
はじめに
この記事は「もくもく会ブログリレー」 29 日目 の記事です。
本記事ではGoogle CloudのAIサービスであるVertex AIでRLHF(人間のフィードバックによる強化学習)によるLLMのチューニングを行う手順を紹介していきたいと思います。
なぜモデルをチューニングするのか
一般的にLLMはさまざまなタスクに対応できるように、さまざまな分野のデータを用いて事前にトレーニングされています。
ですが、実際に生成AIをビジネスで活用するに辺り、特定のタスクにおいて自社のルールに則った回答をさせたい。などの要望が出てくるかと思います。
このような要望を解決する手段として、モデルのチューニングが存在します。
なお、公式ドキュメントではモデルをチューニングするメリットとして、以下の3点をあげています。
- 特定のタスクの品質が向上する。
- モデルの堅牢性が向上する。
- プロンプトが短くなるため、推論のレイテンシとコストが低減される。
参考: モデルをチューニングするメリット
モデルのチューニング方法
モデルをチューニングする方法として、パラメータ効率チューニングとフルファインチューニングの2つの方法が存在します。
パラメータ効率チューニングでは、モデルのパラメータの一部を更新するため、モデルが事前に学習した内容に加えてモデルを特定のタスクに効率的に適応させることができます。
対するフルファインチューニングでは、モデルのすべてのパラメータが更新されるため、特定の高度で複雑なタスクにより高い品質で適応させることが可能です。ただし、フルファインチューニングでは大量のコンピューティングリソースが必要になるので、全体的にコストが高くなるので注意が必要です。
Vertex AIでサポートされているチューニング方法
Vertex AIではチューニング方法として、以下の3つが存在します。
- 教師ありファインチューニング
- RLHF(人間のフィードバックによる強化学習)
- モデル抽出 (蒸留)
教師ありファインチューニングでは、ラベル付けされたテストデータを利用して目的の動作やタスクを模倣するようにモデルを学習することで、モデルに新しいスキルを追加することができます。教師ありファインチューニングはモデルの出力が複雑ではなく、分類、感情分析、エンティティ抽出、複雑でないコンテンツの要約などのタスクにおいて有効となる手法です。
2つ目のRLHFでは人間の好みのフィードバックを学習させることで、モデルを人間の好みに合わせてチューニングすることが可能です。公式ドキュメントでは「人間に海に関する 2 つの詩を示し、その人に好みの詩を選ぶよう求めることができます。」というような、モデルの出力が複雑で教師ありファインチューニングでは容易に解決できないような質問への回答、複雑なコンテンツの要約、リライトなどのコンテンツ作成などのタスクに適していると記されています。
RLHFはChatGPTなどでも利用されており、以前のGPTモデルでは論理的に問題のある回答や差別的な回答を行う可能性が高い状態となっていましたが、これをRLHFを用いて人間のフィードバックを学習させることで改善を行っています。
なお、Vertex AIのコード生成モデルはRLHFをサポートしておらず、教師ありファインチューニングが唯一の選択肢となります。
最後のモデル抽出はディスティレーション(蒸留)とも呼ばれる手法で、別の大規模なモデルを教師モデルとして小さな生徒モデルをトレーニングすることで、大規模な教師モデルと同様の処理を低コストかつ低レイテンシで行う新たな小さいモデルを作成することができます。
参考: 人間からのフィードバックを用いた強化学習(RLHF)によるチューニング
PaLM2をRLHFでチューニング
RLHFを実行する前に、Vertex AIにおけるRLHFはどのようなトレーニングをしているかを見ていきましょう。
Vertex AIにおけるRLHFでは報酬モデルと強化学習の2つのフェーズで構成されています。報酬モデルはあるプロンプトに対する回答を複数用意しどちらの回答が優れているかを指定した「人間の好みのデータセット」から人間の好みの学習を行います。
続く強化学習フェーズでは作成された報酬モデルを使って、人間の好みが指定されていないラベルなしのプロンプトを用いて回答の品質をスコアリングします。この際に回答が高品質であればその内容でモデルが強化され、今後同様の回答が生成される確率が高くなります。
データセットの準備
RLHFでは、プロンプトデータセット、人間の好みデータセット、評価データセットが必要となります。ただし、評価データセットはモデルのチューニングジョブ後に評価を行わない場合は不要となります。
プロンプトデータセットはinput_textフィールドを持つ、前述した強化学習フェーズで利用する人間の好みがラベリングされていないプロンプトを指定します。以下はプロンプトデータセットの例です。
{
"input_text": "Create a description for Plantation Palms."
