
はじめに
みなさんAI Agentを使い倒しているかと思いますが、どうしても属人化してしまい標準化がすごく難しいと感じている今日この頃…
Claude Codeをチーム標準として運用し浸透させるだけでなく、そのナレッジを共有することで
チームの垣根を越えて全体の生産性向上やスキルアップに少しでも貢献できればと思い、記事を作成してみました。
みんなが使いやすくなること・最新のベストプラクティスに準拠することを意識したカスタマイズを設計しているので、参考になれば幸いです。
ついつい書き溜めてしまったので、全4回での記載を予定しています!
本記事は第1回として、4つの拡張ポイントを context lifecycle・自動発動・コスト の観点で並べ
責務分離の指針として利用できるよう情報を整理します。
この記事で得られること
- Claude Codeの4つの拡張点(skill / subagent / commands / hooks)と責務分離
- それぞれがcontext windowに乗るタイミング(常駐 / 発動時 / 別 context)の違い
- subagentモデル解決優先順位の理解と、コスト膨張を防ぐfrontmatter設計
- カスタマイズ前後の定量比較(私のリファクタ実例)
はじめに:公式docsを読んでも「設計の指針」は出てこない
Claude Codeはagent loopのcontextをかなり強くカスタマイズできる構造になっています。
CLAUDE.md・Skill・Subagent・Hooksの4つは独立した機能としてよく説明されていますが
実体は ひとつのcontext lifecycleを異なる粒度で制御する階層的な拡張ポイント として成立しています。
公式ドキュメントは各機能の仕様をかなり網羅的に説明してくれていますが
踏み込んで読むと次のような問いには明確に回答がありません。
- 「この情報は CLAUDE.md と Skill のどちらに書くべきか」
- 「自動発動させたい処理と明示呼び出しに留めたい処理をどう分けるか」
- 「subagentのmodelはどう決まるのか、
Agentツールでmodel指定を省くと何が起こるのか」 - 「context windowを圧迫せずに大きなナレッジベースを持つにはどうするか」
これらは公式仕様を読み込めば大体理解できますが、実運用上の責務分離をどう設計するか はドキュメントに存在しません、教えてくれAnthropic!
…Anthropicは俺に何も言ってはくれない。
なので本記事ではそこを埋めようと思います。
適当に使うと顕在化する3つの構造的問題
- context lifecycle が制御されない
CLAUDE.mdを肥大化させると全セッション・常駐するトークン量が線形に増えます、一方でskillの本体は呼ばれた時だけロードされます。
この差を理解せずに「全部CLAUDE.mdに書く」運用にすると、長い会話でcontext windowがじわじわ食われ、後半の応答品質が落ちます。
私も最初は実際にやりました、ええやりましたとも。
とりあえずここに突っ込んでって言えば覚えといてくれるみたいに感じてついやっちゃいますよね…よね??
- subagent のモデル解決優先順位が不可視
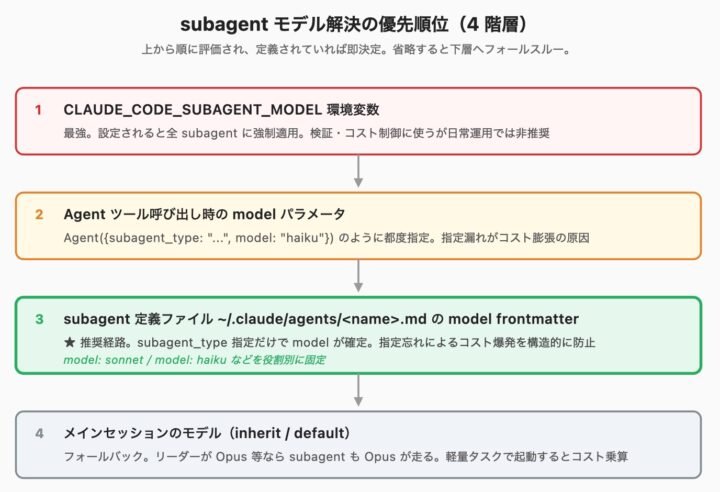
公式ドキュメントには次の優先順位が明示されています。
1. CLAUDE_CODE_SUBAGENT_MODEL 環境変数(全 subagent を強制上書き) 2. Agent tool 呼び出し時の model パラメータ 3. subagent 定義ファイルの model frontmatter 4. メインセッションのモデル(inherit / default)
Agent({subagent_type: "general-purpose"}) のように model を省くと優先順位の 4 番目に落ちます。
その場合、リーダー(Opus等)モデルがそのまま使われてしまいます、あらやだ贅沢な子!!
