
はじめに:SQLを書けない人でも、BigQueryのデータを分析できるのか
「データは BigQuery にあるけれど、SQL が書けないので結局エンジニアに頼む」ということは多くの業務現場で起きていることだと思います。
Conversational Analytics for BigQuery という機能はその入口を変えるかもしれません。
BigQuery のデータに対して、日本語の自然言語で質問するだけで、AI が SQL を生成して実行し、回答とグラフを返してくれます。
今回は非エンジニアや SQL に不慣れな人が、自然言語でどこまで BigQuery を分析できるのかを検証しました。結論を先に言うと、よくある集計(上位ランキング・地域別・利益率・月別推移)は実用レベルでした。一方で、曖昧・高度な問い(異常値の検出など)では AI が独自の前提を置くため、そのまま信じず確認が必要だ、という学びも得られました。
今回の検証環境
- BigQuery に合成のサンプル売上データ(約 200 行・2025-10〜2026-03・架空データで個人情報なし)を用意。列は
order_date / region / product_category / product_name / customer_segment / sales_amount / cost_amount / profit_amount / quantity。 - 必要な API:
geminidataanalytics(Conversational Analytics API)・cloudaicompanion(Gemini for Google Cloud)・bigquery。
コンソール画面と、本記事の裏取り
コンソール画面で該当のデータセットを選択した時、右上にチャット(プレビュー)という項目がありました。
チャット(プレビュー)を押下してこの画面から自然言語での質問を試しました。
ただし、AI の回答をそのまま信じるのは禁物です。そこで今回は、3 つの角度から確かめました。
役割が違うので、先に整理しておきます。
- 画面で聞く(体験): コンソールの「チャット」から日本語で質問します。回答・グラフ・AI が書いた SQL がその場で表示されます。(上のスクリーンショットを参照ください)
- SQL で答え合わせ(検証): AI が表示した SQL を、自分で BigQuery に実行し、回答の数字と一致するかを確かめます。「AI が出した数字は本当に正しいのか」を裏取りする工程です。
- 別の経路でも聞く(比較): 同じ質問を Conversational Analytics API(
geminidataanalytics)経由でも投げ、画面と同じように動くかを見ます。今回の検証では、画面(Gemini 3 Flash)と API(gemini-2.5-flash)でモデルが違い、後半の Q5 では前提の置き方に差が出ました。
