
はじめに
RDS(PostgreSQL)のテーブルデータをS3に出力したいとき、普通はアプリ側でSELECTしてCSVを作ってS3にPUT…となりますが、実は aws_s3 拡張機能 を使えば SQL一発でクエリ結果をS3に直接出力 できます。
実際に使ってみたので、概要・セットアップ・ハマりポイントをまとめます。
公式ドキュメント
aws_s3.query_export_to_s3 とは?
RDS PostgreSQL / Aurora PostgreSQL で利用できる拡張機能の一部で、SELECT文の結果を直接S3バケットにファイル出力する関数です。
・アプリ側でのファイル生成・アップロードが不要
・約6GBを超えると自動的にファイル分割される(data.csv, data.csv_part02, data.csv_part03… のようにサフィックスが付く)
・PostgreSQLの COPY コマンドと同じフォーマット指定が使える
・KMS暗号化にも対応
使い方
SELECT * FROM aws_s3.query_export_to_s3(
'SELECT * FROM my_table', -- クエリ
aws_commons.create_s3_uri('my-bucket', 'data.csv', 'ap-northeast-1'), -- S3の出力先
options := 'format csv, delimiter ''|'', header true' -- フォーマット
);
| rows_uploaded | files_uploaded | bytes_uploaded |
| 12345 | 1 | 1048576 |
このSELECTを実行するとS3へのエクスポートが行われ、戻り値としてエクスポートされた行数・ファイル数・合計バイト数が返ってきます。
KMS暗号化する場合は kms_key パラメータを追加するだけです。
SELECT * FROM aws_s3.query_export_to_s3(
'SELECT * FROM my_table',
aws_commons.create_s3_uri('my-bucket', 'data.csv', 'ap-northeast-1'),
options := 'format csv, delimiter ''|'', header true',
kms_key := 'arn:aws:kms:ap-northeast-1:<アカウントID>:key/<KMSキーID>'
);
SQLだけで完結するのでシンプルです。ただし ここに至るまでのセットアップが大変 です。
セットアップ
全体像はこんな感じです。
RDS (PostgreSQL)
├─ aws_s3 拡張インストール ←【4】
└─ IAMロール紐づけ ←【2】
│
▼
IAMロール ←【1】
├─ S3ポリシー (PutObject等)
└─ KMSポリシー (KMS利用時)
│
▼
S3バケット (同一リージョン, SSE-KMS暗号化)
セキュリティグループ ←【3】
└─ アウトバウンド TCP 443 許可
【1】 IAMポリシー・ロールの作成
RDSからS3に書き込むためのIAMポリシーを作成し、信頼ポリシーで rds.amazonaws.com を指定したIAMロールにアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject*",
"s3:ListBucket",
"s3:GetObject*",
"s3:DeleteObject*",
"s3:GetBucketLocation",
"s3:AbortMultipartUpload"
],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
}
]
}
KMS暗号化を使う場合は kms:Encrypt, kms:GenerateDataKey*, kms:DescribeKey 等の権限も追加が必要です。
【2】 IAMロールをRDSに紐づけ
RDSコンソールでDBインスタンスを選択し、「接続とセキュリティ」タブの「IAMロールの管理」から設定します。
1. 「追加するIAMロールの選択」で作成したロールを選択
2. 「追加する機能の選択」で s3Export を選択
3. 「ロールの追加」をクリック
ステータスが「アクティブ」になればOKです。

(↓AWS CLIからも設定できるみたいです。)
aws rds add-role-to-db-instance \ --db-instance-identifier <DBインスタンス名> \ --feature-name s3Export \ --role-arn arn:aws:iam::<アカウントID>:role/<ロール名> \ --region ap-northeast-1
【3】 セキュリティグループ
RDSのVPCセキュリティグループで アウトバウンドのTCPポート443 を許可します(S3はHTTPS通信のため)。
【4】 拡張のインストール
まず拡張がインストールされているか確認し以下のSQLで順番にインストールします。
SELECT * FROM pg_extension WHERE extname = 'aws_s3'; -- 1. 共通コンポーネントを先にインストール CREATE EXTENSION IF NOT EXISTS aws_commons; -- 2. aws_s3 をインストール CREATE EXTENSION IF NOT EXISTS aws_s3;
拡張がインストールされているか確認(結果が空ならまだインストールされていません。)
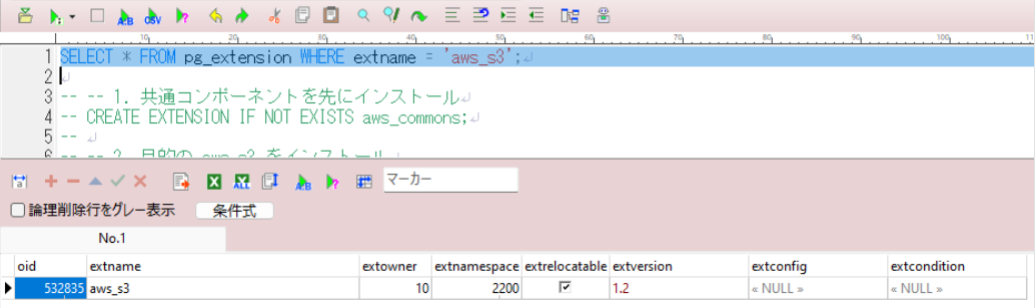
「1. 共通コンポーネントを先にインストール」「2. aws_s3 をインストール」を実行後、再度SELECTを実行して以下の状態になっていれば完了です。
・aws_s3 が一覧に表示されている
・extversion が 1.2 になっている
KMS暗号化を使う場合は v1.2以上 が必要です。古い場合:
ALTER EXTENSION aws_s3 UPDATE TO '1.2';
ハマったポイント
実際に構築してみてハマったポイントです。
①KMSキーの後追い対応が大変だった
最初はKMS暗号化なしで実装していて、以下のSQLで普通に動いていました。
SELECT aws_s3.query_export_to_s3(
?,
aws_commons.create_s3_uri(?, ?, ?),
options := 'format csv, delimiter ''|'', header true'
);
