
概要
セッション名
Google Cloud で始める LLM Ops ~ RAG をどう評価するか ~ (D2-AIML-04)
損害保険ジャパン株式会社 眞方 篤史 氏
リスク管理が厳しい保険業界でどのようにLLMを活用されているのか。
また、RAGの課題と評価フローなど、精度の高いRAGアプリを本番運用する上で、必須の知識をお話しいただきました。
アジェンダ

背景
業務フローについて
画像の赤枠部分をRAGで対応する部分。
- 代理店からの問い合わせ対応
- 1日あたり53分
- 営業店からの問い合わせ件数
- 年間約40万件

実際の問い合わせ例
飛石という普段耳にしない言葉など、業界の特殊な用語などもある。
今回は、画像のFAQをドキュメントとしてLLMに渡してる。

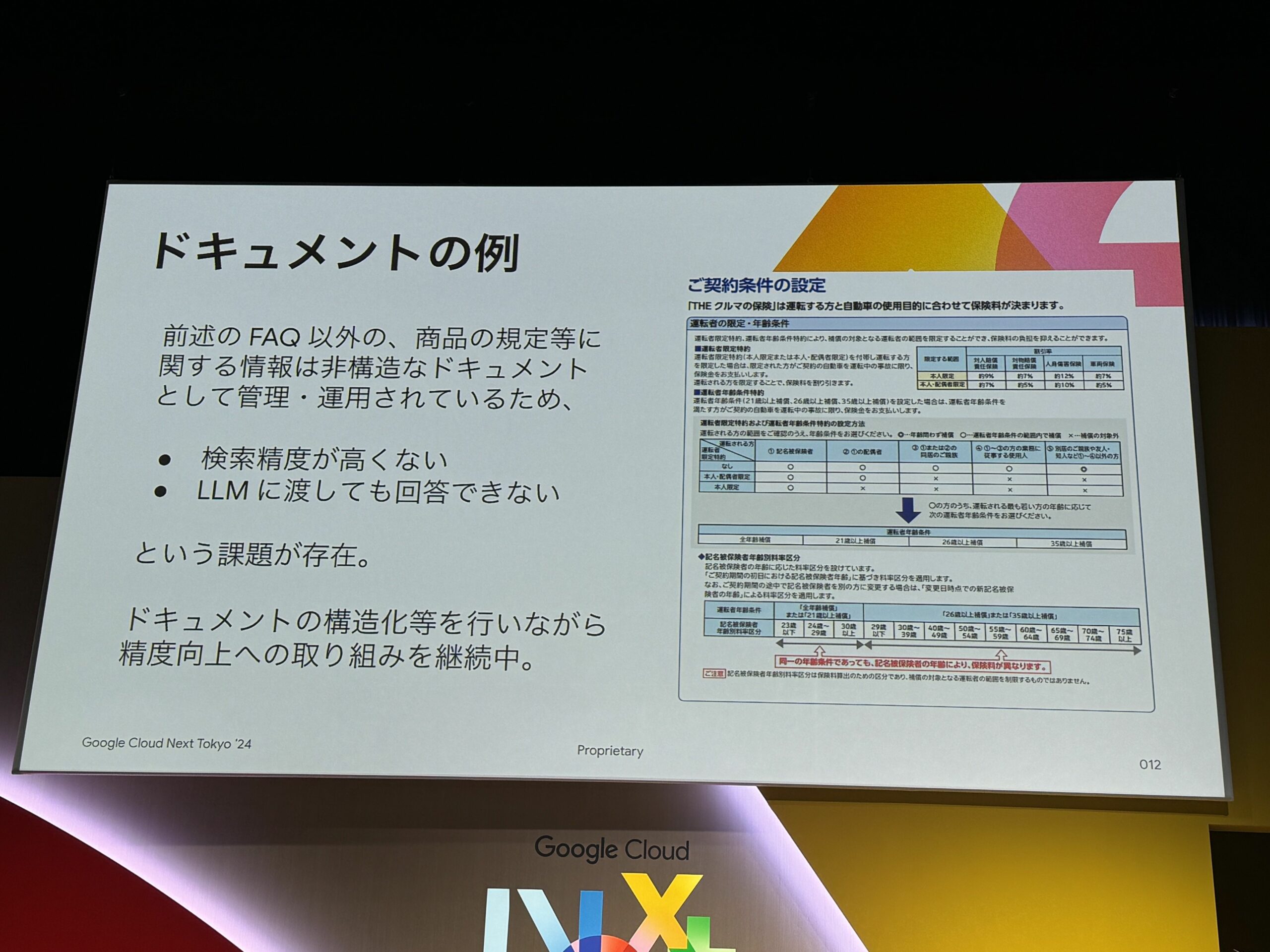
実際のドキュメントの例
先ほどのFAQ以外にも、様々な非構造データがある。
また、下記画像の通り、1ページにテキストやイメージなどがあるが、
それぞれを組み合わせて理解させる必要がある。
非構造データをMarkdownで構造化ドキュメントとして扱っている。
現在も日々精度改善を進めている。

