pytorchとSageMakerのビルトインパターンでの機械学習モデルデプロイ比較
今回はSageMakerを使用する前提で、
その中の手法のうち2種類の手法の比較を行いたいと思います。
記事の目的
同じくSageMakerを使う上で、
アーキテクチャをある程度自ら作成するpytorchパターンとSageMakerのビルトインパターンの2種類での比較
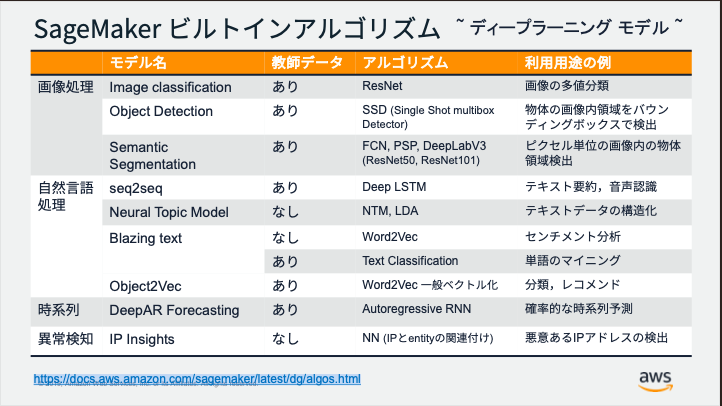
画像出典元:https://pages.awscloud.com/rs/112-TZM-766/images/AWSの機械学習サービスとAmazon SageMaker の基礎.pdf
対象者
機械学習モデルをある程度理解していて、クラウドリソースを用いてモデルの訓練、デプロイを単純化したり、運用を楽にしたいと考える人
この記事を読み終わるまでの時間
およそ5m
関連、参考元記事
以下に詳細記事2つを貼ります。この記事では比較に絞って記載していますので
この記事を読んで概要をつかんだ後に直下のリンク先でより詳細な情報を掴みにいくと望ましいと思います。
以下部分箇所の比較
1:モデル生成箇所比較
pytorchパターン
クラス定義
<br /># Based on https://github.com/pytorch/examples/blob/master/mnist/main.py class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x, dim=1)
引数のminst.pyのmain関数で、このクラスを用いたtrain処理を呼び出すことで、estimatorとして生成している
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point='mnist.py',
role=role,
framework_version='1.1.0',
train_instance_count=2,
train_instance_type='ml.c4.xlarge',
hyperparameters={
'epochs': 6,
'backend': 'gloo'
})
ビルトインパターン
ビルトインアルゴリズムを使うための、コンテナイメージの取得
training_image = sagemaker.image_uris.retrieve("semantic-segmentation", sess.boto_region_name)
print(training_image)
コンテナイメージをEstimatorへ渡して生成
ss_estimator = sagemaker.estimator.Estimator( training_image, # Container image URI role, # Training job execution role with permissions to access our S3 bucket instance_count=1, instance_type="ml.p3.2xlarge", volume_size=50, # in GB max_run=360000, # in seconds output_path=s3_output_location, base_job_name="ss-notebook-demo", sagemaker_session=sess, )
ハイパーパラメータの設定
# Setup hyperparameters ss_estimator.set_hyperparameters( backbone="resnet-50", # This is the encoder. Other option is resnet-101 algorithm="fcn", # This is the decoder. Other options are 'psp' and 'deeplab' use_pretrained_model="True", # Use the pre-trained model. crop_size=240, # Size of image random crop. num_classes=21, # Pascal has 21 classes. This is a mandatory parameter. epochs=10, # Number of epochs to run. learning_rate=0.0001, optimizer="rmsprop", # Other options include 'adam', 'rmsprop', 'nag', 'adagrad'. lr_scheduler="poly", # Other options include 'cosine' and 'step'. mini_batch_size=16, # Setup some mini batch size. validation_mini_batch_size=16, early_stopping=True, # Turn on early stopping. If OFF, other early stopping parameters are ignored. early_stopping_patience=2, # Tolerate these many epochs if the mIoU doens't increase. early_stopping_min_epochs=10, # No matter what, run these many number of epochs. num_training_samples=num_training_samples, # This is a mandatory parameter, 1464 in this case. )

画像出典元:https://pages.awscloud.com/rs/112-TZM-766/images/AWSの機械学習サービスとAmazon SageMaker の基礎.pdf
2:訓練データ情報の引渡し方の違い
pytorchパターン
s3へデータアップロード
inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix=prefix)
print('input spec (in this case, just an S3 path): {}'.format(inputs))
fit時にパス情報を引渡し
estimator.fit({'training': inputs})
ビルトインパターン
s3へのアップロード
%%time train_channel = sess.upload_data(path="data/train", bucket=bucket, key_prefix=prefix + "/train") print(train_channel) train_annotation_channel = sess.upload_data( path="data/train_annotation", bucket=bucket, key_prefix=prefix + "/train_annotation", ) print(train_annotation_channel) validation_channel = sess.upload_data( path="data/validation", bucket=bucket, key_prefix=prefix + "/validation" ) print(validation_channel) validation_annotation_channel = sess.upload_data( path="data/validation_annotation", bucket=bucket, key_prefix=prefix + "/validation_annotation", ) print(validation_annotation_channel)
データチャンネルにパス情報を設定
余談:合わせてラベルマップによってラベルのカスタマイズ可能
distribution = "FullyReplicated"
data_channels = {
"train": sagemaker.inputs.TrainingInput(train_channel, distribution=distribution),
"validation": sagemaker.inputs.TrainingInput(validation_channel, distribution=distribution),
