
概要
セッション詳細: Unleash the power of vector search and multimodal embeddings in BigQuery
スピーカー:
Jeff Nelson 氏 (Google Cloud Developer Advocate)
Márton Kodok 氏 (REEA.net Senior Software Architect)



セッション内容
このセッションではBigQueryをベクトルストアとする、RAG(検索拡張生成)アプリケーションの開発方法の解説が行われました。
大きな流れとしては、以下の通りです。
- ベクトル埋め込みとは何かという概要の解説
- マルチモーダルベクトル埋め込みに移りテキストだけではなく、画像の埋め込みを使用してBigQueryで関連情報を検索する方法についての解説
- RAGアプリケーションでよく見かける、共通のアーキテクチャパターンについての解説
- 2つのライブデモの紹介
- 1つ目はMárton氏がテキストと画像を使用した、マルチモーダル検索の力を示すアプリケーション
- 2つ目はJeff氏がBigQueryを使用したLangChainのデモを行い、検索による回答の拡張についての解説
ベクトルエンベディングとは
ベクトル検索を解説する前に、私達が日常的に使用するアプリケーションは通常、キーワード検索が用いられます。つまり、キーワードを入力すると、データベースから一致する情報が取得され、データが返されます。これは基本的な仕組みで、多くのアプリケーションで非常によく機能します。
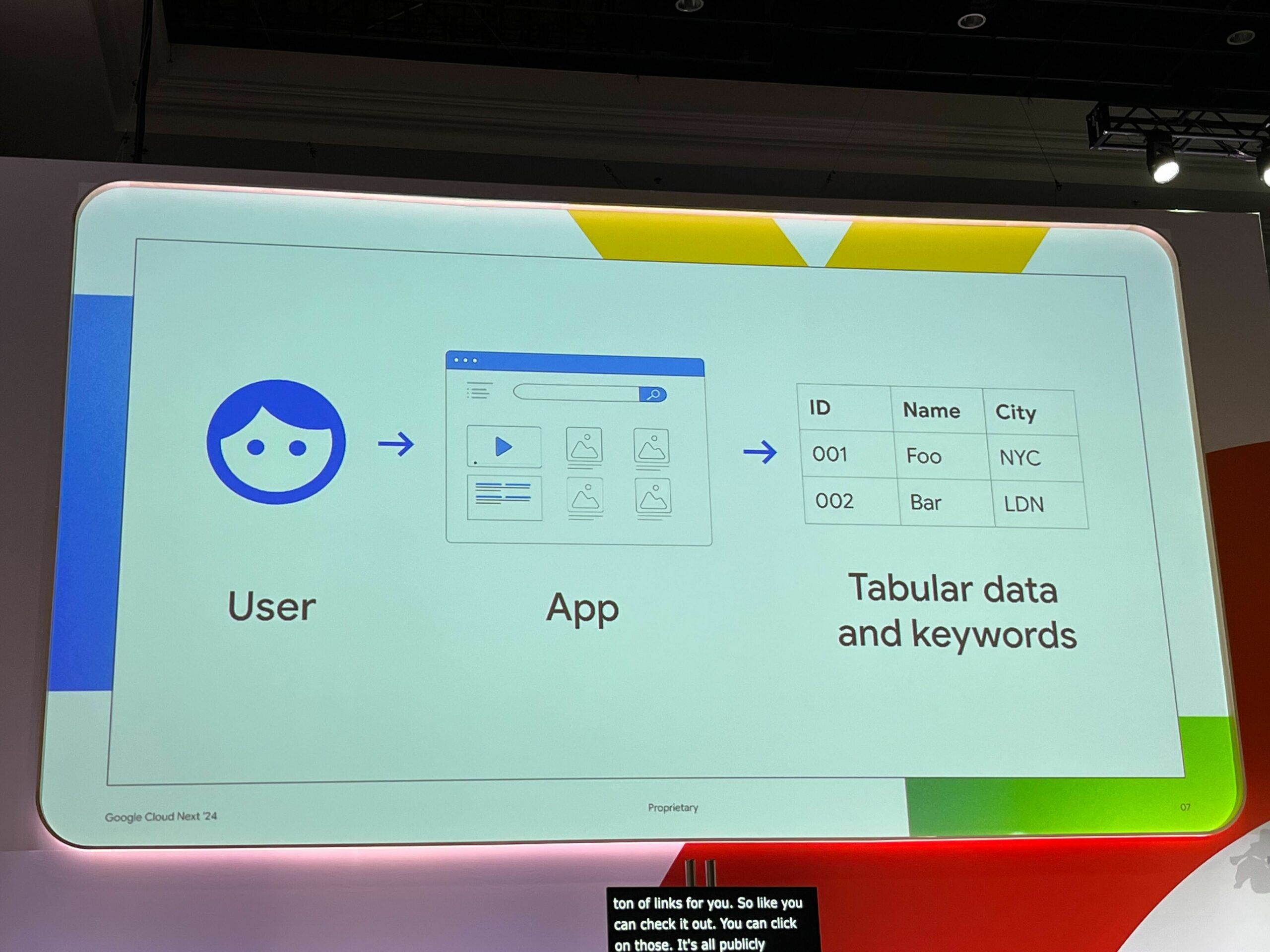
しかし、現在入手できる膨大な量のさまざまな種類のデータ、つまりテキスト、画像、ビデオ、音声などを考えると、従来のデータベースは限界に達し始めています。例えば、キーワードとしては完全に一致しないが、同じニュアンスのものを検索したい場合はどうでしょうか。シノニム(同意語)はどうでしょうか。
この問題をベクトルエンべディング(ベクトル埋め込み)とベクトル検索が解決します。

