
こんにちは、セキュリティエンジニアの田所です。
現地参加している AWS Summit Japan 2026 からセッションの模様をお届けします。
セッションについて
CNS317 AI エージェントのオブザーバビリティ実践
AI エージェントを活用したアプリケーションの開発が進む一方、オブザーバビリティをどう実現するかは多くのエンジニアが直面する課題です。AI エージェントは非決定的に動作し、LLM やツールの呼び出しが複数ステップにまたがるため、従来のアプリケーション監視では十分ではありません。本セッションでは、OpenTelemetry をベースとした計装から、Amazon CloudWatch generative AI observability によるメトリクス・トレース・ログの可視化、Amazon Bedrock AgentCore Evaluations を用いた応答品質の評価まで、AI エージェントのオブザーバビリティについて解説します。
本番運用を見据えて AI エージェントのオブザーバビリティ導入を検討している方に向けたブレイクアウトセッションでした。

1. AI エージェントのオブザーバビリティが難しい理由
生成 AI は、ルールに従って動くアシスタントから、複数のエージェントが連携して動く自律システムへと進化してきています。
自律性とビジネスインパクトが上がるほど、人間が介入する領域は少なくなっていきます。
裏を返せば、システムの挙動を能動的に観測しないと、何が起きているのか分からなくなるということです。

オブザーバビリティの基本は、メトリクス・ログ・トレースの3つのシグナルです。
ここに生成 AI ならではの観点が加わります。
- メトリクス:呼び出し数やレイテンシに加え、トークン消費量のような生成 AI 特有の指標
- ログ:同じ入力でも出力が変わるため、実際の入出力をそのまま残すことが重要
- トレース:ユーザーの指示から応答までの一連の流れの追跡
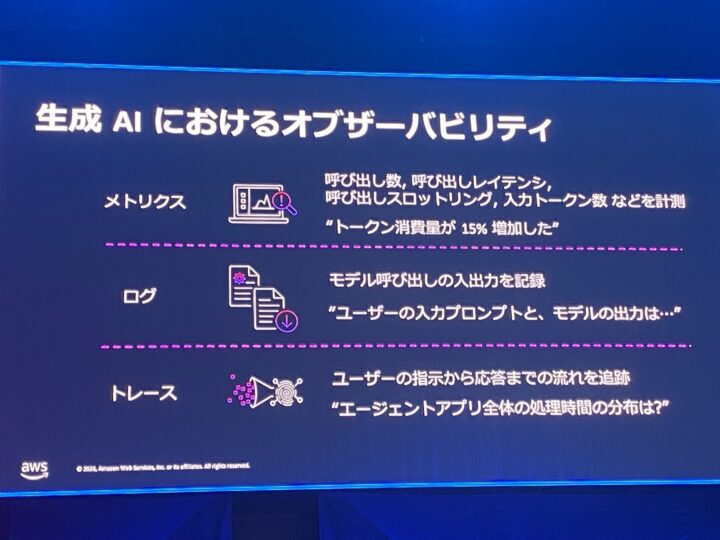
印象的だったのは、生成 AI ワークロードは「正常に稼働していても能動的に観測する必要がある」という指摘でした。
失敗が必ずしもエラーとして記録されないからです。
トークン消費が増え続けている、ハルシネーションが起きている、といった事象はエラーログには出てきません。
このセッションでは、生成 AI 特有の課題を 4 つに整理していました。
非決定的な動作、複雑に連鎖する呼び出し、生成 AI 特有のシグナル、そして応答品質の評価です。

「動いているのにおかしい」を積極的に捉える、という発想の転換が必要だと感じました。
2. OpenTelemetry と CloudWatch 生成 AI オブザーバビリティ
これらの課題に対する土台が OpenTelemetry (OTel) です。
テレメトリデータを収集するためのオープンソースフレームワークで、ベンダーに依存しないデータモデルを提供します。

