
記事の目的
クラウドAIサービス(AWS、GC)の物体検出サービスと自作AIについて、比較を行ない、調査結果を記載、図示。
結論
まずは結論の図から記載。
結論としてこの記事はこの図に対する説明となります。
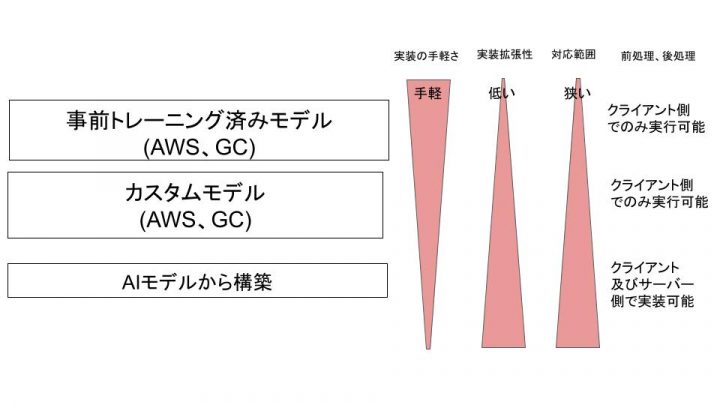
まずAWS、GCの物体検出サービスについて
前提としてクラウド上で物体検出を行うサービスとして
事前トレーニング済みモデル( API ) と カスタムモデル について述べると
事前トレーニング済みモデル( API )
事前トレーニング済みモデル( API )は
AWSではAmazon Rekognition
GCではVision API
などが主に該当し、これらは画像に対してAWS、GCが訓練済みのAIによる識別を行うものです。
例えば、バイクや寿司の画像に対して、bicycle、food、sushiなどの検出結果を返却してくれるものとなります。
Amazon Rekognition例
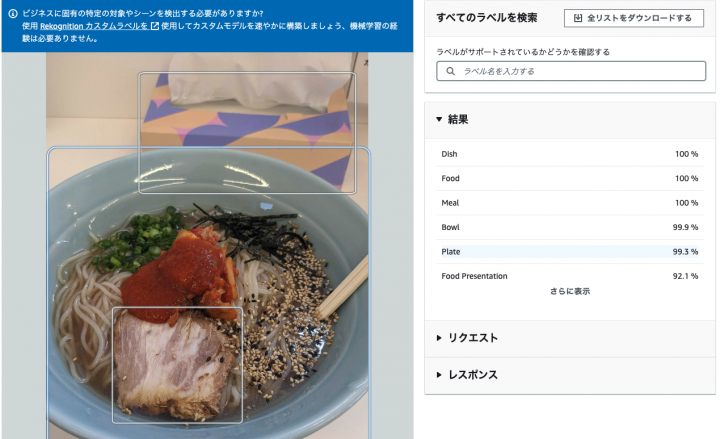
Vision API例
VisionAPIのデモ画面で物体検知で遊んだ。https://t.co/OloyapDvkr pic.twitter.com/I1IBP79VST
— Data science RoosterΦ (@DataRooster) October 21, 2021
カスタムモデル
次にカスタムモデルについては、
awsではAmazon Rekognition カスタムモデル
GCではAutoML Vision
が該当し、これらは前述した 事前トレーニング済みモデル と違い、独自の画像、ラベルを読み込ませ、独自の物体検出を可能とするサービスとなります。
また、訓練が可能、すなわち訓練が必要ということはデフォルトでAPI公開されていないということでもあるため、
これをAPI化する場合は、作成したmodelのデプロイが必要となります。
そこに取り回しやカスタムが効くか、デプロイなしで手軽に使用できるかのトレードオフが存在します。
Amazon Rekognition カスタムモデル例
Nice solution 👉 Detecting solar panel damage with Amazon Rekognition Custom Labels https://t.co/AeWIG4KJcF #AWS #MachineLearning pic.twitter.com/WZRjTMk5Tj
— Danilo Poccia (@danilop) February 22, 2023
AutoML Vision例
#yurufuwaml
AutoML Vision、ノーコードで行ける。ペットの判定ほぼ100%。 pic.twitter.com/fLDdISlJ9l— Google Homer (@google_homer_) January 23, 2020
AIモデルから構築
最後に、最も基礎的とも言えるKerasやtensorflow、pytorch等を用いてAIモデルから構築
という選択肢についてです。
以下にそれを実現するためのモデル定義のコード例を記載します、
(イメージを掴むためのものですので理解の必要はありません)
コード一例
def convolution_block(
block_input,
num_filters=256,
kernel_size=3,
dilation_rate=1,
padding="same",
use_bias=False,
):
x = layers.Conv2D(
num_filters,
kernel_size=kernel_size,
dilation_rate=dilation_rate,
padding="same",
use_bias=use_bias,
kernel_initializer=keras.initializers.HeNormal(),
)(block_input)
x = layers.BatchNormalization()(x)
return tf.nn.relu(x)
def DilatedSpatialPyramidPooling(dspp_input):
dims = dspp_input.shape
x = layers.AveragePooling2D(pool_size=(dims[-3], dims[-2]))(dspp_input)