課題
RAGの課題
- そもそもユーザ自身が何を聞けば良いか分からない
- 実際の人間の担当者であれば、質問を繰り返すことによって、ユーザ自身のニーズを引き出すことも可能だが…
- 回答としても、明文化されていないこと、暗黙知を考慮できない場合がある
- 誤った回答を生成するリスクを今日できない
- 法律的なこと、金銭的なこと、など
- LLMに100%の精度はどこまでいっても無理
- こういう場面でLLM使用したいのであれば、人間の回答補助に使用する
- human in the loop
- 回答精度が低い
- 一口に回答精度が低いと言っても原因特定が難しい
- 質問の方法が悪い?
- LLMが悪い?
- 読み込ませているドキュメントが悪い?
- など
- 定量的な評価が難しい
- 意思決定や改善プロセスに使用しづらい
- なんとなく感覚値で回答が正しそう…となりがち
- 自動評価システム・プロセスなどの構築が必要

LLM Opsとは
LLMを運用していく中で必要なこと。
前述の評価の部分は、まさにLLM Ops。

LLMを評価するための指標と対象
画像のものは、一般的によく用いられる評価指標。
- Correctness
- Factuality
- Harmfulness

上記3つのうち、今回は Correctness と Factuality を評価指標として選択。
下記のマトリクス図は、どのパターンが精度改善の必要があるかを表したもの。
「回答として正しくない」回答は、もちろん改善対象である。
ただ、「回答として正しい」が、「根拠に基づいていない」回答も、偶然正しい回答をできたに過ぎないため、改善対象である。(再現性が低い)

LLMを評価する軸
- 人手での評価
- 機械的な評価
- LLMでの評価
上記3つのうち、今回は LLMでの評価 の話

LLM as a judge
今回の画像の例は、単純にしている。
LLMはこのレベルの矛盾は少ない。


LLMに評価させるために、評価用のプロンプトが必要。
下記画像のInstructionの部分。


Few-shot examplesで、精度改善の傾向があった。

アーキテクチャ
選定時の考慮ポイント
- 通常のワークフローとは切り離したい
- 評価用、回答用のモデルは分けたい
- 同じモデルで評価すると、過剰に良い評価をする傾向がある
- 評価フローはカスタマイズしたい

実際のアーキテクチャ
LLM Opsの基盤として、BigQueryを使用。
主な理由は、OSSの評価ツールも多いが、今回は評価自体シンプル。
なおかつ、BigQueryは、セマンティックサーチにも成熟しているため。

