
目次
1.はじめに
2.Gemmaのダウンロードについて
3.使用SkillとGemini CLIでの実行について
4.おわりに
1.はじめに
生成 AI サービスというとクラウド経由で使用するものが広く普及しています。
導入ハードルが低く手軽に高性能モデルを使えることが理由かと思います。
本ブログでは、上記とは異なるローカル環境で動作するモデルについて紹介します。
Google が提供するオープンモデル「Gemma」をローカル端末にダウンロードし、実際に動かしてみます。
動かし方としては Gemini CLI の Skill を活用します。
完全にクラウドを排除するわけではなく、Skill の仕組みを活用し、スクリプトで Gemma サーバーを起動、そこで処理を実行させ結果を受け取るという流れを試してみたので紹介します。
環境情報
- macOS:Tahoe 26.3.1
- メモリ:16GB
- チップ:Apple M4
- Node.js のバージョン(
node --version):24.11.1 - Gemini CLI のバージョン(
gemini --version):0.38.2
2.Gemmaのダウンロードについて
Gemma のダウンロードについては Gemini CLI のドキュメント Local Model Routing の内容を参考に進めます。(Local Model Routing 機能は Gemini CLI のモデルルーティングに Gemma モデルを活用するというものです。この機能は Gemma モデルをローカルにダウンロードしていることが前提のため、ドキュメントに導入手順が記載されています。それを今回は参考にします)
まず LiteRT-LM ランタイム(Gemma を動かすための実行環境)をダウンロードします。
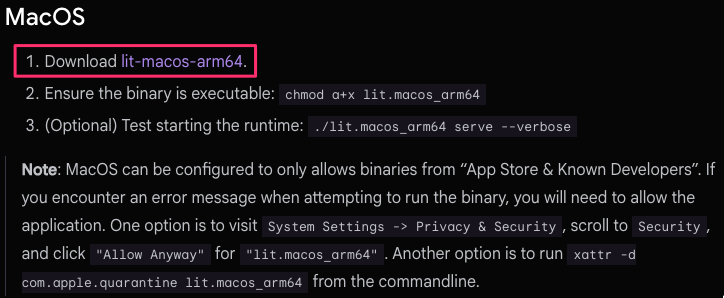
ダウンロードしてきた LiteRT-LM ランタイムを /usr/local/bin/ に移動させます。(/usr/local/bin/ は外部からダウンロードした実行プログラムを置く標準的な場所なので、ここに移動させます)
$ sudo mv ~/Downloads/lit.macos_arm64 /usr/local/bin/ $ ls /usr/local/bin | grep lit.macos_arm64 lit.macos_arm64
実行権限を付与します。
$ chmod a+x lit.macos_arm64
macOS ではインターネットからダウンロードしたファイルに自動で検疫フラグを付与し実行をブロックするため、以下のコマンドでフラグを解除します。
$ xattr -d com.apple.quarantine /usr/local/bin/lit.macos_arm64
ここまでできたら別のターミナルを立ち上げ、そちらで Gemma モデルをダウンロードします。(gemma3-1b-gpu-custom は10億パラメータの軽量モデルで特定の実行環境、ここでは LiteRT-LM ランタイムに最適化したものです)
$ lit.macos_arm64 pull gemma3-1b-gpu-custom
利用規約を確認の上、アクセプトします。
Full Terms: https://ai.google.dev/gemma/terms Prohibited Use Policy: https://ai.google.dev/gemma/prohibited_use_policy Do you accept these terms? (Y/N): Y Terms accepted. Downloading model 'gemma3-1b-gpu-custom' ... Downloading... 968.6 MB Download complete.
