VM Instance > processes > Process CPU
- フィルタ:ラベルと「command=apache2」で絞る
- 閾値:Metric absence
- その他の設定は他の監視項目と同様
CloudSQL
CPU使用率
Compute Engineと設定方法はあまり変わりません
- メトリクス:Cloud SQL Database > database > CPU utilization
- フィルタ:cloud_monitoring:enabledのラベルで絞り込み
- 閾値:90%以上
- その他の設定は他の監視項目と同様
ディスク使用率
- メトリクス:Cloud SQL Database > database > Disk utilization
- フィルタ:cloud_monitoring:enabledのラベルで絞り込み
- 閾値:90%以上
- その他の設定は他の監視項目と同様
メモリ使用率
- メトリクス:Cloud SQL Database > database > Memory utilization
- フィルタ:cloud_monitoring:enabledのラベルで絞り込み
- 閾値:90%以上
- その他の設定は他の監視項目と同様
ロードバランサー
レイテンシ監視
- メトリクス:Global External Application Load Balancer Rule > https > Total latency
- フィルタ:ロードバランサーにはラベルがつけられないため、バックエンド名(backend_target_name)で絞り込む
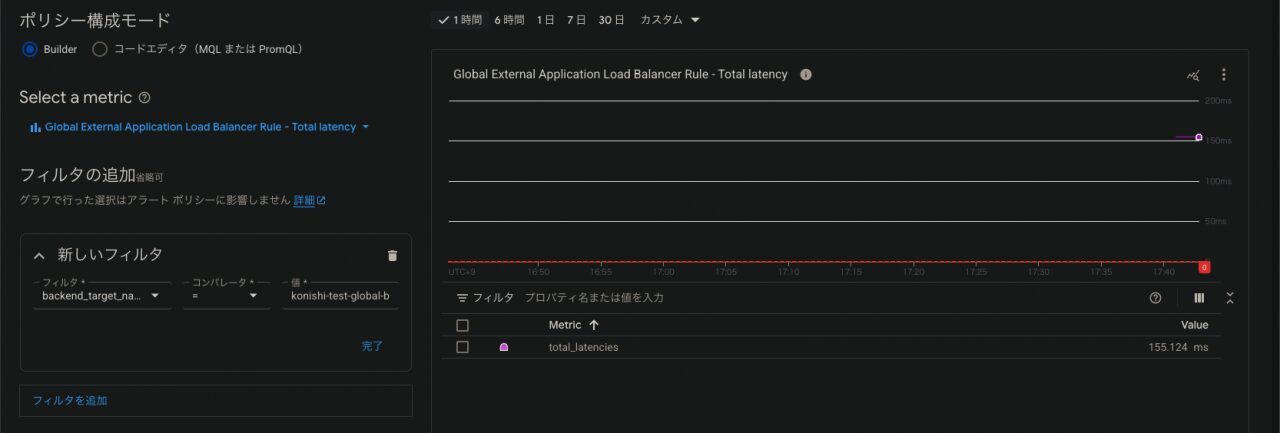
- ローリングウィンドウ関数:パーセンタイルのことです。とりあえず99にしておきます
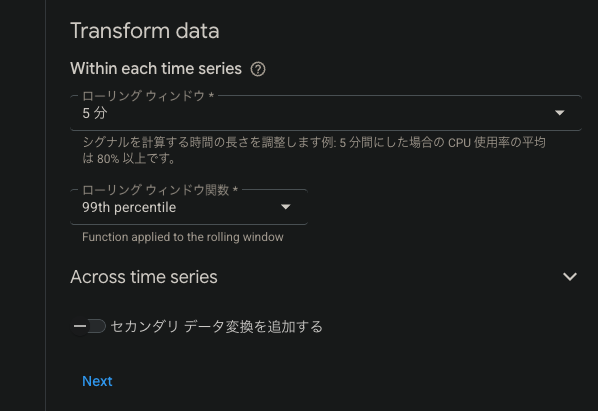
- 閾値:10ms以上
- その他の設定は他の監視項目と同様
バックエンドサービスの健全性監視(UnHealthyHost監視)
これまではアラート作成画面でメトリクスを選択してアラートを作成しましたが、この監視項目を直接的に監視できるメトリクスはありません
そのため、今回は、「ヘルスチェックのログを取る→ログを監視して、”Unhealthy”の文言が出たらアラートを上げる」という方法で監視を設定してみたいと思います
ヘルスチェックのログを設定する
Compute Engine > ヘルスチェック > 監視したいヘルスチェックの詳細画面を開き、「ログ」部分を確認する
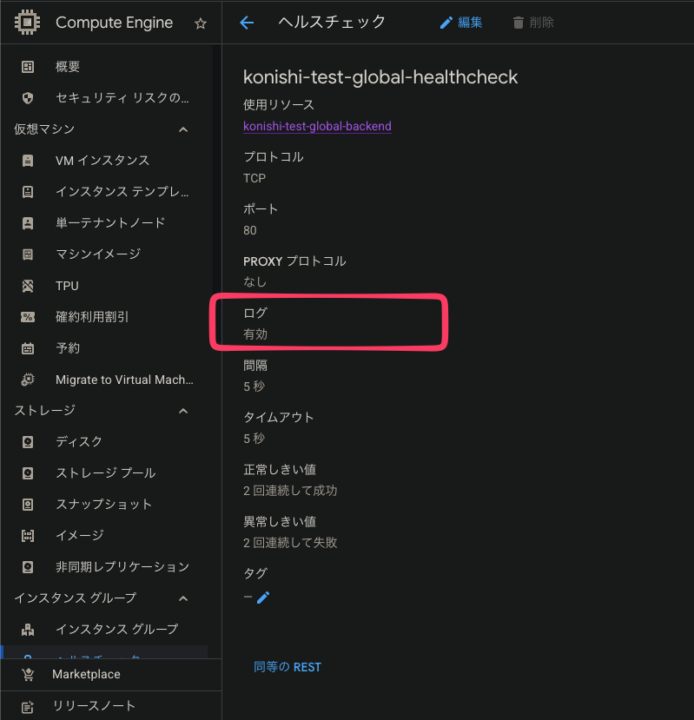
もし有効になっていなかったら有効にする
ログベースの監視を設定する
