
この記事は、Google Cloud Next ’26 のセッションレポートです。
セッション情報
- セッション名: What’s new with data and AI governance: Building the catalog for AI
- 登壇者:
- Chai Pydimukkala 氏(Head of Data Governance, Sharing and Integration, Google Cloud)
- Lu Yang 氏(Group Product Manager, Google Cloud)
- Hua Liu 氏(Software Engineer, Bloomberg)
- Katherine Hann 氏(Software Engineer, Bloomberg)
先に30秒でまとめ
発表されたもの: Google Cloud のデータ管理製品「Dataplex」が「Knowledge Catalog」に名称変更になりました。ただの名前変更ではなく、役割が変わっています。
何が変わったか:
- 昔: 社内のデータがどこに何があるか一覧できる「帳簿」
- いま: AI エージェントが仕事をする前に、データの意味を確認しに来る「辞書」
具体的に何が嬉しいか: 自社で作った AI エージェントが、社内データの意味を間違って解釈して変な答えを返す問題が減ります。たとえば「売上」と言っても会社によって定義は違います。その定義をエージェントに正しく教える共通基盤が、プラットフォーム側に用意されました。
目玉機能: Context API と MCP tools。これを使うと、Google 純正エージェントだけでなく、自社で作ったエージェントからも同じ仕組みを使えるようになります。
印象的だった事例: Bloomberg Media の「$42 問題」。エージェントの誤答を自動で学習させてカタログに書き戻す仕組み(KGA)を構築した話で、本番運用で効く設計パターンとして参考になります。
現場のエンジニアが押さえたい3つの論点
セッション “What’s new with data and AI governance: Building the catalog for AI”(BRK1-039)と同日公開の公式ブログを合わせて読むと、次の3つに絞れそうです。
- Dataplex が「データ資産を棚卸しするガバナンス製品」から「エージェントが推論前に叩きに行く実行基盤」に昇格しました。名称変更より役割の再定義が本題。
- Context Retrieval API と MCP tools の整備で、自作エージェントからも Google 純正エージェントと同じコンテキスト基盤を参照できるようになりました。
- Bloomberg Media の事例で、エージェントの誤答からカタログを自動更新する運用パターンが具体的に示されました。
以下、この3点を軸に整理していきます。
ガバナンス製品からエージェント実行基盤へ

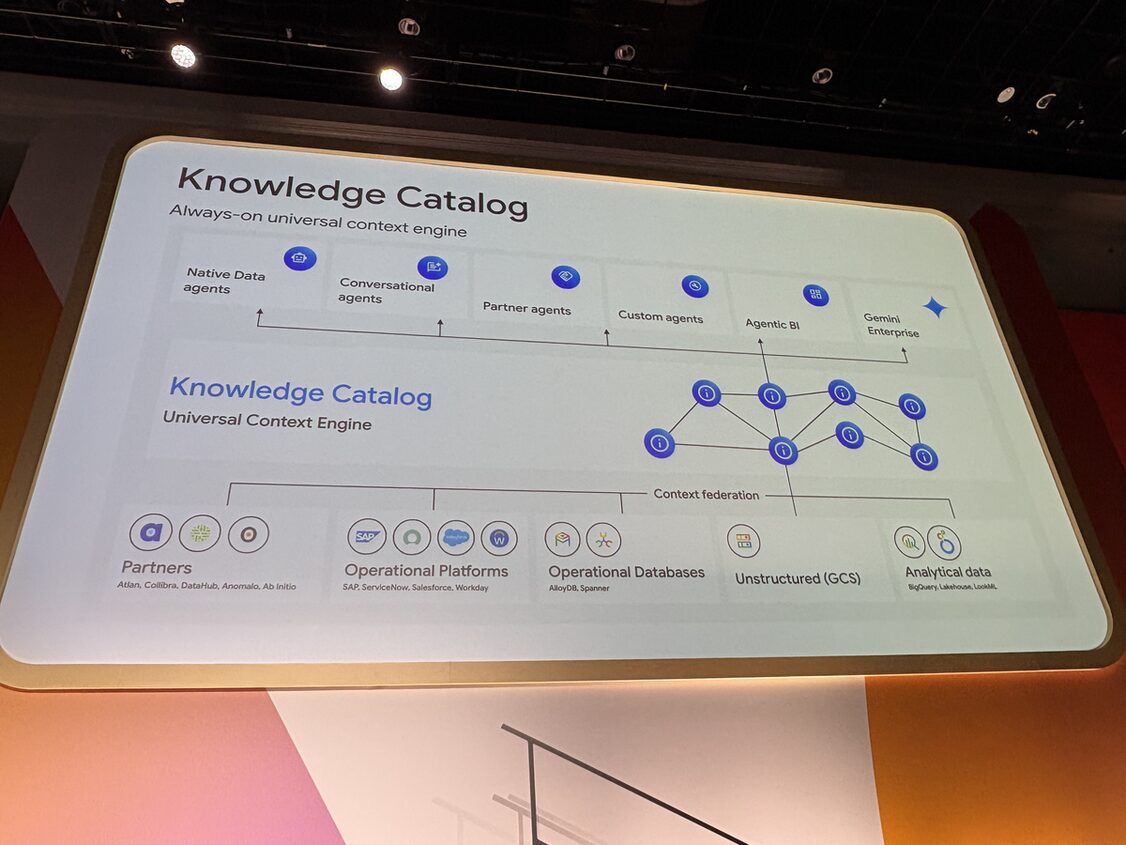
