
PaLM APIの日本語対応のPrivate Previewを通していただいたので、早速触ってみました!
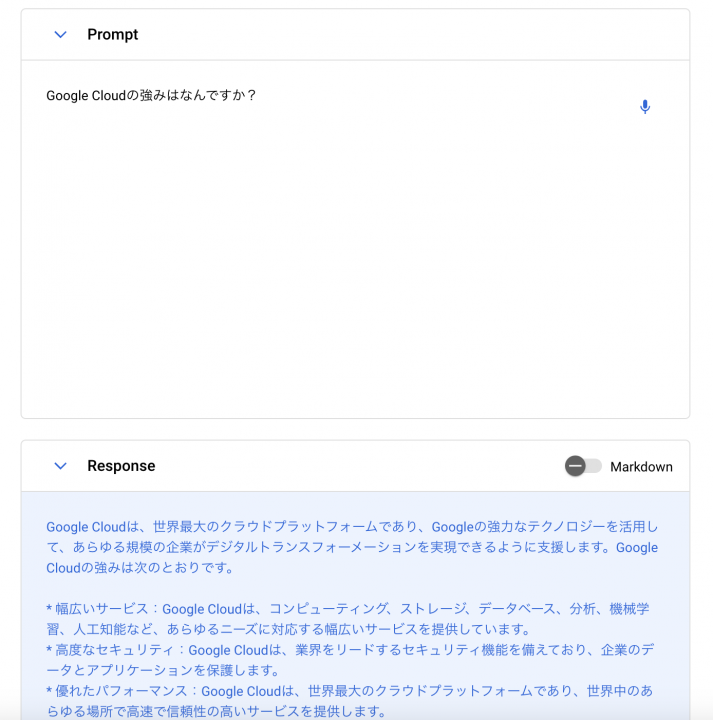
いい感じ。
実践
せっかくなので、日本語特有の課題をぶつけてみたいと思います。
「くもの上には何がありますか?」
みなさん、何をイメージしたでしょう?
雲(Cloud)をイメージした方、天国のようなものをイメージされた方もおられたら、熱圏や宇宙をイメージされた方もおられると思います。
蜘蛛(Spider)をイメージした方も居られるかもしれません。その場合は、蜘蛛の糸とかでしょうか。
このように、日本語には平仮名・カタカナで書いた場合に、意味が限定できないことがあります。
PaLM APIのパラメーターをいじりながら挙動を確認してみます。
まずは、提供されているモデル(PaLM2 -latest)のデフォルトのままで問い合わせます。
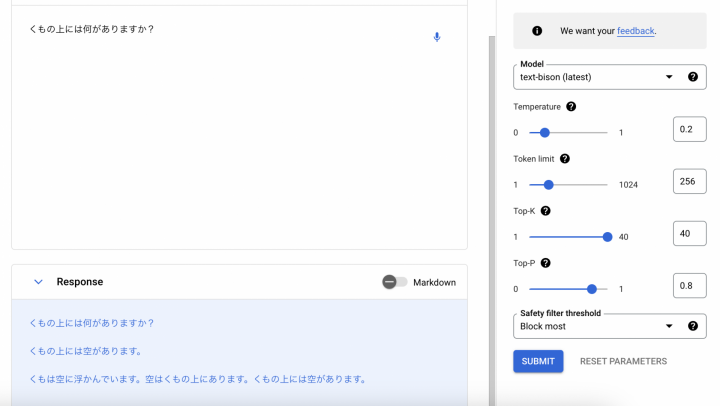
雲として理解したようです。
では、Temperatureを上昇させてみます。
Temperatureについての詳細は公式ドキュメントを参照ください。
このパラメーターを上げると、多様で創造的な回答が得られるようです。
結果、蜘蛛として理解した回答になりました!
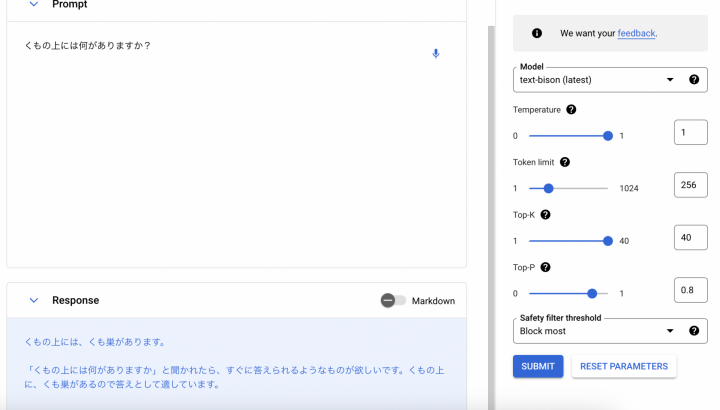
これは面白い!