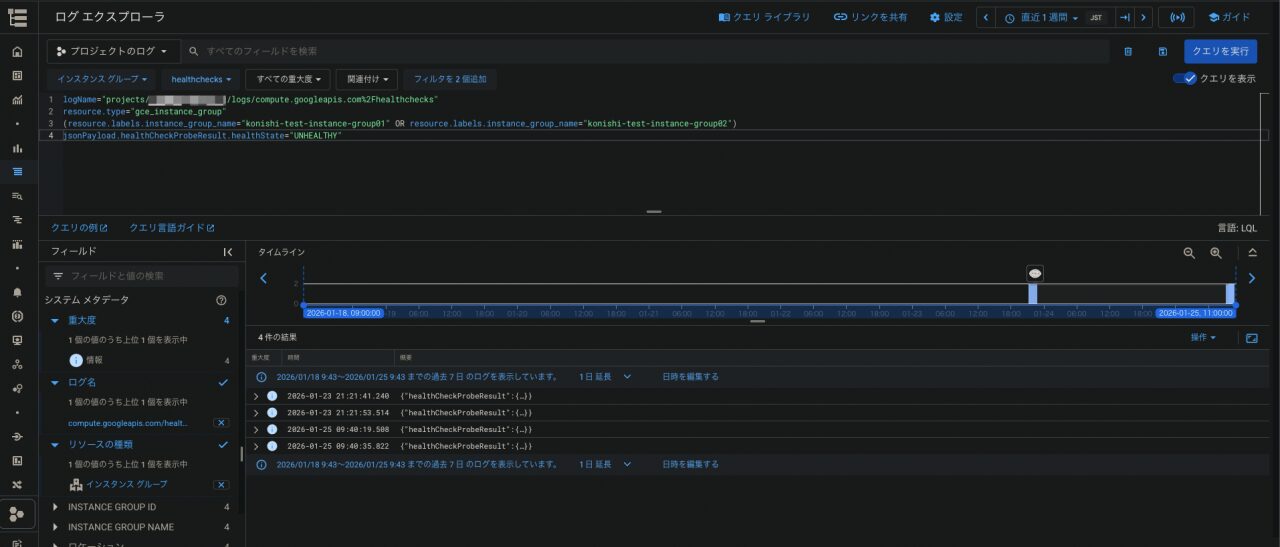
Cloud Monitoring > ログエクスプローラーで、以下のようなクエリを実行する
特定のインスタンスグループのヘルスチェックで、healthstateがunhealthyになったら通知、というクエリです
※projects/hogehoge-fugafugaの部分は、実際のPJ IDです
logName="projects/hogehoge-fugafuga/logs/compute.googleapis.com%2Fhealthchecks" resource.type="gce_instance_group" (resource.labels.instance_group_name="監視対象のインスタンスグループ名1" OR resource.labels.instance_group_name="監視対象のインスタンスグループ名2") jsonPayload.healthCheckProbeResult.healthState="UNHEALTHY"
このログはヘルスチェックに変化がないとログが出ないので、わざとインスタンスを停止させます
すると、このようにログが出てきます
操作メニューを開き「ログアラートの作成」を選択します
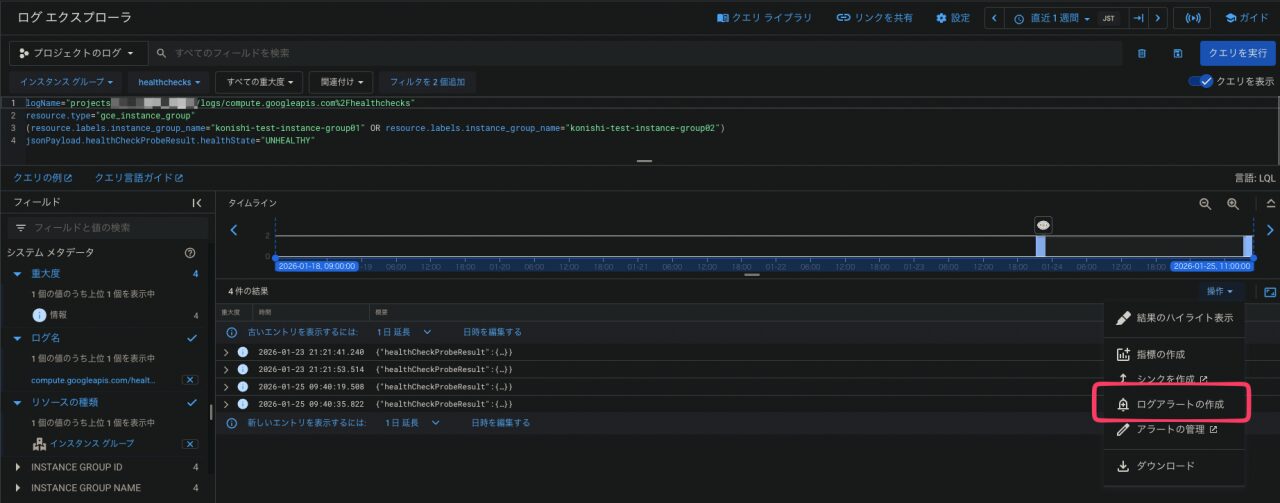
