
連載の軌跡
〜実践!Google Cloud × Geminiで作るナレッジ自動化〜
| # | テーマ | ひとことで言うと |
|---|---|---|
| 1 | 本記事 (統括編) | 課題・理想・企画・結果の共有 |
| 2 | Zendesk × Gemini × BigQuery で完全自動のナレッジ蓄積パイプラインを構築 | Zendeskチケットを Gemini で要約させ スプレッドシート 経由で BigQuery へ流すまでの自動化 |
| 3 | Gemini × Agent Development Kit (ADK) × Slackで作る「人とAIが対話して決める」業務自動化パイプライン | ADK のマルチエージェントと Slack で記事の自動作成 & 人による承認フロー |
| 4 | Gemini × BigQuery × Cloud Runで実現!SlackからGoogleドキュメントを自動生成するナレッジ蓄積パイプラインの構築と24/7運用化 | 承認後の本文自動生成と Cloud Run + Scheduler での 24/7 運用 |
技術詳細はすべて2〜4に書いたので、本記事は 連載の背景 として読んでいただけますと幸いです。
課題 ─ なぜ作ろうとしたか
PoC を始める前、サポート業務の周辺には次のような課題がありました。
- 社内ナレッジが活かせていない
過去のチケットや対応ノウハウが Zendeskに散在し、「以前も似た問い合わせを受けた気がする」と思っても辿り着けず、ゼロから調べ直すことが多い - 問い合わせを捌いているだけになりがち
「対応 → クローズ → 次のチケット」のループに追われ、対応した経験から学びを抽出して翌月以降に繋げる工程が業務に組み込まれない - 情報が集約されない
記事化しようとしても、過去事例の収集・粒度調整・重複チェックなど書く前段の負荷が高く、結局後回しになり、ナレッジが各人の頭に分散したままになる
要するに「情報はあるのに、流通していない」状態でした。
理想 ─ 目指した状態
課題の裏返しとして、PoC で実現したい状態は次の3つに整理できました。
- 社内ナレッジが活用できている
チケット履歴を「眠っているデータ」ではなく「日々参照される情報源」として使える - 記事化することでお客様への案内がスムーズになる
同種の問い合わせに対し、記事の URL を1行貼るだけで案内が完結する - 情報が集約される
顧客対応を開始する前に確認する場所として、情報が1か所に集まった状態
重要なのは 「全自動で記事を量産する」ことが理想ではない という点です。記事の品質を担保するには人の判断が必要で、現場文脈を反映できないナレッジは結局使われません。理想は 「AI が下案を出し、人が短時間で意思決定し、結果が蓄積される」 というフローでした。
企画 ─ どう解こうとしたか
理想に至るための設計の柱を、PoC 着手時に4つ立てました。連載1〜3を貫く設計思想でもあります。
- AI と人の役割分担を明確にする
「全自動」ではなく「AI が下案、人が決断」を前提にする - LLM をどう信じないかを設計する
ハルシネーション前提で、正確さが要る箇所には外部の真実 (検索 / DB) を当てる - 人の判断データだけを次の AI 処理に流す
公開判定 (:zumi:リアクション) を経た記事だけを次回の重複検知の母集団にする - プラットフォームの自動化に乗っかる
Drive API の markdown→HTML→Doc 変換、Cloud Run のメタデータサーバ、Slack Bolt の Events API連携などを素直に使い、自前実装を最小化する
結果として作ったもの
連載1〜3を経て最終的に出来上がったのは、Slack と Google Cloud だけで完結する次のような仕組みです。
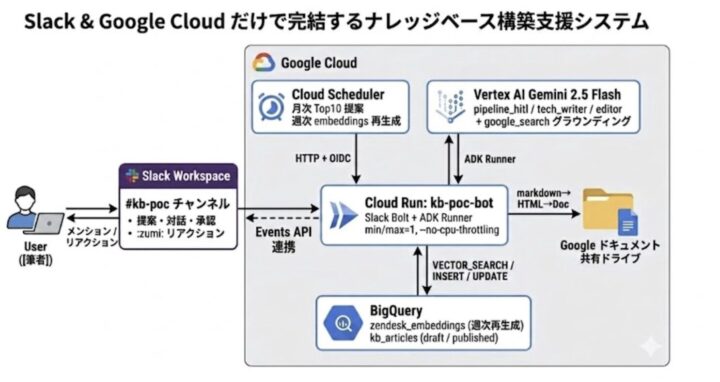
各レイヤの役割は次のとおりです。
- Slack
唯一の操作接点。Top 10 提案を見て、対話で修正指示・部分承認を返し、生成後は:zumi:リアクションで公開判定する - Cloud Run (
