
概要
IaaS のサービスを中心に稼働状況の把握に役立つサービスにふれる機会があったため、その際に確認した内容を纏めます。
Google Cloud ではシステムの稼働状況を手っ取り早く把握するための方法が準備されています。
その把握に当たって、サービスによっては Observability タブがあったり、指標というタブがあったり、はたまたモニタリングと呼ばれる項目内でメトリクス情報が纏められています。
そのタブや項目でどのようなことがわかるか、また、より詳細に把握するためにはどのような Google Cloud のサービスで把握が可能か、について記載します。
詳細
Observability タブ
Observability タブがどのサービスで表示されているか確認したところ、確認した範囲では GCE、GKE で確認できました。
GCE と GKE、Cloud Storage では以下のように表示される内容が異なりました。
GCE
以下サンプルとなります。
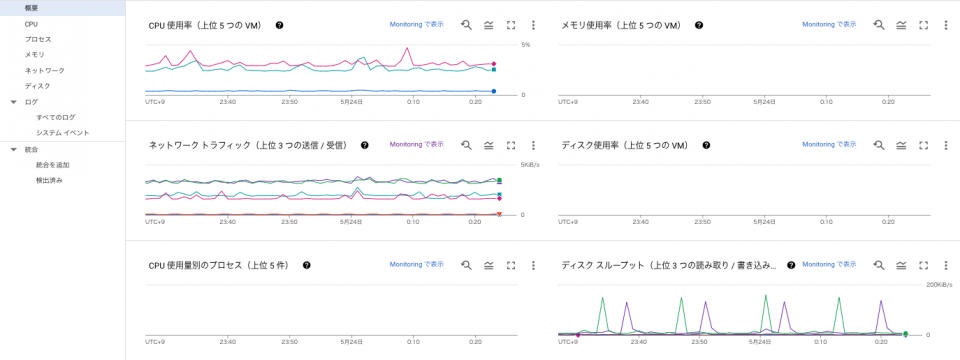
概要、CPU、プロセス、メモリ、ネットワーク、ディスク、ログ、といった項目が表示されています。
概要ではよく閲覧されると思われる、上の図のようなメトリクスがすぐに閲覧可能です。
※メモリ使用率、ディスク使用率、CPU 使用率プロセスが表示されていないのは Ops エージェントが未導入のためで、すべて表示させるためには Ops エージェントの導入が必要です。
概要以外の CPU、プロセス、メモリ、ネットワーク、ディスクでは、よりその項目に特化したメトリクス情報の閲覧が可能です。
プロセスに関して、細かくプロセスごとの CPU 使用率や、メモリ使用率、ディスクスループットが取得できるのは特徴的だと思いました。
プロセス情報の取得は Ops エージェントを導入する必要がありますが、エージェント経由での取得でもカスタム無しで、クラウドサービス純正のエージェントでこのような値を取得できるのが意外でした。
GKE
以下サンプルとなります。
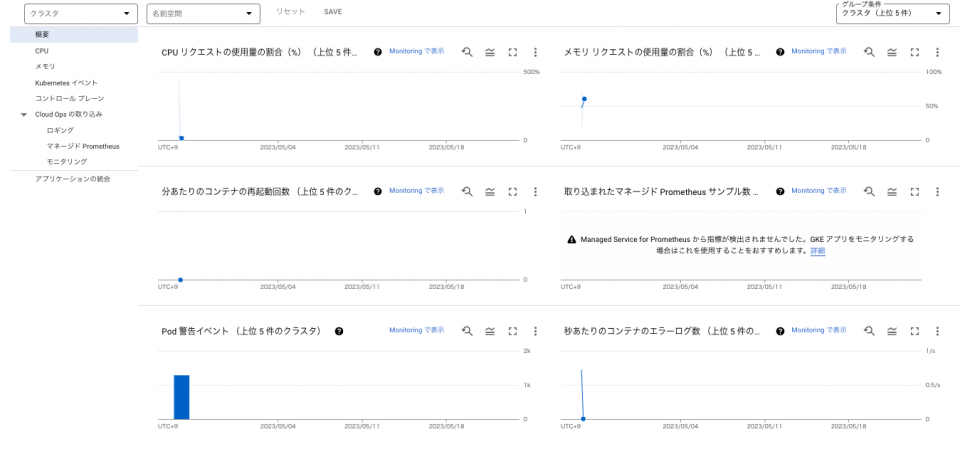
概要、CPU、メモリ、Kubernetes イベント、コントロールプレーン、Cloud Ops の取り込みといった項目が表示されています。
右上のクラスタ上位5件となっている箇所はプロジェクト全体、名前空間上位5件とグループ条件を変えることが可能です。
GCE と同様に概要ではよく閲覧されると思われる、上図にあるような上位のクラスタ情報を確認できます。
コンテナサービスであるためコンテナの再起動回数、エラーログ数、Pod 警告イベントなど直接サービス提供に影響を受けそうな内容が纏められており、GKE 用になっている、という印象です。
