
4月に入社しました、DX開発事業部の野呂瀬です。
昨日、Google Cloud Next Tokyo ’24に参加しました。
この記事では、前半に一番印象に残ったセッション、後半では、ブースの体験などを記載したいと思います。
セッション内容
株式会社WFS様は、社内に溢れかえる情報をチャット形式で検索できないか?という課題に対し、Google CloudのAIソリューションを活用し社内ツールとして構築を行なったという内容でした。
事例紹介
生成AIを使用した社内向けのチャットサービスの開発
AIが社内資料を元にWebブラウザ上で動作し、回答してくれるサービス。
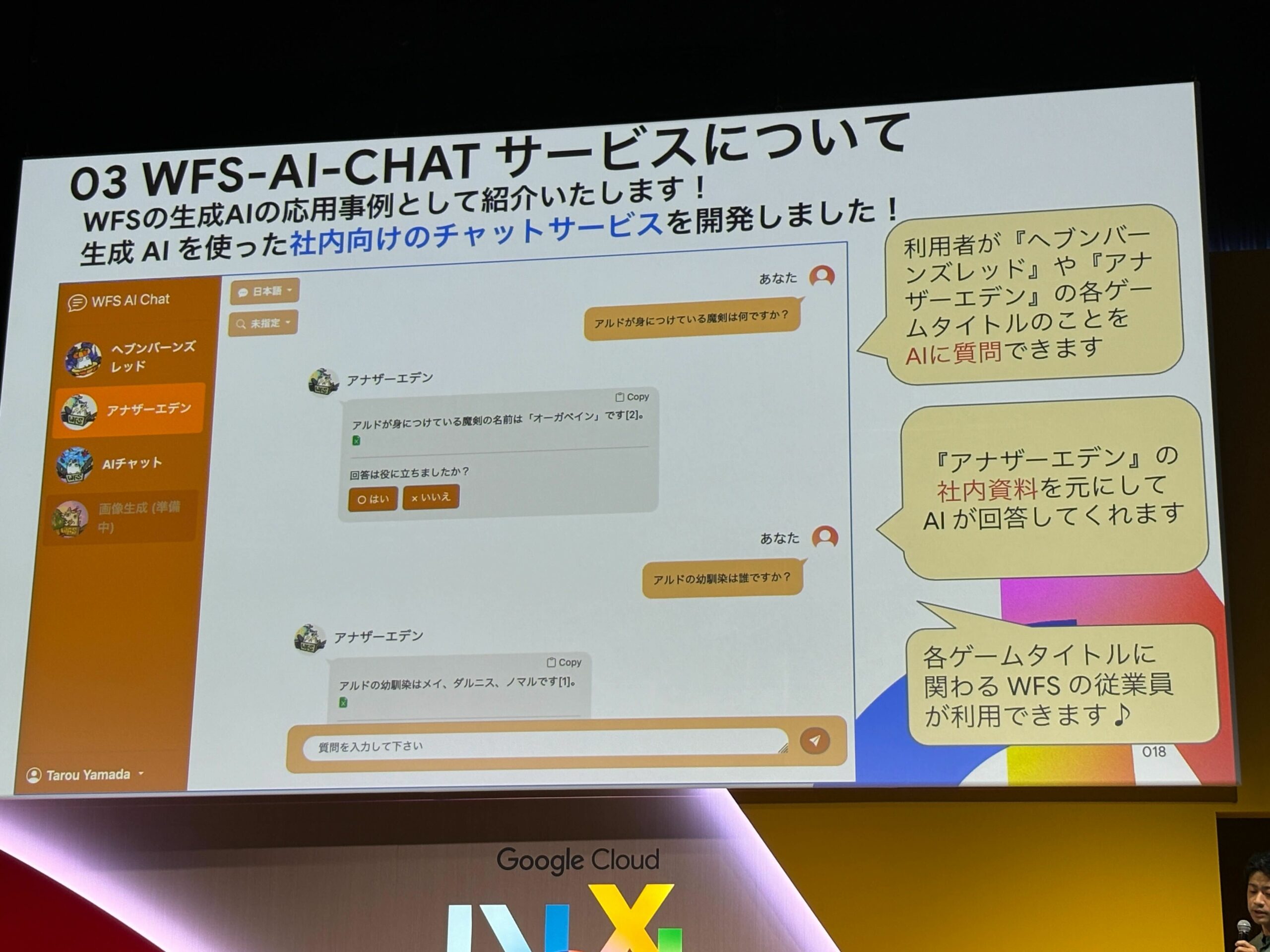
特徴としては、非構造化データの社内資料をベクトルデータとしてVertex AI Searchに取り込んで、AIに回答させる、
社内資料は、約3万ファイル、約4千ファイルと膨大な量のデータであるという特徴があります。