ありがちな悩みとして、言語やクラウドが違うとコンポーネントごとに別々の計装ツールが必要になる、という問題があります。
OTel を使えば、構成がバラバラでもすべて OTel 形式で統一して処理できるようになります。
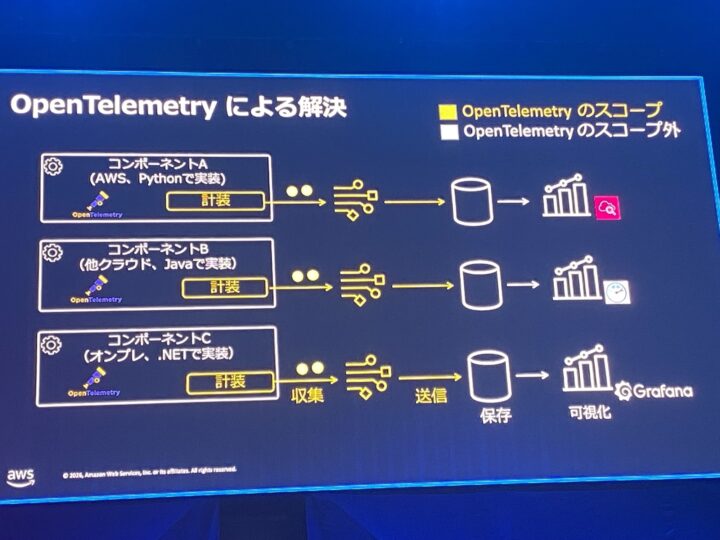
AWS はマネージドなディストリビューションとして AWS Distro for OpenTelemetry (ADOT) を提供しています。
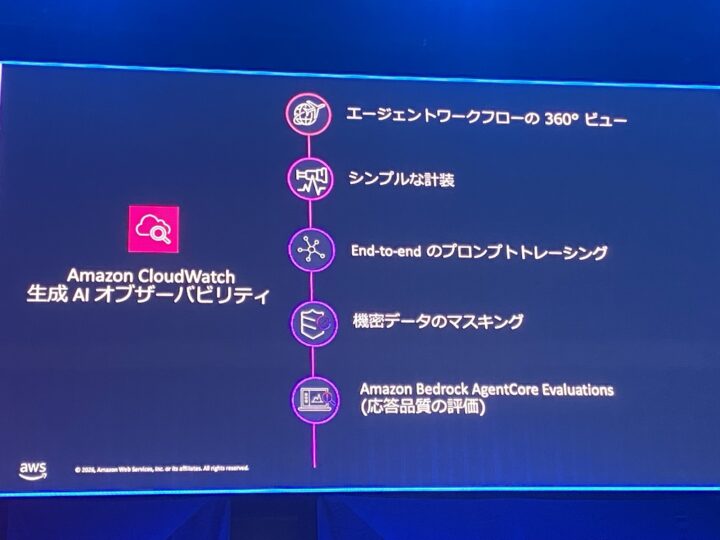
そして収集したデータの可視化先が Amazon CloudWatch 生成 AI オブザーバビリティです。
エージェントワークフローの 360 度ビュー、シンプルな計装、End-to-end のプロンプトトレーシング、機密データのマスキングといった機能が並びます。
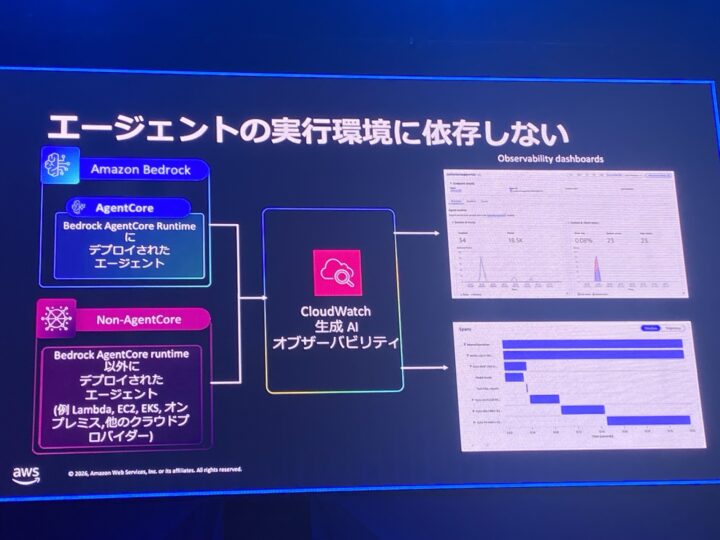
ありがたいのは、エージェントの実行環境に依存しない点です。
Bedrock AgentCore にデプロイしたエージェントはもちろん、Lambda や EC2、EKS、オンプレ、他のクラウド上のエージェントからもデータを送信できます。
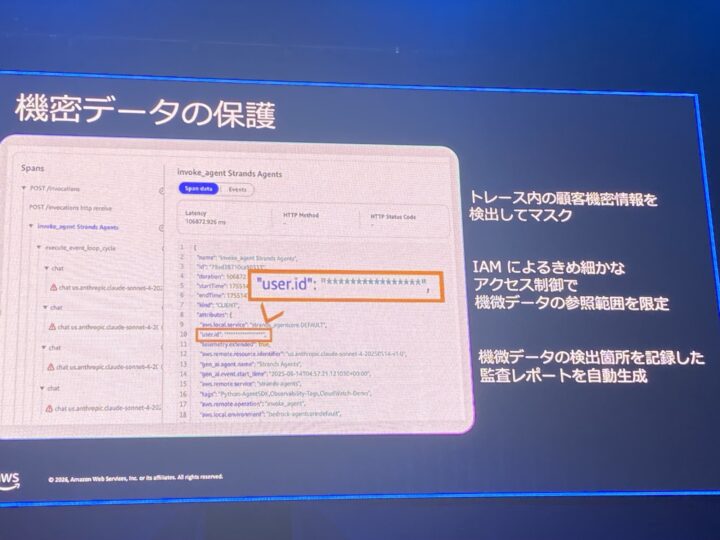
ログまわりは、セキュリティ目線で特に気になったポイントです。
生成 AI の挙動は同じ入力でも再現できないため、呼び出しログ (Invocation Logs) と回答のログ (Agent logs) を残せるようになっています。
さらに、ログに含まれる機密情報はマスキング可能で、限定されたユーザーだけが元データを参照できる権限設計が推奨されていました。
検出箇所を記録した監査レポートも自動生成されるとのことです。
トレースは、セッション・トレース・スパン・サブスパンという階層構造になっています。
E2E で可視化することで、複雑に連鎖する呼び出しのどこでエラーが起きたのかを切り分けられます。
カスタム属性の付与もできるので、業務に合わせた観測ができそうですね。

