
はじめに
この記事ではPagerDuty APIとDatabricks、Lookerで運用分析を進める内容となっています。
今回はDatabricks Blogにあった以下の記事を読んで、うっすら弊社でもできそうなことを思いついたのでいくつかPoCレベルで紹介しようと思います。
こんなことやってみました
- PagerDuty APIにDatabricks Notebooksでアクセス、Unity Catalogを作成してアドホックに分析
- Unity CatalogとGoogle Sheetsとの連携
- Looker 会話分析とコラボレーション
なお、実行環境としては以下のとおりです。
前提となる環境
- PagerDuty
- APIが実行できる環境、今回は弊社の評価環境を利用
- Databricks
- Notebooksが使えれば、FreeでもOK
- 外部ロケーションとしてS3を1つ指定している状態
- Looker
- Developer ライセンスを1つ
PagerDuty APIにDatabricks Notebooksでアクセス、Unity Catalogを作成してアドホックに分析
おおまかな手順としてはつぎのとおりです。
- PagerDuty APIからjsonを取得してjsonlにする
- S3に保存
- S3に保存されたjsonlを使ってUnity Catalogを作成
- SQLを書いてデータを取り出し
ポイントとしてはデータをjsonをjsonlに保存するところです。PagerDuty APIからのレスポンスは純粋なjsonになるため、データを格納するときにエラーとなってしまうことがあります。
また、取り出すデータはKey-Value形式でPagerDuty APIの仕様に沿ったままにしておくと良いです。
理由としてはDatabricksにはメダリオンアーキテクチャというものがあります。
データを取り出して保存する層はメダリオンアーキテクチャのうちBronzeに匹敵しますので、取り出したままが良いです。
なお、S3への保存先についてはバケット内に新しく、プレフィックスを作成しておきます。(例:S3://S3バケット名/bronze)
次にS3に保存されたjsonlを使ってUnity Catalogを作成ですが、これはSparkを使います。
ソースコードの一部を示すと以下のとおりです。Genie Codeで生成しています。
まずはDataFrameを作成します。
s3_path = "s3://S3バケット名/bronze"
# JSONの読み込み(マルチラインを有効にする)
df = spark.read.format("json") \
.option("multiLine", "true") \
.load(s3_path)
# データの確認
display(df)
作成したDataFrameをDelta形式でテーブルとしてUnity Catalogに登録します。
# テーブル名の指定
catalog_name = "workspace"
schema_name = "default"
table_name = "bronze"
full_table_name = f"{catalog_name}.{schema_name}.{table_name}"
# Delta形式でテーブルを上書き(または作成)
# .mode("overwrite") または .mode("append")
df.write.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.saveAsTable(full_table_name)
print(f"Table {full_table_name} has been created successfully.")
これでテーブルが作成されました。
最後にSQLを書いてデータを取り出します。Notebookを使っているので%sqlを忘れないようにしましょう。
スキーマはPagerDuty APIの仕様に沿って書いていけば、だいたいできます。
※Genie Codeを使ったクエリ作成で一発でした。
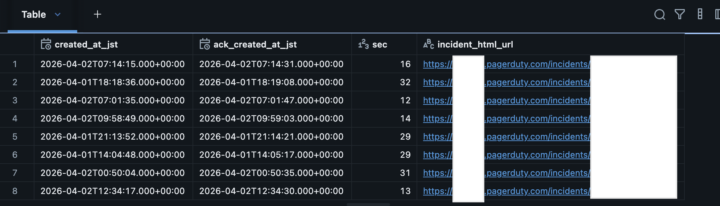
今回はPagerDuty APIが仕様としてもっているcreated_atとincident.html_urlを取り出します。
ただ取り出すだけでは面白くないので以下のクエリではPagerDutyでインシデントが作成された時間とackした時間を2つ取得して差分を計算しています。こうすることでインシデントが作成されてからackするまでの時間が計算できます。
なお、今回利用しているデータは筆者が意図的に発行して作成したインシデントになります。