Agentic Data Cloud のスタック図で見ると、Knowledge Catalog は AI Powered Engines 層の直下、Lakehouse 層の直上にはっきりと独立した層として描かれていました。
上には Native Data agents、Conversational agents、Partner agents、Custom agents、Agentic BI、Gemini Enterprise が並びます。下には BigQuery、Lakehouse、AlloyDB、Spanner、Cloud Storage、さらに SAP や Salesforce といった業務系まで横断接続される形。
ここにメタデータとセマンティクスを常時収集・常時補強して集約する能動的な層、という位置づけですね。人間のスチュワードが手で整える受動的なカタログから、エージェントがコンテキストを取りに来ることを前提にした設計へ、思想ごと組み直した感じです。
発表機能群をどう読むか

このスライドが発表の全容を1枚で示しています。以下、Aggregation / Enrichment / Search の3カテゴリに沿って見ていきます。
Aggregation
Lineage を本腰で揃えにきた
BigQuery の column-level lineage、Google Cloud Lakehouse Lineage(Iceberg)といった主要な lineage がまとめて GA になりました。Looker Core や Spark の column-level lineage も後続します。
OpenLineage、API、MCP 経由で拡張できますし、BigQuery Cloud Assist から lineage graph を自然言語で辿る機能も用意されます。AI の出力を裏付ける手がかりとして lineage を整備しきる意図がはっきり見えますね。

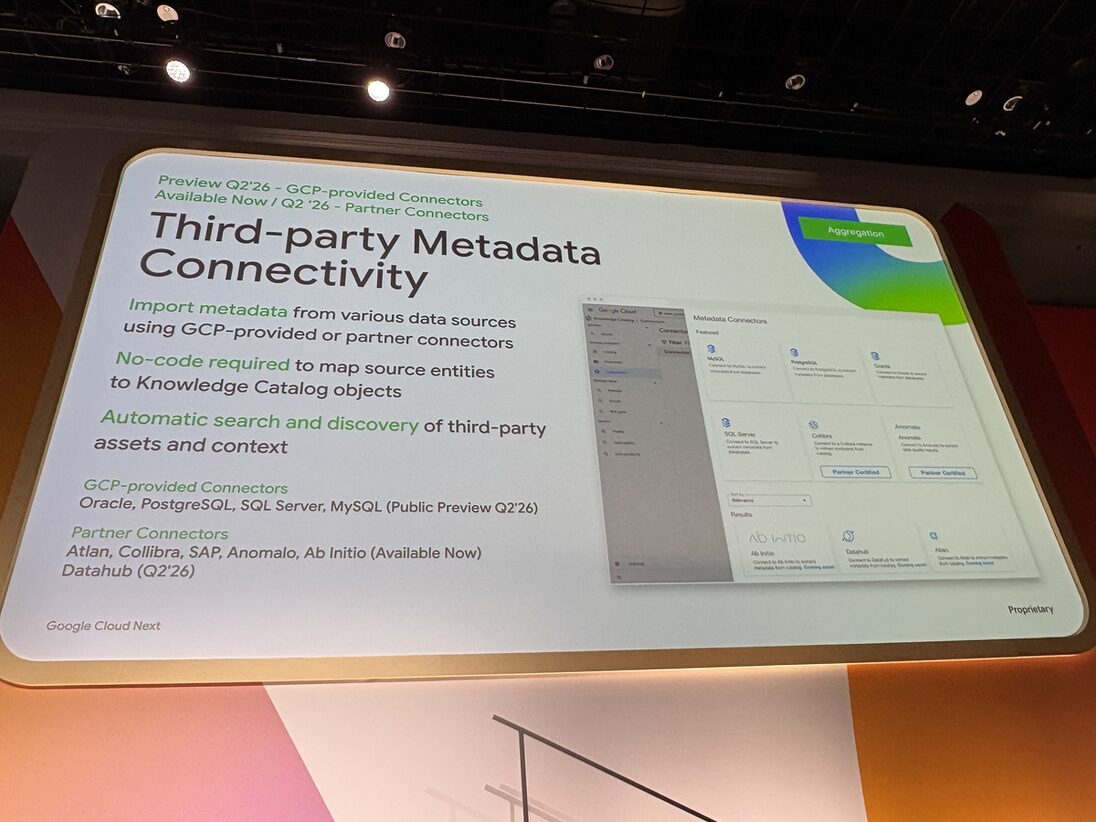
Google Cloud 外の資産も横断接続する
Lakehouse の Iceberg REST Catalog 統合を GA で据えて、Databricks Unity Catalog、AWS Glue Data Catalog、Snowflake Horizon Catalog といった他社 IRC も揃います。主要 RDB のコネクタ、パートナーカタログとの双方向連携も一挙に入りました。
さらに公式ブログで新発表された Enterprise connectivity では、Palantir、Salesforce Data360、SAP、ServiceNow、Workday といった業務 SaaS までカバーします。「Google Cloud の外はカタログから見えない」という前提がここで崩れますね。
セマンティック層を作り直す: LookML Agent と BigQuery measures
この2つ、地味ですけど効きそうなんですよね。LookML Agent は戦略ドキュメントから実用可能なセマンティクスを自動生成してくれるもの。VS Code Extension も併せて提供されます。
