
12月14日に大阪のコングレコンベンションセンターで開催された「Generative AI Summit Osaka」に参加してきました!
セッションの内容など他の方の参考になればいいな。との思いで書かせて頂きます!
【セッション】Google Cloudで実現する生成AIデータエンジニアリングの第一歩

データエンジニアの主な役割:
「データを分析できる形にして届ける」
「データを誰でも安心・安全に扱えるようにする」


生成AIがあることによりデータエンジニアリングの変化
・非構造化データを活用
・基盤モデルを用いたAI/MLの活用
・AIアシスタントで生産性の向上、データを多くの人が扱いやすくなる(民主化)
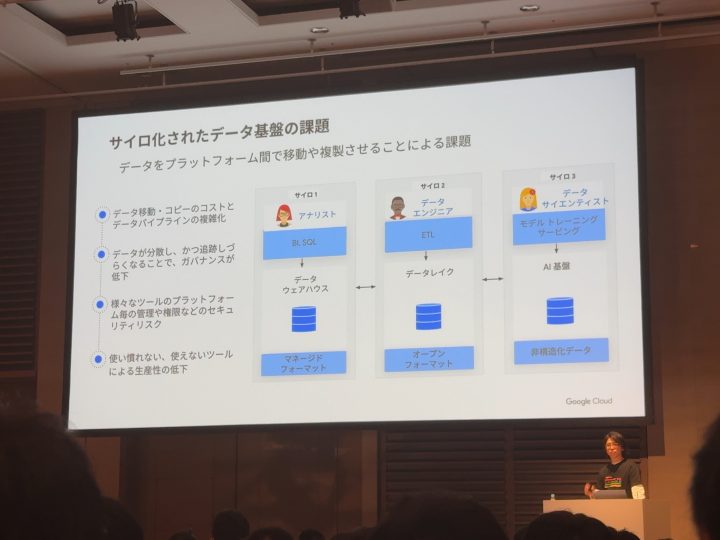
今のデータ基盤での課題例
・「用途」「種別」「使う人」によってばらばらに存在している
・データが行ったり来たりすることにより重複したりし複雑化する
・権限管理が大変
Google CloudのAIを使うとどのように解決されるか?

ここで重要になるのが「BigQuery」
「BigQuery」はGoogle Cloudが提供する「サーバーレスアーキテクチャ」で数テラバイトから数ペタバイトまでの大規模データに高速に解析することができます。
*僕調べになります。
その「BigQuery」がどんどん進化しているらしいです!
【進化例】
・「SQL」以外の処理も可能になった
・どのストレージ・フォーマット(画像や音声も)からでもデータを扱える
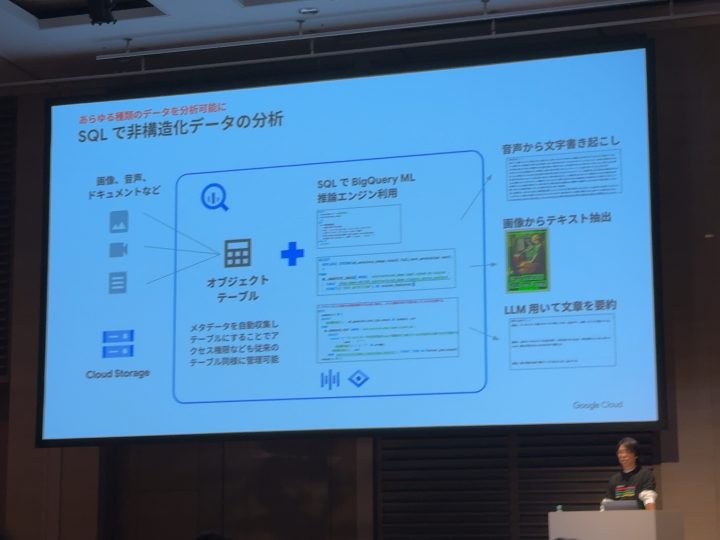
・非構造化データを分析できる(上画像)
「画像」「音声」などを「オブジェクトテーブル」を使ってSQLから参照できる + これに対し何かの処理ができる
(例)音声をテキストにする
(例)画像からテキストを取り出す
これらは事前学習させる必要なくモデルを使用してそれらの機能を使用できます。
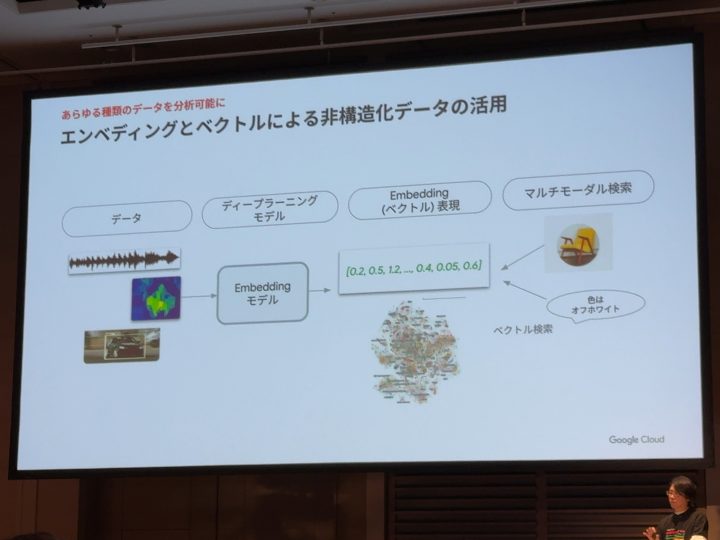