ざっくり言うと、①と③は「AI に同じ質問を投げる 2 つの経路」、②は「AI の答えを人間が検算する方法」です。本記事では ① の画面を主役に見せつつ、② と ③ で裏取りしていきます(③ の API 側は、永続的な「データエージェント」を作らず、リクエストごとに対象テーブルを指定する stateless 方式で試しています)。
できたこと:自然言語の質問が、ちゃんとした集計になる(Q1〜Q4)
同じサンプルデータに、基本的な質問を日本語で投げてみました。
そしてAI が生成した SQL を BigQuery で実行し、結果が一致するかを確認しています。
| 質問(日本語) | AI が生成した SQL の要点 | 結果(AI と手動実行が一致) |
|---|---|---|
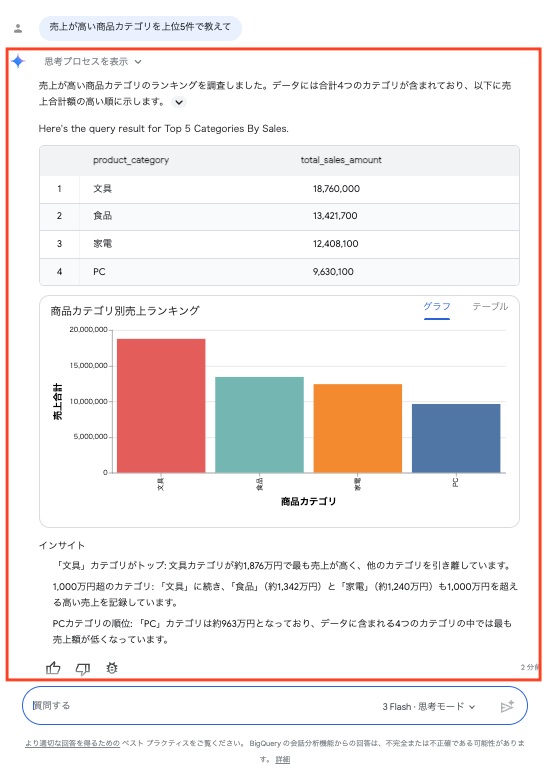
| 売上が高い商品カテゴリを上位5件で教えて | GROUP BY product_category + SUM(sales_amount) 降順 |
文具 約1,876万 / 食品 約1,342万 / 家電 約1,241万 / PC 約963万(カテゴリは4種なので4件)。一致 |
| 地域別の売上傾向を教えて | DATE_TRUNC(order_date, MONTH) × region で集計 |
5地域 × 6か月 = 30行。一致 |
| 利益率が低い商品カテゴリを教えて | SAFE_DIVIDE(SUM(profit_amount), SUM(sales_amount)) を昇順 |
文具 31.3%(最低)→ PC 33.8% → 家電 34.3% → 食品 34.5%。一致 |
| 月別の売上推移を教えて | DATE_TRUNC(order_date, MONTH) で月次集計 |
6か月分。10月が最高、11月に落ち込み後に回復。一致 |
AI が生成した SQL は次のとおりでした。
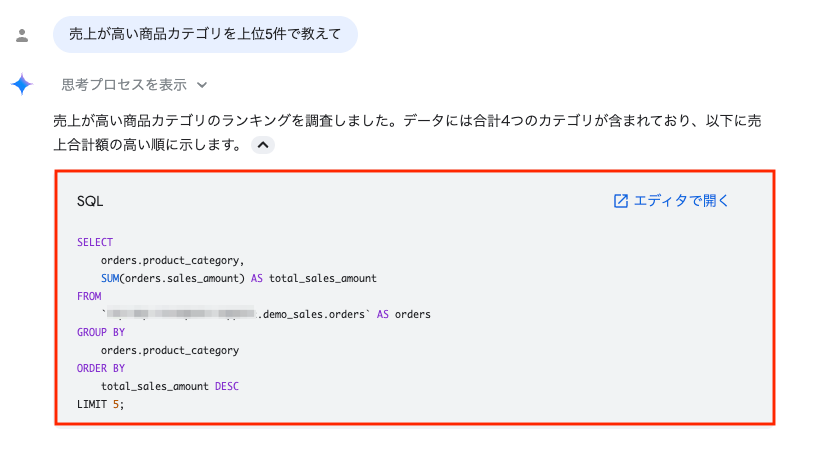
SELECT product_category, SUM(sales_amount) AS total_sales_amount FROM `YOUR_PROJECT_ID.demo_sales.orders` AS orders GROUP BY product_category ORDER BY total_sales_amount DESC LIMIT 5;
ポイントは2つです。
- 日本語の質問が、妥当な SQL に変換されていた。例えば「利益率が低い」に対しては
SAFE_DIVIDE(ゼロ除算を避ける関数)を使うなどしていました。 - AI が出した数字を、生成 SQL の手動実行で裏取りでき、一致した。つまりこの範囲なら「まず自分で聞いて、生成 SQL で確かめる」が成立します。
AI は回答に短いインサイト(「文具は売上最大だが利益率は最低=薄利多売の可能性」など)も添えてくれて、最初のあたりを付けるには十分でした。
注意点:曖昧・高度な問いでは、AI が“解釈”と“手法”を選ぶ(Q5)
一方で、「異常値っぽい注文を抽出して」という曖昧な質問では、結果の受け取り方に注意が必要でした。これは機能の不具合ではなく、AI が質問の意図を補うために、解釈・手法・対象を自分で決めるために起きることです。