BigQuery measures は業務ロジックを SQL エンジン側に埋め込む新機能で、計算定義の再利用性と正確性を担保してくれます。Knowledge Catalog はこの両者を集約する上位レイヤーとして働きます。
「純売上とは何か」を組織で1つに決めてエージェントに配る経路を、ようやくプラットフォーム側が持ったことになりますね。
Aggregation のステータスまとめ:
| カテゴリ | 機能 | ステータス |
|---|---|---|
| Lineage | BigQuery column-level lineage | GA |
| Lineage | Google Cloud Lakehouse Lineage (Iceberg) | GA |
| Lineage | Looker Core lineage | Preview |
| Lineage | Managed Service for Apache Spark column-level lineage | Preview(GA Q2’26) |
| Lineage | BigQuery Cloud Assist の自然言語 lineage | Preview Q2’26 |
| 横断接続 | Lakehouse Iceberg REST Catalog (IRC) | GA |
| 横断接続 | Databricks Unity IRC / AWS Glue Data Catalog IRC / Snowflake Horizon IRC | Preview Q2’26 |
| 横断接続 | GCP-provided Connectors(Oracle / PostgreSQL / SQL Server / MySQL) | Public Preview Q2’26 |
| 横断接続 | Partner Connectors(Atlan / Collibra / SAP / Anomalo / Ab Initio) | Available Now |
| 横断接続 | DataHub | Available Q2’26 |
| 横断接続 | Enterprise connectivity(Palantir / Salesforce Data360 / SAP / ServiceNow / Workday) | Preview |
| セマンティック層 | LookML Agent / VS Code Extension for LookML | 公式ブログで新発表 |
| セマンティック層 | BigQuery measures | Preview |
Enrichment
Table Insights(メタデータの自動生成を含む)が GA。Gemini が説明、要約、関係性、クエリ推薦を自動で作ってくれます。
非構造化データには、Cloud Storage と組む Smart Storage and Object Context API が入りました。バケット到着時点で自動タグ付けとベクトル化が走ります。Deep multimodal metadata extraction で、複雑な非構造化ファイルからエンティティと業務関係性を抽出するパイプラインも自動構築される仕組みです。
