
セッション概要
今やAWSの中でも、特に重要な存在となったS3についてDive Deepするセッションです
S3のアーキテクチャはどうなっているのか、耐久性をどう実現しているのか、などについて語られていました
Dive Deepするだけでなく、S3の性能を十分に発揮するために必要なTipsも語られていました
また、re:Invent 2023で発表された「Express One Zone」のしくみについてや、最適なユースケースについての説明もありました
以下、AWS Summti公式ページのセッション紹介文からの引用となります
Amazon S3 は、業界トップクラスのスケーラビリティ、耐久性、セキュリティ、パフォーマンスを提供するクラウドオブジェクトストレージです。
このセッションでは、Amazon S3 の基盤となるアーキテクチャを掘り下げ、どのようにしてスケーリングと伸縮自在性を実現しているのかを見ていきます。
データ保護方法、データの耐久性に対する考え方や文化、そして新しい Amazon S3 Express One Zone ストレージクラスがどのように一貫したパフォーマンスを実現するかについて知っていただき、利用者の機械学習ワークロードや、データ分析を支える仕組みの理解を深めます。
資料も公開されておりますが、現地の雰囲気を感じていただきたいため現地で撮影した写真を掲載していきます
最近流行りの生成AIを使う上でのS3の活用方法についても語られていたため、興味のある方はぜひ資料を確認いただければと思います

S3とは

S3はフロントエンド、インデックス、ストレージ層の3層から成り立っているサービス
S3のフロントエンドについて
フロントエンドのスケール実装

S3のピークトラフィックは1PB/sを超えるので、ユーザーがストレスを感じないようにフロントエンドがスケールする必要がある
- マルチパートアップロードとレンジ
- 一括でデータ転送すると転送失敗時に最初からやり直しになる
- マルチパートアップロードを使うと処理の効率化だけでなく、トラブルが発生した時も途中から転送をやり直すことが可能
- データ保存だけではなく、データ取得でも並列化を行うことが可能
- フリートに渡ってリクエストを分散させる
- DNSのMVAによって、S3への接続先IPアドレスを分散している
- MVA(複数値回答):ひとつのURLに対して複数のIPを返す技術
- これらの処理はSDKのランタイムにすでに実装されている
- このような考え方をCRT(Common Runtime)と呼んでいる
- 開発者が意識しなくても、ベストプラクティスに準拠した実装が可能になる
S3のMountpoint
- S3をマウントするのは元々バッドプラクティス、今でもRESTで接続する方を推奨している
- しかし、ニーズとしては依然存在している
- プロトコルの変換が必要になるが、使い勝手を求めて使用するユーザーは存在している
- ニーズに対応するべく、ローカルキャッシュ、コンテナ対応、S3 Express対応を新しく発表している
- これらのアップデートは、どちらかというと機械学習分野で快適に読み込みを実装するための対応
S3のインデックスについて
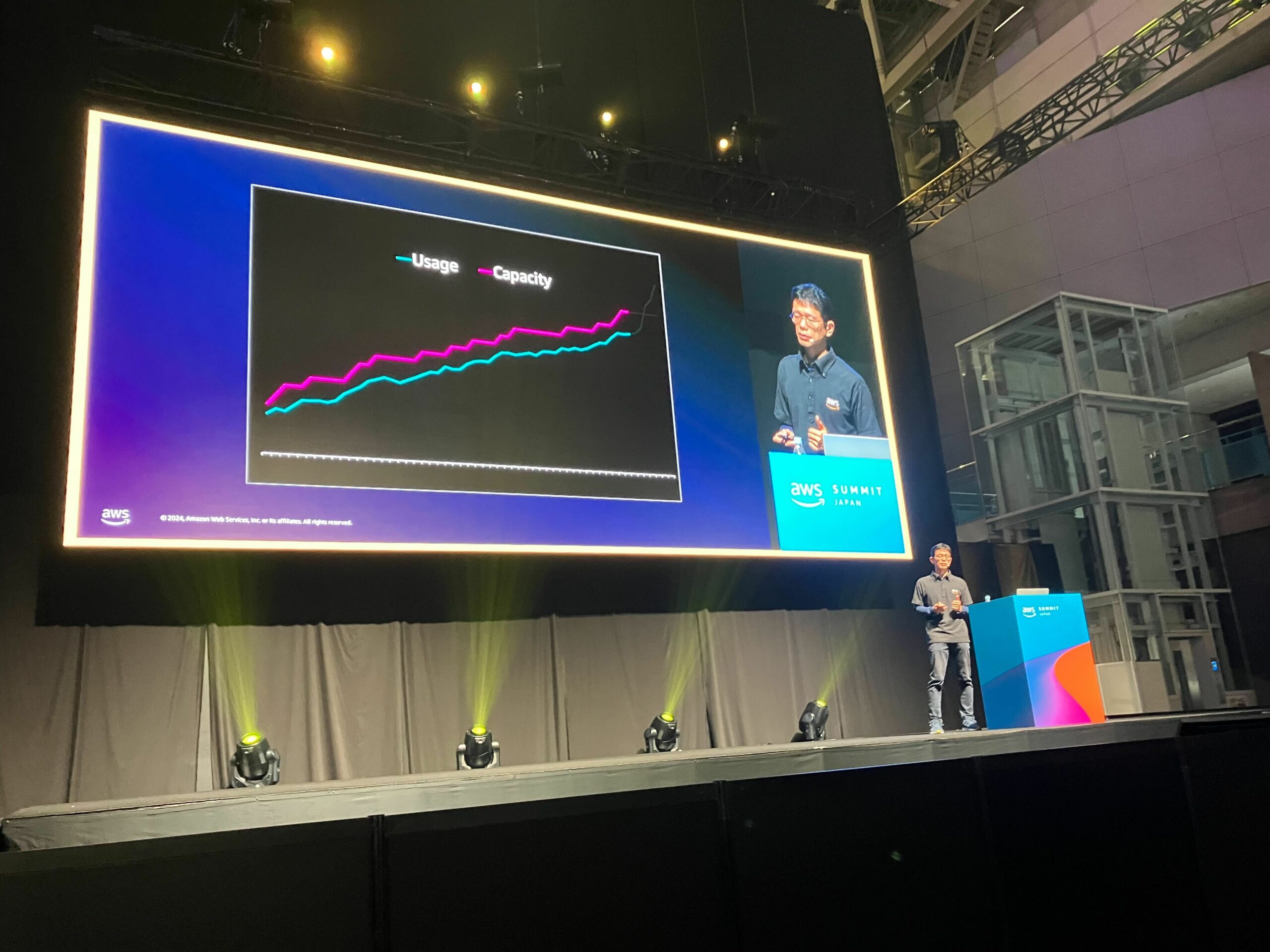
- 350兆のオブジェクトを保存されており、毎秒1億件以上のリクエストを処理する必要がある
- 利用状況とキャパシティを常にモニタリングし、キャパシティを確保できるようにしている

