
はじめに
第1回はおかげさまで、多くの方に読んでいただきました。
予想外ではありますが大変嬉しく思います、ありがとうございます!
前回はClaude Codeの4つの拡張点を整理し、context lifecycle・自動発動・コストの観点で記載をしました。
ただし前回の記事では 「skillを自動発動させるには結局どう書けばいいのか」 という最も実用的な問いには触れていません。
そこで第2回では skillの中身、特に frontmatter の設計 に絞って掘り下げたいと思います。
SKILL.mdの本体を頑張って書いたのに全然発動しない、毎回スラッシュコマンドを自分で叩いている、そんな使い方をしている方は、たぶん frontmatter になっていないからかもしれません。
ついでに公式 claude-api skillのフォーマットや、Progressive Disclosureの考え方、disable-model-invocation 設計までご紹介できたらと思います。
この記事で得られること
- skillが自動発動する仕組み(descriptionマッチング)とClaudeが毎ターン読むもの
description/when_to_use/TRIGGER when:/SKIP:の使い分けと公式claude-apiskillから学ぶ書き方- Progressive DisclosureでSKILL.md本体をミニマムに絞る理由と方法
allowed-tools/disable-model-invocation/user-invocableで「自動発動」と「過剰な権限の防止」を両立する設計
はじめに:skillはdescriptionが9割、本体は読まれない
skillを作るとき、ついつい本体(SKILL.mdのMarkdown本文)に時間をかけてしまいます、私も最初にやりました。
頑張って手順を書き、コード例を入れ、参考リンクを並べて…いざ「設計書見て」と発話するも、Claudeはskillに記述された内容から逸脱した作業をしている。
これだからAIは信用できないんだよなー…やっぱclaude.mdに書かないとダメかな…となったそこの貴方、ちょっと待った!
それ本当にskill使えてます?試しにスラッシュコマンドから指示してみたら、ちゃんと作業してくれたりしてません?
そう、適当に作ったskillは呼ばれないんです。
というか、ClaudeはそもそもSKILL.mdの本体を毎ターン読んでいません、読んでいるのは frontmatter の description だけ。
つまりskillが呼ばれるかどうかは、本体の質ではなく descriptionの質 で決まります。
本体は呼ばれた後に初めて読まれる、開く前の本みたいなものなんです。
- skillディレクトリは本棚
- descriptionはタイトルの書かれた背表紙
- SKILL.md本体はページ
作り込むべきは descriptionで、本体は最低限の手順とリンクで済ませて良い、これは構造的にそうなっています。
動作の内容はみなさん当然に練っていますが、ここをすっ飛ばして使っている人をよく見かける気がします。
というより、コマンドで毎回手動実行をしていると気付けないんですよね、コマンドに抵抗のない歴戦のエンジニアほど陥りやすいかもしれません。
