
MSP江崎です、溶けるほど暑い夏ですが皆さんいかがお過ごしでしょうか。
先日紹介したPagerDuty on Tour TOKYO 2024にLT登壇者として参加してきました。LTが5分のため今回はLTだけでは紹介しきれなかったスライドの背景や思いなどを紹介いたします。
PagerDuty on Tour TOKYO 2024
イベントについてはこちら:【PagerDuty on Tour TOKYO 2024】気になるイベント情報を一足先にご紹介!
今回私はLT登壇のチャンスをGetして参加してきました。LT(Lightning Talk)と聞いていたので勝手に小規模なセッションとイメージしていましたが200名+スタンディング(懇親会)のスペースでの登壇ということを応募後に知って驚いたのは内緒です..
前提
まずは言葉の定義として、登場人物については以下のように設定しています。また今回の投稿では話さない内容も予め記載しておきます。
定義
- Tier1 (24/365):お客様の環境を24時間365日有人で対応しているアイレットの運用保守チーム
- Tier2 (案件担当者):構築・運用を実施している各お客様(案件毎)の担当チーム
話さないこと
- 細かなPagerDuty の設定について
- Operaitons Cloudなどの基本や対応フローについて
MSP × Operations Consoleの活用法
今回私がLTのテーマに選んだのはPagerDuty が提供するAIOpsの機能のひとつである「Operations Console」を使用してMSPが抱える課題をどのように解決できたか!です。
それでは、背景等も踏まえLTの時間だけでは説明しきれなかった内容を紹介していきます。
伝えたいこと
いきなり結論になりますが、Operations Consoleを活用すれば我々 MSP Tier1 (24/365)が対応するインシデントだけがダッシュボードに表示されます。
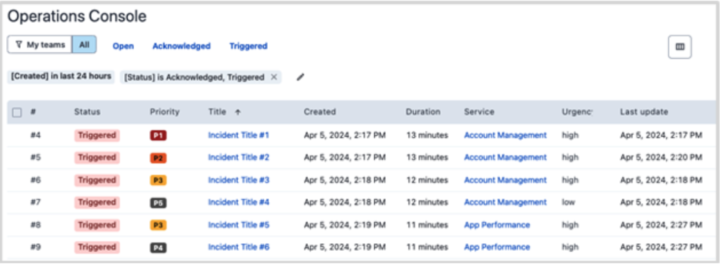
参考:ライブビューリスト
うん?…どういうこと??

Serviceは必ず1つのチームが完全に責任を持つ範囲で分割する
Serviceの分割において守るべき原則は、あるServiceに責任を持つチームは必ず1つであることです。複数のチームに責任がまたがってしまうと、通知先(Escalation Policy)が適切に設定できません。ここでいう「責任を持つ」とは「インシデント解決のための初動対応を行う」という意味です。
今回の経緯を理解する上で必要なPagerDuty の概念として1つのチームでインシデント発生から完了まで対応することを原則として考えられているということです。つまり「エスカレーションなどで対応するチームが変わる」ということは想定された作りではありません。この「1つのチームで対応する」という概念が重要になるので、頭の片隅にメモしておいてください。
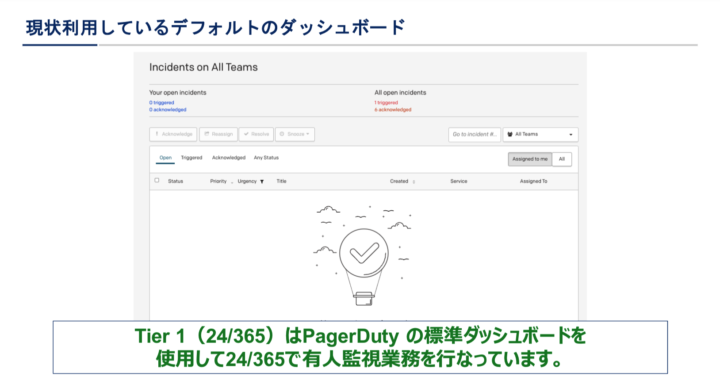
現状利用しているデフォルトのダッシュボード
私たちはPagerDuty のデフォルトのダッシュボードを運用業務の要として使用しています。このダッシュボードが使いにくい。という話ではなく弊社でインシデント対応する際に表示されるインシデントがMSPを介するエスカレーションのフローと乖離する部分がある。という話になります。
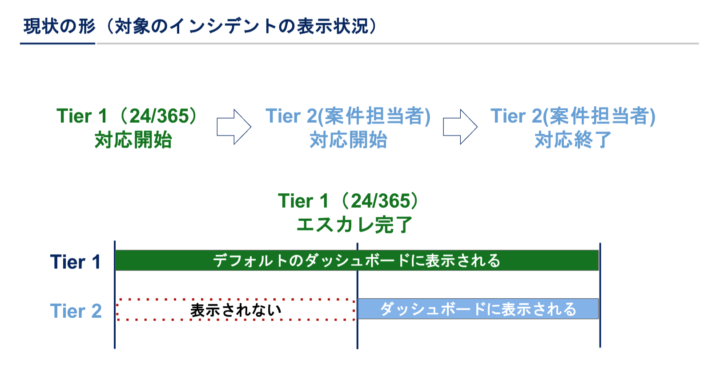
現状の形(対象のインシデントの表示状況)
図でエスカレーションのフローを交えながら説明します。上部の矢印がインシデントに沿ったエスカレーションの流れ。下部がそれに伴うデフォルトダッシュボードの表示状態を示しています。現状は上部のエスカレーションの発生に関わらずTier1のダッシュボードには常に表示されます。(もちろんエスカレーションを受けたTier2のダッシュボードにも表示されます)
理想の形(対象のインシデントの表示状況)
理想の形を見てみましょう。現状とは違いエスカレーションの流れに応じてTier1 / Tier2 のダッシュボード上の表示が変化しています。これが実現したい理想の形、逆を言えばこれが実現できないのです。

なぜ実現できないの??
話だけ聞くと、とっても簡単な話に聞こえますが実現できない仕様になっているのです。その理由として先ほどポイントに挙げた「Serviceは必ず1つのチームが完全に責任を持つ範囲で分割する」が関連してきます。つまりそもそもの仕様(概念)として対応するチームが変わる(受けわたす)ことを想定された作りになっていない。ということが理由になります。
なぜ理想を実現したいのか??