LiteRT-LM ランタイムの方のターミナルに戻り、以下のコマンドを実行します。
これでローカル環境に HTTP サーバーが立ち上がり、Gemma モデルを利用できる状態となります。
$ lit.macos_arm64 serve --port=9379 --verbose
サーバーを立ち上げた状態で Gemma モデルをダウンロードしたターミナルに戻り、以下のコマンドを実行します。
Gemma に対して HTTP リクエストを投げ、応答をもって動作確認完了です。
$ curl "http://localhost:9379/v1beta/models/gemma3-1b-gpu-custom:generateContent" \
> -H 'Content-Type: application/json' \
> -X POST \
> -d '{"contents":[{"role":"user","parts":[{"text":"日本語で自己紹介をしてください"}]}]}'
{"candidates":[{"content":{"role":"model","parts":[{"text":"はい、かしこまりました。自己紹介をさせていただきます。\n\n私は、Googleによってトレーニングされた、大規模言語モデルです。\n\n**簡単に言うと、私は人間のように言葉を理解し、生成することができます。**\n\n以下に、もう少し詳しく説明しますね。\n\n* **得意なこと:**\n * 質問に答える\n * 文章を作成する(詩、コード、スクリプト、音楽、メール、手紙など)\n * 様々な種類のテキスト形式を生成する\n * 翻訳する\n * アイデアをブレインストーミングする\n * 情報を整理する\n* **学習:**\n * インターネット上の膨大な量のテキストとコードを学習しています。\n * 日々、新しい情報を学習し、知識をアップデートしています。\n* **限界:**\n * まだ完璧ではありません。誤った情報や偏った情報を提供してしまうことがあります。\n * 感情や主観的な意見を持つことはできません。\n * 物理的な世界を理解することはできません。\n\n**何かお手伝いできることはありますか?** 例えば、何か質問があれば、お気軽にお尋ねください。"}]},"finishReason":"STOP","index":0}],"usageMetadata":{"promptTokenCount":0,"candidatesTokenCount":1,"totalTokenCount":1}}
日本語での自己紹介を要求し、期待通りの応答が確認できました。
Gemma の導入作業はこれで以上となります。
3.使用SkillとGemini CLIでの実行について
今回使用する Skill はテキスト整形 Skill です。
実務的というよりはあくまで Gemma を試すためのものとなります。
利用しているのは小型モデルなので、軽量処理に対して実行します。
Skill は SKILL.md と convert.py を使用します。
~/.gemini/skills/
└── gemma-formatter/
├── SKILL.md # Skillの定義・動作指示
└── scripts/
└── convert.py # Gemmaを呼び出す処理スクリプト
SKILL.md の内容は以下です。
- 用途:テキストファイルを Markdown へ変換する、もしくは壊れた JSON の構文エラーを修正する。出力は元ファイルを変更せず新規ファイルとして保存する。
- 動作環境:ローカルの Gemma モデルで処理をする。Gemma サーバーはスクリプトが自動で起動・停止するため手動操作は不要。
SKILL.md
--- name: gemma-formatter description: > テキストファイルをMarkdownファイルに変換する、または壊れたJSONファイルの構文エラーを修正する。 「マークダウンにして」「整形して」という指示でテキスト変換を行う。 「JSONを直して」「JSONが壊れてる」という指示でJSON修正を行う。 いずれもローカルのGemmaモデルで処理するためクラウドAPIを使わない。 compatibility: Python 3.x が必要。lit.macos_arm64 が /usr/local/bin に配置されていること。 --- # Text to Markdown ローカルのGemmaモデルを使ってファイルを変換する。クラウドAPIは使わない。 ## 対応する変換 | 指示の例 | モード | 出力ファイル | |---|---|---| | 「マークダウンにして」「整形して」 | `to-markdown` | `元ファイル名.md` | | 「JSONを直して」「JSONが壊れてる」 | `fix-json` | `元ファイル名.fixed.json` | ## Workflow ### 1. ファイルパスとモードを特定 - ユーザーの指示からファイルパスを取得する - モードを判断する - JSON修正のキーワード(「直して」「壊れてる」「fix」)があれば `fix-json` - それ以外は `to-markdown` ### 2. スクリプトを実行 bash python3 ~/.gemini/skills/gemma-formatter/scripts/convert.py <ファイルパス> <モード> ### 3. 結果を報告 - 生成されたファイルのパスを伝える - 変換結果の概要を簡潔に報告する ## Gotchas - Gemma サーバーはスクリプトが自動で起動・停止するので手動操作は不要 - 出力は必ず新規ファイルとして保存される(元ファイルは変更しない) - fix-jsonはGemmaが修正するため、大きく壊れたJSONは完全に直せない場合がある
convert.py の内容は以下です。
- 処理フロー:起動時に Gemma サーバーの稼働確認を行い、未起動なら lit.macos_arm64 serve で自動起動。変換処理後は、スクリプトが起動したサーバーのみ停止する。
- 変換処理:変換対象のファイル内容を指定プロンプトと結合し、Gemma へリクエストを送信。新規ファイルとして保存し、元ファイルは上書きしない。Markdown 変換については出力の拡張子を変える。
convert.py
#!/usr/bin/env python3
"""
テキストファイルをGemmaに投げて整形するスクリプト
使い方: python3 convert.py <ファイルパス> [変換種類]
