
概要編
プロダクト概要
画像内の特定の構造物の検出
採用したAIモデル
DeepLabV3
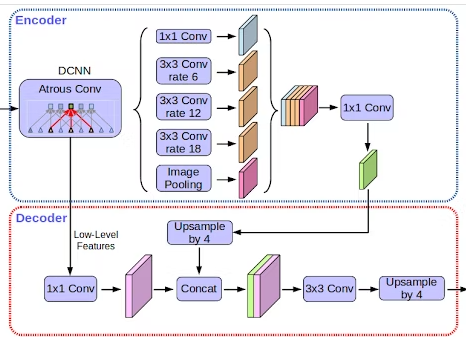
画像出典元:https://developers-jp.googleblog.com/2018/04/semantic-image-segmentation-with.html
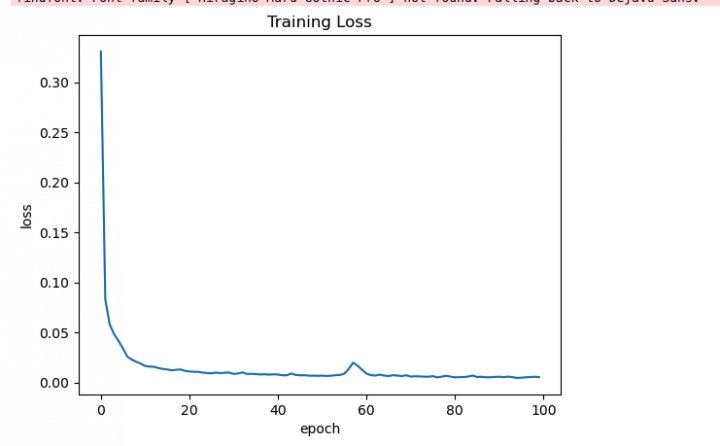
損失関数
SparseCategoricalCrossentropy accuracy ver
diceloss ver
dicelossとSparseCategoricalCrossentropyのaccuracyを比較しながら使用
SparseCategoricalCrossentropy – 離散化されたカテゴリ予測に使用可能なカスタマイズされたクロスエントロピー誤差関数
最適化アルゴリズム(optimizer)
Adamを使用
主に参考にした技術サイト
訓練データイメージ図
工夫したこと
- UnetとDeepLabV3を並列で検証することで、それぞれの優位点の検証の実施
- Data Augumentaion をする際に、オフライン拡張では、処理速度が遅いのと、手間があったのためオンライン拡張を実施。
- エッジ成分を薄めないために、リサイズロジックとしてNearest neighborを使用
苦労したこと
- 画像の解像度が高く、GC上でのメモリが足りなくなりやすかった(4k画質)
ラベル付けから訓練までの流れ(Path名は一例)
教師データ、ラベルデータ作成のツールはlabelmeを使用
# labelmeでのラベルづけ後の対応手順書 ## labelme実行 labelme ## ラベルづけ完了 ## 作業1: ファイルのコピー、移動 cd /Users//gitdir/build-segmentation rm labelme/examples/semantic_segmentation/train/* cp images/addLabelWork/* labelme/examples/semantic_segmentation/train ### やっていること 以下ディレクトリにjsonとjpgを作業ディレクトリからコピー build-segmentation/images/addLabelWork ↓ build-segmentation/labelme/examples/semantic_segmentation/train/ ※ build-segmentation/labelme/examples/semantic_segmentation/label.txt も変更点あればちゃんと変更すること ## 作業2: labelme実行でのラベルつけ処理を実施(data_datasetディレクトリを消してから実行) cd labelme/examples/semantic_segmentation rm -rf data_dataset python3 labelme2voc.py train data_dataset --labels labels.txt ## 作業3: 作成したdata_datasetを訓練用のディレクトリにコピー cd /Users//gitdir/build-segmentation rm -rf images/train/* cp -R labelme/examples/semantic_segmentation/data_dataset/* images/train ### やってること build-segmentation/labelme/examples/semantic_segmentation/data_dataset ↓ build-segmentation/images/train ## 作業4: deepLabv3用のデータ作成 rm -rf images/work/input/* rm -rf images/work/output/* cp -R images/train/SegmentationClassPNG/* images/work/input mkdir images/train/SegmentationClassPNGDeep /usr/bin/python3 /Users//gitdir/build-segmentation/scripts/dataAugument/dateAugumentation.py cp -R images/work/output/* images/train/SegmentationClassPNGDeep ### やってること grayイメージの作成
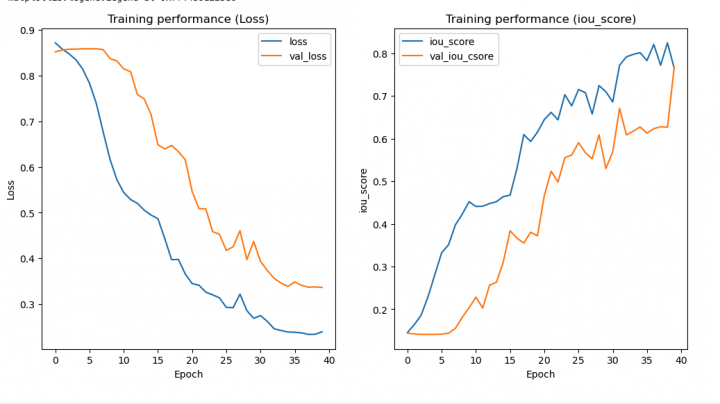
訓練ログ抜粋、これを訓練ごとに記載