「BigQuery」の中で非構造化データをエンべディング(ベクトル化)することもでき、
また、作成したエンべディング(ベクトル化)を検索できる。
ベクトル間の距離を計算し、距離が近いもの(類似)を参照したり、そのエンべディングに新たな文字列を与えどれが距離が近いのか?など「BigQuery」の中で計算させることができる。
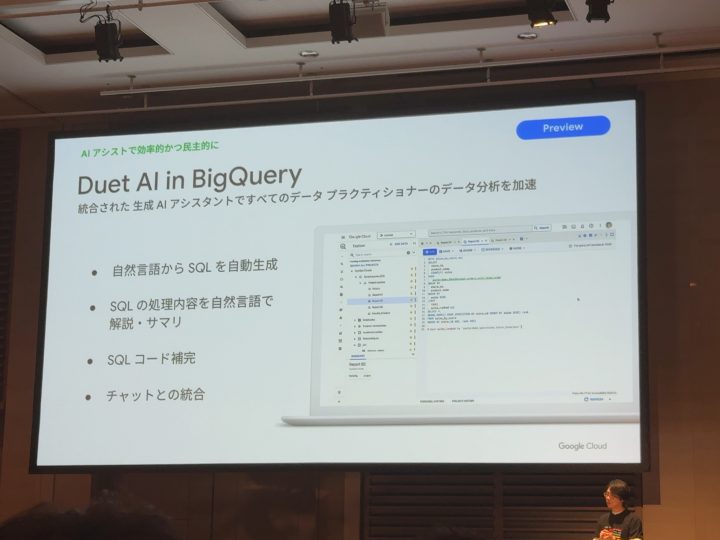
AIアシストの力を使うと「クエリが書けない人」でもDuet AIを使うと「自然言語で使用」で「BigQuery」の中でも分析することができるらしい!スゴイシアリガタイ
デモ

デモでは、映画のレビューのテキストを「BigQuery」上で「BigQuery」内の非構造化データを構造化データにしていくことを見せて頂きました!
【内容】
大量の映画レビューを「BigQuery」上で
・「要約」
・レビューが「ポジティブ」か「ネガティブ」かを分ける
・キーワードを抜き出し
・「JSON」のフォーマットにする。
の指示し「BigQuery」内の非構造化データを構造化データにしていきます。
【結果】
・元々のレビュー内容
・レビューの要約
・そのレビューのキーワード
・そのレビューが「ポジティブ」か「ネガティブ」か
・「JSON」で帰ってきた内容
指示通りのものがすべて返ってきていました!
*デモに没入していて写真撮り忘れました…
さいごに
セッションを聞くことにより「データエンジニアリング」とはなんたるか?
「今のデータ基盤での課題」や「その課題をGoogle CloudのAIを使うとどのように解決できるか」などデモを踏まえて説明して頂く事により「データの扱い」に慣れていない僕も触ってみたいと思うほど興味が湧くセッションでした!
最後まで見て頂きありがとうございました!