x = convolution_block(x, kernel_size=1, use_bias=True)
out_pool = layers.UpSampling2D(
size=(dims[-3] // x.shape[1], dims[-2] // x.shape[2]), interpolation="bilinear",
)(x)
out_1 = convolution_block(dspp_input, kernel_size=1, dilation_rate=1)
out_6 = convolution_block(dspp_input, kernel_size=3, dilation_rate=6)
out_12 = convolution_block(dspp_input, kernel_size=3, dilation_rate=12)
out_18 = convolution_block(dspp_input, kernel_size=3, dilation_rate=18)
x = layers.Concatenate(axis=-1)([out_pool, out_1, out_6, out_12, out_18])
output = convolution_block(x, kernel_size=1)
return output
def DeeplabV3Plus(y_image_size,x_image_size, num_classes):
model_input = keras.Input(shape=(y_image_size, x_image_size, 3))
resnet50 = keras.applications.ResNet50(
weights="imagenet", include_top=False, input_tensor=model_input
)
x = resnet50.get_layer("conv4_block6_2_relu").output
x = DilatedSpatialPyramidPooling(x)
input_a = layers.UpSampling2D(
size=(y_image_size // 4 // x.shape[1], x_image_size // 4 // x.shape[2]),
interpolation="bilinear",
)(x)
input_b = resnet50.get_layer("conv2_block3_2_relu").output
input_b = convolution_block(input_b, num_filters=48, kernel_size=1)
x = layers.Concatenate(axis=-1)([input_a, input_b])
x = convolution_block(x)
x = convolution_block(x)
x = layers.UpSampling2D(
size=(y_image_size // x.shape[1], x_image_size // x.shape[2]),
interpolation="bilinear",
)(x)
model_output = layers.Conv2D(num_classes, kernel_size=(1, 1), padding="same")(x)
return keras.Model(inputs=model_input, outputs=model_output)
model = DeeplabV3Plus(y_image_size=Y_IMAGE_SIZE,x_image_size=X_IMAGE_SIZE, num_classes=NUM_CLASSES)
メリット
AIモデルから構築のメリットとしては以下となります
- 物体検出だけでなく、SemanticSegmentationという物体領域の検出など、より多岐にわたるコンピュータビジョンタスクを実行できる。
- ビジネスに応じて、AIアーキテクチャのカスタマイズが可能 Unet DeepLabv3などを検出条件に応じて選択でき、より深く精度向上が行えることがある
- 上記APIは当然ながら従量課金となるのですが、API公開をしない場合その金額は必要ない。