}
続いて人間の好みのデータセットは報酬モデルをトレーニングする際に利用される、プロンプトとそれに対する2つの回答を用意しどちらが優れているのかをラベリングしたものを用意します。以下は人間の好みのデータセットの例です。
{
"input_text": "Create a description for Plantation Palms.",
"candidate_0": "Enjoy some fun in the sun at Gulf Shores.",
"candidate_1": "A Tranquil Oasis of Natural Beauty.",
"choice": 0
}
最後の評価データセットはプロンプトデータセットと同じく評価用に人間の好みのラベリングがないプロンプトを用意します。ただし、プロンプトデータセットの内容とは異なるものを用意する必要があります。
なお、上記のデータセットはJSONLと呼ばれるフォーマットで準備する必要があります。
チューニングの実行
Google CloudコンソールからVertex AIを開き、左メニューの「VERTEX AI STUDIO」->「言語」を選択します。すると「TUNE AND DISTILL」タブが表示されるので、「CREATE TUNED MODEL」を選択します。
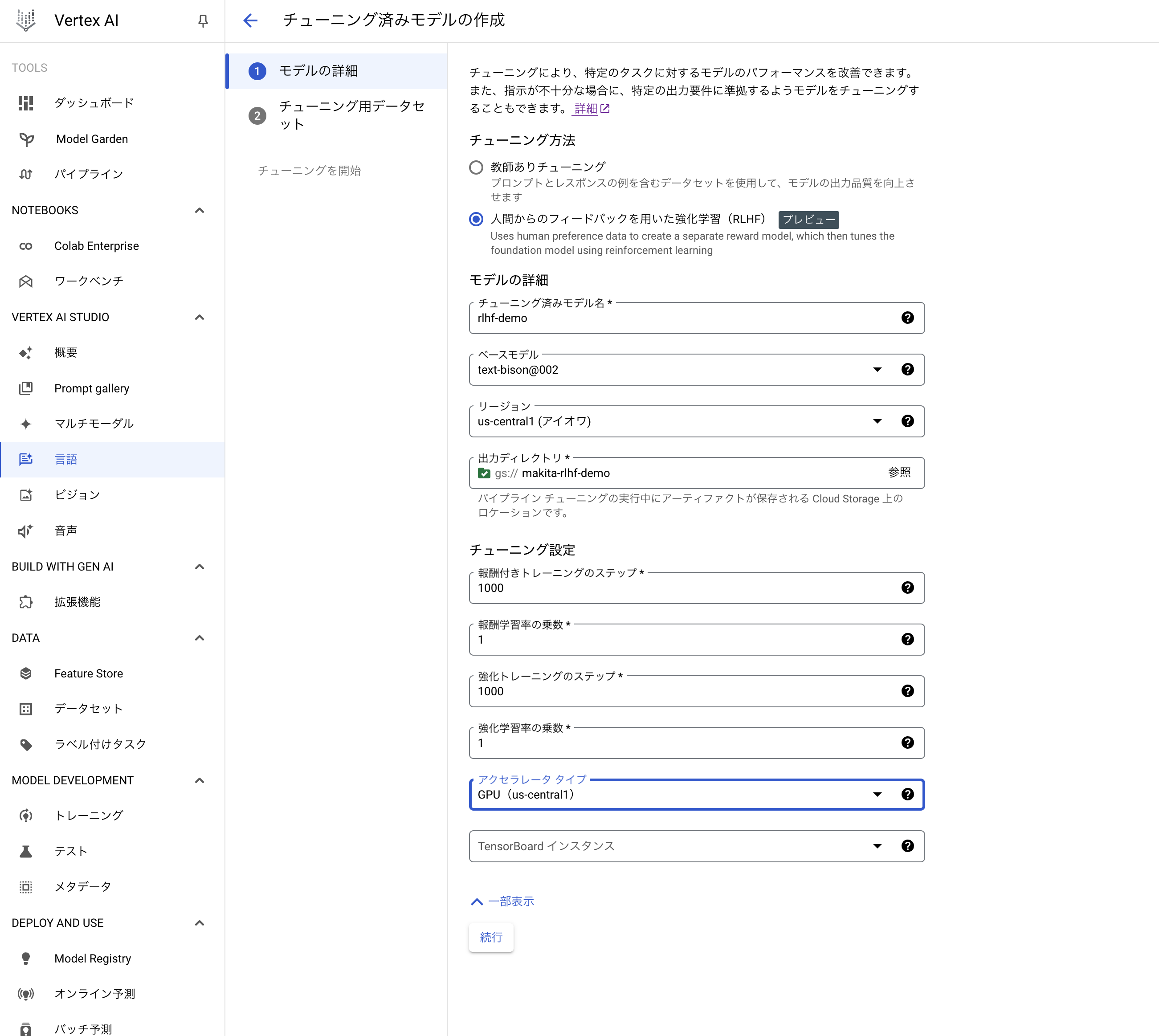
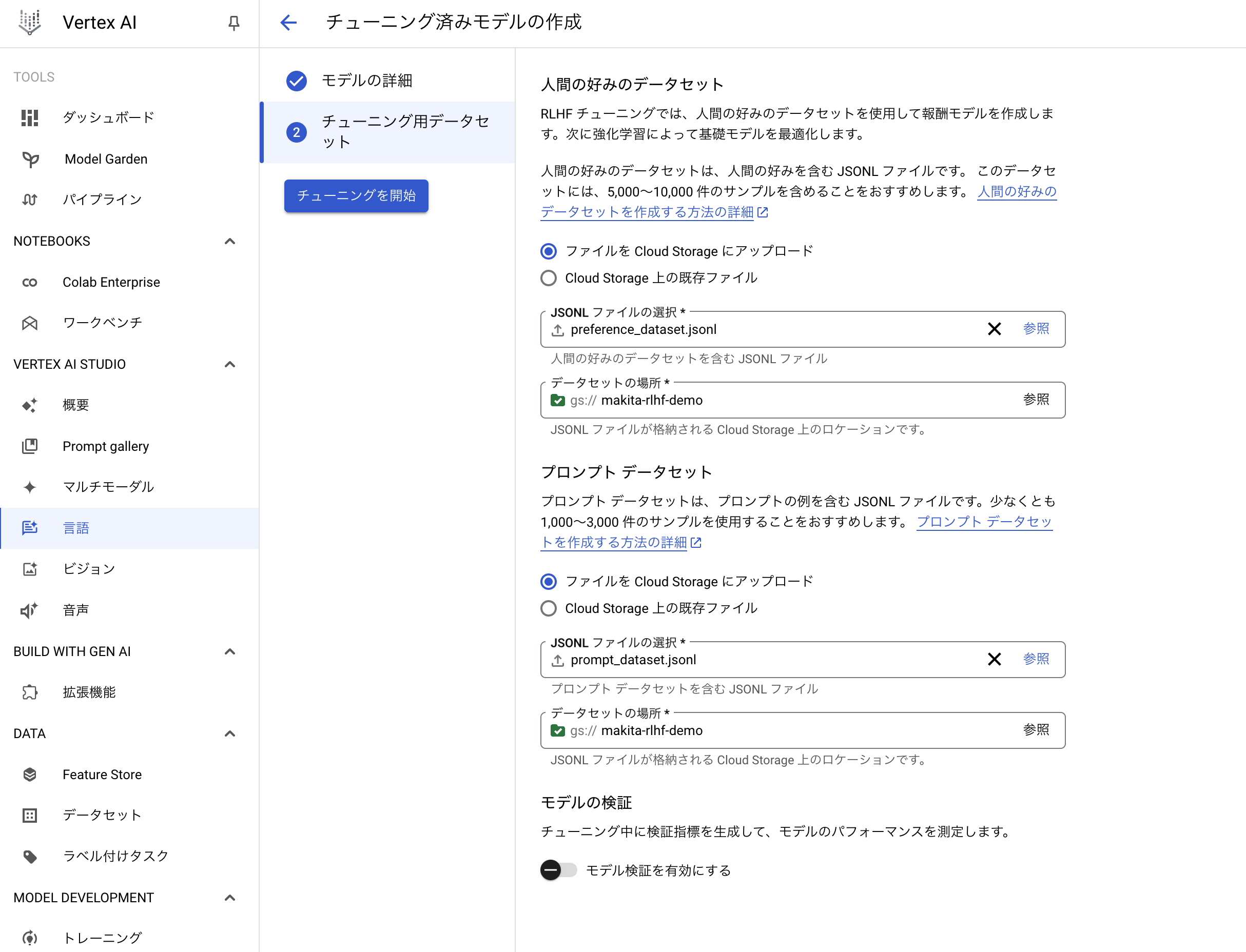
