
Google Cloud Next ’24 にて行われたセッション「How to use Google Cloud Storage to unify your data for analytics workloads」のレポートです。
Google Cloud Next ’24 とは?
2024 年 4 月 9 ~ 11 日にラスベガスのマンダレイ ベイで開催されている、Google Cloud が主催する最大級規模のイベントです。
https://cloud.withgoogle.com/next/
登壇者
Google Cloud Group Product Manager
Brad Kelemen 氏
Google Cloud Group Product Manager
Vivek Saraswat 氏
Uber Senior Manager, TPM
Henry Gray 氏
Uber Principal Engineer
Abhi Khune 氏
セッション内容
データ分析とストレージについて
- ストレージの現状
- 複数のデータコピーが必要だったり、同期が取れていなかったり、一貫性のないセキュリティモデルによってデータサイロが発生している
- これらによりコストや管理の複雑さが増大している
- 分析のビジョン
- 複数のワークロードやデータタイプ、統一されたテーブル形式、一貫したセキュリティとガバナンスといったデータレイクハウスが求められる
- 分析の統合プラットフォーム
- このような状態を目指したい
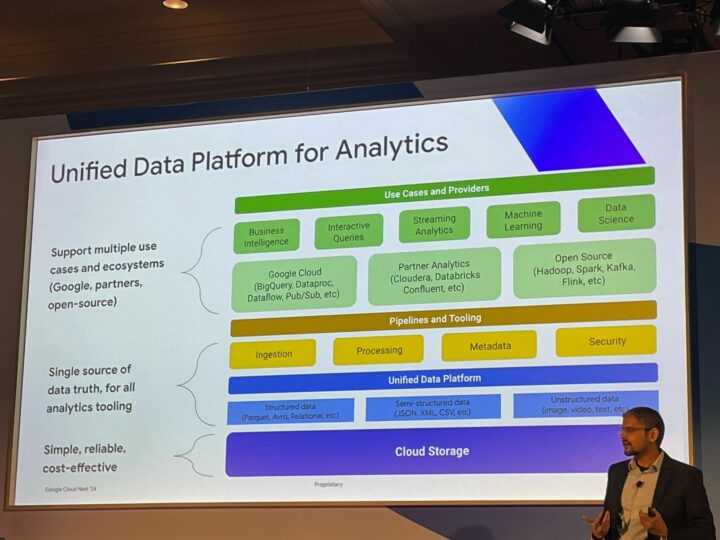
データ統合におけるストレージの課題
簡潔にまとめると、以下を満たすことが望ましいとのことです。
- パフォーマンス
- 高スループット
- どこでも実行できるワークロード
- ガバナンス
- きめ細かいアクセス制御
- 既存ツールとの統合
- プログラマビリティ
- セマンティクス
- 最適化
- エコシステム
- 1P:適切なクラウドプロパイダー
- 3P:マルチクラウドおよびハイブリッドクラウドのパートナー
- セルフマネージド:独自ソースまたはオープンソース
Anywhere Cache plus Multi-Region Buckets (プライベート GA)
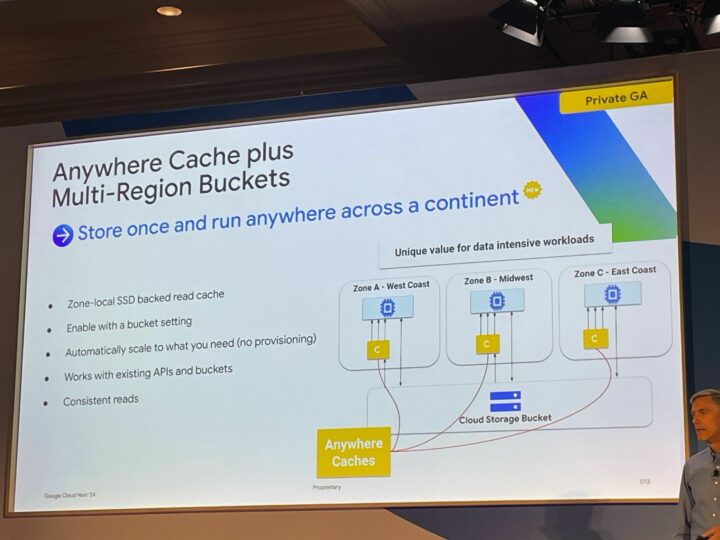
- 特徴
- 一度保存すれば大陸中のどこでも実行可能
- ゾーンローカル SSD でバックアップされた読み取りキャッシュ
- バケットの設定から有効化できる
- 必要に応じて自動スケーリング (プロビジョニングなし)
- 既存の API およびバケットと連携
- 一貫した読み取り
- こんな時に使いたい!