下記の画像が、最終的なアーキテクチャ。
評価用のプロンプトテンプレートは、Cloud Functionsに格納。
また、評価関数Aの評価結果をBigQueryに格納。
評価結果格納の際には、ベクトルも一緒に保存して次回の評価に使用できるようにしている。
そして、今後は、Lookerにてダッシュボード作成予定。
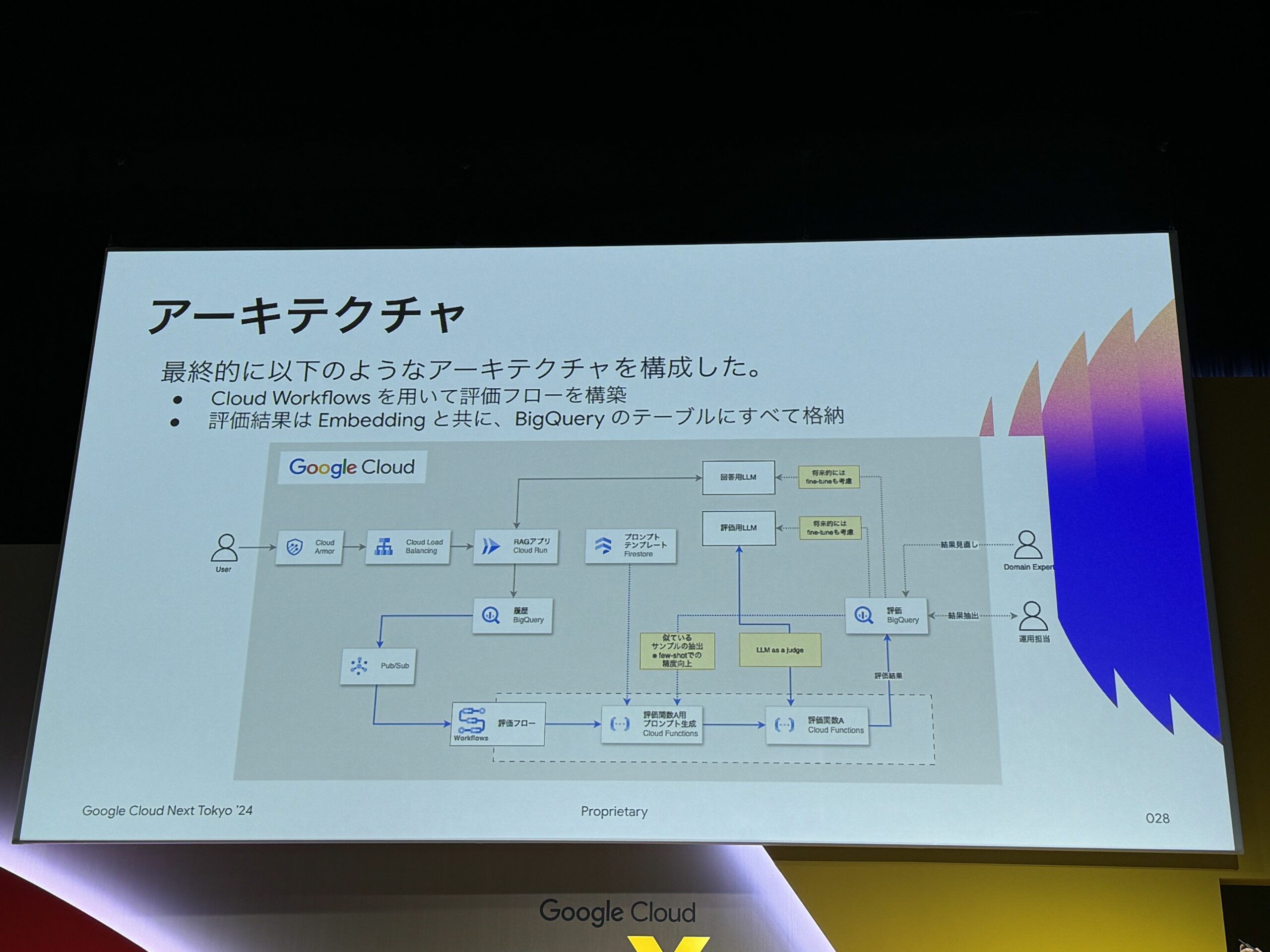
評価のフローは、Cloud Workflowsで
- プロンプト生成
- また、今回Few-shot examplesでプロンプトを生成するようにしている。
- 必須ではないが、精度向上が期待できる。
- また、BigQueryではクエリ取得しやすい。
- 評価実行
- 書き込み