チューニングジョブの作成画面に遷移するので、チューニング方法を「人間からのフィードバックを用いた強化学習(RLHF)」を選択し、以下のようにチューニングジョブを作成します。なお、「チューニング設定」内の各パラメータは公式ドキュメントで以下のように解説されています。
- 報酬付きトレーニングのステップ: 報酬モデルのトレーニングで実施するステップ数を入力します。報酬モデルはモデルをチューニングするために使用されます。デフォルト値は 1000 です。
- 報酬学習率の乗数: 報酬モデルをトレーニングする際の学習率に影響する浮動小数点値を入力します。デフォルトの学習率を上げるには、より大きな値を入力します。デフォルトの学習率を下げるには、より低い値を入力します。デフォルト値は 1.0 です。
- 強化トレーニングのステップ: 強化学習を使用してベースモデルをチューニングする際に実行するステップ数を入力します。デフォルト値は 1000 です。
- 強化学習率の乗数: 強化モデルをトレーニングする際に学習率に影響する浮動小数点値を入力します。デフォルトの学習率を上げるには、より大きな値を入力します。デフォルトの学習率を下げるには、より低い値を入力します。デフォルト値は 1.0 です。
トレーニングジョブを作成すると、Vertexi AI パイプラインが作成されます。
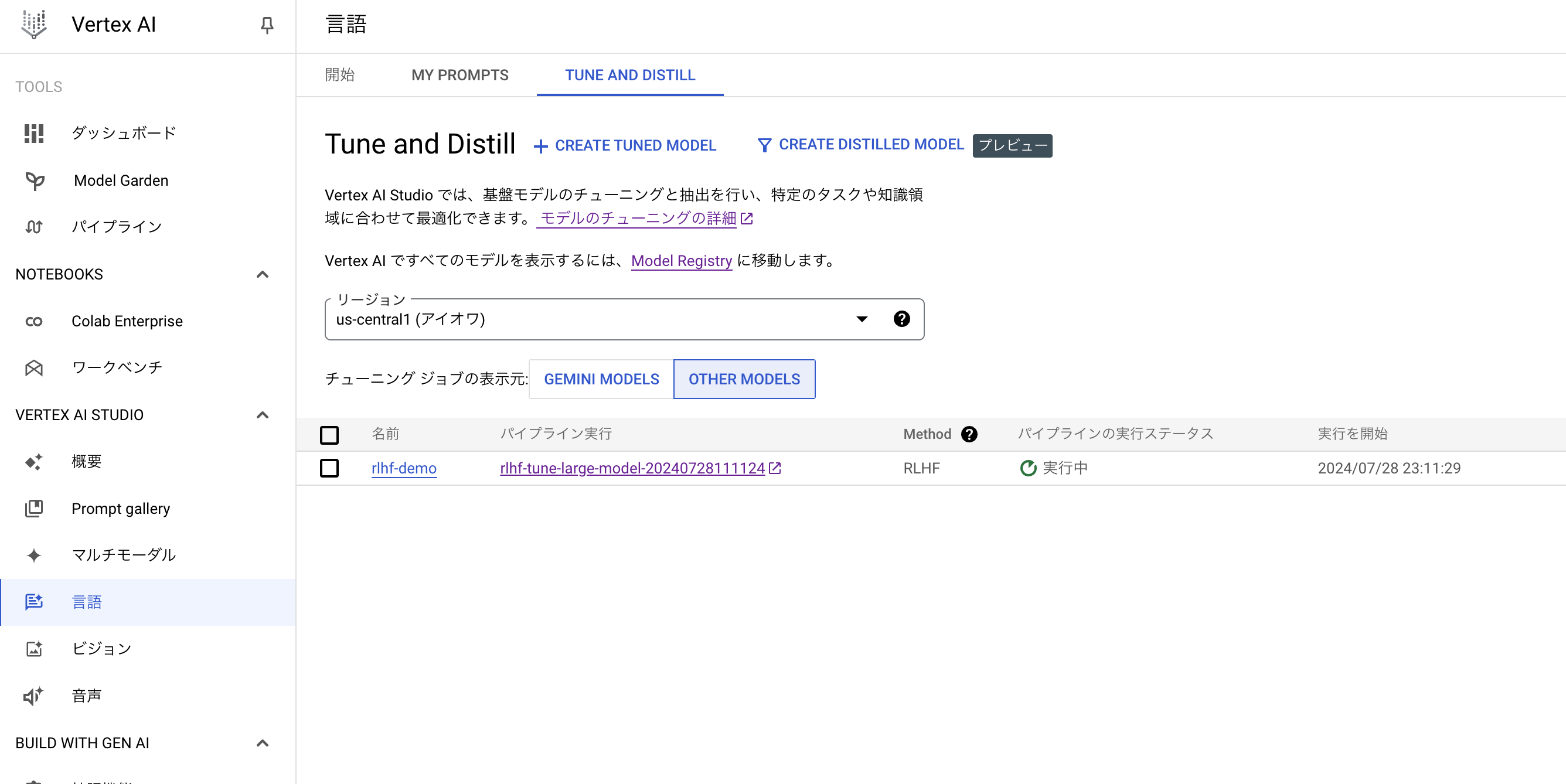