## Try 17: - 前回と同様は→dataSize,epochs,encoder_weights,architecture,augumentationは - batch_size=1, - augumentation=True - 備考、考察 - 本筋はUnetのため、データサイズを拡張 - augumentationもオンにしている。 - 気になるのは過学習、実際は最後の学習より、最初の学習の81番目が最も良かった。 - 1s/step - loss: 0.2559 - iou_score: 0.8092 - val_loss: 0.2691 - val_iou_score: 0.6537 Epoch 81/100 - いずれにせよ検出制度が非常に落ちているので、batchサイズは2の方が良さそう - 一度、augumentationをしていない状態で試そうとも思っている
model定義
def convolution_block(
block_input,
num_filters=256,
kernel_size=3,
dilation_rate=1,
padding="same",
use_bias=False,
):
x = layers.Conv2D(
num_filters,
kernel_size=kernel_size,
dilation_rate=dilation_rate,
padding="same",
use_bias=use_bias,
kernel_initializer=keras.initializers.HeNormal(),
)(block_input)
x = layers.BatchNormalization()(x)
return tf.nn.relu(x)
def DilatedSpatialPyramidPooling(dspp_input):
dims = dspp_input.shape
x = layers.AveragePooling2D(pool_size=(dims[-3], dims[-2]))(dspp_input)
x = convolution_block(x, kernel_size=1, use_bias=True)
out_pool = layers.UpSampling2D(
size=(dims[-3] // x.shape[1], dims[-2] // x.shape[2]), interpolation="bilinear",
)(x)
out_1 = convolution_block(dspp_input, kernel_size=1, dilation_rate=1)
out_6 = convolution_block(dspp_input, kernel_size=3, dilation_rate=6)
out_12 = convolution_block(dspp_input, kernel_size=3, dilation_rate=12)
out_18 = convolution_block(dspp_input, kernel_size=3, dilation_rate=18)
x = layers.Concatenate(axis=-1)([out_pool, out_1, out_6, out_12, out_18])
output = convolution_block(x, kernel_size=1)
return output
def DeeplabV3Plus(y_image_size,x_image_size, num_classes):
model_input = keras.Input(shape=(y_image_size, x_image_size, 3))
resnet50 = keras.applications.ResNet50(
weights="imagenet", include_top=False, input_tensor=model_input
)
x = resnet50.get_layer("conv4_block6_2_relu").output
x = DilatedSpatialPyramidPooling(x)
input_a = layers.UpSampling2D(
size=(y_image_size // 4 // x.shape[1], x_image_size // 4 // x.shape[2]),
interpolation="bilinear",
)(x)
input_b = resnet50.get_layer("conv2_block3_2_relu").output
input_b = convolution_block(input_b, num_filters=48, kernel_size=1)
x = layers.Concatenate(axis=-1)([input_a, input_b])
x = convolution_block(x)
x = convolution_block(x)
x = layers.UpSampling2D(
size=(y_image_size // x.shape[1], x_image_size // x.shape[2]),
interpolation="bilinear",
)(x)
model_output = layers.Conv2D(num_classes, kernel_size=(1, 1), padding="same")(x)
return keras.Model(inputs=model_input, outputs=model_output)