例として、「bug」という言葉を検索したいとします。
「今日庭でbug(虫)を発見しました」の場合は昆虫を明らかに昆虫を表し、「コードの中にbug(バグ)を見つけた」の場合は不具合を表しています。
文脈が「bug」という言葉の意味を完全に変えてしまいます。 これがベクトル埋め込みが役立つところです。
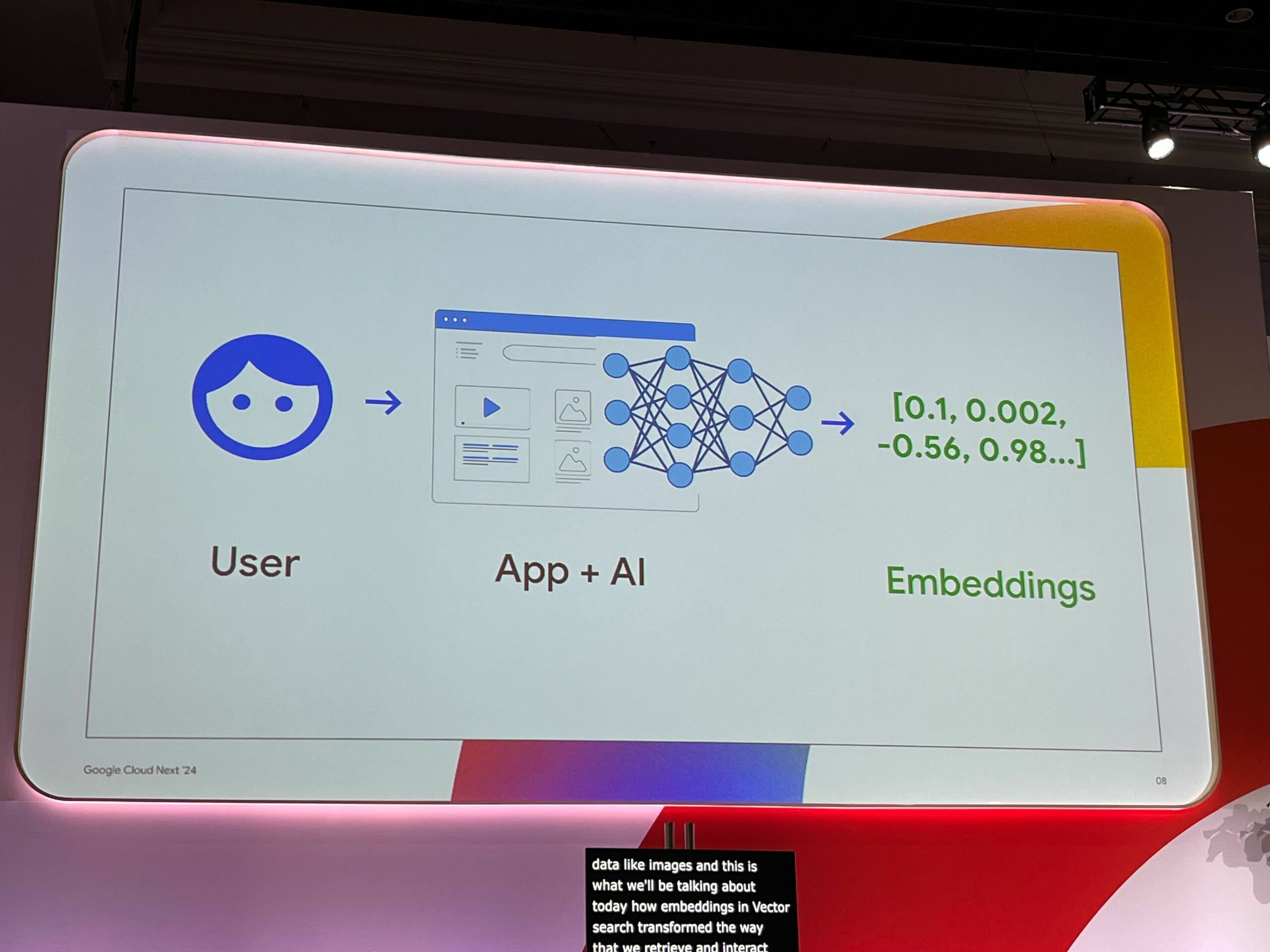
自由形式テキストのような複雑なデータを理解するには、それを表現するための標準的な方法が必要となります。 機械学習モデルは、非構造化入力を数値ベクトル(多次元の数値配列)に変換することができます。つまり、テキストや画像を入力として受け取り、ベクトルエンべディングを行うモデルに通すと、数値の配列であるエンべディングが得られます。
これらのベクトルエンべディングは、データの背後にある意味を捉え、正確なキーワードではなく意味的関係に基づいて比較や検索を行うことを可能にします。