- あるインデックスにアクセスが集中すると、自動的に分散させるように実装されている
- ただし限界があるため、ユーザー側で事前にアクセス分散の実装をしておくと良い
- そのために必要になるのが「プレフィックス」という概念
プレフィックスについて、適切なプレフィックスの付け方

- プレフィックスは厳密には「フォルダ」ではない
- S3の中身はフォルダ構造になっておらず、すべてのデータがフラットに保存されている
- なので、
/(スラッシュ)でいくら区切ってもレイテンシーに影響はない
- 適切なキー命名によって、より快適にS3を使うことができる
- できるだけ数の多いカーディナリティを左側に寄せる
- 日付は右側に寄せる方がいい
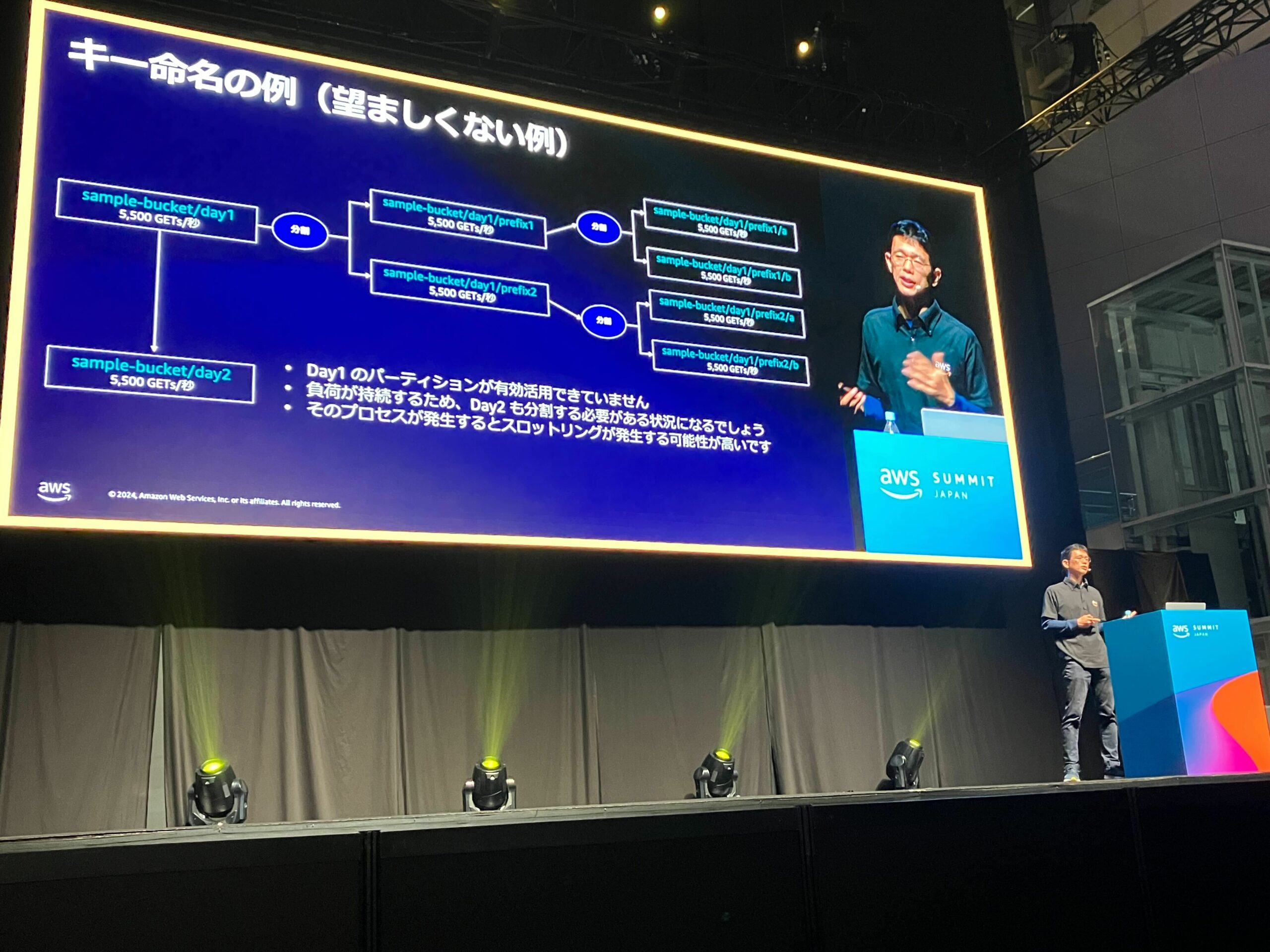
- キー命名の例
- 望ましくない例
- 日付を左に寄せてしまうと、前日に作られたパーティションされた環境を使用できない
- Day2配下でさらに分散する必要があり、スロットリングが発生する可能性が高い
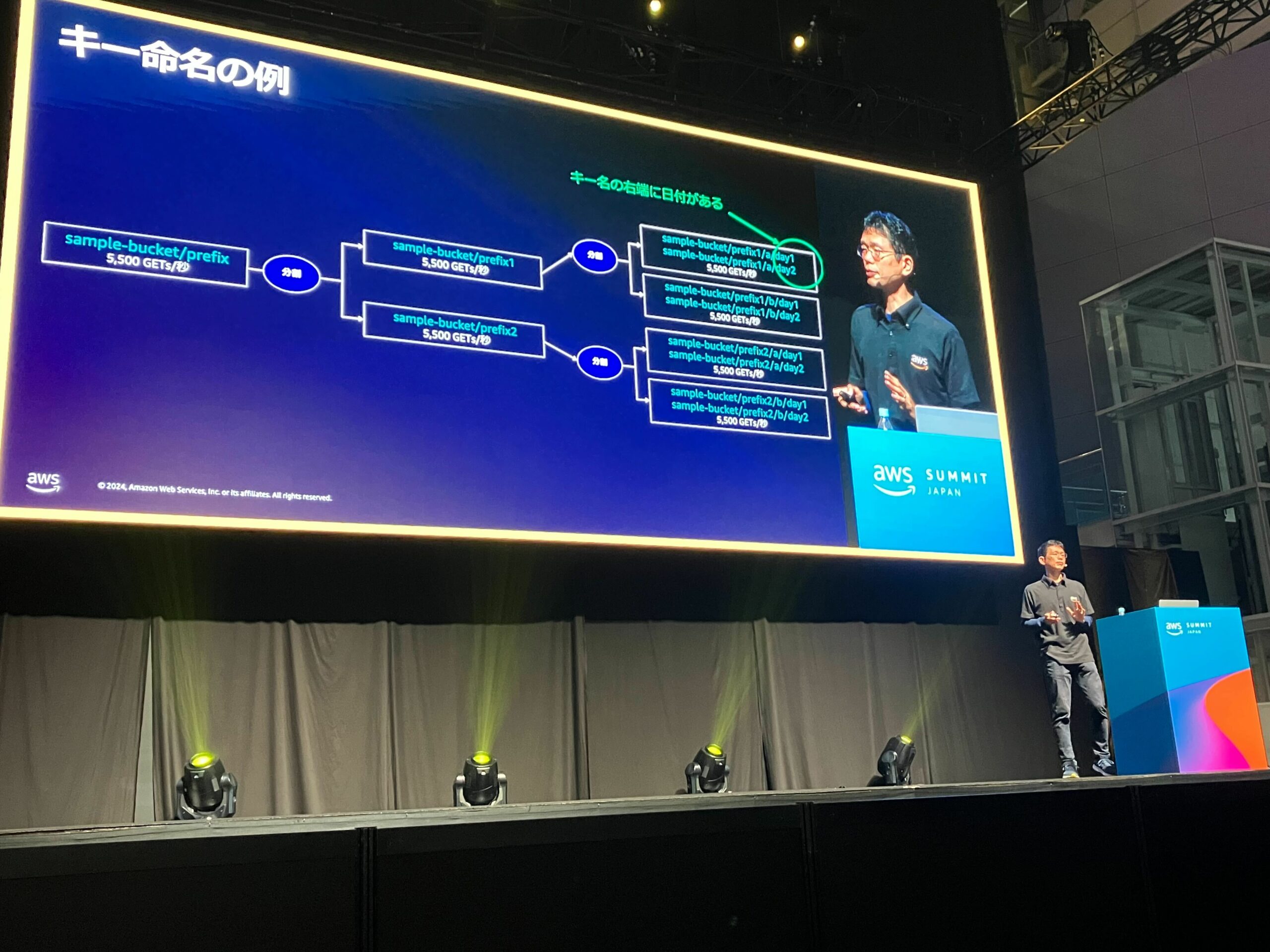
- 望ましい例
- 日付を右側に寄せる
- パーティションの有効活用ができ、スロットリングの発生確率を減らすことができる
- 望ましくない例
ストレージ層について