そう、これを読んでいる貴方の事です(唐突なごますり)
…ということで、公式ドキュメントを読み返してみるとちゃんと書いてありました。
読み込みが足りなかったのは私です、まず公式を読めというご先祖様の声が聞こえてくる気がします。
descriptionマッチングの仕組み — Claudeは毎ターン何を読んでいるか
ここで第1回の context lifecycle図をもう一度思い出してください、毎ターンcontextに積まれているのは
- CLAUDE.mdの全文
- 全 skillの frontmatter(description + when_to_useのみ)
- 直近のユーザー発話
この3つだけです、本体(SKILL.mdの Markdown本文)はClaudeが「これを呼ぶべき」と判断した瞬間に初めてロードされます。
claudeさんの横に本棚があって、それぞれ背表紙にdescriptionが書いてあり、それだけが見えている感じです。
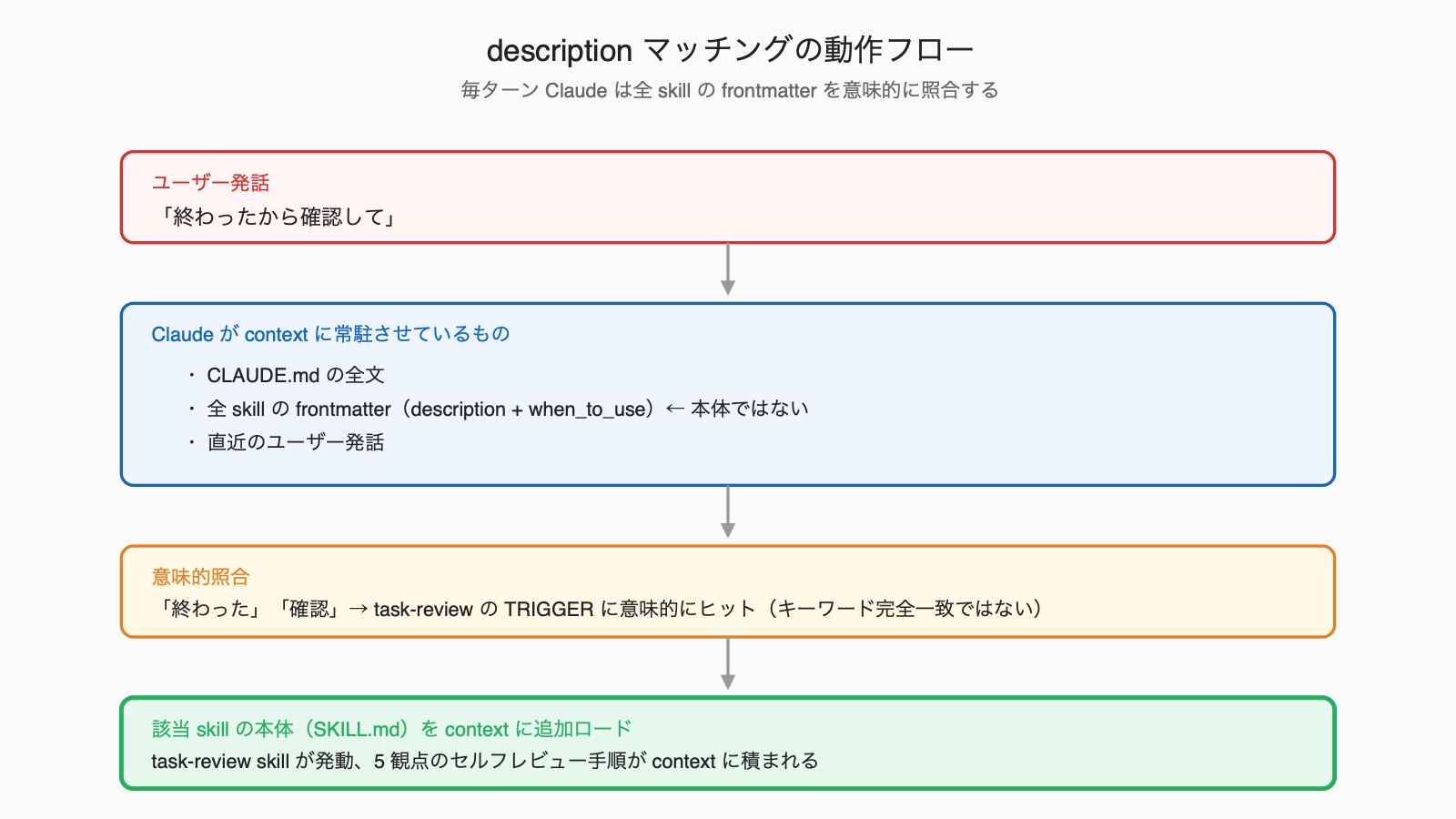
判断のロジックはシンプルで、ユーザー発話と各skillのdescriptionを 意味的に 照合します。
キーワードの完全一致ではなく、Claudeが「この発話はこのskillの領域だな」と推論する仕組みです。
なので descriptionには
- 想定される発話のキーワード
- 対象となる作業の状況
- 「これは違う」ケース(誤発動防止)
これらを網羅的に書きます、ここでケチると一生skillが呼ばれません。
これだけは皆さん覚えておいてください、背表紙で見つけてもらえない本はどれだけ本文が良くても読まれません。
TRIGGER when: / SKIP: 形式 — 公式claude-api skillから拝借する
descriptionの書き方には、公式が示しているフォーマットがあります。
それがAnthropicのbundled skillである claude-api のdescriptionです。
--- name: claude-api description: Build, debug, and optimize Claude API / Anthropic SDK apps. ... TRIGGER when: code imports `anthropic`/`@anthropic-ai/sdk`; user asks for the Claude API, Anthropic SDK, or Managed Agents; user adds/modifies/tunes a Claude feature. SKIP: file imports `openai`/other-provider SDK, filename like `*-openai.py`, provider-neutral code, general programming/ML. ---
このフォーマットは公式 bundled skill
claude-apiから確認できます(Skills 公式 参照)
TRIGGER when: で発動条件を、SKIP: で除外条件を明示する二段構え。
これだけ明示すれば、Claudeも「呼ぶか呼ばないか」で迷いません、シンプル is ベストな神フォーマットでは?