model = DeeplabV3Plus(y_image_size=Y_IMAGE_SIZE,x_image_size=X_IMAGE_SIZE, num_classes=NUM_CLASSES)
dataAugumentation例
# map関数で呼び出すaugumentation用の関数 def augumentationMapfunc(image:tf.Tensor, mask:tf.Tensor) -> tf.Tensor: # imageもmaskも同様の変換をしてほしいのでseed値を生成し共有 randomSeed = np.random.randint(1,9) delta = 0.2 delta1 = 1 - delta # 明るい delta2 = 0 - delta # 暗い if 5 <= randomSeed <= 7: image = tf.image.adjust_brightness(image, delta1) if 7 <= randomSeed <= 9: image = tf.image.adjust_brightness(image, delta2) return image, mask def data_generator(image_list, mask_list): dataset = tf.data.Dataset.from_tensor_slices((image_list, mask_list)) # データ読み込み dataset = dataset.map(load_data, num_parallel_calls=tf.data.AUTOTUNE) # ランダムに水増しするが、水増ししても元データをある程度確保するためrepeatを実施 dataset = dataset.repeat(3) # 前処理(augumentation) dataset = dataset.map(tensorM.augumentationMapfunc, num_parallel_calls=tf.data.AUTOTUNE) # 指定したbatchサイズで分割したデータサイズを返却 e.g. 8要素の配列でBATCH_SIZEが2の場合4要素の格納された配列が返却される dataset = dataset.batch(BATCH_SIZE, drop_remainder=True) return dataset # 訓練データの取得 all_images = sorted(glob(os.path.join(trainingPath, trainDir))) train_images = all_images[:NUM_TRAIN_IMAGES] # 読み込み実行 train_dataset = data_generator(train_images, train_masks)
課題、考慮する必要がある項目
大枠として、
①検出上の課題、
②大規模解像度画像を検出対象とした際の課題
③実装工数の課題
に分別して記載
①検出上の課題:
・検出対象を覆う物体があると、検出が理論上難しいものとなる。
・希望する検出範囲外に同一の構造物が存在する場合、
同一の見た目である以上、検出してしまうため、
除外を希望する場合は独自のカスタムが必要となる。
・同一の見た目になるものは、その物体の周囲の視野やAIモデルの視野によって差異はあるが、検出が難しくなることがあるので、
その点を考慮に入れた上で検出対象の吟味が必要となるケースがある。
・撮影時刻や時期、天気によって、撮影写真に影が多いと、検出精度が一般に低下する。
それを解消する場合は、影を消すAIを別途用意するなど、対応を考慮する必要がある。
・影がない場合でも撮影時刻や天気によって、検出精度が影響を受ける。
※例えば、冬の昼に全体的に白んでいる写真と夏の夕方では、影の程度などが異なるので、同一の結果とは限らない。
・同一の物体でも、見た目によって判別ラベル種類を別にしたほうがいい、まとめたほうがいい観点がある。
それは数学的にフィルターが発火するかの観点から、分割をしすぎず、適度な範囲を判断することが必要
・検出物に応じて、リサイズのアルゴリズムを吟味したほうが良い
(今回は画像のエッジをぼかしたくなかったので、
Bilinearではなく、Nearest neighborのアルゴリズムを選択、使用した)
②大規模解像度画像を対象とした際の課題:
・大規模解像度画像の検出の場合、歪みの影響を受けることを考慮する必要がある。
※大規模解像度画像の特に端の画像に発生しやすい
・一般に大規模解像度画像のファイルサイズは巨大なため、
想定の大規模解像度画像の解像度と、訓練可能な画像サイズを両方想定に入れた上で、
画像の分割サイズや、検出サイズを固定し訓練する必要がある。
(メモリ容量の問題などで)
今回で言うと、オルソ画像の目標横幅は15000 〜 20000px
検出対象画像の横幅は1024pxを設定し、訓練を実施していた。
③実装工数の課題:
・訓練データを作成する手間が無視できないので、
その工数をあらかじめ充分に想定に入れる必要がある
(横20000pxの画像あたり2-3時間程度かかった)
・訓練データについては、ラベル分けが少し異なるだけで検出精度への影響が大きくなるケースがあるので慎重な確認作業が必要