変換種類: to-markdown(デフォルト)/ fix-json
"""
import sys
import json
import time
import subprocess
import urllib.request
import shutil
from pathlib import Path
GEMMA_URL = "http://localhost:9379/v1beta/models/gemma3-1b-gpu-custom:generateContent"
LIT_COMMAND = shutil.which("lit.macos_arm64") or "lit.macos_arm64"
PORT = 9379
PROMPTS = {
"to-markdown": """以下のテキストをMarkdown形式に整形してください。
- 内容は絶対に変更しない
- 補足や説明を追加しない
- Markdownのみを出力する
""",
"fix-json": """以下は壊れたJSONです。構文エラーを修正して正しいJSONを返してください。
- 内容は変更しない
- 修正したJSONのみを出力する
- 説明は不要
""",
}
EXTENSIONS = {
"to-markdown": ".md",
"fix-json": ".fixed.json",
}
def is_server_running() -> bool:
try:
payload = {"contents": [{"role": "user", "parts": [{"text": "test"}]}]}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(GEMMA_URL, data=data, headers={"Content-Type": "application/json"}, method="POST")
with urllib.request.urlopen(req, timeout=5) as res:
return res.status == 200
except:
return False
def start_server() -> subprocess.Popen:
print("Gemmaサーバーを起動中...")
process = subprocess.Popen(
[LIT_COMMAND, "serve", f"--port={PORT}"],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
for i in range(15):
time.sleep(1)
if is_server_running():
print("✅ Gemmaサーバー起動完了")
return process
print(f" 待機中... ({i+1}秒)")
process.terminate()
print("ERROR: Gemmaサーバーの起動がタイムアウトしました")
sys.exit(1)
def ask_gemma(text: str) -> str:
payload = {
"contents": [{"role": "user", "parts": [{"text": text}]}],
"generationConfig": {"temperature": 0.2}
}
data = json.dumps(payload).encode("utf-8")
for attempt in range(3):
try:
req = urllib.request.Request(GEMMA_URL, data=data, headers={"Content-Type": "application/json"}, method="POST")
with urllib.request.urlopen(req, timeout=60) as res:
result = json.loads(res.read().decode("utf-8"))
return result["candidates"][0]["content"]["parts"][0]["text"].strip()
except Exception as e:
print(f" リトライ {attempt+1}/3: {e}")
time.sleep(2)
print("ERROR: Gemmaリクエスト失敗")
sys.exit(1)
def main():
if len(sys.argv) < 2:
print("使い方: python3 convert.py <ファイルパス> [to-markdown|fix-json]")
sys.exit(1)
input_path = Path(sys.argv[1])
mode = sys.argv[2] if len(sys.argv) >= 3 else "to-markdown"
if not input_path.exists():
print(f"ERROR: ファイルが見つかりません: {input_path}")
sys.exit(1)
if mode not in PROMPTS:
print(f"ERROR: 変換種類が不正です: {mode}(to-markdown / fix-json)")
sys.exit(1)
server_process = None
if is_server_running():
print("✅ Gemmaサーバーはすでに起動しています")
else:
server_process = start_server()
try:
content = input_path.read_text(encoding="utf-8")
print(f"変換中: {input_path.name} → {mode}")
prompt = f"{PROMPTS[mode]}\n{content}"
result = ask_gemma(prompt)
# 新規ファイルとして出力(上書きなし)
output_path = input_path.with_suffix(EXTENSIONS[mode])
output_path.write_text(result, encoding="utf-8")
print(f"✅ 完了: {output_path}")
print()
print("=== 変換結果 ===")
print(result)
finally:
if server_process is not None:
print()
print("Gemmaサーバーを停止中...")
