
みなさんこんにちは。
DX開発事業部 の石川です。
Google Cloud Next 2026 のセッションレポートを現地ラスベガスよりお届けいたします。
本記事ではGoogle BigQueryのグラフ機能に関するセッションの内容をまとめます。
なぜGraph
従来のリレーショナルモデル(RDB)は、データを構造化されたテーブルとして整理するアプローチですが、人間が直感的に理解・推論しやすいデータの表現方法としては必ずしも最適ではありません。グラフ構造は、ノード(節点)とエッジ(辺)によってデータの関係性を視覚的・直感的に表現できるため、特に複雑な関係性の分析において優れた能力を発揮します。

しかし、従来のグラフシステムには以下のような課題がありました。
- データ抽出の複雑さ: 多くのグラフシステムはプロプライエタリであり、データを別プラットフォームへ抽出するETLパイプラインの構築・維持が必要
- スケーラビリティの問題: データ量がギガバイトからテラバイト、さらにはペタバイト規模へと拡大するにつれてパフォーマンスが低下
- 専門知識の必要性: グラフ専用のクエリ言語を習得する必要があり、導入障壁が高い

BigQuery Graphが解決するもの
BigQuery Graphはこれらの課題に正面から取り組んだ!とのこと。
主な特長は以下の通り。
ストレージフリーのグラフ構造
BigQuery Graphは、既存のリレーショナルテーブルの上にグラフ構造をオーバーレイとして作成します。データを別の場所へ移行・抽出する必要がなく、クエリプランも自動的に最適化されます。
SQLとGQLの完全な相互運用性
BigQuery Graphでは、標準SQLとグラフクエリ言語(GQL)を自由に組み合わせることができます。既存のSQLの知識を活かしながら、グラフ特有のリレーションシップ分析をシームレスに実行できるため、学習コストを最小化。
構造化・非構造化データの統合処理
BigQuery Graphは、構造化データと非構造化データの両方を扱うことができ、ベクトル検索・全文検索・近似最近傍探索(ANN検索)などと組み合わせたクエリも実行可能。
弾力的なスケーリング
データやノード数の増大に合わせて自動的にスケールし、大規模なグラフ処理でも安定したパフォーマンスを維持。
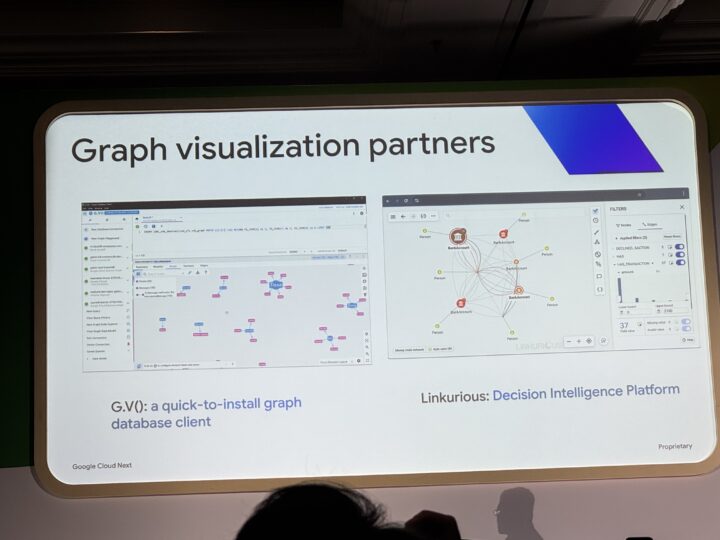
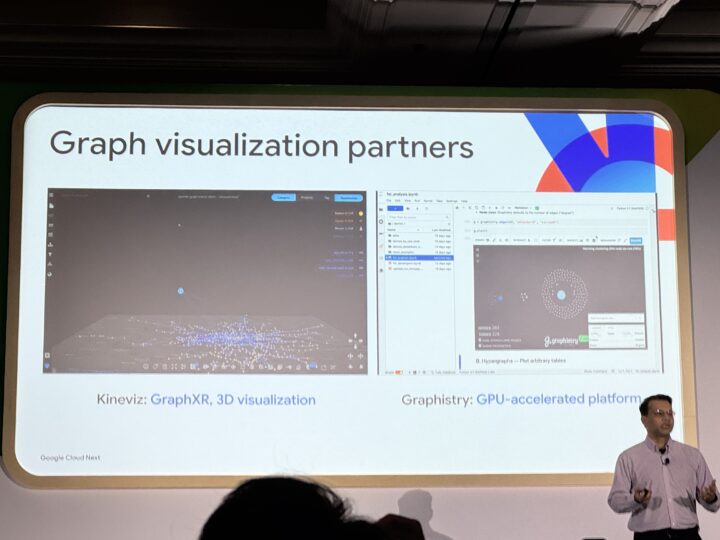
可視化サポート
BigQuery Studioのノートブック上でグラフの可視化が可能なほか、G.V()、Linkurious、Kinevizなどのパートナーツールとの連携も提供。
グラフテーブルの作り方:3ステップ
BigQuery Graphの利用は非常にシンプルで、以下の3ステップで始められます。
1.既存テーブルの活用: アカウントテーブル、人物テーブル、転送テーブルなど、すでに存在するリレーショナルテーブルをそのまま利用
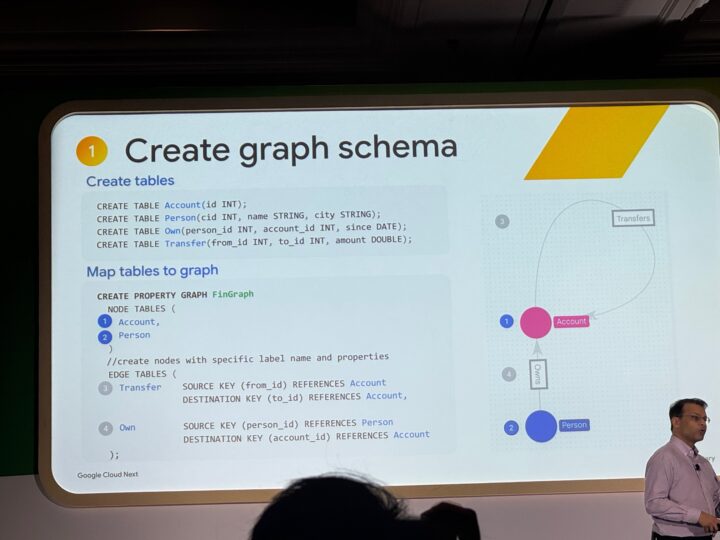