図内の左ペインにある、CPU、メモリなどを選択すると、クラスタの未使用のコア数、未使用のメモリのメトリクスがあり、リソース状況の確認を意識した項目が提供されており、インフラ向けの内容になっていると感じました。
Cloud Storage
以下サンプルとなります。
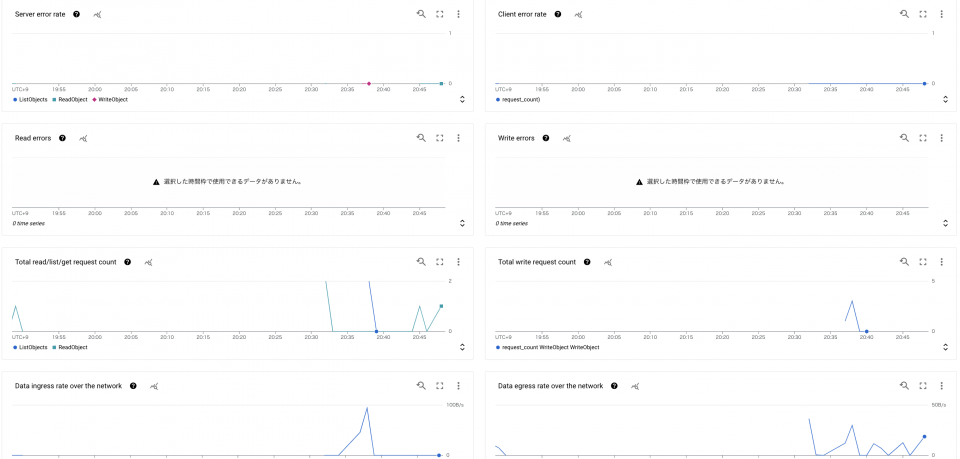
GCE と GKE ではリソースの使用状況の把握やエラー状況の把握、改善点などを検討するような項目がありましたが、Cloud Storage ではエラー状況(サーバー側かクライアント側の切り分けなど)、ネットワーク状況の把握に利用できそうです。
保存は必要だが読み取り状況が把握できていない場合など、確認することで、ストレージクラスの変更を検討するようなこともできそうですが、用途が明確であれば、そういった利用ケースは少ないかも、と感じました。
指標タブ
Cloud Run、Cloud Functions という Web サービスやジョブのサービスとしても利用できるサービスで確認できました。
Cloud Run ではリクエスト数、CPU、メモリ使用率、レイテンシという、Webサービスに特化した項目の表示となっています。
以下サンプルです。
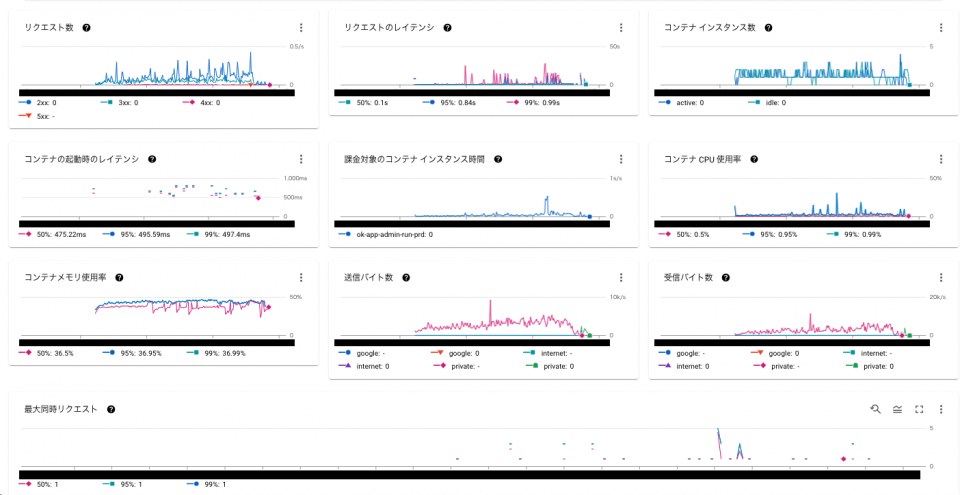
Cloud Functions では回数、メモリ使用率、実行時間、インスタンス数という、Functions に特化した項目の表示となっています。
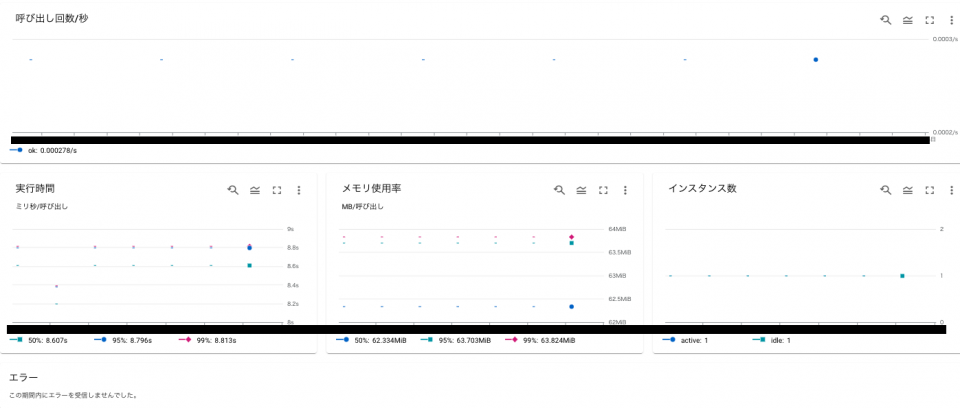
それ以外
その他のサービスはモニタリングとしての表示が多かったですが、モニタリング以外だと一覧化まではされておりませんが、対象を切り替えてメトリクスを閲覧できる状態でした。
アプリケーションパフォーマンス監視
ここまではサービスに応じてメトリクス情報が様々な形で纏められていることがわかりました。
閲覧可能な内容で十分なことは多いですが、アプリケーションパフォーマンス監視を行ないたいケースもあるかと思います。
その場合、Cloud Trace、Cloud Profiler を利用することでアプリケーション内のパフォーマンス状況を可視化及びボトルネックの調査が可能です。
それぞれのサービスでどういう内容の可視化が可能か、以下に記載します。
Cloud Profiler
Profiler エージェントをインストールし、約1分毎に10秒間プロファイリングデータを収集し、1つのプロファイルを作成します。
その作成したプロファイルごとで利用されたリソースの使用量を把握することが可能です。
詳細はこちらをご覧ください。