server_process.terminate()
server_process.wait()
print("✅ Gemmaサーバー停止完了")
if __name__ == "__main__":
main()
では、Skill を使ってみます。
JSON 崩れのファイルとテキストファイルを用意しました。
project/ ├── gemma-server.json └── gemma-skill-memo.txt
gemma-server.json は3箇所崩れています。
- "port": 9379 の後のカンマ抜け
- "name": "gemma3-1b-gpu-custom" の後のカンマ抜け
- "max_tokens": 1024, のブロック後のカンマ抜け("logging"の前)
{
"server": {
"host": "localhost",
"port": 9379
"tls": false,
},
"model": {
"name": "gemma3-1b-gpu-custom"
"temperature": 0.2,
"max_tokens": 1024,
}
"logging": {
"level": "info",
"output": "/var/log/gemma.log"
},
}
gemma-skill-memo.txt の中身は以下です。
Gemma Skill 使い方メモ 概要 ローカルのGemmaモデルを使ってテキストを整形するSkillです。 対応モード ・to-markdown: テキストをMarkdownに変換する ・fix-json: 壊れたJSONを修正する 実行方法 python3 convert.py <ファイルパス> <モード> 注意事項 Gemmaサーバーはスクリプトが自動で起動・停止します。 出力は新規ファイルとして保存されます。元ファイルは変更されません。
これらに対して、JSON ファイルは JSON 崩れの修正を依頼、テキストファイルは Markdown ファイル化を依頼してみます。
Gemini CLI を起動します。
使用 Skill は gemma-formatter になります。

ユーザープロンプトに以下を入力します。
gemma-server.json のJSONが壊れてるので直してください
Skill の利用を承認します。
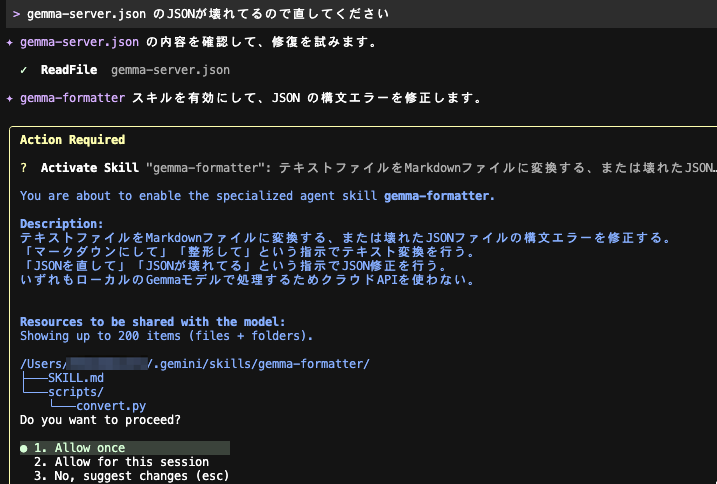
修正処理が実施されました。
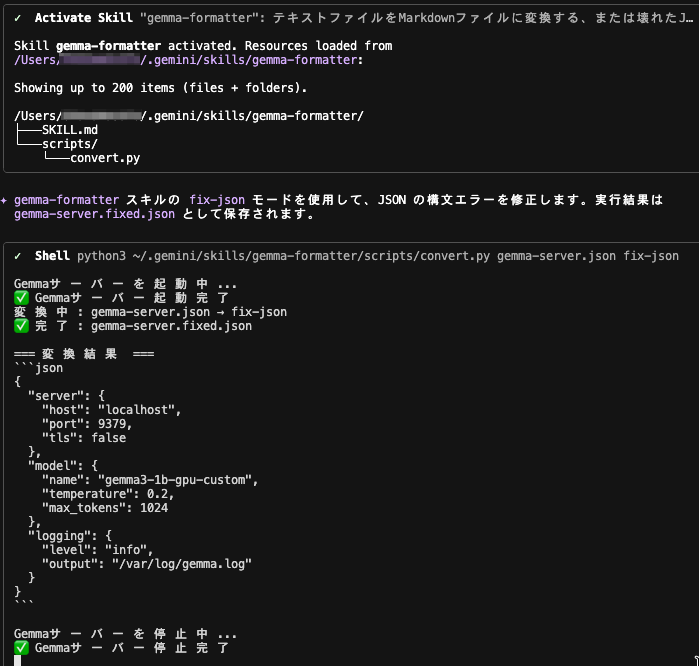
作成された gemma-server.fixed.json の中身は以下の通り、下記3点の JSON 崩れが修正されたものになっています。
- "port": 9379 の後のカンマ抜け