- 応答時間を短縮し、コンピューティングを効率的に使用したい
- 高スループット:各キャッシュから最大 10 Tbps
- 読み取り時間の短縮:最大 50% 短縮
- 大規模なデータセットへの拡張:最大 1 PB のデータをキャッシュに保存
- コスト削減
- 古いデータの提供を避けたい
Cloud Storage gRPC (プライベートプレビュー)

- 特徴
- 応答時間を短縮し、コンピューティングのコストを削減
- JSON と比較して、読み取り集中型のワークロードのパフォーマンスが向上
- 読み取りレイテンシ、全体的な実行時間の短縮
- 以下で利用可能
- Cloud Storage クライアント ライブラリ:C++、Java、Go
- Hadoop/Spark ワークロード用の Cloud Storage コネクタ(Dataproc を含む)
- Dataflow から Cloud Storage へのパイプライン
Access Control at All Levels (GA)
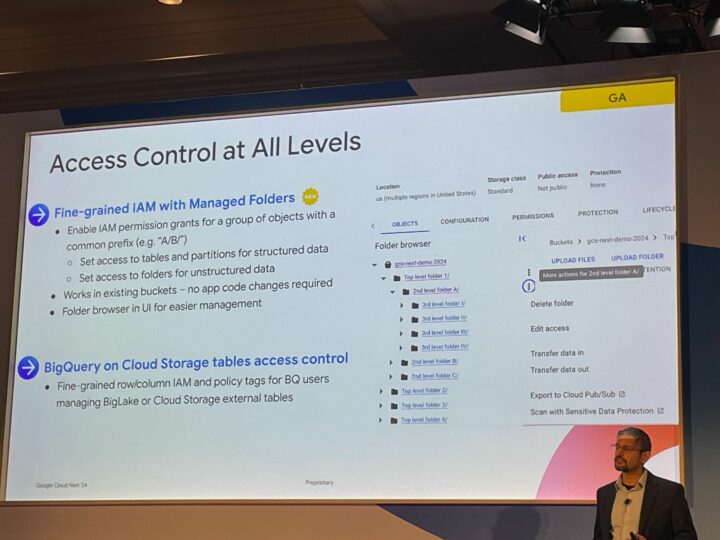
- 特徴
- フォルダを使用したきめ細かい IAM (New)
- 共通のプレフィックス (A/B/など) を持つオブジェクトに対する IAM 権限付与
- 構造化データのテーブルとパーティションへのアクセス制御
- 非構造化データのフォルダーへのアクセスを制御
- アプリケーションのコードの変更なしで、既存のバケット上で動作
- 管理しやすい UI によるフォルダ ブラウジング機能
- Cloud Storage 上の BigQuery テーブルへのアクセス制御
- BigLake または Cloud Storage の外部テーブルを管理する BQ ユーザー向けの、きめ細かい行/列 IAM およびポリシータグ
Access Buckets with Local Filesystem Semantics (GA)

- Cloud Storage Fuse
- バケットをクライアント上のローカル ファイルシステムとしてマウントする
- バケットから直接データを反復処理し、コンピューティングのアイドル時間を削減します。
- Linux パッケージまたは GKE、Vertex Al、Deep Learningとの統合を介してデプロイが簡単
- Fuse File Cache (New)
- ローカル ディレクトリをキャッシュとして使用して、小規模でランダムな I/O の繰り返し読み取りを高速化します。
- データの読み込みを高速化: トレーニング時間を 59% 短縮し、TCO を 58% 削減
Optimized Buckets for File-Oriented Workloads (Q2にプレビュー)

- 階層型名前空間バケット (New)
- データ集約型のワークロード向けにストレージ構造を最適化した新しいバケット作成オプション
- スループットの向上
- オブジェクトの読み取り/書き込み操作で最大 8 倍の初期バケット QPS
- ファイルシステムのような拡張機能
- API を使用した新しいフォルダリソース