私のskillにもこれを拝借しまして、例えば task-review skillの descriptionには
description: タスク完了時の汎用セルフレビュー・チェックリスト。エラーハンドリング全パス・ビジネス判断確認・管理方式所在・既存バグ発見・ナレッジ蓄積判断の5観点を検証。 when_to_use: | TRIGGER when: タスク完了報告の直前、ユーザーへ作業完了を伝える前、ユーザー発話に「終わった」「できた」「完了」「確認して」「レビューして」「これで良い?」等の完了/確認表現が含まれる時、コード変更/設計書作成タスクの最終ステップ、`/task-review`コマンド実行時。 SKIP: 単純な確認・調査のみのタスク(コード変更なし)、ユーザーが「終了で良い」「もう確認不要」と明示した場合、typo修正・コメント修正のみの軽微変更。
このようにしました。
発動するべき発話キーワード(「終わった」「できた」等)を具体的に列挙、SKIP条件で「もう確認不要」みたいな終了宣言も明示。
これで「実装終わった」と書くだけで task-review が自動発動するようになります、便利。
閑話:そもそも自動発動って必要なの?
自動発動の必要性に関しては、正直諸説あると思っています。
スラッシュコマンドで明示的に発動すれば良いわけですし、それで困っていない方やそういうものでしょ?という発想の方もいらっしゃいます。
ですが、ユーザーが自らコマンドを覚えて起動し、条件を指示するスタイルは、操作ステップが増えてしまい利便性や柔軟性に欠けるのではないかと私は思います。
もちろん正確性を担保したり手放しにし過ぎないといったメリットもあるので、一概にどちらが優れているという話ではないのですが…
実際に複数ウィンドウで並行していくつもの作業を回していく中で、人間の脳のオーバーヘッドを少しでも減らすことが非常に重要だと感じました。
「この作業はどのskillが適しているかな」「あれ、このskillって何できるんだっけ」などと考えていると、その度に思考にノイズが発生してしまいます。
その結果、せっかく上がった作業効率に自分自身でブレーキをかけてしまい、どんどん人間がボトルネックになってしまう状態が生み出されます。
これは個人のマルチタスク適性が低いからではなく、どんな人でもAIを使い込めばいずれ直面する問題ではないかと思っています。
そんな問題を解決するのが、作り込まれたdescriptionによる自動発動の精度です!
普段チャットで会話するような、自然言語での気軽な指示から適切なskillを見つけて作業を行なってくれるので
余計なことを考えずとも人間は同じペースで使い続けることができます。
複数セッションでの作業をしても本質的な部分に思考リソースを無駄なく割くことができるようになります。
※ついでに頭が疲れている状態で雑なプロンプトを投げても、skillで設定した手順で作業をしてくれるので事故防止になってたりもします。
無論これらは適切なdescriptionだけでなく、きちんと作り込まれたskillだからこそ出来る芸当でもあるのでその点は注意が必要です。
skillの作り込みに終わりは無い…
when_to_useフィールドへの分離 — 1,536 字キャップとの闘い
ところで先ほどの例、description と when_to_use が分かれていることに気づいた方、鋭いですね?さては天才だな??