"train_annotation": sagemaker.inputs.TrainingInput(
train_annotation_channel, distribution=distribution
),
"validation_annotation": sagemaker.inputs.TrainingInput(
validation_annotation_channel, distribution=distribution
),
# 'label_map': label_map_channel
}
fit時にデータチャンネルを渡す
ss_estimator.fit(data_channels, logs=True)
3:デプロイは同一処理
pytorchパターン
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
ビルトインパターン
ss_predictor = ss_estimator.deploy(initial_instance_count=1, instance_type="ml.c5.xlarge")
4:検証:Inference
pytorchパターン
検証
import numpy as np image = np.array([data], dtype=np.float32) response = predictor.predict(image) prediction = response.argmax(axis=1)[0] print(prediction)
ビルトインパターン
検証
%%time cls_mask = ss_predictor.predict(imbytes) print(type(cls_mask)) print(cls_mask.shape) plt.imshow(cls_mask, cmap="jet") plt.show()
※以降は比較というトピックからは少し話が逸れるので読み飛ばしても構わないが、
モデルの種類の関係上シリアライザーとデシリアライザーを加工するロジックを上記のpredictの前に実行することが望ましい
デシリアライザーの設定
from PIL import Image import numpy as np class ImageDeserializer(sagemaker.deserializers.BaseDeserializer): """Deserialize a PIL-compatible stream of Image bytes into a numpy pixel array""" def __init__(self, accept="image/png"): self.accept = accept @property def ACCEPT(self): return (self.accept,) def deserialize(self, stream, content_type): """Read a stream of bytes returned from an inference endpoint. Args: stream (botocore.response.StreamingBody): A stream of bytes. content_type (str): The MIME type of the data. Returns: mask: The numpy array of class labels per pixel """ try: return np.array(Image.open(stream)) finally: stream.close() ss_predictor.deserializer = ImageDeserializer(accept="image/png")
シリアライザーの設定
ss_predictor.serializer = sagemaker.serializers.IdentitySerializer("image/jpeg")
with open(filename, "rb") as imfile:
imbytes = imfile.read()
# Extension exercise: Could you write a custom serializer which takes a filename as input instead?
5:エンドポイントの削除
pytorchパターン、ビルトインパターン共通
estimator.delete_endpoint()
まとめ
ここまでで、各機能の比較は終わりです
どちらの手法でもSageMakerによって、機械学習プロジェクトで起こりがちな
下記問題にアプローチできていることがわかります。
- 環境構築が大変
- 複数の学習ジョブを並列で実行するのが大変
- 複数マシンを使った分散学習を実現するのが大変
- 推論用の API サーバ構築とメンテが大変

画像出典元:https://pages.awscloud.com/rs/112-TZM-766/images/AWSの機械学習サービスとAmazon SageMaker の基礎.pdf
その上でpytorchやtensorflowなど、フレームワークのアップデート状況を加味しつつ、適切な選択を行うことが望ましいと思います。
Appendix:
少し詳細情報になるので、本題が終わったところで情報追加となります。
pytorchバージョンで実装を行う場合、軽く上記した通りメインのコードの加工を少々行う必要があります。
修正する上でのポイントは以下となります。
- main関数の中で–batch-sizeなどのハイパーパラメータを受け取れるように記載する
- main関数で同ファイル内のtrain関数を呼び出す
- SageMakerのEstimatorに対応するために、以下の関数をファイル内に定義しておく必要がある
- model_fn(モデルの読み込み)
- input_fn(前処理)
- predict_fn(予測)
- output_fn(後処理)
※推論時は2→3→4の順で処理が実行される
以下引用コード:
import argparse
import json
import logging
import os
import sagemaker_containers
import sys
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
from torchvision import datasets, transforms
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))
# Based on https://github.com/pytorch/examples/blob/master/mnist/main.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def _get_train_data_loader(batch_size, training_dir, is_distributed, **kwargs):
logger.info("Get train data loader")
dataset = datasets.MNIST(training_dir, train=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset) if is_distributed else None
return torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=train_sampler is None,
sampler=train_sampler, **kwargs)
def _get_test_data_loader(test_batch_size, training_dir, **kwargs):
logger.info("Get test data loader")
return torch.utils.data.DataLoader(
datasets.MNIST(training_dir, train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=test_batch_size, shuffle=True, **kwargs)
def _average_gradients(model):