%sql SELECT from_utc_timestamp(created_at, 'Asia/Tokyo') AS created_at_jst, from_utc_timestamp(get(ack_log_entries, 0).created_at, 'Asia/Tokyo') AS ack_created_at_jst, unix_timestamp(from_utc_timestamp(get(ack_log_entries, 0).created_at, 'Asia/Tokyo')) - unix_timestamp(from_utc_timestamp(created_at, 'Asia/Tokyo')) AS sec, get(ack_log_entries, 0).incident.html_url AS incident_html_url FROM workspace.default.bronze WHERE get(ack_log_entries, 0).created_at IS NOT NULL LIMIT 100
ここで少しだけ気づきですが、一部のデータではデータがテキストではなくKey-Valueの形式になっていました。
そういった場合はgetを使うことで解消するようです。
具体的には以下のとおりです。
%sql SELECT get(ack_log_entries, 0).agent.summary AS first_agent_summary, -- 1番目の要素のsummary ack_log_entries.id AS all_ids -- 全要素のIDを配列で取得 FROM workspace.default.bronze
Unity CatalogとGoogle Sheetsとの連携
こんな感じでUnity Catalogができたところで、Databricksを開かないとデータを参照できないのかと思われるかもしれません。実は最近になってDatabricksさんからスプレッドシート(Google Sheets)との連携が発表されました。
せっかくなのでこれもやってみました。※使い方はblog参照
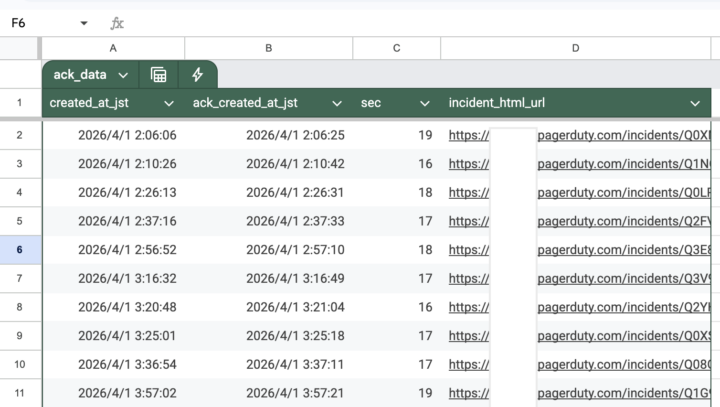
シートにどんなデータを連携するかはSQLで指定できます。今回はPagerDuty APIの仕様に沿っているのでカラム名はPagerDuty APIのレスポンスと互換性があります。
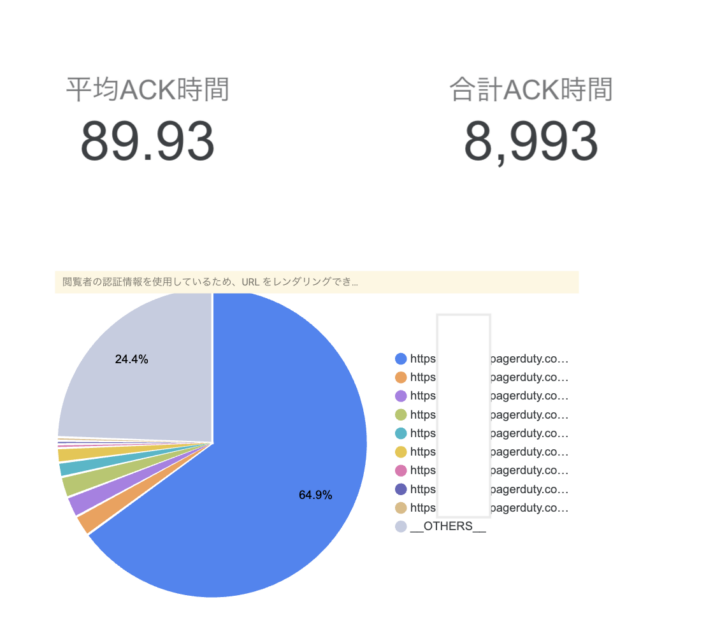
もちろん、Data Studio(旧Looker Studio)で可視化もできます。
Looker 会話分析とコラボレーション
これはまだ試せていないため、イメージと設計イメージを共有したいと思います。
まずはLooker会話分析は以下のようなイメージです。
会話分析ではAIが結果をサマライズするため、算出した数値が正しいかどうかを確認できるように、背景知識となる数値を共有します。
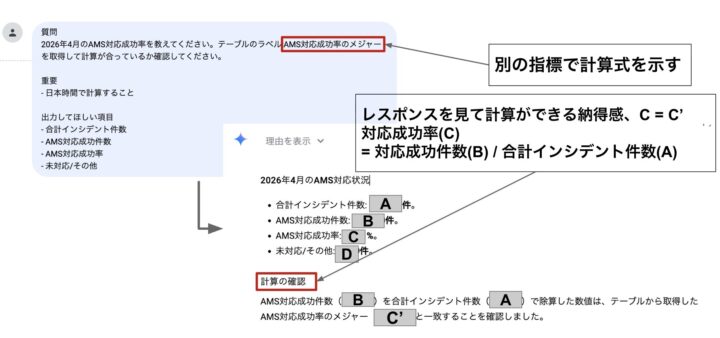
なお、弊社におけるLooker、特に筆者の所属するセクションにおいてはデータソースをAmazon Athenaとしているため、Databricksと以下のようなコラボレーションが可能です。
1.Glue Data Catalog にデータを登録
2.Unity CatalogとGlue Data Catalogでフェデレーション
3.Unity CatalogをDatabricks Notebookで参照
逆もしかりです。Unity CatalogからGlue Data Catalogというパターンも可能です。
これはDelta Sharingという機能を使います。
つまり、以下の手順が可能です。
1.PagerDuty APIからデータを取得
2.DatabricksでUnity Catalogを作成、Glue Data Catalogに共有
3.LookerでLookMLを書いてデータモデルを登録
4.LookerのExplorerと会話分析で生成AIを使ったデータ分析
まとめ
今回はPagerDuty + Databricks + Lookerという3つの製品コラボレーションを紹介しました。
とてもいろんなことができる反面、高いスキルが要求されると見ていますが
分業できれば、現実的な範囲で実現できるものだと認識しています。
また、レイクハウスというとBigQueryもあります。
BigQueryには、Glueとのフェデレーションもあるのでどのように接続するとよいかのアーキテクチャを考える力が問われそうです。
なお、今回これをやろうと思った理由としては「ローカルでデータエンジニアリングってキツいところあるよね?」というところから始まっています。ブラウザ一つで全部できるのは最高です。
くわえて、データを全部Databricksが参照できるようにすれば、運用分析用のAIや昨今流行りのSREエージェントを内製するときのヒントになるかも?とも思っています。
最後にこれは検証を通して終始思っていたんですが、Genie Codeが便利すぎました。
今回は以上です。Databricksで最高の運用分析ライフを体感してみてください。