個人的にはリソースの使用状況の比較がし易いのと視覚的にわかりやすいと思いましたが、こちらの導入にあたってはエージェントインストールのみではなくコードの変更が必要があり、今までに記載したものより少しハードルが高いかな、と感じました。
※参考までにGoの導入についてご覧ください。
Cloud Trace
Cloud Profiler がリソース使用状況だったのと比較し、Cloud Traceでは処理時間に関する内容を知ることができます。
例えばユーザが Google Cloud で運用しているサービスに対してリクエストし、そのリクエスト内で別の API へのリクエストの完了までの時間や、その処理内での DB へのクエリの時間など、1つのリクエスト内で、どこでどのくらいの時間がかかっているか、を把握することができます。
これを行なうことでリクエストの処理時間のボトルネック調査やレイテンシの把握、アプリケーション毎の依存関係の把握をすることが可能です。
特に嬉しいのが、Cloud Run、Cloud Functions、App Engine(フレキシブル、スタンダードともに)ではトレースデータが自動で収集されるようになっています。
※GCE、GKE、Google Cloud 以外の環境では自分でインストールする必要があります
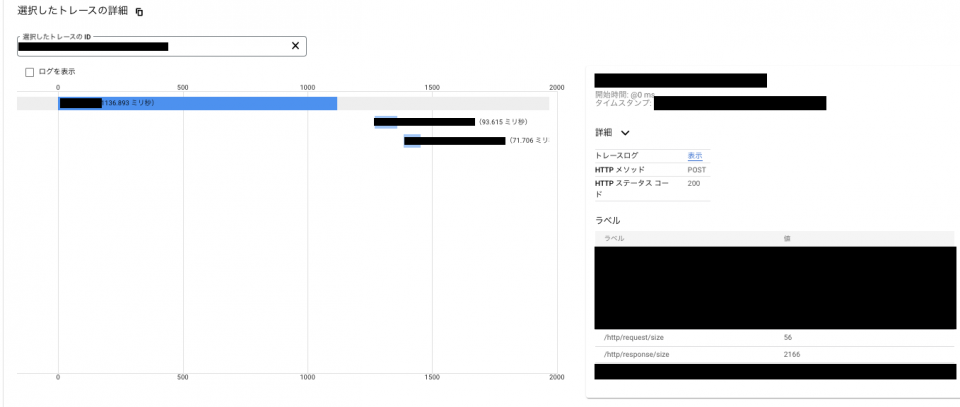
Cloud Trace がどのような形で閲覧できるのか、以下にサンプルを貼ります。
こちらはいくつかあるトレースの中で一つのトレースを選択したものですが、どこでどの程度時間がかかっているか、どのような依存関係か、が見てわかるかと思います。
所感
Ops Agent とC loud Profiler 以外は、標準で利用できるもの(Cloud Trace関しては一部)であり、そのサービスの内容に応じて、特に Observability タブ、指標タブはダッシュボードのカスタムなど必要とせずに一定のメトリクスの一覧が確認できる状態でした。
Google Cloud に関しても、システムの状況確認について利用者目線で閲覧し易い形を意識した工夫がされてきています(2023/5/24時点で Cloud Storage のダッシュボードも直近のアップデートでした)。
また、Cloud Run についてはマルチコンテナのプレビュー利用が発表されたり、アップデートが続く中で、Cloud Trace が標準装備されているなど、目に触れづらい部分でも強力であることも再確認でき、良い機会でした。
近いうちに Ops Agent の導入によってプロセス毎の各種使用率がどう見えるか、Cloud Trace でどのようなことができるか、をもう少し深掘りしたいと思います。