2.グラフテーブルの定義: ノードテーブル(例:アカウント、個人)とエッジテーブル(例:所有関係、取引関係)を定義してグラフ構造を作成
3,GQLでクエリ実行: MATCH構文などを使って、複雑なリレーションシップを簡潔に記述してクエリを実行
例えば、不正検知においては、特定のアカウントに関連する全アカウントとその取引履歴を一つのグラフクエリで取得でき、従来のJOINを多数連ねたSQLに比べて大幅にクエリがシンプルになります。
活用事例:Texas Instrumentsによるコンテンツレコメンデーション
セッションの後半では、Texas InstrumentsのWebエクスペリエンスチームが、BigQuery Graphを活用したパーソナライズドコンテンツレコメンデーションの取り組みが紹介されました。
課題
TI.comには毎日数万人のアクティブユーザーがいる。パーソナライズされたメールを送ることは可能だが、「何を送るべきか」が明確でなかったため、従来は1日あたり数十〜数百通程度しか送れていなかった。

アプローチ:グラフによるデジタルフットプリントの生成
BigQuery Graphを使ってユーザーの「デジタルフットプリント」を生成。
- ユーザー → セッション → イベント(ページビュー、ダウンロード、クリックなど)という階層構造をグラフで表現
- 各イベント間の遷移確率を計算し、ユーザーが次に関心を持ちそうなコンテンツを予測
- ユーザーが過去に閲覧したことのないが、多くの別ルートから辿り着くコンテンツを特定してレコメンド
GQLクエリは非常にシンプルで、MATCH構文を使ってユーザー → セッション → コンテンツ → 遷移先コンテンツという経路を記述し、未閲覧かつコンテンツ型のノードをフィルタリングするだけ。
成果(パイロット運用結果)
| 指標 | 改善率 |
|---|---|
| メール開封率 | 2倍 |
| コンテンツクリック率 | 5倍以上 |
| 1日あたりの送信可能メール数 | 10倍以上 |
| コンテンツダウンロード数(月次) | 100倍 |
このアプローチは今後、製品レコメンデーションや形式(コンテンツ・製品・プロモーション)を横断した統一ランキングリストの生成にも拡張予定。
Spanner GraphとBigQuery Graphの統合ビジョン
BigQuery Graphに加え、セッションではSpanner Graphとの統合的なビジョンも提示された。
- Spanner Graph: リアルタイム・低レイテンシのオンラインユースケース(リアルタイム不正検知、デジタルツインなど)に最適
- BigQuery Graph: 大規模なバッチ処理・履歴データ分析・サプライチェーン最適化・顧客360度分析などに最適
両者はグラフスキーマの定義方法・クエリ言語(GQL)・スキーマの表現形式が統一されており、シームレスな使い分けが可能
Graph × Measures:次世代のAIエージェント基盤
セッションの最後では、グラフとビジネスメトリクスを統合する新機能としてMeasuresサポートが発表されました!