- 一貫した整合性のあるフォルダ名変更と高速フォルダリスト
- 管理フォルダーによるきめ細かい IAM
- エコシステムとの互換性
- Hadoop/Spark ワークロード用の Cloud Storage Connector と Dataproc
- ローカルファイルシステムのようなセマンティクスのための Cloud Storage FUSE
Uberの事例
- 移行の目標としては、規模に応じてコストと信頼性を維持しながら、Uber のビジネスを加速すること
- 操作の簡素化
- 機能の制限を解除
- 生産性の向上
- アーキテクチャ
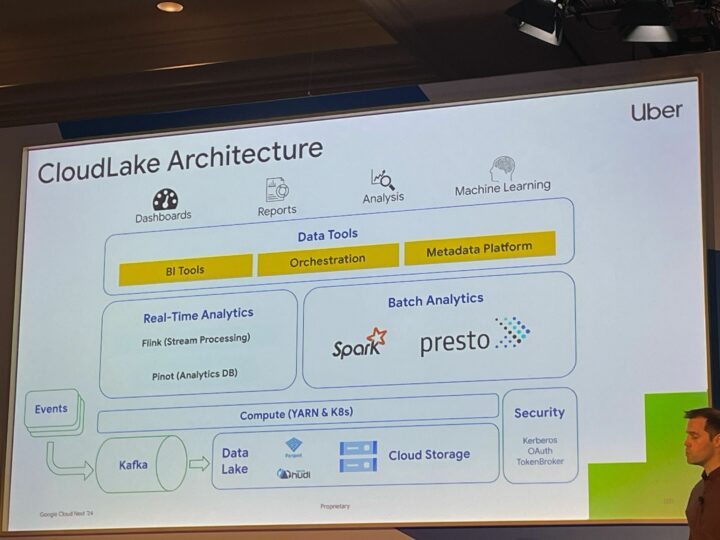
- 課題その1
- HDFSの性能均等性を維持すること
- 解決策その1
- Cloud Storage コネクタの gRPC 改善
- 初期の gRPC の書き込みは JSON クライアントと比較して遅かったが、最新のビルドは同等になった (読み取りは一貫して高速になった)
- 並列複合アップロードでは、p50 で書き込みが +40% 改善
- Spark の最適化: 可観測性と調整
- アトミックなディレクトリ名変更
- 課題その2
- 内部ユーザーが苦痛に感じるような移行を回避すること
- 解決策その2
- クライアントの標準化: Cloud Storage コネクタでの使用に「公式」 HDFS クライアントを義務付ける
- データ メッシュ: HDFS とオブジェクト ストレージの違いを隠す
- セキュリティ モデル: Uber の Hadoop セキュリティ モデルと GCP の IAM モデルを連携
- ダウンスコープアクセスに資格情報アクセス境界トークンを使用
- 課題その3
- 数年にわたる移行中のオンプレミスとクラウドのフットプリント管理
- 解決策その3
- ワークロード/データ分割の管理方法に関する詳細な計画と戦略
- 自動移行サービス: データのコピーと検証、データ ロケールに基づいたワークロードの自動ルーティング、自動パイプラインへの移行
- キャパシティプランニング: いつ、どこで何が必要になるかを長期的に計画する
Uber + Google Cloud によって、
オープンデータ分析プラットフォーム 「CloudLake」 のオンプレミスから Google Cloud へのリフトアンドシフト移行を可能にした!
感想
Cloud Storage の新機能についての紹介が主な内容でした。
誰もが使ったことがありそうなほど非常に普及率の高いサービスですが、今回は関連するセッションが少ない印象だったのでアップデートも少ないのかなと思っていました。
しかし、そんなことはなかったようです。
新機能の中では特に Anywhere Cache plus Multi-Region Buckets が気になっており、キャッシュにより実際にどのくらいパフォーマンスが向上するか検証してみたいと思いました。
また、Uberの事例ではクラウドへの移行について話されており、Cloud Storage の性能の高さを再認識できました。