集計やファイル検索のような軽量タスクに上位モデルが回ると、サブエージェント並列起動の度にコストが乗算されもはや投げ銭状態に。
あっという間にトークンが消し飛び、その日はポンコツエンジニアと化します、もうおわりです。
- ナレッジが蓄積されにくい
特定のフレームワーク・ドメインの落とし穴(型比較の罠・トランザクション境界・テスト環境の癖など)はコードを読むだけでは表面化しません。
「以前同じ問題を解いた」という記憶を毎セッション口頭で再注入する運用は非現実的です。
これは個人の記憶量の問題ではなく、コンテキストへの自動注入の仕組みを持っていないという
重大な設計上の欠陥であるといえます、個人の能力に依存するのはナンセンス。
というか作業を効率化するために非効率な作業をしてしまいます。
これらは個別に「気をつける」では解決しません、それを自ら切り開き積極的に形にしていくのが私達の仕事。
Claude Codeが用意している4つの拡張ポイントは、まさにこの3つの問題を構造的に解決するための階層として利用できます。
必死に公式ドキュメントを読み込みつつ、試行錯誤を繰り返していく毎日ですがようやく形になってきました。
Claude Code の4つの拡張点
Claude Codeはこれらの問題を解決するために4つの拡張機能を用意しています。
CLAUDE.md
- 場所:
~/.claude/CLAUDE.md(ユーザー)/./CLAUDE.md(プロジェクト) - 役割: 全セッション共通のルール
- ロード: セッション開始時に全文
skill
- 場所:
~/.claude/skills/スキル名/SKILL.md - 役割: 自動発動できる「ナレッジ + 手順」
- ロード: description は常時 / 本体は発動時のみ
subagent (agent)
- 場所:
~/.claude/agents/.md - 役割: 役割別の独立 AI(model / tools / 権限を固定)
- ロード:
Agent({subagent_type: "..."})起動時に独立 context として
command
- 場所:
~/.claude/commands/.md - 役割: スラッシュコマンド
/ - ロード: ユーザー入力時のみ
hooks
- 場所:
~/.claude/settings.jsonのhooksセクション - 役割: イベント駆動シェルコマンド
- ロード: ツール実行前後・セッション開始終了などのイベント発火時
え?5つに見えるって?私にもそう見えます。(?)
しかしCLAUDE.mdは「ルール」、skill / subagent / command / hooks が「拡張点」というのが正確な分類です。
だから4つで合ってます、はい合ってますとも。
skill と command の関係
公式仕様には次の記述があります。
Custom commands have been merged into skills. A file at
.claude/commands/deploy.mdand a skill at.claude/skills/deploy/SKILL.mdboth create/deployand work the same way.
Claude Code Skills 公式 より引用。
つまりcommandはskillの前身であり、現在のskillはcommandの上位互換として位置づけられています。
skillはcommandの機能(スラッシュコマンドとしての動作)を全て含んでいます。
さらにreferences/ ディレクトリの分離やallowed-tools / disable-model-invocation / user-invocable 等の追加frontmatterフィールドをサポートするようになっています。
commands/ 配下のファイルもそのまま動きますが、新規追加するならskill形式(ディレクトリ + SKILL.md + references/)を選ぶのが基本です。
commandの時代は終わった…。
skill と subagent の関係
どちらも曖昧な理解のまま使ってる場合も多いですが(それでも全然使えちゃうので)、明確な役割があります。
skill
- 起動の主体: descriptionマッチでClaudeが自動ロード / ユーザーが
/nameで明示呼び出し - context: リーダーのcontextに追加ロード
- 用途: 「ナレッジ・手順」を渡す
subagent
- 起動の主体: リーダーが
Agent({subagent_type: ...})で明示起動 - context: 独立context(リーダーから分離)
- 用途: 「役割」を持たせる(独立作業)
skillは「リーダーに知恵を授ける」、subagentは「別人格で並列作業させる」と覚えると分かりやすいです。
両者は連携可能で、skillからsubagentを呼び出すこともできますしsubagentに特定のskillをプリロードすることもできます。
これらは使い込んでいくことで、自身で設計した通りに自律動作させることが可能になります。
skillは便利なプラグイン程度の使い方だと勿体無いです、それだと作り込む時間が無駄になりがちです。
私は割とここが好みで、意識せずとも自然に会話をする中で適切に作業してくれたりします。
頭ポンコツ状態でゆるふわプロンプトしちゃった時にガードしてくれたり、案外助かる。
それぞれが「いつ」「どれだけ」ロードされるか
context window効率を考えると、ロードのタイミングと量の理解が重要です。