これは公式が用意している分離の仕組みで、目的は 1,536字キャップ対策 です。
The combined
descriptionandwhen_to_usetext is truncated at 1,536 characters in the skill listing to reduce context usage. (Skills 公式 より引用)
公式の言い分はこうです、「descriptionが長すぎるとskill一覧で切り詰めてしまうので、when_to_useに分けてね」
切り詰められるとせっかく書いたTRIGGER条件が途中で消えて、一生発動しないskillが爆誕します。
散々作り込めとか言っておいてなんたる罠、ちゃんと公式を読んだ俺でなきゃ見逃しちゃうね。
ということで
description: 何をする skillかの 1-2 文(短く)when_to_use: TRIGGER when / SKIPの詳細(こちらに集約)
という二段構えにします、これで上限管理しやすくなります。
これにちゃんと気付いて理解しているそこの貴方、やっぱり天才だな?
あ、今この記事読んだ貴方もこの瞬間から天才なのでセーフです(^ω^)
Progressive Disclosure — SKILL.md本体を30-70行に絞る理由
ここまででdescriptionの重要性を散々語りましたが、もちろん本体(SKILL.mdの Markdown本文)も書きます。
ただし 30-70 行に絞る、これが基本の「キ」です。
「本体は呼ばれた時にcontextにロードされる」と言いました。
ロードされるということは、それ以降のすべての応答でその本体がcontextを占有します。
本体が500行あったら、その後の会話で500行分のトークンが常時消費される地獄が待っています。
この門をくぐる者は一切の希望を捨てよ..ってなります。
なので本体は最小限にし、詳細は references/ 配下のファイルに分離します。
Claudeが「もっと詳しい情報が要る」と判断した時だけreferencesをロードする、これが Progressive Disclosure です。
なんか必殺技っぽくてちょっとカッコいいですよね、Progressive Disclosure

例えば私の design-review skillは本体80行 + references3ファイル構成です。
~/.claude/skills/design-review/ ├── SKILL.md # 本体(80行・観点概要のみ) └── references/ ├── error-handling-checklist.md # 詳細チェックリスト ├── business-judgment-checklist.md └── db-design-checklist.md
本体には「6観点ありますよ」という見出しと一行説明だけ、詳細は referencesに。
これで初動のロードコストを抑えつつ、必要時に深い情報も引き出せます。
最初は「全然収まらないじゃない…」とか思っていました。
でも一度やってみると、長文SKILL.mdがいかに無駄だったか分かります。
まともに動いてない、適当に動いて安定しない、記憶喪失頻発のくせにトークンコストだけは爆発する始末…
でもその内容をよく精査すると、構造化して8割はreferencesに追い出せます。
副作用 skillの防衛策 — disable-model-invocationで「勝手に発火」を防ぐ
ここまでは「呼ばれるskill」をどう作るかの話でした。
ですが世の中には 絶対に勝手に呼ばれてはいけないskill が存在します、例えばcommitやpush。
/commit skillを作ったとして、それをClaudeが「あ、コード変更終わったからcommitしちゃお」と勝手に発動したらどうなるでしょう。
気づいたら勝手にmainブランチにpushされている、ちゃんと致命傷ですね。
しかも「コード修正終わったらcommitするのは当たり前でしょ?」とでも言わんばかりのドヤ顔で報告してきます。
これを防ぐのが disable-model-invocation: true フィールドです。
これを frontmatter に書くと、Claudeの自動発動から外れ、ユーザーが /commit と明示した時だけ動く ようになります。
※skillに「発動前にユーザ確認必須」などと入れ込むこともできますが、意図的に手動発動に絞りたいものはこれで絶対安全になるので覚えておきましょう。
--- name: commit description: 変更内容を分析し、適切な単位に分割して自動コミットするスキル。 disable-model-invocation: true ---
私は以下のskillにこれを設定しています、自分で操作する人間専用のskillです
commit(gitに変更をcommitする)sync-mcp-config(MCP設定を上書きする)team(agentTeamsを spawnする)settings(claudeの設定を更新する)
どれも勝手に動かれたら大事故です。
commitが勝手に走った日には宇宙やら刻が見えます、君は小宇宙を感じた事はあるか?