kb-poc-bot)
Slack Bolt と ADK Runner を載せたオーケストレーター。Slack の Events API webhook を /slack/eventsで受け、min=max=1 で常駐 (アイドル時は CPU を throttle してコスト最適化) - Vertex AI Gemini 2.5 Flash
3つのエージェント (pipeline_hitl / tech_writer / editor) を切り替えて、提案・本文生成・校正を担当 - BigQuery
チケットデータ・要約・Embedding と、kb_articlesの記事メタを保持。embedding列を VECTOR_SEARCH で叩いて類似チケットをグラウンディング - Google ドキュメント (共有ドライブ)
生成された記事本文の置き場。markdown を Drive API で HTML 経由 Doc に変換して保存 - Cloud Scheduler
月次の Top10 自動分析と、週次の Embedding 再生成
連載1で 基盤 を作り、連載2で AI と人の合意形成ループ、連載3で 記事生成と運用化 を作った、という 3 段構えで、本記事冒頭の理想像にあたる仕組みが組み上がりました。
開発結果とこれからの課題
課題と理想に対しての到達度
| 課題 | 理想 | 本開発で到達した状態 |
|---|---|---|
| 社内ナレッジが活かせていない | ナレッジが活用できている | チケット履歴が要約・Embedding 化され、月次で記事化候補として Slack に流れてくる |
| 問い合わせを捌いているだけ | 案内がスムーズになる | 案内に使える 記事ドラフトが手元に継続的にストックされていく |
| 情報が集約されない | 情報が集約される | 共有ドライブと kb_articles テーブルに記事メタが一元管理され、後から横串で検索できる |
観測できた手応えと、まだ確かめられていないこと
開発してみて実際に感じたのは次の3点です。
- 月次の提案を眺めるだけで、自分の中での「最近多いトピック」の解像度が上がる
- 重複検知が効いており、過去に書いた記事と類似度が高いトピックは提案時点で警告が出る
- 記事ドラフトの品質は「そのまま公開はできないが、ゼロから書くより速い」レベルに収まっており、Editor の
<editor_notes>を頼りに手を入れれば1記事30分前後で公開判断まで持っていける
逆に、まだ確かめられていない のは次のような点です。
- 長期運用で記事ストックが増えたときの整理運用 (賞味期限切れの記事の扱い)
- 複数人が同時に書き出しを走らせたときの並列実行挙動
連載で感じたAI開発における原則
連載を通して何度も顔を出した、今後も使えそうな原則 を6つにまとめます。
- AI の部分は全体の2割、残り8割はインフラと運用とUX
- LLM をどう信じるかではなく、どう信じなくていいかを設計する
- 役割分担を1つのプロンプトに詰めない
- 人の判断データだけを次の AI 処理に流す
- プラットフォームの自動変換に乗っかる
- 観測性は最初から組み込む
まとめ
今後にどう活かしたいか
- 「LLM + 外部の真実」パターンの横展開
ハルシネーション対策として、検索 / DB / 既存ドキュメントを引用させる構造は他開発をする際も軸にしたいです。 - 「人の判断データだけを次に流す」パイプライン設計
公開フラグの仕組みは他のワークフローにも応用が利きそうだと思います。
感想
連載を書ききって思うのは、新しい技術が来てもエンジニアの本業は変わらない ということでした。AI そのものに過剰な期待をするのではなく、AI と人の役割分担を設計する力 こそが、これからより重要になりそうです。今回はまだ私個人のスコープでの運用ですが、設計判断の根っこは「課題 → 理想 → 企画 → 結果」のどのフェーズでも同じであると感じました。
連載をここまで読んでくださった方、ありがとうございました。「自分のチームでも使えそう」と思った方は、ぜひ各記事のコードや設計判断を参考にしてみてください。