アーキテクチャは以下のようになっています。
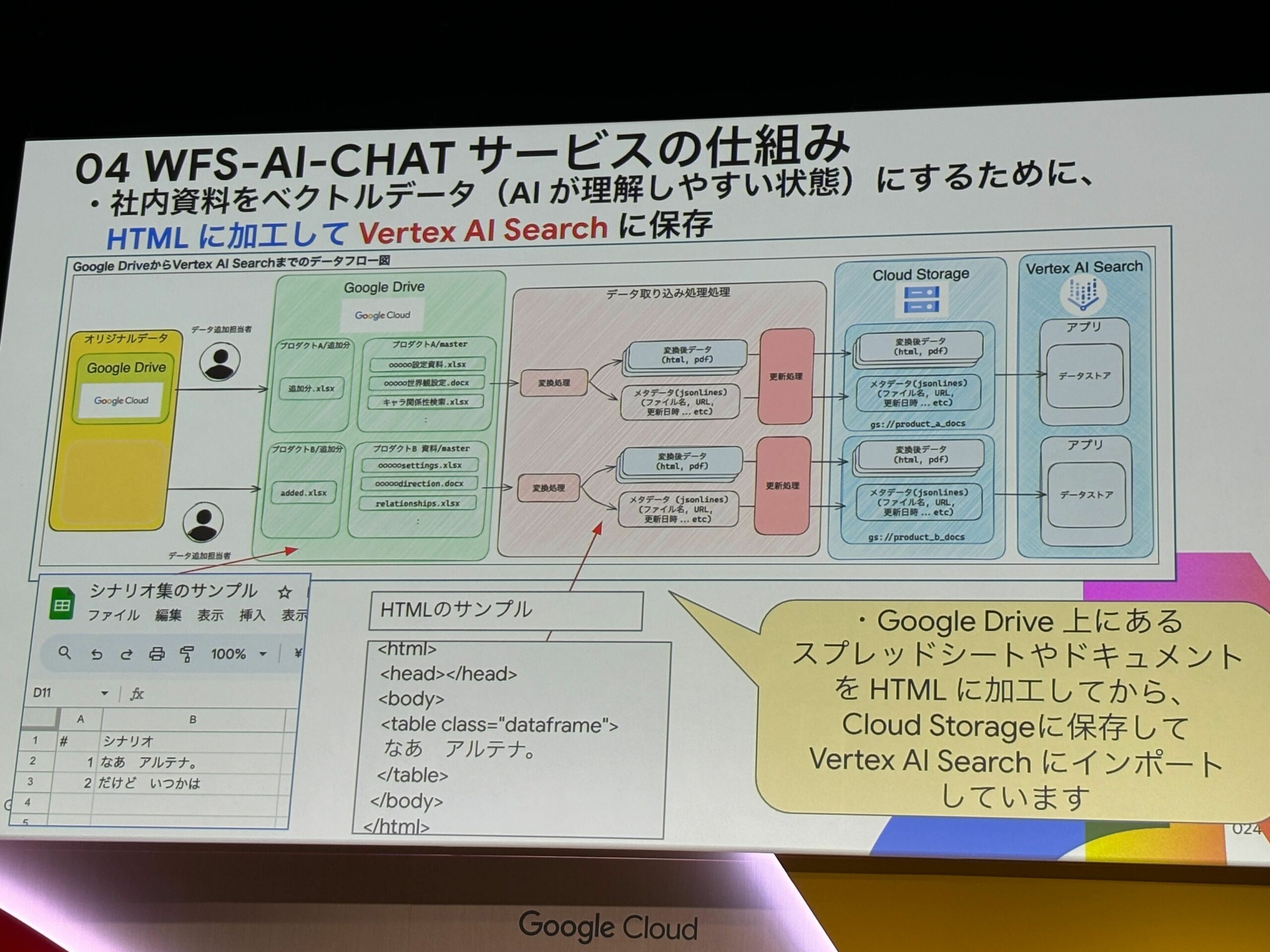
社内資料をベクトルデータにするために、データを取り込む処理としてGoogle Drive上にあるスプレッドシートやドキュメントをHTMLに加工してCloud Storageに保存して、Vertex AI Searchにインポートしています。
このサービスの仕組み(RAG)は以下のようになっています。
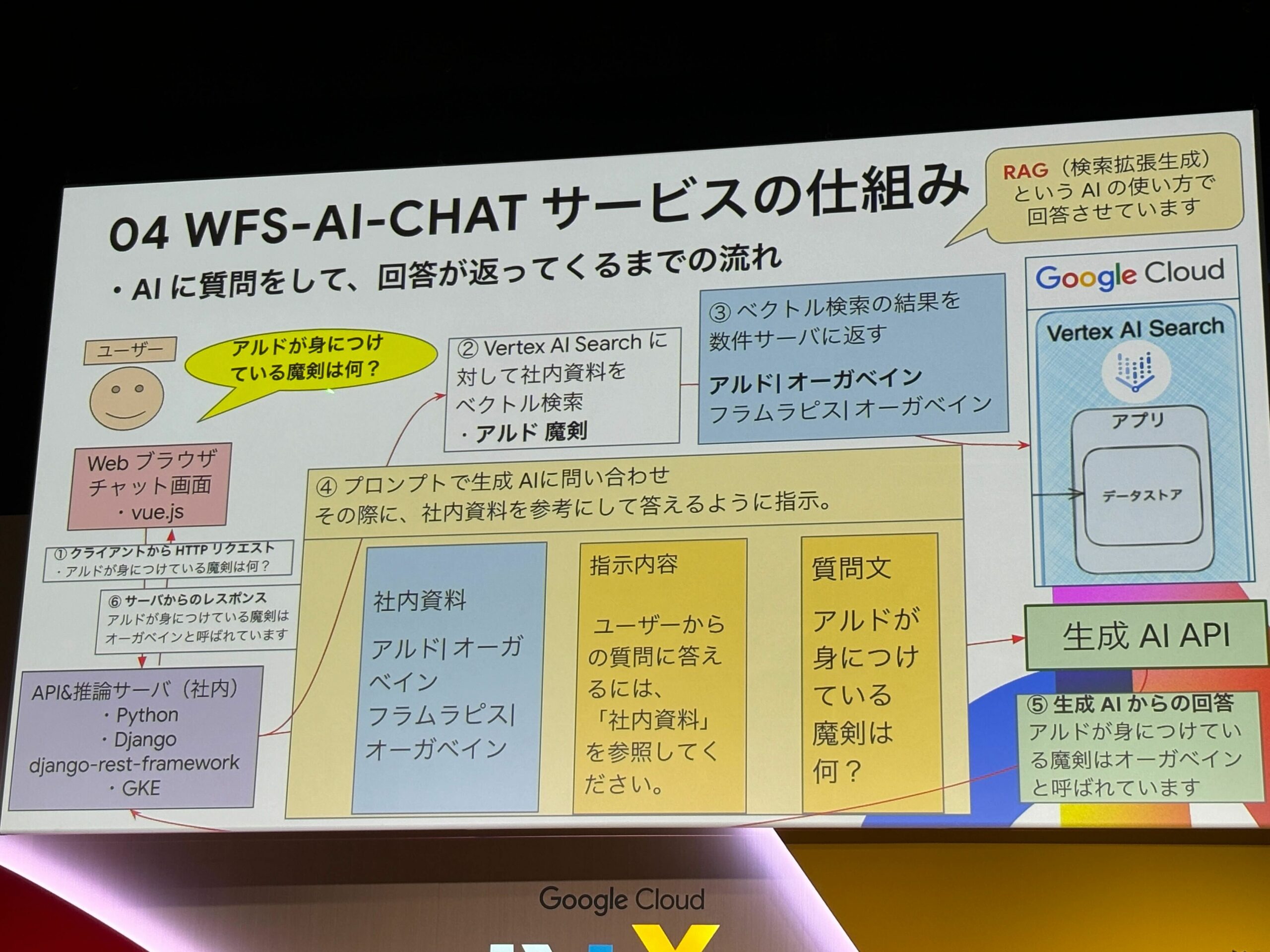
①クライアントからHTTPリクエストを送信される
②Vertex AI Searchに対して社内資料をベクトル検索する
③ベクトル検索の結果を数件サーバに返す
④プロンプトで生成AIに問い合わせ、その際に社内資料を参考にして答えるように指示する
⑤生成AI APIを作成して、回答します
⑥サーバからレスポンスを送信する
という流れになっております。
Vertex AI Searchを利用する際のポイント