user-invocable: false で「Claude専用ナレッジ」を作る
逆に ユーザーが手動で呼ぶ意味がないskill もあります。
例えば mem-product-knowledge のような「特定プロダクト固有のナレッジ集」、これをユーザーが /mem-product-knowledge と打って呼ぶ場面は無いんですよね。
そういう skillは user-invocable: false で /menu から隠せます
--- name: mem-product-knowledge description: ... when_to_use: | TRIGGER when: ... user-invocable: false ---
これで Claudeの自動発動のみで使われる「裏方」になります。
/menu がスッキリし、ユーザーが「これは何のskillだ?」と迷うこともない、不要な選択肢を見せない美学。
メモリ系のskillにはまずこれを付けると思って良いです。
※claudeのメモリ機能について解説すると長くなるので今回は割愛します。
allowed-toolsで意図しないツール起動を抑止する
allowed-tools は「このskillがアクティブな間、許可するツール」を明示するフィールドです。
--- name: design-review description: 詳細設計書の品質レビュー・チェックリスト... allowed-tools: Read, Grep, Glob, AskUserQuestion ---
design-review はレビューだけなので Read系のみ、書き込みツール(Edit / Write)は許可しません。
こうしておくと、Claudeが間違って「ついでに修正もしておきますね」とEditを叩いてしまう事故を防げます、レビュアーが勝手にコードを書き換えるブラック労働環境を事前に撲滅しましょう。
私の7skillのallowed-toolsは以下のとおりです(mem-* 系は参照型なのでallowed-toolsを持たず、Claudeの判断に委ねる)
agent-teams-guide:Agent, TaskCreate, SendMessage, Read, Grep(オーケストレーション中心)design-review:Read, Grep, Glob, AskUserQuestion(読み取り + 質問のみ)detailed-design:Read, Write, Edit, Agent, AskUserQuestion, Grep, Glob(設計書執筆フルセット)implement:Read, Edit, Write, Agent, Bash, Grep, Glob, AskUserQuestion(実装フルフルセット)task-review:Read, Grep, Glob(読み取りのみ)
意図しないツール起動、それは油断し切ったある日突然に発生します。
allowed-toolsで予防しておきましょう、ここをサボるとサイレント編集とかいう狂気に飲み込まれる恐れがあります。
あれは一度味わったら二度とclaudeを信用できなくなります(誇張表現)
4つの frontmatter フィールド責務マトリクス
ここまでで紹介した4つの追加 frontmatter フィールドを、責務マトリクスとして整理します。