- それぞれのビジネスに応じた細かい要件について適応していくので、当然限られたラベルの識別精能は深くチューニングしていくことが可能
- APIに渡した後の画像の前処理を追加、変更することが可能:通常、物体検出を行う際に、データサイズや解像度の統一やトリミング、色調整などを行なって識別した方が検出精度が高くなることがあります。こういった前処理もクライアント側ではなくサーバー側で対応することができます。
- より詳細を見てみたい方は、関連記事を添付しますので参考いただけると幸いです。
関連記事:https://iret.media/71817
デメリット
- API化する場合は別途APIサーバーの構築と運用が必要
- 運用に伴う使用ライブラリのアップデートの必要
- トレーニング、ラベル付け対応の必要
- 実装の際は機械学習エンジニアが必要となりやすい:最低限のバックボーンとなる機械学習の専門知識と、サーバー運用を行えるエンジニア知識を持った開発者が必要となります。
説明が長くなりましたが上記より
通常AIによる物体検出を行う場合は、
「事前トレーニング済みモデルサービス」と「カスタムモデルサービス」と、「AIモデルから構築」
という3つの選択肢からビジネス要件に応じて選択、及びプログラムから利用する必要があります。
注:説明を簡略化するため、ここでの「AIモデルから構築」の定義は、ライブラリから定義済みAIモデルを読み込み訓練、使用することも含む形とさせていただきます。
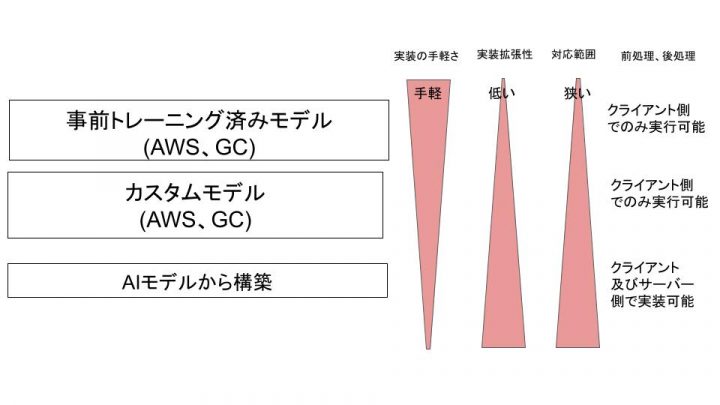
SageMakerやVision APIが最も手軽ですが、ある程度のカスタマイズや精度を上げたい場合はSageMakerカスタムモデルの使用や、AIモデルからの作成の必要が出てきます。
特にsemantic segmentationなどのタスクを実行したい場合は、
自分が調べた限り、訓練デプロイなしでAWSやGCの準備されたAIサービス一本での対応は現時点では難しく、
少なくともクラウド、ローカル上でAIモデルをライブラリから読み取ったり、新しくモデルを定義し訓練、デプロイを行う必要があります。
(ただし、SageMakerやVertixAIなど、クラウド上の総合的なAI開発サービスを用いることで、GPUリソースを適切に活用したり、訓練効率を向上させることも可能となります!)
semantic segmentation例:
Testing out "Semantic Segmentation" ControlNet from Blender. #b3d #stablediffusion pic.twitter.com/wGeVm55hej
— BLENDER SUSHI 🫶 X – 24/7 Blenderian (@jimmygunawanapp) March 3, 2023
転移学習に関して
上記で使用した訓練データ数は、
一般公開されているimagenetで学習済みのモデルをdeepLabv3用のモデルへと取り込み、
転移学習にて、出力層近辺のパラメータのみチューニングを行ったことで、
通常必要となる画像の特徴のトレーニングを低減させることで、
画像の訓練数自体は100枚程度でこの精度を実現しています。
これによって、自作モデルのデメリットの一つである、訓練データの確保の手間の問題、及び訓練時間を軽減しています。
転移学習について
https://udemy.benesse.co.jp/data-science/deep-learning/transfer-learning.html
終わりに
アイレットでは上記3種のAI活用方法を組み込んだサービス開発を承っています。
例えば、上記のAIモデルアーキテクチャからカスタマイズした例でいうと
建造物を上空から撮影し識別する実装をDeepLabv3のモデルをkerasを用いて作成、
imagenetのパラメータを用いて転移学習し、
semantic segmentatioタスクの実装を行うなどしています。
上記AIを用いた物体検出モデルの作成や、適合、それに伴う画像処理など、
幅広くAIを活用した案件のご相談を承っておりますので、興味が湧いた方のご連絡をお待ちしています。
https://www.iret.co.jp/contact/service/form/
補足
上記に述べたコンピュータビジョンサービスは、説明のためすべてを取り扱っている訳ではないのでご了承いただけると幸いです