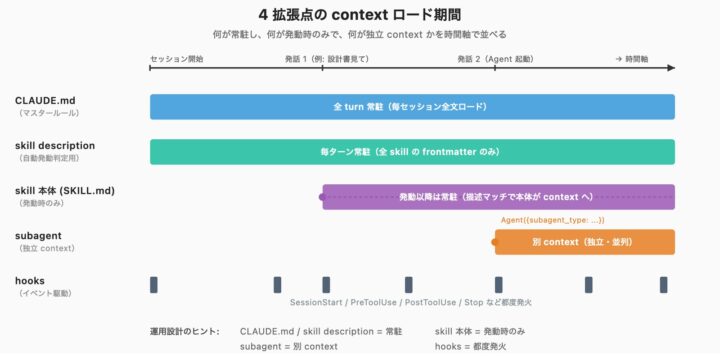
セッション開始
│
├── CLAUDE.md 全文 ──────── 毎セッション・全 turn 効く
├── 全 skill の description ─ 毎ターン読み込み(自動発動判定用)
│
▼
ユーザー発話 "設計書見て"
│
├── description マッチで skill 発動 ─ SKILL.md 本体が context へロード
│
▼
Agent({subagent_type: "reviewer"}) 起動
│
└── subagent の system prompt が独立 context へ
ポイントは次の3つです
- CLAUDE.md は全文ロード: ここに何でも書くと毎セッション重くなります、200 行未満が公式推奨
- skill description は常時ロード: しかし本体は呼ばれた時のみ、詳細は
references/に分離して必要時のみ参照する設計(Progressive Disclosure) - subagent は独立 context: リーダーの履歴は引き継がれず、プロンプトで明示的に渡す情報だけが伝わる
この性質を理解すると「どこに何を書くべきか」が見えてきます。
- 全セッション共通の不変ルール → CLAUDE.md
- 特定タスクの手順・観点 → skill
- 特定ドメインの固有罠(自動参照させたい)→ mem-* skill(
user-invocable: falseで/menuから隠す) - 役割を持った独立ワーカー → subagent
- 明示的に呼びたいワークフロー → command
- ツール実行前後のイベント処理 → hooks
~/.claude/ 配下の構成
実際のディレクトリ構造はこんな形になります(commandsとかそのままですゴメンナサイ)。
~/ ├── CLAUDE.md # プロジェクト用(最小化) └── .claude/ ├── CLAUDE.md # 全プロジェクト共通マスター ├── settings.json # hooks / permissions / env │ ├── agents/ # 役割別 subagent 定義 │ ├── implementer.md # 実装専門(sonnet) │ ├── tester.md # テスト実行・集計(haiku) │ ├── reviewer.md # コード/設計レビュー(sonnet) │ └── ... │ ├── skills/ # 自動マッチスキル │ ├── design-review/ # 設計書の品質チェック │ │ ├── SKILL.md │ │ └── references/ │ ├── implement/ # 実装フェーズの標準化 │ ├── task-review/ # 完了時セルフレビュー │ ├── mem-claude-code/ # Claude Code 固有ナレッジ │ └── ... │ ├── commands/ # スラッシュコマンド │ └── ... │ └── scripts/ # hooks 用スクリプト └── ...
agents/ で 役割 を定義し、skills/ で ナレッジと手順 を定義する。
commands/ は 明示呼び出しのエントリポイント で、多くの場合skillへの誘導として最小化します。
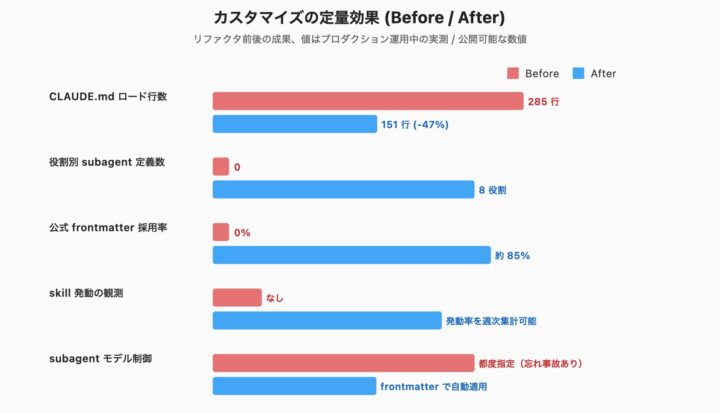
カスタマイズ前後の定量比較
カスタマイズの前後でどう変わるかを観点ごとに整理します。
モデル指定忘れ
- Before: 都度パラメータ指定が必要、忘れるとリーダーモデル継承
- After:
subagent_typeだけで agent 定義の model が自動適用
レビュー観点の網羅
- Before: 毎セッション口頭伝達
- After: skill 自動発動で6観点・5観点を強制
固有罠の自動参照
- Before: 都度ユーザーが思い出して伝える
- After:
mem-*skillがdescriptionマッチで自動ロード
設定の標準化
- Before: 個人の頭の中
- After: skill / agentファイルとして共有可能
観測
- Before: なし
- After:
PostToolUsehook + 集計スクリプトで発動率を計測
次回: skill の自動発動精度を最大化する
第2回(skillの自動発動とProgressive Disclosure)では、自動マッチングの仕組みを深掘りします。
description/when_to_use/TRIGGER when:/SKIP:の使い分け- 公式
claude-apiskill が採用するフォーマット - Progressive Disclosure: SKILL.md 本体は 30-70 行に絞る理由と方法
allowed-tools/disable-model-invocation/user-invocableの使い所
「skillを真面目に書くと何が違うのか」を、実例とコード付きで掘り下げます
シリーズ全 4 回の予定
- 本記事: Claude Codeを本気でカスタマイズしてみた:【第1回】4つの拡張点
- Claude Codeを本気でカスタマイズしてみた:【第2回】skill の自動発動
- [Claude Codeを本気でカスタマイズしてみた:【第3回】subagent モデル制御](近日公開)
- [Claude Codeを本気でカスタマイズしてみた:【第4回】skill 発動率の観測](近日公開)