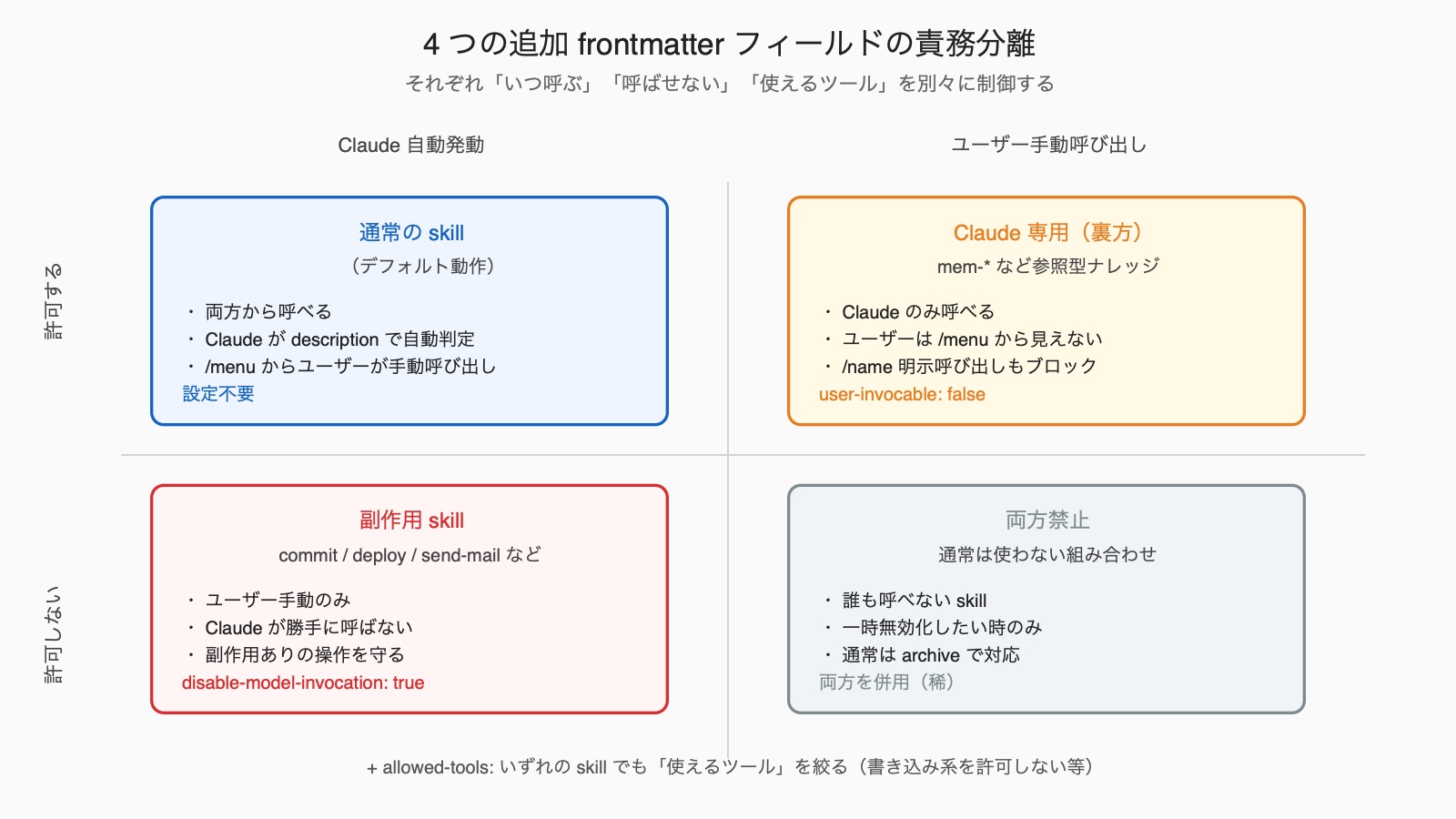
それぞれの責務をひと言で:
when_to_use: 「いつ呼ぶか」の詳細条件をdescriptionから分離(1,536字キャップ対策)disable-model-invocation: true: 「Claudeが勝手に呼ばない」副作用skill用user-invocable: false: 「ユーザーが手動で呼ばない」mem-* など裏方skill用allowed-tools: 「この skillが使えるツール」を絞り込み、意図しない発火を防ぐ
これら4つを使い分けると、skillの挙動を 意図通りにコントロール できるようになります。
ここまで読んだ貴方はもうskillの魔術師です、明日からスキル・マジシャンと名乗ってください。
実例:7skillの frontmatter Before / After
私が運用している7個のskillについて、リファクタ前後で frontmatter がどう変わったかを紹介します。
Before(リファクタ前)
--- name: design-review description: 詳細設計書の品質レビュー・チェックリスト。エラーハンドリング全パス網羅、ビジネス判断確認、DB制約根拠、スキーマ管理所在、擬似コード精度、ADR充実度の6観点で検証。TRIGGER when:「詳細設計書」「設計書」「設計ドキュメント」「ADR」を含む作成依頼の開始時/完了時、設計書レビュー依頼(「設計書を見て」「設計レビューして」等)、`/design-review`コマンド実行時、DBスキーマ変更を含む設計タスク、擬似コード/状態遷移/エラーハンドリング設計を含むドキュメント作成時。SKIP:README/技術メモ/議事録/仕様書概要などの設計書以外の.md作成、コード実装のみのタスク、要件定義書(*.md)のみのレビュー、`/save-memory`等のナレッジ蓄積タスク、Claude設定ファイル(CLAUDE.md/SKILL.md)の編集。 ---
descriptionに全部突っ込んでいる、これだと1,536字キャップに引っかかるskillも現れ始めていました。
長過ぎて滅
しかもこれ claude自身に作らせたskillなんです、なんで自分で仕様分かってないんだキミ…
After(リファクタ後)
--- name: design-review description: 詳細設計書の品質レビュー・チェックリスト。エラーハンドリング全パス網羅、ビジネス判断確認、DB制約根拠、スキーマ管理所在、擬似コード精度、ADR充実度の6観点で検証。 when_to_use: | TRIGGER when: 「詳細設計書」「設計書」「設計ドキュメント」「ADR」を含む作成依頼の開始時/完了時、設計書レビュー依頼(「設計書を見て」「設計レビューして」等)、`/design-review`コマンド実行時、DBスキーマ変更を含む設計タスク、擬似コード/状態遷移/エラーハンドリング設計を含むドキュメント作成時。 SKIP: README/技術メモ/議事録/仕様書概要などの設計書以外の.md作成、コード実装のみのタスク、要件定義書(*.md)のみのレビュー、`/save-memory`等のナレッジ蓄積タスク、Claude設定ファイル(CLAUDE.md/SKILL.md)の編集。 allowed-tools: Read, Grep, Glob, AskUserQuestion ---