①Vertex AI Searchのデータ登録時にデジタルパーサーとレイアウトパーサーを使い分けてデータを登録する
使い分けとしては、基本デジタルパーサーで取り込み、精度が悪い際にレイアウトパーサーに切り替える

②Vertex AI Serachのメタデータに検索したいメタ情報を登録する
1ファイル毎にメタデータを登録でき、検索範囲の絞り込みなど、いろいろな用途に使うことができる

③Vertex AI Serachのデータストアを分類ごとに別々に用意
ベクトルデータを貯めているデータストアは、検索のHIT率を上げるためにゲームタイトル毎・分類毎に用意する

④登録するファイルが大きすぎる場合はファイル分割
膨大なファイルであると、ファイルの後方の情報が検索でHITしない場合があるため、適切な範囲でチャンク化をして、ファイルを分割してから登録する
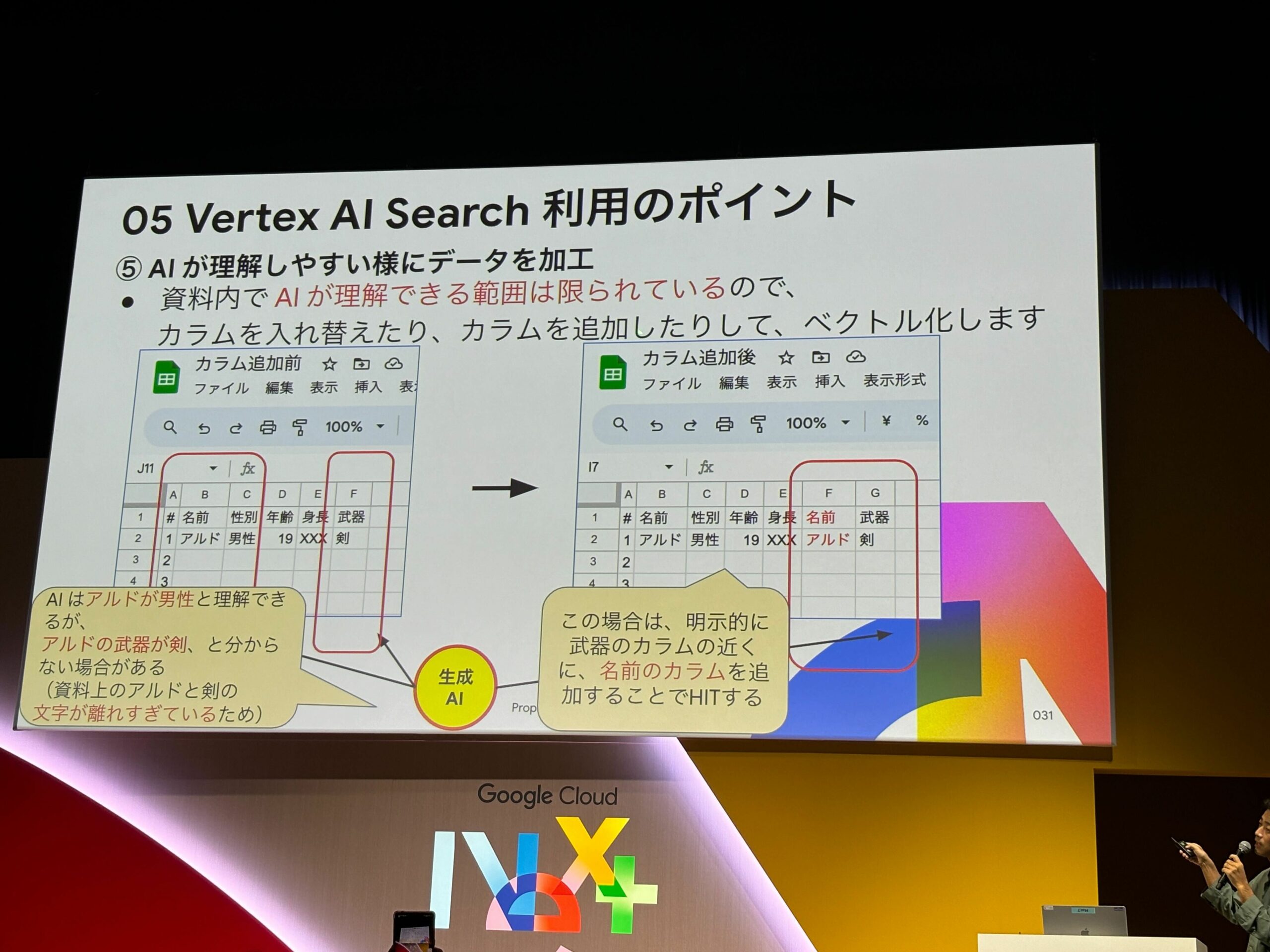