エージェントが SQL を勘で書く問題には Verified queries and semantic guardrails で応えます。正解の SQL パターンと、対応する自然言語質問を事前に用意しておく発想ですね。
ほかに Cross-table Insights、Metadata Change Workflows、Anomaly Detection などもあって、ガバナンス寄りの裏も合わせて締めにきている印象です。
Enrichment のステータスまとめ:
| 機能 | ステータス |
|---|---|
| Table Insights(メタデータの自動生成 含む) | GA |
| Cross-table Insights / Insights for Google Cloud Lakehouse | Preview |
| Unstructured Data Insights | Preview |
| Smart Storage and Object Context API | Preview |
| Deep multimodal metadata extraction | Preview |
| Verified queries and semantic guardrails | Preview |
| Metadata Change Workflows | Preview Q2’26 |
| Business Glossary(at-scale assignment / import / export) | GA |
| Data Quality with reusable rules | GA |
| Anomaly Detection | Preview(GA Q2’26) |
Search
Semantic Search と Metadata Change Feeds が GA。ユースケース単位でアセットとコンテキストをバンドルする Data Products が GA Q2’26、Domains が Preview Q2’26 の予定です。非エンジニア向け OSS 参照実装の Business UI も公開されました。
Search のステータスまとめ:
| 機能 | ステータス |
|---|---|
| Semantic Search | GA |
| Metadata Change Feeds | GA |
| Data Products | GA Q2’26 |
| Domains | Preview Q2’26 |
| Business UI | OSS |
目玉は Context API と MCP tools
今回の発表で実務インパクトが最も大きいのはここだと思います。

自作エージェントと Google 純正エージェントが同じコンテキスト経路を共有する構図を示した1枚ですね。