なぜGraph × Measures
メトリクスとグラフを統合
従来のRAGベースのAIエージェントは、データを参照して回答を生成しますが、以下のような限界が生じる
- 「売上がなぜ下がったか」のような因果関係を問う質問に答えられない
- 複数のエージェントやダッシュボードが異なる答えを返す(メトリクスの不一致)
- サプライヤーの変動や需要の損失など、テーブルの結合だけでは見えない関係性を理解できない
解決策:グラフDDLへのメトリクス定義
BigQuery Graphのグラフスキーマ(DDL)の中に、ビジネスメトリクス(合計・平均など)を直接定義できるようになりました。
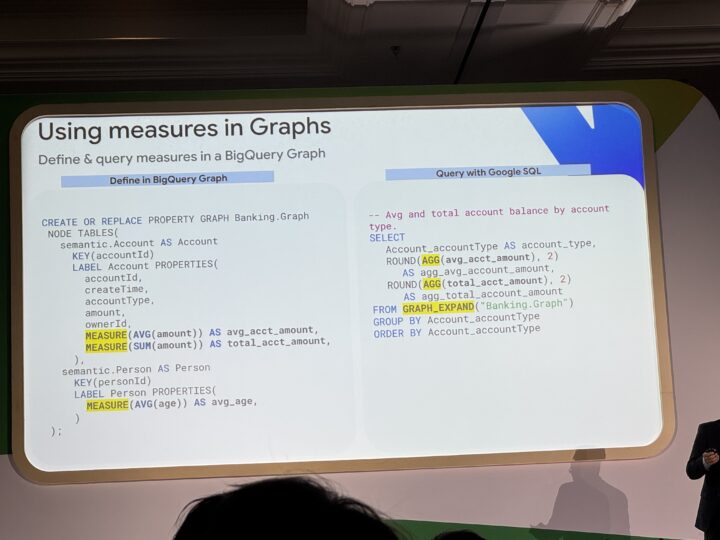
この仕組みにより、AIエージェントはグラフを探索する際に「どのメトリクスが存在するか」「それが何を意味するか」を自動的に理解が可能に。
デモ
従来の純粋なJOINクエリでは、1件のオーダーに複数の商品が含まれる場合に売上が重複カウントされ、実際の売上(427,000ドル)が約990,000ドルと誤って算出される問題が発生した。グラフにメトリクスを定義することで、この種のデータ増幅問題を防ぎ、正確な値を返すことができた。
また、グラフ上でチャットインターフェースを通じた会話型分析も可能になっており、「カリフォルニア州の最も購買額の高いユーザーは誰か」「そのユーザーの購買履歴に基づいて類似製品を推薦してほしい」といった複合的な質問にも、グラフ構造を活用して正確に答えることが可能になっていた。
まとめ
BigQuery Graphは、リレーショナルデータベースの資産をそのまま活かしながら、グラフ分析の強力な能力をBigQueryのエコシステムにシームレスに統合する新しいアプローチです。ETL不要・SQL/GQL相互運用・弾力的スケーリング・メトリクス統合という4つの柱により、不正検知・レコメンデーション・サプライチェーン分析・AIエージェントのグラウンディングなど、幅広いユースケースに対応します。
今後のロードマップとしては、最短経路アルゴリズム・パターンマッチング・中心性分析・Googleの検索技術から派生したグラフアルゴリズムのBigQuery Graphへの組み込みが予定されており、グラフ分析プラットフォームとしての更なる進化が期待されます。