結果
評価条件

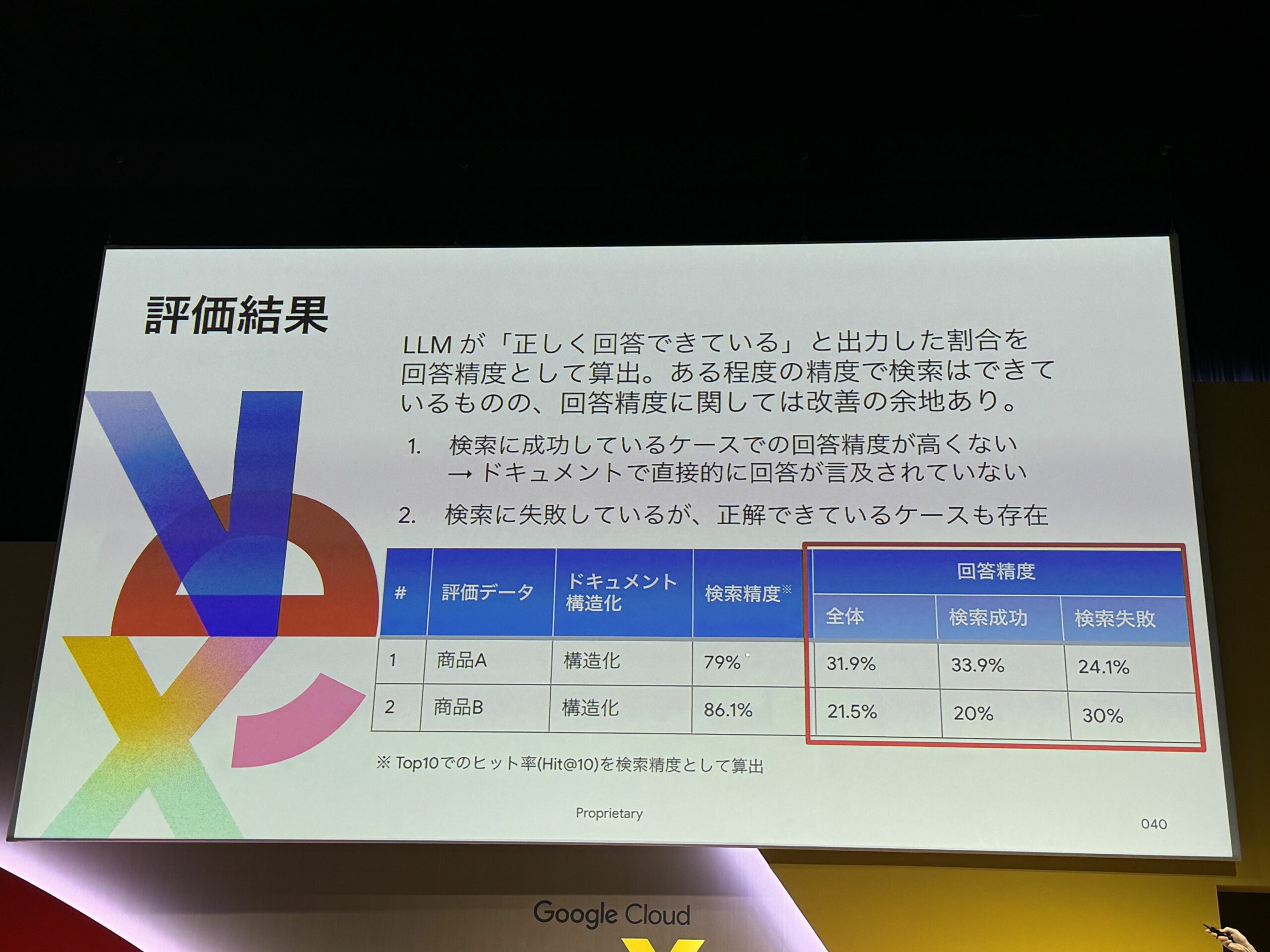
評価結果
検索精度は8割程度。
ただし、回答精度は芳しくない。
検索成功・失敗でそんなに精度が変わらない。
今までは、検索に注力をしていて、回答生成のチューニングはこれから。
また、LLM側の原因として考えられるのは、LLMに2値で回答させているため、
ランダムになる可能性考えられる。とおっしゃっていました。

サマリ

この記事のまとめ
RAG構築して精度改善を行うための具体的な方法が目から鱗がポロポロでした。
評価することで、検索・生成どちらに問題があるのかも明確になる。
よって、数ある改善手法をやみくもに試すのではなく、焦点を絞って改善を進められる。
RAGを構築する際に、必須の取り組みですね。