これまで Knowledge Catalog(旧 Dataplex)のメタデータは、BigQuery conversational analytics や Gemini Enterprise の Deep Research Agent といった純正エージェントが内側から叩く性質のものでした。ADK で自作した社内エージェントや LangChain 系の独自実装から、同じ粒度で参照する標準的な経路はなかったわけです。
Context Retrieval API が入ると、任意のアセットに紐づく技術 / 運用 / 業務のフルコンテキストが、エージェント向けにフォーマットされた形で一発で返ってきます。MCP tools が GA になったことで、自作エージェントは標準プロトコル経由でこの API と検索を呼べるようになります。
ADK ユーザー向けには Knowledge Catalog for Google Cloud Data Agent Kit も発表されて、一次サポートが用意されます。
Knowledge Catalog が、Google 純正エージェント専用の機能から、社内の Python スクリプトからでも叩ける共通インフラに変わる。ここが本当に効くポイントです。自作エージェントが Gemini Enterprise と同じセマンティクスを共有して動くという構図は、本番で定義のブレを抑えるうえで大きな意味を持ちますね。
エージェント開発をやっているチームは、この API 仕様を真っ先に読んだほうがいいと思います。
具体的なステータス:
| 機能 | ステータス |
|---|---|
| Context Retrieval API | Preview |
| MCP tools for search | GA |
| MCP tools for lookupContext and lineage | Preview |
| Knowledge Catalog for Google Cloud Data Agent Kit | Preview |
Bloomberg Media の $42 問題
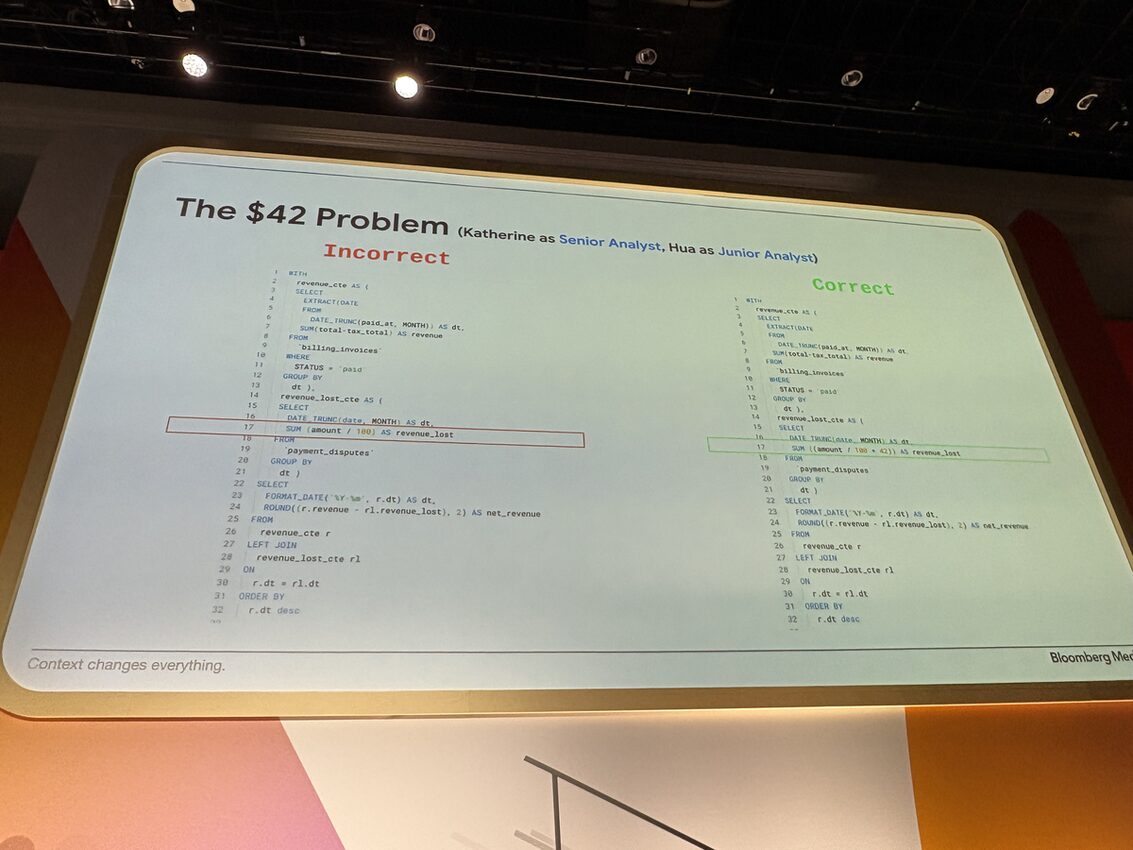
Knowledge Catalog が本番で効くのかを示す事例として登壇したのが Bloomberg Media(有料購読 720K、月間 UU 100M)でした。主役は「$42 問題」と名付けられた、あるあるすぎるエピソードです。
シーンはこんな感じ。月次の純売上を計算したいんですが、決済ベンダーとの契約で不払い1件につき $42 のフィーが取られます。これを引かないと売上が正しく出ません。
ところがこのルール、パイプラインにはハードコードできません。契約ごとに金額が違うからです。では仕様書はどこにあるのかというと、2017年に書かれた社内 Confluence ページ。著者は退社済み。
書かれていない組織知がエージェントの誤答を生む、という構造をそのまま可視化した事例ですね。
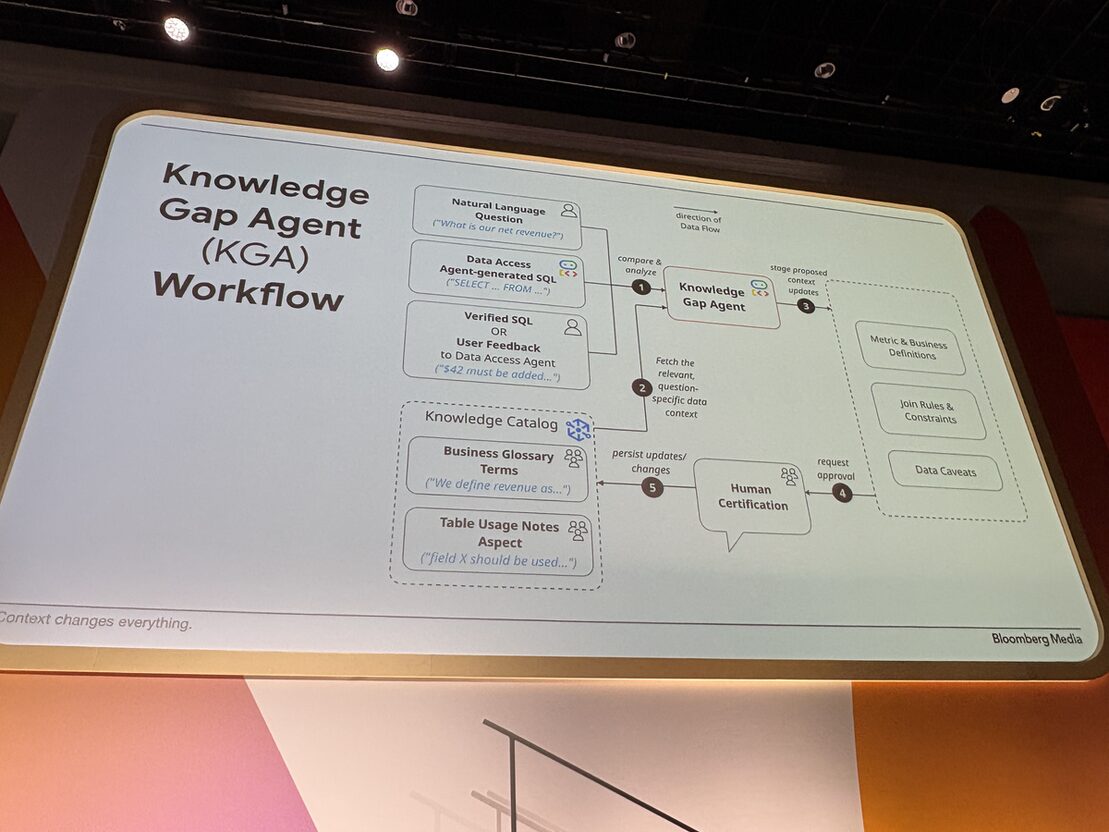