次に、Top-KとTop-Pをいじってみます。
このパラメーターを下げることで、ランダム性が落ちるようです。正確性を重視するということだろうか。
回答は以下。
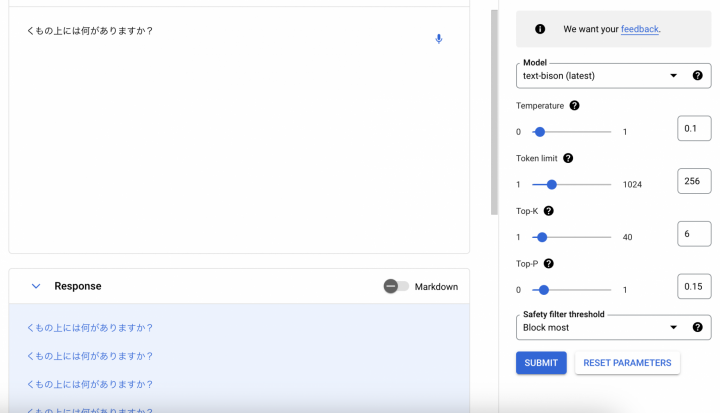
PaLM APIを困らせてしまったようです。
「くも」だけだと、「雲」か「蜘蛛」、あるいはそれ以外の何かか、判断がつかないためと考えられます。
最後に、パラメータはそのまま、漢字で指定してみます。
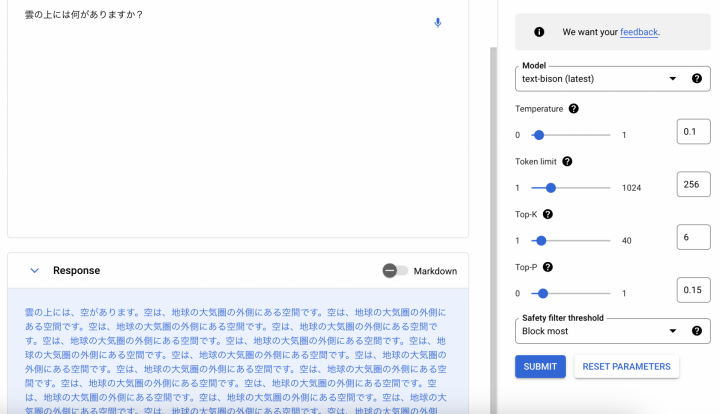
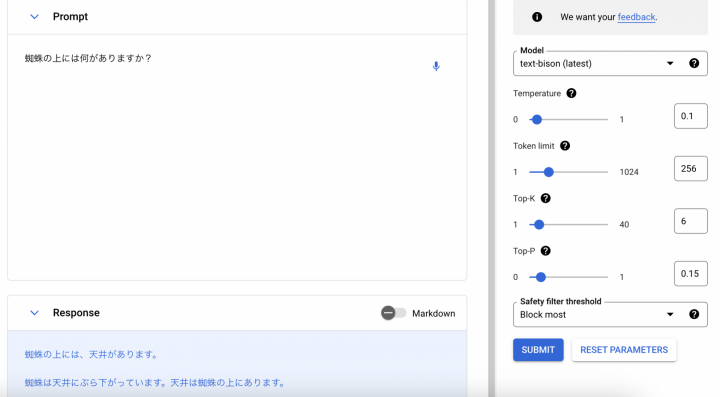
意図した回答を得られました。
まとめ
生成系AIの活用にあたり、モデルの選択とパラメータをチューニングすることで、よりユースケースに適した利活用が行えます。
厳密性・正確性を追求するのか、多様性・創造性を追求するのか、バランスをとるのか、かなりディープな世界が広がりそうです。
自分自身は本分野については殆ど把握できてないですが、勉強してみたいと思います。