⑤AIが理解しやすいようにデータを加工する
資料内でAIが理解できる範囲は限られているので、カラムを入れ替えたり、カラムを追加したりして、ベクトル化を行う

⑥Vertex AI Searchで検索する前にユーザクエリを生成AIに補正・判定させる
質問文をVertex AI Searchに問い合わせる前に、生成AIに問い合わせて、文章の補正や判定をして検索のHIT率を上げる
これらのような点を開発する際のポイントとして抑えておきたいとおっしゃていました。
ブース・体験
・負荷分散を体験する

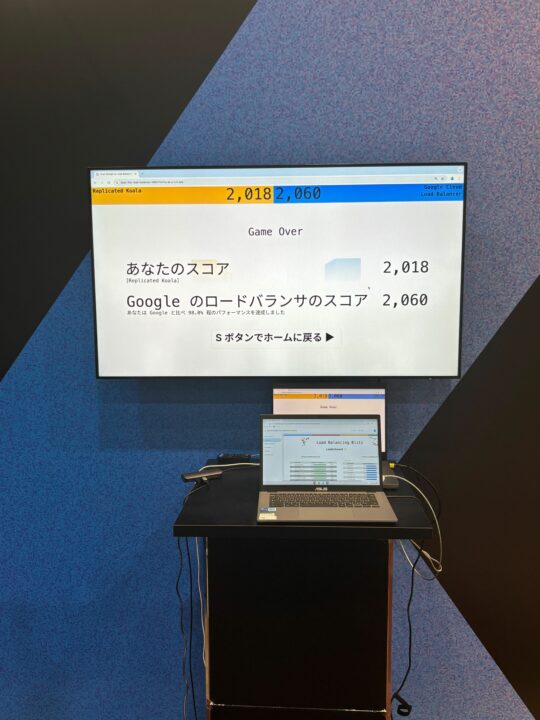
大量に流れてくるリクエストを手動でボタンを押して均等に処理し、Google Load Balancing と対決する体験をしました。
結果的には、惜しくも負けてしまいましたが、本来もっと大量なリクエストを処理していると想像すると、Google Load Balancingは恐ろしく、とても頼り甲斐があると感じました。