今回 Console(Gemini)が行ったのは、次のような複数ステップの分析でした。
- 「異常値」を自分なりに解釈し、手法を組み合わせた: ① 日次の売上合計に BigQuery ML の
AI.DETECT_ANOMALIES(学習期間とテスト期間に分けて異常を検出する関数)をかけ、2026-03-25 を異常な日として検出(予測上限 約 219 万円に対し約 334 万円)。② あわせて「売上が極端に高い個別注文(トップ10)」も抽出。 - AI 側の見立てを言葉で添えた: 「異常値は特定の地域に限定されず、札幌・大阪・名古屋・福岡など各地で発生」「180 万円の高額注文は入力ミスや大口案件の可能性」など、AI が前提や解釈を補足していました。
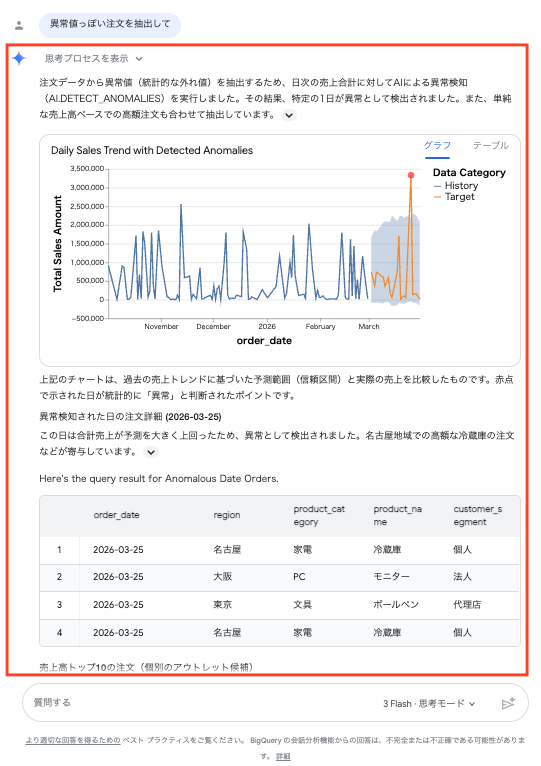
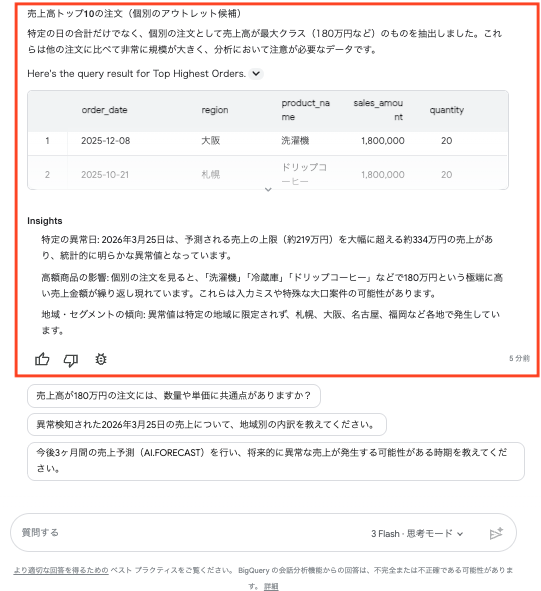
ここで注目したいのは、同じ質問でも、使うモデルや経路によって AI の置く前提が変わることです。裏取りのために別経路(API 経由・gemini-2.5-flash)で同じ質問を投げたところ、今度は対象を「名古屋」地域だけに絞って分析しました(Console 側のモデルは Gemini 3 Flash)。Console 版は全データ、別経路版は名古屋限定どちらも明確な誤りとは言えませんが、前提が違えば答えも変わります。
これはConversational Analytics が壊れているという話ではありません。曖昧で高度な問いほど、AI は解釈・対象範囲・手法を自分で補うので、その前提が自分の意図と合っているかを人間が確認する必要がある、ということです。実務では次の3点を確認するのが安全です。
- 解釈・前提: AI が「異常値」をどう定義し、対象範囲をどう取ったか(全体か、特定地域か)。
- 手法: どんな計算・関数を使ったか(今回は
AI.DETECT_ANOMALIES+ 高額注文の抽出)。 - 生成 SQL と結果の対応: 表示された生成 SQL を自分で実行して結果と突き合わせる(経路によっては、表示された SQL と最終表示が一致しないこともあります)。
まとめ
- 入口としては実用的: 上位ランキング・地域別・利益率・月別推移といったよくある集計は、自然言語の質問だけで妥当な SQL になり、手動実行とも一致しました。「SQL が書けないから聞けない」を「まず自分で聞いてみる」に変えられます。
- ただし鵜呑みにしない: 曖昧・高度な問いでは AI が前提を置きます。生成 SQL・前提(対象範囲)・実行結果は人間が確認する運用も必要になるかと考えます。
- コンソール画面の「チャット」にはプレビューという記載がありました。そのため利用時は公式ドキュメントで最新を確認してください。
非エンジニアの「最初の一歩」を大きく下げてくれる一方で、AI の答えを検証する力はむしろ重要になるというのが、今回の率直な感想です。