3. AgentCore Evaluations で応答品質を評価する
最後の柱が、パフォーマンスではなく「応答の品質」そのものを評価する仕組みです。
これまで人間が定性的に行っていた評価を、Amazon Bedrock AgentCore Evaluations が LLM-as-a-Judge でスコア化して判定してくれます。

評価観点は、情報への忠実さ・指示への忠実さ・有用性・回答の的確さといった軸で整理されています。
14 種類の組み込み Evaluator が用意されており、独自のカスタム Evaluator も作成できます。
評価結果は CloudWatch 経由で AgentCore Observability に統合され、一元的にモニタリングできるのもうれしいところです。

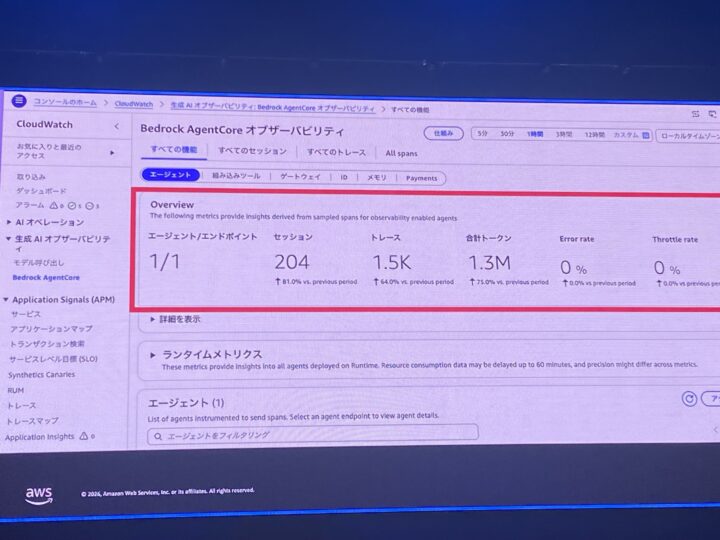
デモでは、ペットショップでおすすめのペットフードを提案するエージェントを題材に、CloudWatch 生成 AI オブザーバビリティの画面が紹介されました。
エージェント別のインサイトやメトリクス、セッションごとのトレース・レイテンシ・エラーが一画面で確認できます。
セッション数や合計トークン、エラー率といった数字が並ぶダッシュボードは、運用のイメージがぐっと湧くものでした。
まとめ
AI エージェントのオブザーバビリティについて、課題の整理から OpenTelemetry による計装、CloudWatch 生成 AI オブザーバビリティでの可視化、AgentCore Evaluations による品質評価まで、一通り見てきました。
AI エージェントの自律性が高まるほど、観測すべき範囲はメトリクスやログから「応答の品質」へと広がっていることを実感しました。
非決定的なシステムを安心して本番運用するための道具が AWS 側に揃っており、セキュリティ観点でもマスキングや監査レポートまで踏み込んでいる点は心強いと感じました。
本番投入を見据えて、まずは手元のエージェントに計装を入れるところから試していきたいと思います。
おしまい


![[AWS Summit Sydney 2026] エージェンティックな世界における先進的なチーム構造](https://iret.media/wp-content/uploads/2026/06/5be593864f50750d0997386cb691de4f-220x123.jpg)