マルチモーダルなベクトルエンべディング
通常、エンべディングの入力はテキストが一般的ですが、他にも画像や動画、音声なども入力ソースにできます。
これにより「木」というテキストと、木の画像から生成されるベクトル値は同じ、もしくは類似値となり同じ意味を表します。

また、今回のリリースでBigQueryでもSQL関数だけでマルチモーダルなベクトルエンべディングを行ったり、SQL関数だけでベクトル検索を可能になりました。(まだ動画や音声は未対応)

マルチモーダルなベクトルエンべディングによりテキストだけで画像を見つけたり、特定の顧客サポートチケットに似たチケットを見つけたりするなど、新たな可能性が生まれます。 検索された顧客サポートチケットと、多少表現が違っていても似たようなチケットを見つけることもできるとのことです。

以下は猫の画像をエンべディングしたベクトルグラフの例です。青い点で表現されていることが確認できます。

続けて「クリスマスツリーの前に横たわる灰色の縞模様の猫」のテキストをエンべディングしたベクトルグラフ。緑の点で表現され、多次元領域において、画像の点と非常に近い位置を占めていることが確認できます。

RAGアプリケーションの一般的なアーキテクチャ

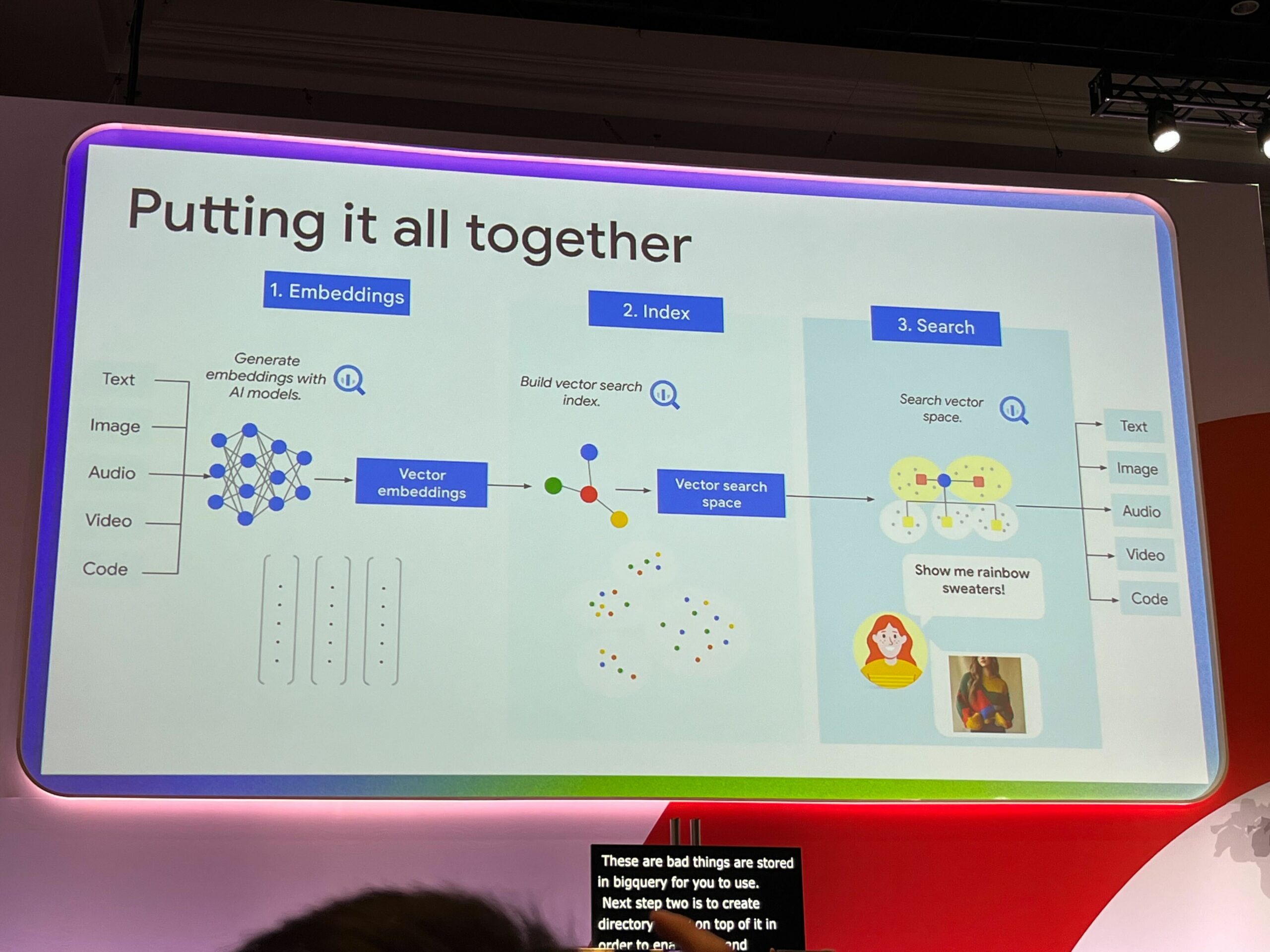
上の図は一般的なRAGアプリケーションのアーキテクチャです。