- ストレージ層では何百ものハードウェアが稼働している
- たとえデバイスが破損してもイレブンナインの耐久性を保つ必要があるため、以下3つの方法で実現している
- リクエストの整合性
- 常に冗長化されたデバイスに保存
- 定期的に保存されたデータの耐久性をチェックする
- たとえデバイスが破損してもイレブンナインの耐久性を保つ必要があるため、以下3つの方法で実現している
イレブンナインの耐久性の実現方法

- リクエストの整合性チェック
- S3へのPUTを行うと、裏では厳密な整合性チェックが行われている
- デバイスに到達するまでに、データのチェックを色々なところで行う
- チェックサムのチェックサムも使用して整合性を保つ
- S3へのPUTを行うと、裏では厳密な整合性チェックが行われている
- デバイスの冗長化
- 大量のハードウェアを使って大規模に冗長化している
- 十分な予備リソースと十分な計画をもって管理している
- 保存されたデータの耐久性を定期的に監視
- チェックサムなどの監視を定期的に行っている
AZ障害への対応
- S3ではマルチAZがデフォルトになっている
- PUTリクエストが複数AZに分散される
- そして、すべてのAZからOKが返ってきてから保存がされたと判断する
S3 Express One Zone
- 今までのS3はGeneral purpose bucketsと呼ばれ、3AZ以上に保存されることがデフォルトとなっているストレージクラス
- プレフィックス単位でスケールする
- 負荷によって段階的にTPS(Transaction per second)が増える
- ひとつひとつのバケットとのやりとりにおいて、認証認可を挟む仕様になっている
- Express One ZoneはDirectory bucketと呼ばれる特別なバケットで、シングルAZで実装されている
- バケット単位でスケールする
- 初めから一定性能を提供する前提で設計されている
- セッション単位で認証認可を行うため、セッションが切れるまでは認証認可が行われない

- AZ内で冗長化しているので耐久性はイレブンナイン
- ただし、仮にAZがひとつ失われたら、データも失われる可能性がある
- S3とのレイテンシーを低減したいアプリケーション向けに高パフォーマンスを実現している
Express One Zoneを使う上での考慮事項
- AZの配置によってレイテンシーに影響が発生する
- パフォーマンスを発揮するためには、S3を使用するアプリケーションと同じAZにバケットがある必要がある
- ただし、AZを跨いでしまっても料金に変動はない
- 異なる耐久性モデルであることをあらかじめ理解しておく必要がある
Express One Zoneのユースケース