- "name": "gemma3-1b-gpu-custom" の後のカンマ抜け
- "max_tokens": 1024, のブロック後のカンマ抜け("logging"の前)
{
"server": {
"host": "localhost",
"port": 9379,
"tls": false
},
"model": {
"name": "gemma3-1b-gpu-custom",
"temperature": 0.2,
"max_tokens": 1024
},
"logging": {
"level": "info",
"output": "/var/log/gemma.log"
}
}
続いてユーザープロンプトに以下を入力します。
gemma-skill-memo.txt をマークダウンにしてください
gemma-formatter スキルの処理が実行されます。
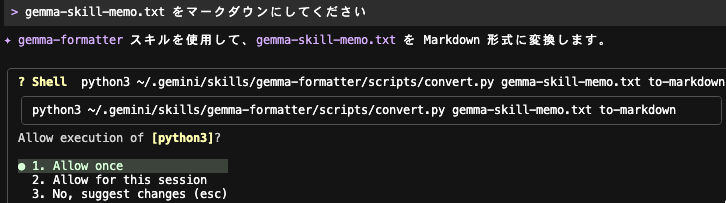
Markdown ファイル作成が実施されました。
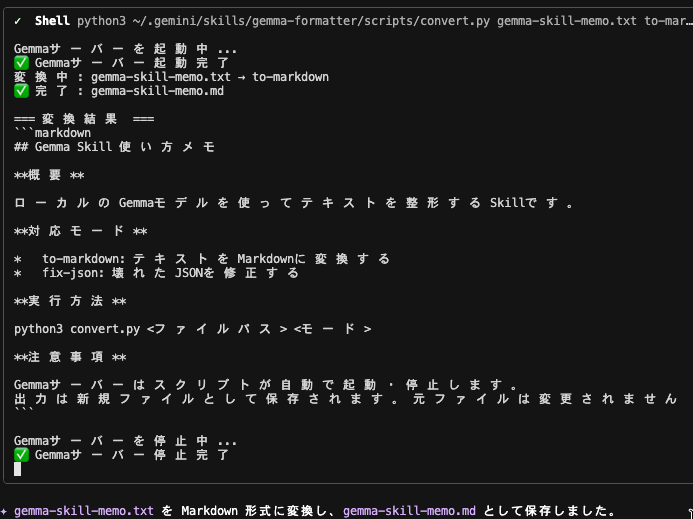
gemma-skill-memo.md の中身は以下です。
Markdown になっています。
## Gemma Skill 使い方メモ **概要** ローカルのGemmaモデルを使ってテキストを整形するSkillです。 **対応モード** * to-markdown: テキストをMarkdownに変換する * fix-json: 壊れたJSONを修正する **実行方法** python3 convert.py <ファイルパス> <モード> **注意事項** Gemmaサーバーはスクリプトが自動で起動・停止します。 出力は新規ファイルとして保存されます。元ファイルは変更されません。
この Skill はファイルの上書きでなく新規作成をするので、Skill 実行後はトータル4ファイルとなっています。
project/ ├── gemma-server.fixed.json ├── gemma-server.json ├── gemma-skill-memo.md └── gemma-skill-memo.txt
4.おわりに
Gemma をダウンロードし Gemini CLI の Skill 経由で使ってみました。
ローカル LLM と聞くと導入ハードルが高く感じるかもしれませんが、それほど手数をかけずに利用できることがイメージできたかと思います。
今回は簡単な処理を試してみましたが、ローカル LLM で出来ることはローカル LLM で実行すれば、クラウド側のモデル利用を節約できるかと思います。
ローカル LLM は Gemma 以外にも様々なモデルがあるので、興味が湧いた方はぜひ調べてみてください。