詳細画面で、アラート名やアラート対象のログ、通知頻度などを設定します
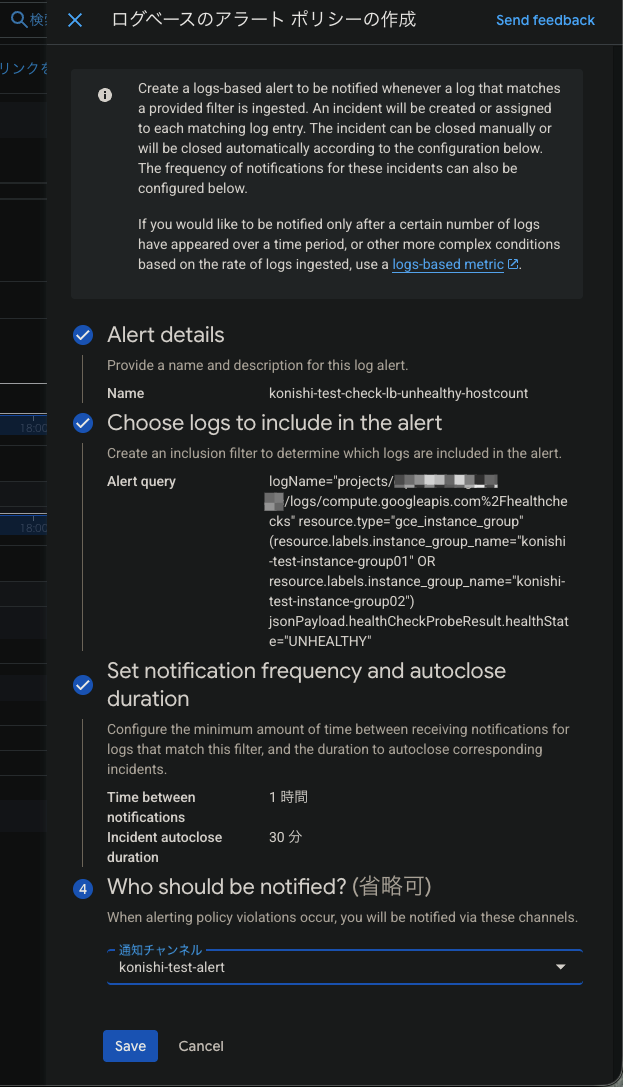
このようにアラートが作成できました
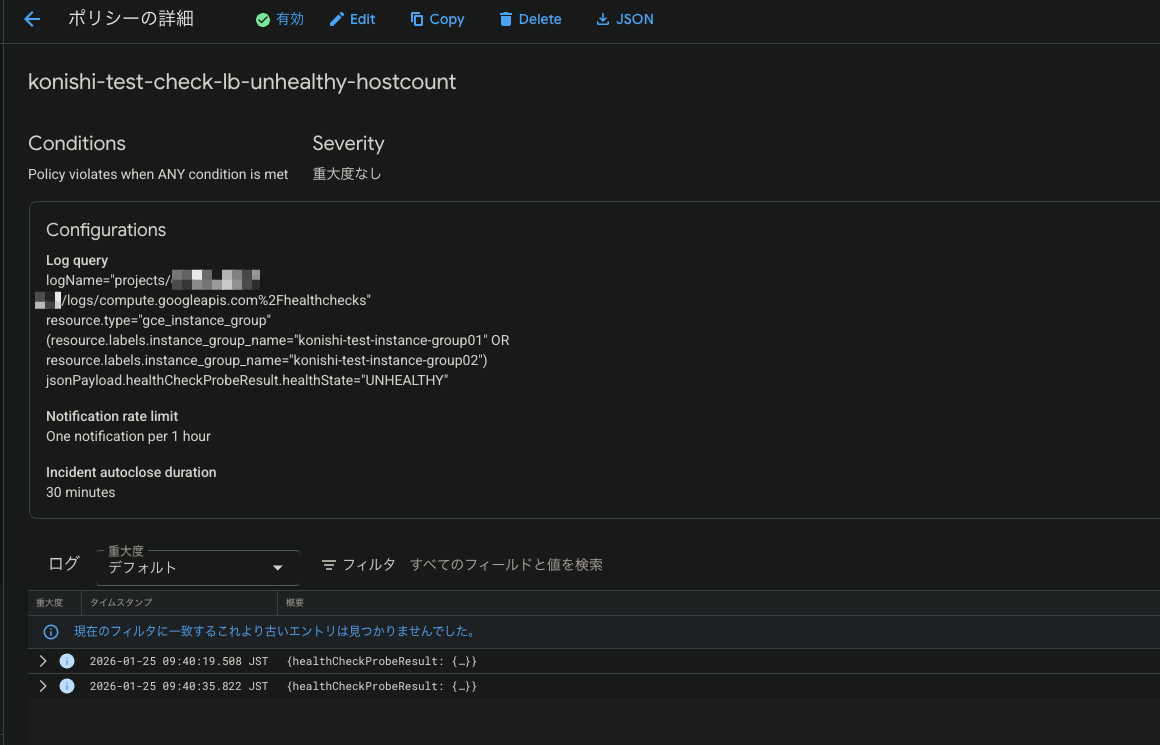
通知チェック
アラートが作成できたので、試しにVMインスタンスを停止させ、Ops Agentの死活監視のアラートを上げてみます
インスタンスを停止させてしばらくすると、アラートがこのようにメールで飛んできました
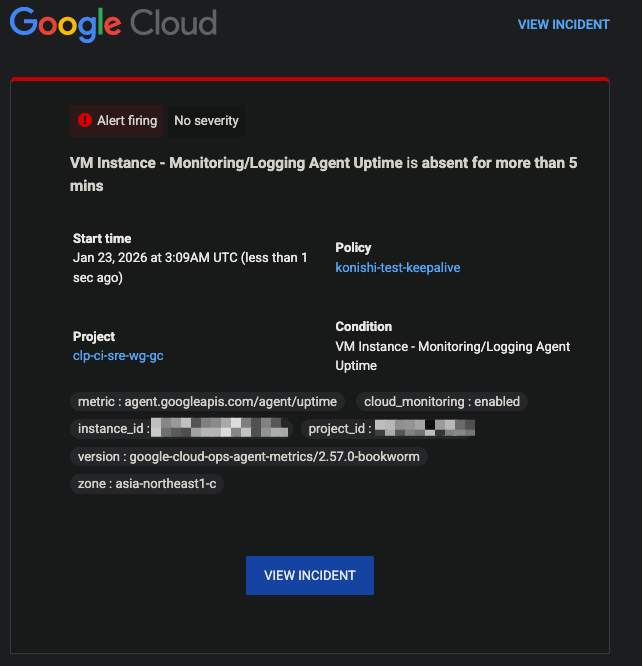
インスタンス名が直接書かれていないので若干分かりにくいですが、アラートが上がっていること、どのインスタンスで派生しているかは確認できます
これでCloud Monitoringを使用したリソース監視→アラート発報が完了しました
感想
筆者はこれまで監視といえばNew RelicもしくはDatadogが中心で、クラウドサービスの機能を利用した監視は初めて設定しました
不慣れなこともあり、今回は少数のメトリクスに対する単純な「監視→通知」のシステムしかできませんでしたが、次回は例えばPub/Subと組み合わせてログ監視、やSSL証明書の期限監視など、より発展的な内容にチャレンジしてみたく思います