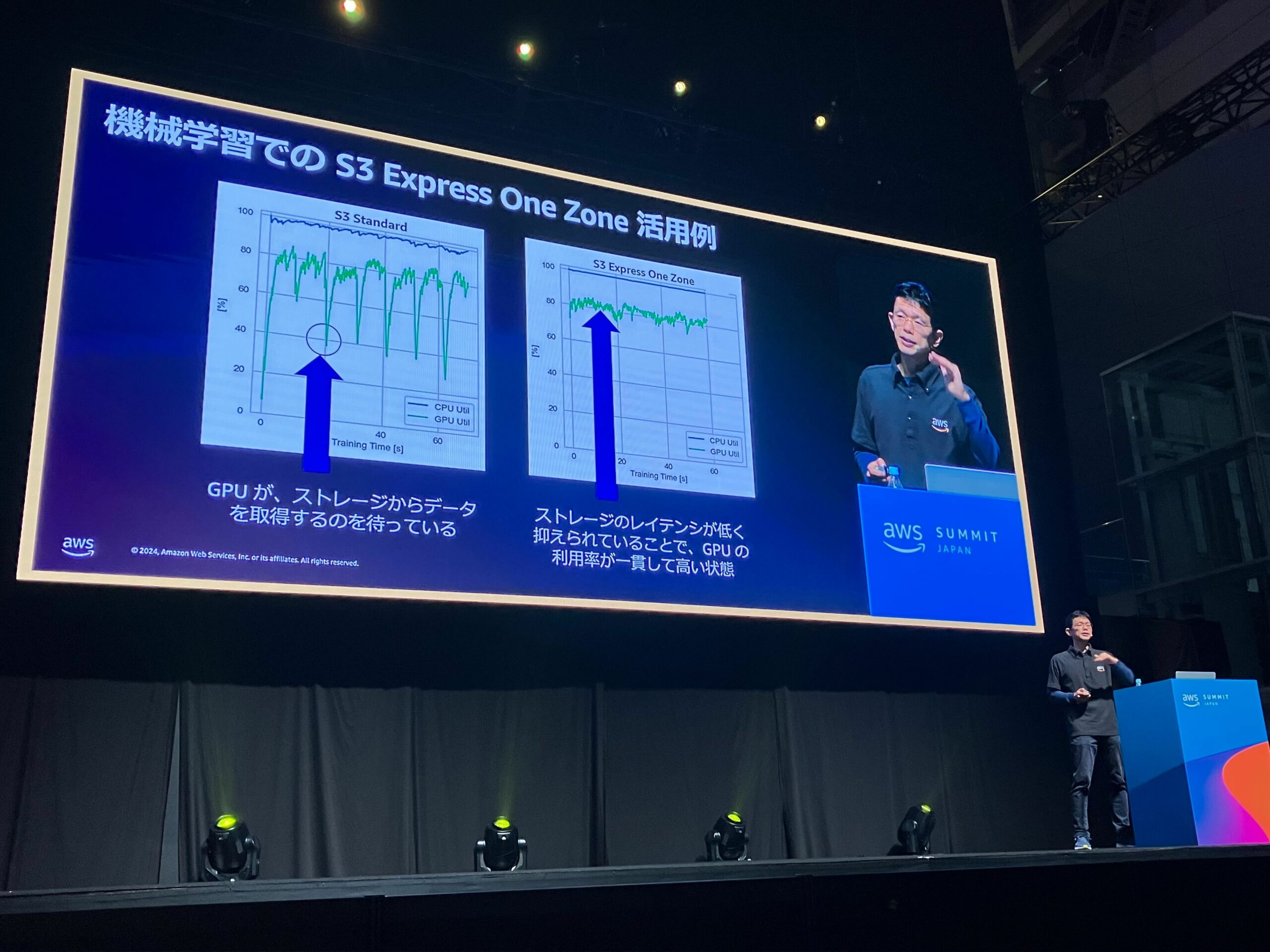
- 機械学習のジョブ完了までの時間を短縮する
- レイテンシーを減らすことでI/O性能が向上し、GPUが処理を行わずに待機時間を減らすことができる
- ジョブ完了までのトータル時間を短縮することできるだけでなく、GPUリソースの有効活用につながる
- さらに、コンピュートコストの削減につながる
誤削除への対策
- 一括削除操作によってデータが失われることは避けたい
- バージョニング、レプリケーション、オブジェクトロック、バックアップなどの方法が用意されている
- AWS Backupを使ったバックアップにより、面でのリストアが可能になる
- 誤削除の機能はExpress One Zoneでは提供されていないので注意
