
はじめに
この記事は
先日のGemma Developer Day in Tokyoにて、「Cloud RunでGemma2を動かす」という内容のセッションがありました。
セッションの内容がとても面白かったので、遅ればせながら実際に試してみました。
記事の内容は、実際に動かすための手順と少しの解説行っています。
今回作るメインの構成は、
「Gemma 2 JPN (gemma-2-2b-jpn-it) をOllamaを使用して、Cloud Run with GPU上で動かす」です。
また、扱いやすい(&高速に動作する)ため、モデルの量子化も行います。
ただし、セッションで紹介されたコードの内容は覚えていないため、「あくまで一個人が試してみた」という記事としてご覧ください。
(参考)
Gemma2ってなに?
Google DeepMind社がメインで開発しているオープソースモデルです。
Gemma2本体は、2024/6/27にリリースされました。
そして、今回使用する Gemma 2 JPN は、まさにGemma Developer Day in Tokyoの会場で当日(2024/10/3)リリースの発表され、大盛り上がりでした。パーリー
セッション全体で推されていたGemma2本体の特徴をざっと紹介します。
- オープソース
- 3種類のパラメータサイズ
- 2B, 9B, 27B
- マルチリンガル
- 特に小さいモデルが高い性能
- Gemma 2 9BのJapanese MT-Benchのスコア0.67強
- GPT-3.5 Turboや、最新の700Bモデルに相当
まとめると、オープソースかつ、軽量なモデルが特に強いため、どのデバイスでも、どんな言語でも自由に高性能なモデルが使用可能。というのがGemma 2の強みの一つのようです。
(参考)
全体の流れ
実際に試してみる際の全体の流れは以下です。
- (前編)モデルの前準備として、Gemma2をGGUFファイルに変換 <- この記事
- (後編(仮))Google Cloud上でサービス構築してGemma2を動かす
長くなりすぎるて読みづらくなるので2記事に分けてます。
今回作る構成図モドキ
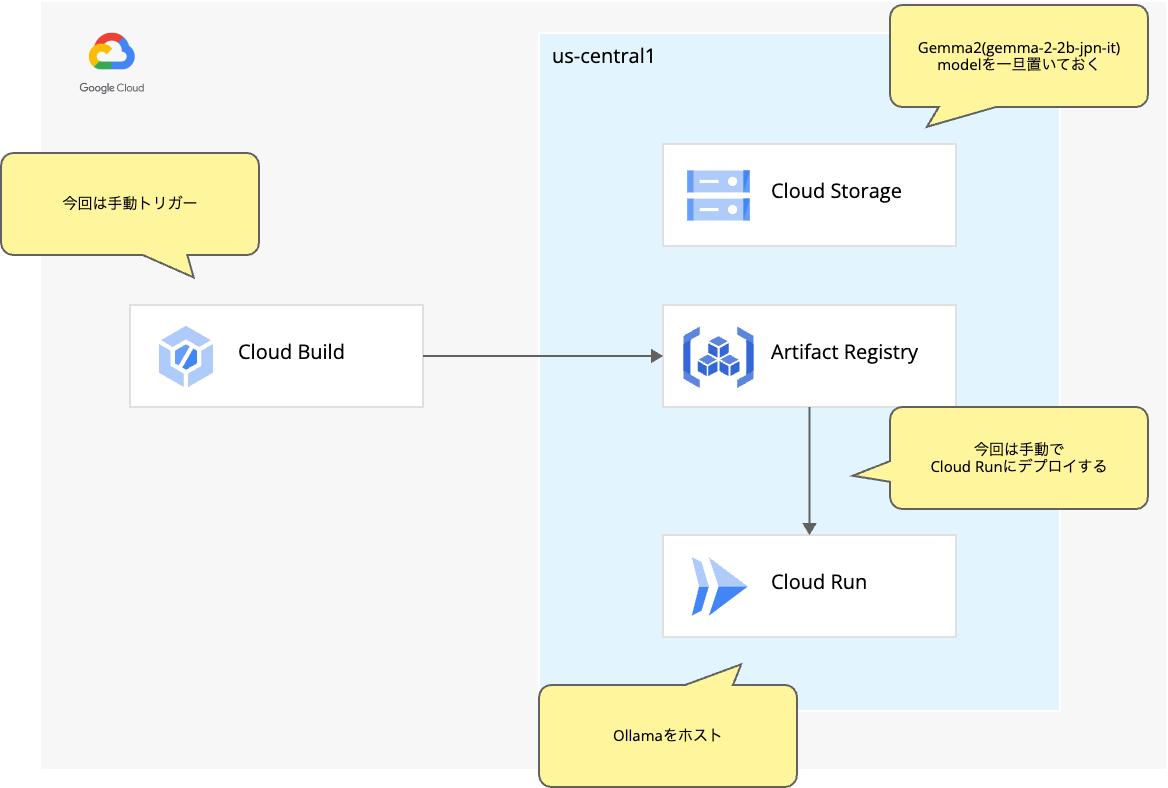
実際に作ってみる…その前に
前準備
ざっくり、話したところで、早速進めていき…たいところですが、あれこれ前準備が必要です。
特に、Cloud Run with GPUが利用可能になるまで、少し時間がかかるためご注意ください。ゆっくりお茶でも飲んでお腹を膨らませて待ちましょう。
Cloud Run with GPU利用申請
現在GPUはプレビューであり、利用申請が必要となっています。
利用可能になるまで、数日かかります。
私の場合は、4日くらいで利用可能となり、個人的に想定していたよりも早くてよろこびでした。
利用申請フォームはこちら
Gemma系モデル利用申請
今回は、Gemma2モデルを丹精込めて量子化してから、Ollamaでホストするため、Hugging Faceからをダウンロードします。
よって、Gemma2モデルの利用申請をHugging Face上で行う必要があります。
※ Hugging Faceアカウント必須
こちらのモデル情報の上部に Agree and access repository と出てくるので、規約を確認の上、申請してください。
環境情報
- Python 3.10.12
- Colab Pro
- CPU (ハイメモリ)
モデルの量子化
概要
概要でも少し触れたように、GGUFで量子化することで、扱いやすい&高速に動作するため、llama.cppを使用してHuggingFace(Safetensors)形式からGGUFファイルに変換します。
実際の作業は、Colab Pro上で行います。
Colab 無料版だと、おそらくメモリーが足りずにちにます。
ただし、ご自身のパソコンがつよで、ローカルで作業できるならそれでOKです。
私の場合は、Gemma2はいくら軽量モデルとはいえ、メモリーがちぬため。(私のパソコンのスペックがウルトラ貧弱という問題)
また、今回は、腕によりをかけてGGUFファイルに変換しますが、通常のGemma2であれば、Ollamaに組み込まれているので、モデル名を指定するだけで使用できます。
(Gemma 2 JPN (gemma-2-2b-jpn-it) が、Ollamaのモデルライブラリにいないだけ…)
通常のGemma2なら以下のコマンドで万事OKです。らくらく。
$ ollama pull gemma2:2b
