
はじめに
私たちが運用しているカスタマーサポート向けのAIチャットボット(RAGシステム)において、新たに「Zendesk ヘルプセンター記事」を検索ソースとして追加する要件が発生しました。
ヘルプセンター記事は日々の業務の中で頻繁に追加・更新されるため、AIの検索インデックスであるVertex AI Searchも常に最新の状態に保つ必要があります。毎回手動で更新したり、記事の更新のたびにAPIを叩いてインデックスを細かく操作するスクリプトを組むことも可能ですが、運用保守のコストは極力下げたいと考えました。
そこで今回は、Google CloudのマネージドサービスであるCloud Run Jobs、Cloud Scheduler、BigQueryと、Vertex AI Searchの「標準スケジュール同期機能」を組み合わせることで、シンプルかつ堅牢な日次の自動同期パイプラインを構築しました。本記事では、そのアーキテクチャと実装の工夫についてご紹介します。
アーキテクチャの全体像
今回構築したデータ同期パイプラインの構成は以下の通りです。
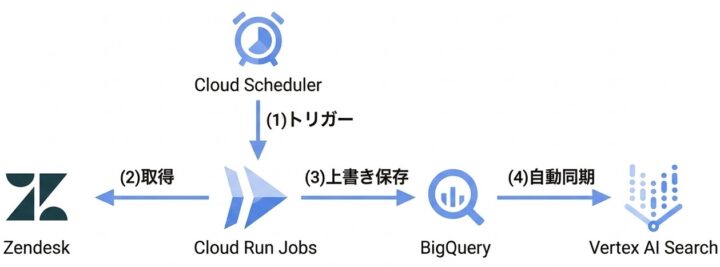
日次バッチとして、Cloud Schedulerがトリガーとなり、Pythonで実装されたCloud Run Jobsを起動します。このジョブがZendeskのAPIからすべてのヘルプセンター記事データを取得し、BigQueryのテーブルを更新します。
そして、データ連携が完了した後に、Vertex AI Searchのスケジュール機能が自動でBigQueryの最新データを読み込み、検索インデックスを更新するという流れです。
各コンポーネントの実装ポイント
1. Zendesk APIからのデータ取得と整形
データの取得には、バッチ処理に適したCloud Run Jobsを採用しました。Webリクエストに応答するCloud RunサービスやCloud Functionsとは異なり、タイムアウトの制限が緩く、非同期のタスク処理を安定して実行できるためです。
ZendeskのHelp Center APIからヘルプセンター記事を取得する際、ページネーションを利用してデータがなくなるまでループ処理を行います。ここで工夫したのが、データの整形処理です。Zendesk ヘルプセンター記事の本文はHTML形式で返ってきますが、そのままではLLMや検索エンジンにとってノイズが多く扱いにくいため、BeautifulSoupを用いてHTMLタグを除去し、プレーンテキストに変換してから保存するようにしました。
from bs4 import BeautifulSoup
# 記事本文のHTMLタグを除去してプレーンテキスト化
raw_html = article.get("body", "")
if raw_html:
# LLMが文脈を理解しやすいよう、改行やスペースを意識して抽出
soup = BeautifulSoup(raw_html, "html.parser")
body_text = soup.get_text(separator="\n", strip=True)
else:
body_text = ""
processed_article = {
"id": article.get("id", ""),
"title": article.get("title", ""),
"content": body_text,
"url": article.get("html_url", ""),
"updated_at": article.get("updated_at", ""),
}
2. BigQueryを中間層に挟む理由
このアーキテクチャの一番の肝は、取得したデータを直接Vertex AI SearchのAPIに投げるのではなく、一度BigQueryに保存している点です。これには明確な理由があります。
まず、Vertex AI SearchにはBigQueryからデータを定期的にインポートする標準機能が備わっており、GCPコンソールからGUIベースで簡単にスケジュール設定ができるという運用上の大きなメリットがあります。また、万が一検索結果がおかしい場合に、BigQueryにデータが残っていれば、SQLを使ってデータの欠損や不整合をすぐに調査・分析することが可能です。
from google.cloud import bigquery
# BigQueryへのロード設定
job_config = bigquery.LoadJobConfig(
schema=schema,
write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE,
)
job = client.load_table_from_json(data, table_ref, job_config=job_config)
job.result()
3. Vertex AI Searchへの自動同期と検索アプリの紐付け
BigQueryに最新のデータが用意された後は、Vertex AI Search側での取り込みです。
この設定はコーディング不要であり、GCPコンソール上で対象のBigQueryデータセットとテーブルを指定し、スケジュールを組むだけで完結します。
ここで、構築時にハマりやすい重要な注意点があります。Vertex AI Searchでは、「データストア」を作成してデータをインポートしただけでは、アプリケーションからAPI経由で検索することができません。 実際に検索用APIを利用するには、別途「検索アプリ」を作成し、そこに構築したデータストアを紐付ける作業が必須となります。
- データストアの作成:BigQueryをソースとして定期インポートを設定する。
- 検索アプリの作成:カスタム検索アプリを作成し、手順1のデータストアをリンクする。
- APIからの呼び出し:アプリケーションからは、この検索アプリが参照しているデータストアIDを指定して検索を実行する。
このステップを踏むことで、初めて外部システムから最新のZendesk ヘルプセンター記事を検索できるようになります。
おわりに
今回は、BigQueryを中間データストアとして活用し、シンプルかつ保守性の高いZendeskとVertex AI Searchの自動同期パイプラインを構築しました。
この記事が、皆さんのRAG開発や運用改善のちょっとしたヒントになれば嬉しいです!