Bloomberg のチームは、Root / Business Analyst / Data Engineering のマルチエージェント構成の Data Access Agent を、MCP Toolbox 経由で Knowledge Catalog と BigQuery に接続しました。
面白いのはもう一段の工夫。エージェントの誤答とユーザーの修正指示のやり取りから組織知を抽出して、Knowledge Catalog に書き戻す別エージェント Knowledge Gap Agent (KGA) を併設しています。
$42 の存在を会話の中で教えると、KGA が該当テーブルの usage notes aspect を特定して永続化してくれます。次のセッションでは誰が同じ質問をしても、$42 が加味された SQL が返ってくる仕組みです。
数字の裏付けとして、Data Access Agent の MVP 開発期間中に KGA は20テーブルで102件の usage note を自動生成し、Data Access Agent の SQL 精度を63%改善したと報告されています。

Bloomberg Media CTO の William Anderson は公式ブログで、AI を “grounding our AI in trusted institutional context” することで、生成される各インサイトの正確性と品質に確信を持てるとコメントしています。
誤答をカタログに還流させるループという設計パターンは、エージェントを本番で運用するチームがそのまま参考にできるものだと思います。
おわりに
正直、会場で聴きながら興奮してました。
自分が普段やってる AI エージェント開発の文脈で、一番のボトルネックって、機能やモデルじゃなくて「データがぐちゃぐちゃ」なんですよね。
テーブルの中身はあるけど、何を意味してるか定義が揃ってない。業務ルールが Confluence のどこかに埋まってる。結果、エージェントにうまく食わせられなくて、活用も進まない。開発してる立場からすると、これが一番つらいです。
今回の発表は、まさにそこを殴りに来た感じがしました。Knowledge Catalog が「エージェントが推論前に意味を確認しに来る辞書」として位置づけられて、Context API で叩ける。Google 純正だけでなく、自作エージェントからも同じ仕組みを使える。
特に Bloomberg の KGA の、エージェントを使えば使うほどカタログが勝手に良くなっていくという構造。本当にこれがやりたくてたまらないです!永久機関を完成させたい。
「データを整えてからエージェント」じゃなくて、「エージェントを動かしながらデータも整えていく」。
データ整備を待っていたら永遠に始まらないところを、エージェントの側から引っ張れる。これ、めちゃくちゃ希望があるなと思います。
帰国後、一番最初に触るのは Context API と決めました!自社のデータに、まずは Knowledge Catalog の仕組みを当ててみて、エージェントに食わせる手前のところから整理も始めたいですね。
続きは別のブログでお会いしましょう!