ちなみに、Vertex AIでは、Gemma 2のデプロイはボタン1つで簡単にデプロイできます。
Hugging Faceからのデプロイもシームレスに対応しています。至れり尽くせりです。
今回は取り扱いませんが、ぜひ試してみてください。
(参考)
1.モデルをダウンロード
Hugging FaceからGemma2(gemma-2-2b-jpn-it)モデルをダウンロードします。
環境スペックにもよりますが、私は、5分程度で終わりました。
今回は、Colab上からなので、アクセストークンを使用してさくっとモデルダウンロードを行います。コマンドは以下。
!git clone https://<user_name>:<token>@huggingface.co/<repo_path>
- user_name
- 自身のHugging FaceのID
- token
- 自身のHugging Faceのアクセストークン
- アクセストークン作成は、Settings -> Access Tokens -> Create new token
- repo_path
- 各リポジトリのpath
- 今回は、google/gemma-2-2b-jpn-it
ちなみに、ダウンロードのための認証方法は、アクセストークン or SSHキーでの認証となっています。
(passwordでのダウンロードは廃止)
(参考)
2.llama.cpp準備
llama.cppにHuggingFace(Safetensors)形式からGGUFに変換するPythonスクリプトがあるので、何はともあれllama.cppをクローンします。
Colabで作業している方は、作業ディレクトリを変えていなければ/contentの直下に/llama.cppのディレクトリが作成されます。
!git clone https://github.com/ggerganov/llama.cpp
3.GGUFファイル変換
早速、GGUFファイルに変換していきます。
所望するファイルは、ファイル名からわかる通り「convert_hf_to_gguf.py」です。
これで、HuggingFace(Safetensors)形式からGGUFに変換できます。
今回、量子化タイプは、デフォルトである、16ビットの半精度浮動小数点数とします。
下記コマンドで実行します。
!python /content/llama.cpp/convert_hf_to_gguf.py /content/gemma-2-2b-jpn-it --outtype f16 --outfile /content/gemma-2-2b-jpn-it.gguf
これでデータ量も約1/2かつコンパクトな1ファイルになりました。
build時間も、動作時間も快適高速になります。わーい。
4.Cloud Storageバケット作成
GGUFファイルを置くためのCloud Storageバケットを作成します。
バケット作成は、Google Cloudコンソールからでも、どこからでも問題ありません。
CLIでの作成コマンドをそっと置いておきます。
リージョンは、Cloud Run with GPU利用申請と同じ、us-central1にしています。
また、今回はテストのためすぐ消すのでそこまで気にしないでもいいですが、念の為、非公開アクセスかつ、均一アクセスとしています。
!gcloud storage buckets create gs://<bucket_name> --location=us-central1 --public-access-prevention --uniform-bucket-level-access
5.Cloud Storageにアップロード
4で用意したバケットに、GGUFファイルをアップロードします。
以下のコードのバケット名などは適宜ご自身のものに変更して実行してください。
from google.cloud import storage
BUCKET_NAME = 'bucket_name'
FILE_NAME = 'gemma-2-2b-jpn-it.gguf'
FILE_PATH = f'/content/{FILE_NAME}'
client = storage.Client()
bucket = client.get_bucket(BUCKET_NAME)
blob = bucket.blob(FILE_NAME)
blob.upload_from_filename(FILE_PATH)
おわりに
長くなるので後半に続きます。
つづく…