ところが後からKMS暗号化が必要になり、kms_key パラメータを足せばいいだけかと思ったらそう簡単にはいきませんでした。実際に必要だった対応は以下の3つです。
1. aws_s3 拡張を v1.2 にアップグレード
kms_key パラメータは v1.2 で追加されたもので、それ以前のバージョンだとパラメータ自体が認識されません。最初これに気づかず「パラメータが不正」的なエラーが出て悩みました。。。
ALTER EXTENSION aws_s3 UPDATE TO '1.2';
2. IAMロールにKMS権限を追加
S3への書き込み権限だけでは足りず、KMSキーの操作権限(kms:Encrypt, kms:GenerateDataKey* 等)もIAMロールに追加する必要がありました。
3. SQLに kms_key パラメータを追加
SELECT aws_s3.query_export_to_s3(
?,
aws_commons.create_s3_uri(?, ?, ?),
options := 'format csv, delimiter ''|'', header true',
kms_key := ? -- ← これを追加
);
この3つが全部揃って初めて動きます。1つでも欠けるとエラーになるので、後からKMSを追加する場合は注意が必要です。
②エクスポート失敗時の「current transaction is aborted」
複数テーブルをループでエクスポートしていたとき、あるテーブルで query_export_to_s3 が失敗した後、次のテーブルのエクスポートを実行しようとすると以下のエラーが出ました。
ERROR: current transaction is aborted, commands ignored until end of transaction block
query_export_to_s3 が失敗するとPostgreSQLのトランザクションが abort状態 になり、同一コネクション上では何のSQLも実行できなくなります。次のテーブルの処理に進むには、先にROLLBACKを実行してトランザクションをリセットする必要がありました。
} catch (Exception e) {
logger.error(tableName + "のS3エクスポートに失敗しました。", e);
// ロールバックしないと次のSQL実行で
// "current transaction is aborted" エラーになる
dao.rollback();
}
これはPostgreSQLの仕様なので aws_s3 に限った話ではないですが、バッチで複数回 query_export_to_s3 を呼ぶ場合は意識しておく必要があります。
実際の活用:Javaバッチからの呼び出し
この機能を使ってSpring Batchで複数テーブルをS3にエクスポートするバッチを作りました。簡単に紹介します。
構成
マスタテーブル
│ エクスポート対象のテーブル名を管理
▼
Spring Batch
│ 1. 対象テーブル一覧を取得
│ 2. テーブルごとにループ → aws_s3.query_export_to_s3() 実行
│ 3. 処理結果(成功/失敗テーブル数)をログテーブルに記録
▼
S3バケット
staging/TABLE_A_20251029.csv
staging/TABLE_B_20251029.csv
...
エクスポート対象のテーブル名をDBで管理することで、コード変更なしに対象を増減できるようにしています。
Javaからの呼び出し
SQLをプロパティファイルに外出しして、PreparedStatement でバインドしています。
sql.properties:
export.toS3=\
SELECT aws_s3.query_export_to_s3( \
?, \
aws_commons.create_s3_uri(?, ?, ?), \
options := 'format csv, delimiter ''|'', header true', \
kms_key := ? \
)
Dao:
public void exportTableToS3(String tableName, String bucketName,
String s3Key, String region, String kmsKeyArn) throws SQLException {
try (PreparedStatement stmt = con.prepareStatement(
rb.getString("export.toS3"))) {
stmt.setString(1, "SELECT * FROM " + tableName); // クエリ
stmt.setString(2, bucketName); // バケット名
stmt.setString(3, s3Key); // S3キー
stmt.setString(4, region); // リージョン
stmt.setString(5, kmsKeyArn); // KMSキーARN
stmt.execute();
}
}
KMSキーARNやバケット名は環境変数から取得して組み立てています。
エラーハンドリング
複数テーブルをエクスポートする場合、1テーブルの失敗で全体を止めたくありません。ただし前述の通り query_export_to_s3 が失敗するとトランザクションがabort状態になるので、ロールバックしてから次のテーブルへ進む設計にしています。
for (String tableName : targetTables) {
try {
exportTableToS3(tableName);
successCount++;
} catch (Exception e) {
logger.error(tableName + "のS3エクスポートに失敗しました。", e);
errorTables.add(tableName);
// ロールバックしないと次のSQL実行で "current transaction is aborted" エラー
try { dao.rollback(); }
catch (SQLException re) { logger.error("ロールバックに失敗しました。", re); }
}
}
まとめ
aws_s3拡張を使えばSQL一発でRDSからS3にエクスポートできる- セットアップ(IAM、KMS、SG、拡張)は少し大変だが、一度構築すれば運用は楽
- 特に SSE-KMS必須 と aws_s3 v1.2必要(KMS利用時)はドキュメントを読み込まないと気づきにくい
- アプリ側でCSV生成→アップロードするよりコード量が大幅に減り、大容量データもメモリを気にせず出力できる