事前に解説した通り、報酬モデルの作成フェーズと教科学習のフェーズが存在することが確認できます。
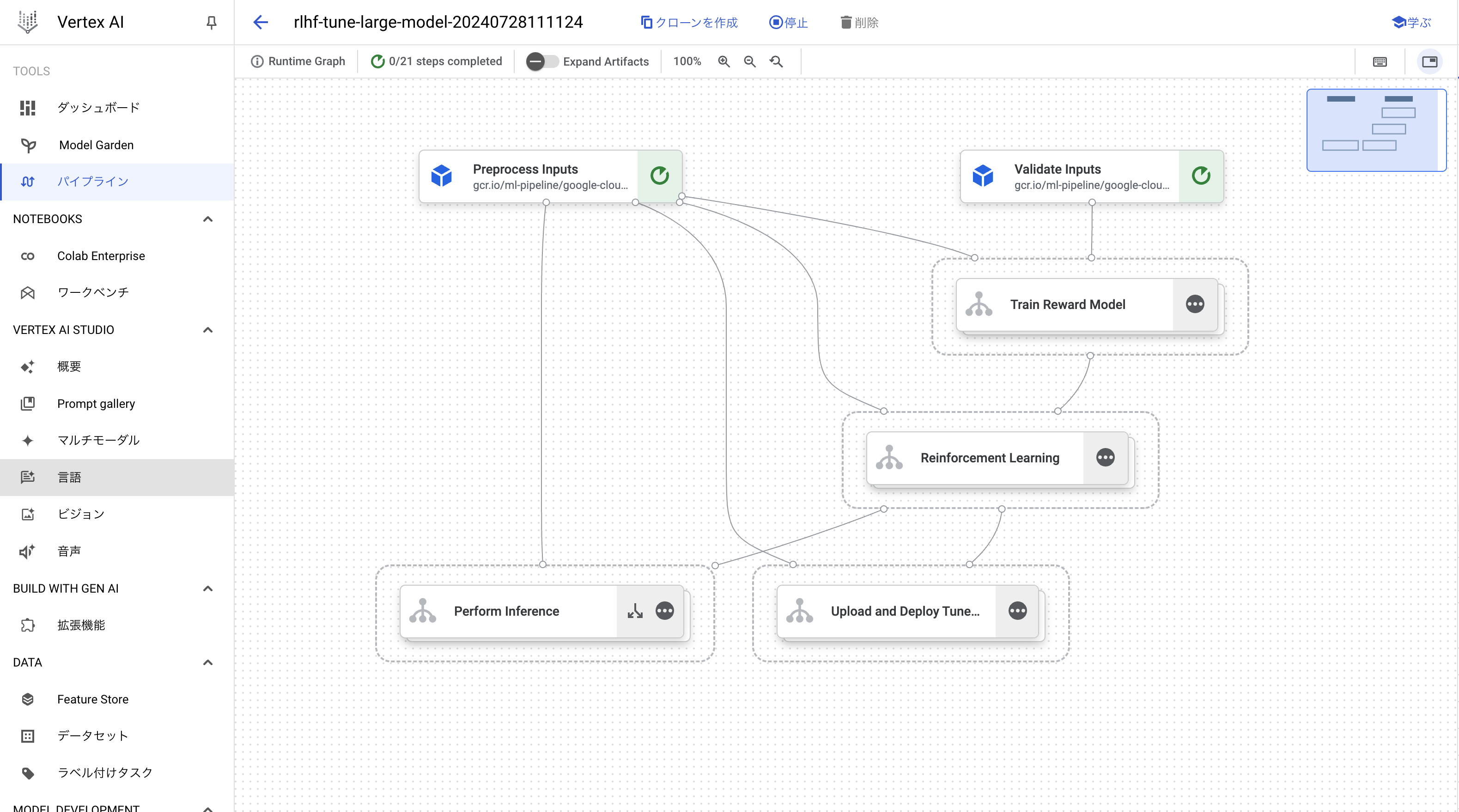
コストの関係で最後まで実行できませんが、パイプラインが完了するとジョブの作成時に指定したバケットにトレーニングされたモデルが出力されます。
これをModel Registryなどにアップロードすることで、呼び出して利用することが可能です。
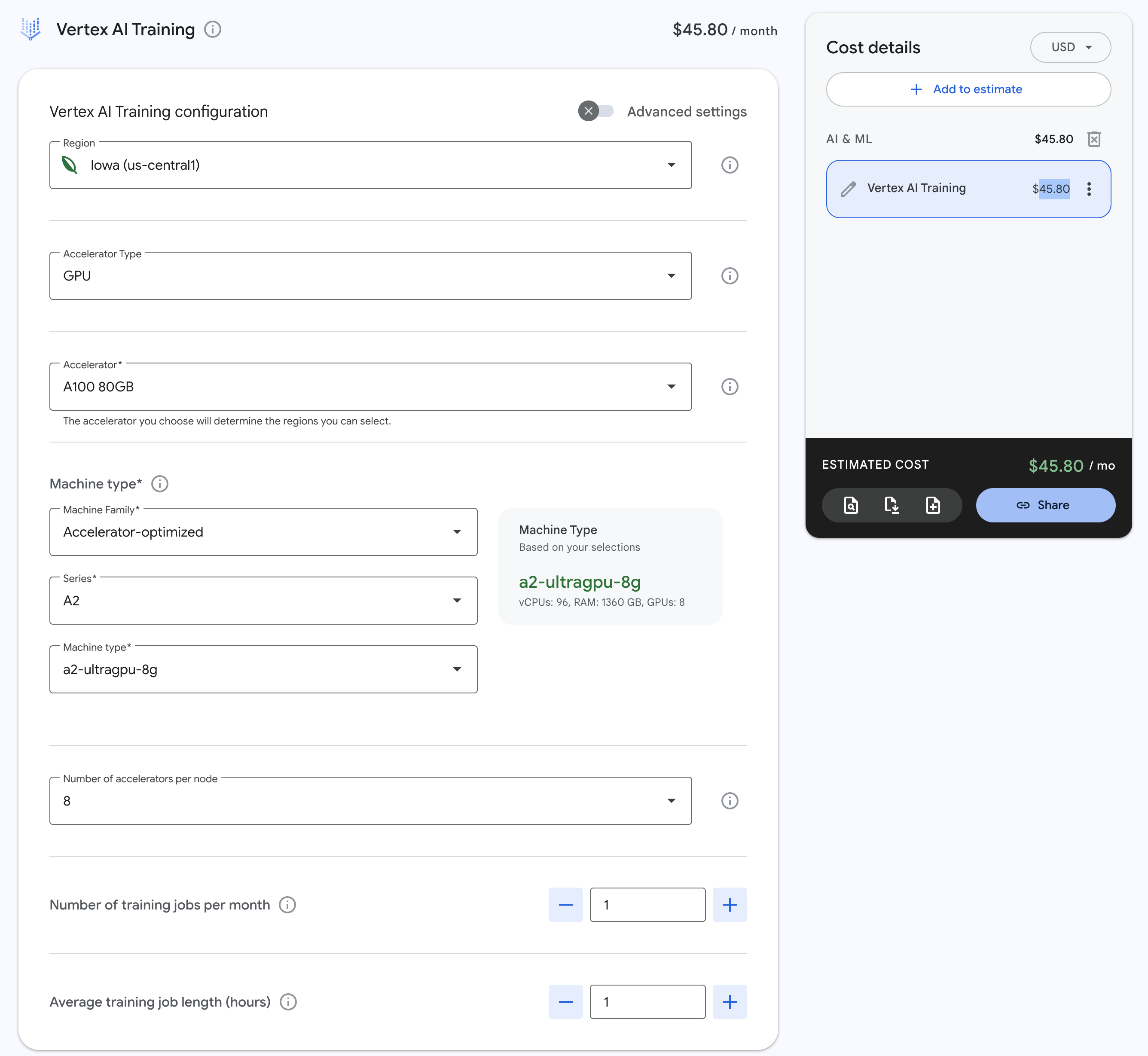
なお、このパイプラインで実行されるコンピューティングリソースはus-central1リージョンの場合は「8 個の Nvidia A100 80 GB GPU 」となっており、料金としては1時間あたり$45.80が課金されますので、課金額を考慮しながらの実行が必要となります。
最後に
Vertex AIにおけるRLHFの手順を解説しましたが、いかがでしたでしょうか。
コストはかかりますが、教師ありファインチューニングで対応が難しい場合のチューニングの最終手段として活用できるチューニング手法のため、手順や勝手を知っておくことで、実際に利用して課題に直面した場合の選択肢となるアプローチが増えるので知っておいて損はないかと思います。
明日の記事は、土井田 さんの「AWS IAM Identity Center & Amazon Managed Grafanaと連携したセキュアな静的コンテンツ配信の実現 」です。お楽しみに。