- Embeddingsで、エンべディングを行うモデルへソースデータのインプットを行い、ベクトル値を生成します。
続いて2. Indexで、生成したベクトル値をベクトルストアへ格納し、インデックスを作成します。
最後に3. SearchでRAGアプリケーションがユーザーの検索ワードをベクトル化し、ベクトルストアに対して検索を行い、同様の意味を持つデータを検索し最も一致するものをレスポンスします。
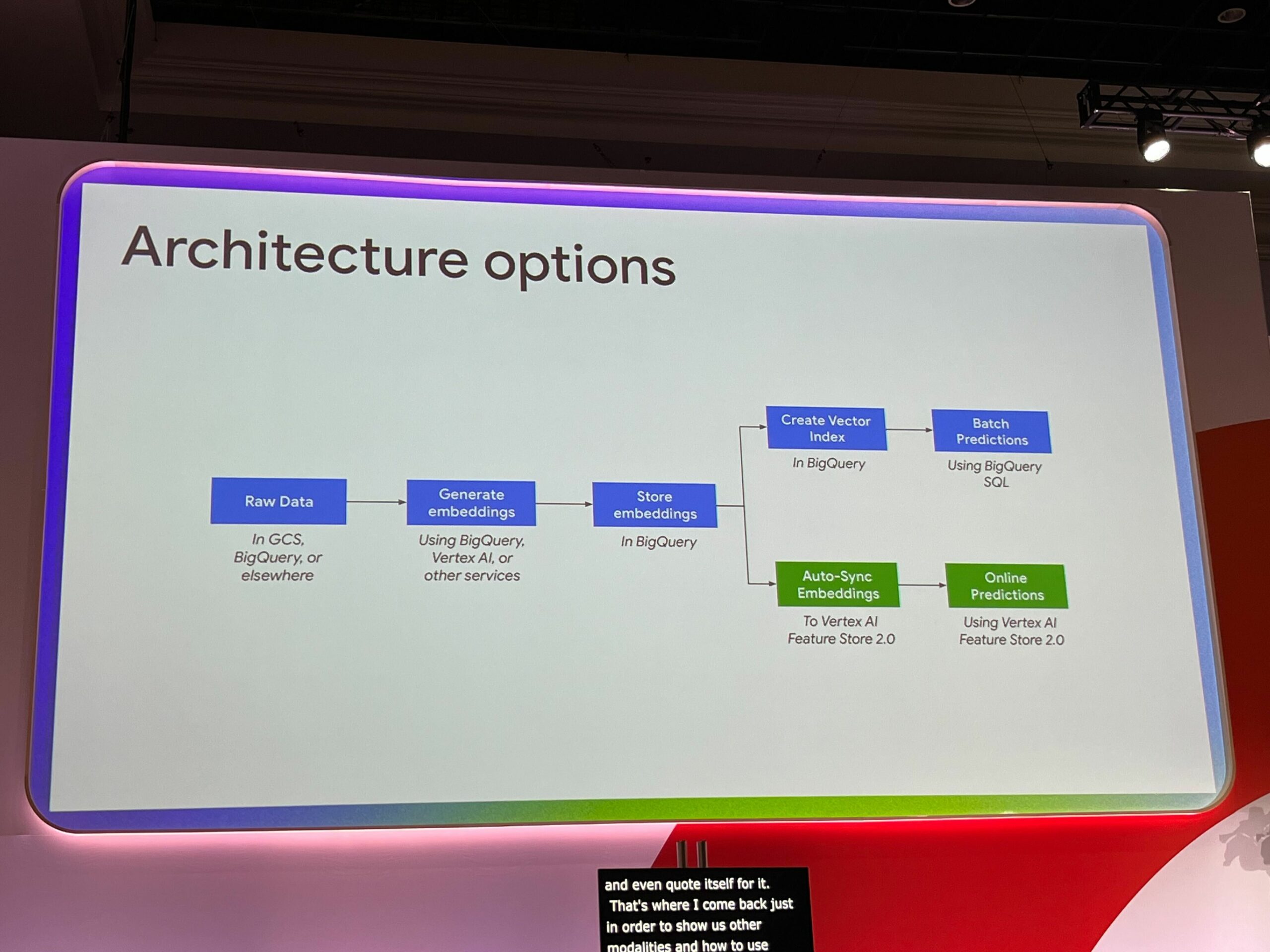
またベクトル値を生成してベクトルストアに格納とインデックス作成する際に、バッチ処理的に行うか、リアルタイムに行うかを選択する必要があります。バッチとリアルタイムはトレードオフの関係にあり、それぞれ以下のメリット/デメリットがあります。
バッチ処理
- 一度に大量のデータを取り込んで、BigQueryのスケールでこれらの検索を実行できる。
- インデックスを管理したり、インフラストラクチャを管理したりする必要はない。
- 結果が数秒後に返ってくる可能性がある
リアルタイム
- Vertex AI Feature Storeを使用する。この場合、BigQueryに格納されている埋め込みは自動的にFeature Storeに同期され、その後オンライン予測を実行できる。
- 結果がミリ秒単位で返されるが、一方で少し多くのインフラストラクチャを管理する必要があり、コストも少し高くなる。
検索の拡張

エンべディングとベクトル検索は、さまざまなユースケースに対応できます。 たとえば、レコメンドシステム、類似性に基づいた分類、さらにはウェブサイトのクリックストリームデータのようなものにも埋め込みを使用できるとのことです。
重要なのは、エンべディングとベクトル検索は柔軟なツールであり、マルチモーダルデータに対応しているため、さまざまな領域でソリューションを提供できるということ。
最後に
今回のアップデートでBigQueryをベクトルストアとして利用することができるようになりました。
またBigQueryのSQL関数だけで入力データのベクトルエンべディングやベクトル検索も行えるため、LangChainなどと連携することでRAGアプリケーション開発に関わる大部分を汎用化しシンプルにすることができます。
Vertex AI Searchと比較すると使い分けが難しいところですが、外部データソースのグラウンディングがそれほど複雑ではない場合はVertex AI Searchを、グラウンディングが複雑ではあるがRAGアプリケーション自体の実装はなるべくシンプルに行いたい場合はBigQueryとLangChainを利用する。という使い分けができ、選択の幅が広がりそうですね。