・GeminiによるAIゴルフコーチ体験

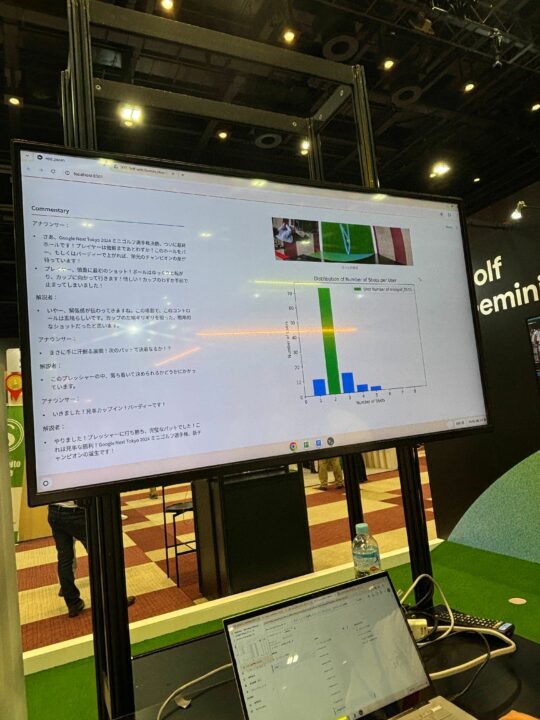
Cloud Functionが動画を分析し、Geminiが解説を生成してもらえるという体験でしたが、ただの解説ではなく、アナウンサーと解説者がコメントをし、実際に大会に出てるような解説でした。また、軌道や自分の向きなどを確認できるため、かなり実用的で興味深い体験でした。
終わりに
初めてのGoogle Cloud Next Tokyo でしたが、とても面白い体験ができました。また、プロジェクトでVertex AIを使用するので、知見としてとても勉強になりました。しかし、他のセッションでは、まだ知識量が足りなく、理解には及ばない箇所がありましたので、この1年間でレベルアップし、来年のGoogle Cloud Next Tokyoでは、どのようなGCPを扱っているのか理解しながら聞けるように、日々鍛錬していきます。楽しかったです。