descriptionを 1-2 文に短縮- TRIGGER/SKIPを
when_to_useに分離 allowed-toolsで読み取り系のみ許可
これだけでロード負荷も低下し誤動作も減りました、わりとすぐ効果が出ます。
skillの発動精度に関してはほぼ100%で、執筆時点では無事故無違反です。
カスタマイズ前後の定量比較
frontmatter リファクタを7skill全部に適用した結果を観点ごとに整理します。
descriptionの文字数
- Before: 平均280字(中には700字超のものも)
- After: 平均90字(1,536字キャップに余裕で収まる)
TRIGGER条件の網羅性
- Before: descriptionに詰め込みすぎて、肝心の発話キーワードが埋もれる
- After:
when_to_useでTRIGGER/SKIPを明示的に分離、キーワードを列挙
SKILL.md本体の行数
- Before: 平均150行(referencesなし or 一部のみ)
- After: 平均50行 + references 3-7ファイル(Progressive Disclosure徹底)
自動発動の体感精度
- Before: 「呼ばれない」「呼ばれすぎる」が混在、SKIPが効かない
- After: 想定通りに発動、誤発動は SKIP強化で対処可能(今のところない)
副作用 skillの事故
- Before: 「あれ?勝手に commitしてる?」が時々発生(防止策は入れていたが稀に無視される)
- After:
disable-model-invocation: trueで事故ゼロ
文字数とロード負荷を減らしながら、精度は上がる、これは本当に勝ち確です、約束された勝利のskillです。
わりと本気でskillを書く価値があると感じています、こうして記事まで書いているくらいにはテンションブチ上がります。
次回:役割別subagentでモデル制御を構造化する
第3回(subagentモデル制御)では、いよいよsubagentに踏み込みます!
Agent({subagent_type: "..."})のモデル解決優先順位を実例ベースで掘り下げる~/.claude/agents/*.mdで8役割を定義してモデルを固定する設計toolsの最小権限化(testerは Writeを持たない、reviewerはread-only 等)- agentTeamsとの連携と
teammateDefaultModelの落とし穴
第1回でも触れた「モデル指定忘れによるコスト爆発」の構造的解決編、これが第3回です。
お楽しみに。
シリーズ全 4 回の予定
- Claude Codeを本気でカスタマイズしてみた:【第1回】4つの拡張点
- 本記事: Claude Codeを本気でカスタマイズしてみた:【第2回】skillの自動発動
- [Claude Codeを本気でカスタマイズしてみた:【第3回】subagentモデル制御](近日公開)
- [Claude Codeを本気でカスタマイズしてみた:【第4回】skill発動率の観測](近日公開)
参考リンク
- Claude Code公式ドキュメント
- Skills
- Agent Skillsオープン標準
- Anthropic bundled skill: claude-api(公式 skillフォーマットの参考例)