# Gradient averaging.
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)
param.grad.data /= size
def train(args):
is_distributed = len(args.hosts) > 1 and args.backend is not None
logger.debug("Distributed training - {}".format(is_distributed))
use_cuda = args.num_gpus > 0
logger.debug("Number of gpus available - {}".format(args.num_gpus))
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
device = torch.device("cuda" if use_cuda else "cpu")
if is_distributed:
# Initialize the distributed environment.
world_size = len(args.hosts)
os.environ['WORLD_SIZE'] = str(world_size)
host_rank = args.hosts.index(args.current_host)
os.environ['RANK'] = str(host_rank)
dist.init_process_group(backend=args.backend, rank=host_rank, world_size=world_size)
logger.info('Initialized the distributed environment: \'{}\' backend on {} nodes. '.format(
args.backend, dist.get_world_size()) + 'Current host rank is {}. Number of gpus: {}'.format(
dist.get_rank(), args.num_gpus))
# set the seed for generating random numbers
torch.manual_seed(args.seed)
if use_cuda:
torch.cuda.manual_seed(args.seed)
train_loader = _get_train_data_loader(args.batch_size, args.data_dir, is_distributed, **kwargs)
test_loader = _get_test_data_loader(args.test_batch_size, args.data_dir, **kwargs)
logger.debug("Processes {}/{} ({:.0f}%) of train data".format(
len(train_loader.sampler), len(train_loader.dataset),
100. * len(train_loader.sampler) / len(train_loader.dataset)
))
logger.debug("Processes {}/{} ({:.0f}%) of test data".format(
len(test_loader.sampler), len(test_loader.dataset),
100. * len(test_loader.sampler) / len(test_loader.dataset)
))
model = Net().to(device)
if is_distributed and use_cuda:
# multi-machine multi-gpu case
model = torch.nn.parallel.DistributedDataParallel(model)
else:
# single-machine multi-gpu case or single-machine or multi-machine cpu case
model = torch.nn.DataParallel(model)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
model.train()
for batch_idx, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
if is_distributed and not use_cuda:
# average gradients manually for multi-machine cpu case only
_average_gradients(model)
optimizer.step()
if batch_idx % args.log_interval == 0:
logger.info('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.sampler),
100. * batch_idx / len(train_loader), loss.item()))
test(model, test_loader, device)
save_model(model, args.model_dir)
def test(model, test_loader, device):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
logger.info('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def model_fn(model_dir):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.nn.DataParallel(Net())
with open(os.path.join(model_dir, 'model.pth'), 'rb') as f:
model.load_state_dict(torch.load(f))
return model.to(device)
def save_model(model, model_dir):
logger.info("Saving the model.")
path = os.path.join(model_dir, 'model.pth')
# recommended way from http://pytorch.org/docs/master/notes/serialization.html
torch.save(model.cpu().state_dict(), path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Data and model checkpoints directories
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--backend', type=str, default=None,
help='backend for distributed training (tcp, gloo on cpu and gloo, nccl on gpu)')
# Container environment
parser.add_argument('--hosts', type=list, default=json.loads(os.environ['SM_HOSTS']))
parser.add_argument('--current-host', type=str, default=os.environ['SM_CURRENT_HOST'])
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
parser.add_argument('--data-dir', type=str, default=os.environ['SM_CHANNEL_TRAINING'])
parser.add_argument('--num-gpus', type=int, default=os.environ['SM_NUM_GPUS'])
train(parser.parse_args())
他関連資料:SageMakerの基礎資料
https://pages.awscloud.com/rs/112-TZM-766/images/Amazon SageMaker の基礎.pdf
共通点概要
- S3に訓練データを格納し、並列トレーニングを実施している点
- SageMakerによって、訓練、デプロイを行える点