そもそもの話ですが、なぜエスカレーションに沿ったダッシュボード表示を実現したいのか。その答えは「インシデント数が増加」していることが背景にあります。以下のグラフの通り年々お預かりするプロジェクト数が増加すると共にインシデント件数も増加傾向にあります。
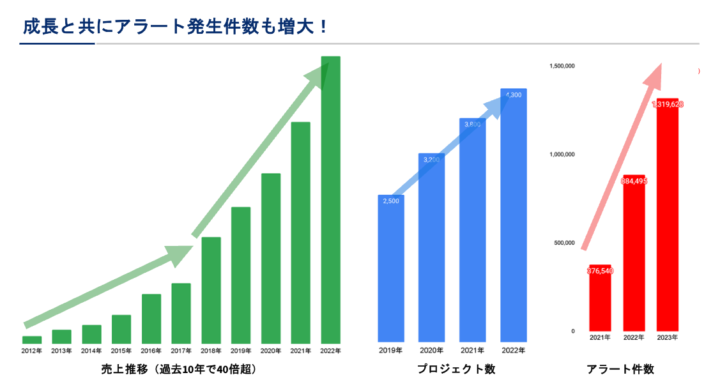
対応が必要なインシデントだけを表示させたい。
環境や状況が変化すると共に、もちろん運営側(現場)サイドのニーズにも変化が生じます。本来のエスカレーションの動きとともにダッシュボードも変化したらいいのにな。。そんなニーズ(理想)をがっちりホールドして叶えてくれるのが「Operations Console」になります。
Operations Console?
Operations ConsoleはNOCのモダナイズを推進するAIOpsのオプション機能
- リアルタイムのインシデント管理(ダッシュボード)
- 柔軟なフィルタ機能
- 自動診断と推奨アクション
- 次に発生する可能性の高いインシデントの予測
- 修復のための貴重なコンテキストの提供
NOCのモダナイゼーションとダウンタイムの減少
限られたリソースで、顧客のために厳しい基準を満たし、ダウンタイムを最小限に抑える責務をもつNOCでは、24時間365日、いつ発生するか分からないアラートやインシデントに対応するために積極的に監視しています。NOCにおける担当者の多くは、様々なツールから通知される、異なるデータセットをコンテキスト化し、適切な対応チームと連携しながらインシデントの迅速な修復を進めていますが、膨大なデータと認知負荷の増大、他部門のチームとの連携に大きな課題を抱えています。このような状況を打開するには、NOCのモダナイズが必要となります。
※NOC(Network Operations Center)つまりアイレットでいうMSPのTier1(24/365)
つまり時代の変化に合わせて運用保守をアウトソーシングするケースも踏まえ、PagerDuty 側も追加で機能を実装してくれた!という喜ばしい変化です。
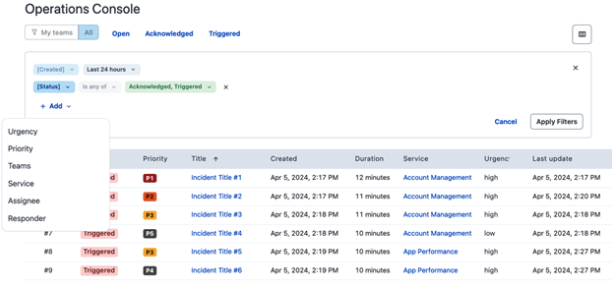
柔軟なフィルター機能
Operations Consoleの機能の中で今回使用するのは主に2つになります。
- リアルタイムのインシデント管理(ダッシュボード)
- 柔軟なフィルタ機能
リアルタイムで表示されるダッシュボードに加えて、柔軟なフィルター機能を使用することでTier1(24/365)が対応するインシデントだけを表示することが可能になります!!!具体的にはエスカレーションポリシー・ユーザーなどで柔軟にフィルターを設定しカスタマイズすることが実現。
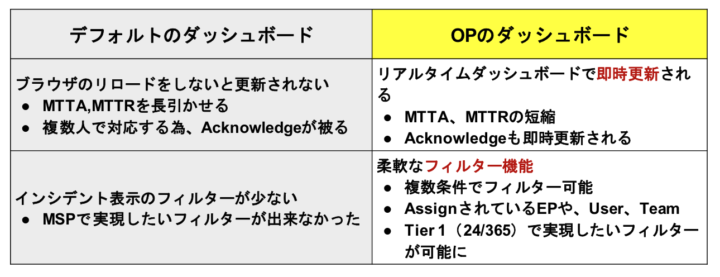
Operations Consoleの導入効果
以下に導入効果を簡単にまとめています。
Operations Consoleについての補足
Operations ConsoleについてはAIOpsのアドオン機能の1つとして追加することで利用が可能です。
まとめ

今回はAIOpsの新機能のひとつ「MSP × Operations Consoleの活用法」を紹介いたしました。今後もPagerDuty の概念や機能を理解して運用業務の最適化に挑戦することでお客様環境の保守のスペシャリスト・プロフェッショナル集団としてより一層レベルアップしていきたいと改めて感じるきっかけとなりました。

