
概要
この記事は、以下のアイレット社内の導入事例の技術解説記事です。
事業部ごとの勤務状況を可視化し、データドリブンな労働環境改善が可能に!Looker を活用した勤怠管理・分析システム開発
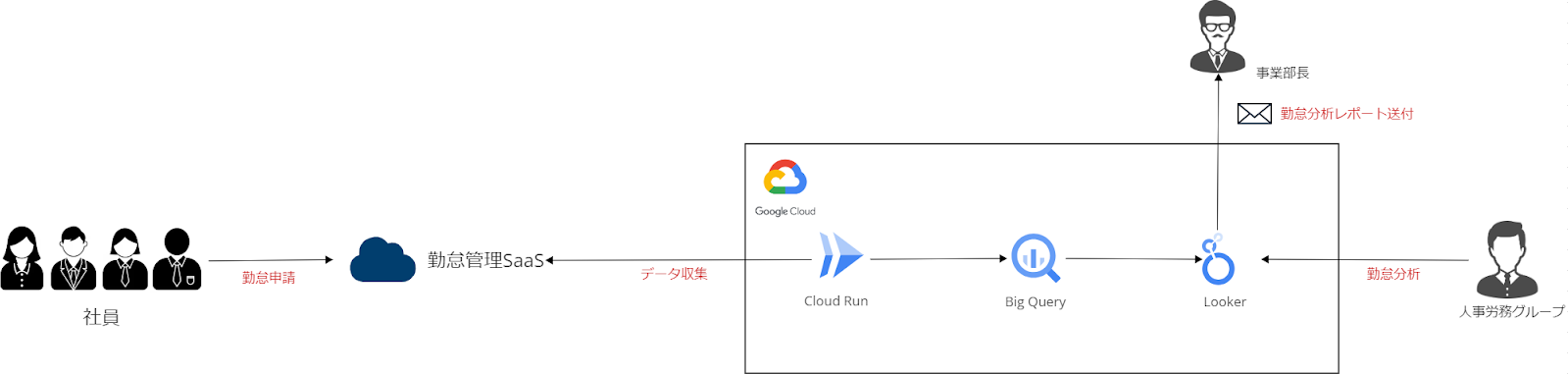
構成の全体像
まず、本構成の全体像ですが、
Google Cloudではスタンダードかつ、シンプルなデータ分析基盤です。
データの流れはバッチ処理で取得し、BigQueryをDWHとし、Lookerにてダッシュボードを作成しています。
本構成のコンセプトは、「シンプルな実装」「高い拡張性」であり、
また、サーバレスサービスを多く使用しているため、管理コストが少ないのもポイントです。
構成図 (簡易)
構成詳細
Google Cloudサービス
Google Cloudサービスは以下を利用しています。
以降、主要サービスのみ、ポイントを解説していきます。
- Cloud Run Functions (旧 Cloud Functions)
- BigQuery
- Looker
- Cloud Scheduler
- Cloud Storage
Cloud Run Functions (旧 Cloud Functions)
Cloud Run Functionsの主な役割としては、2つあり、データ取得・データ保存です。
役割を2つにしている理由としては、1 Functionに、1 機能とし、所謂単一責任な実装としています。
データ取得
実際にSaaS APIからデータを取得する処理を行っています。
今回は、データ取得&前処理がとてもシンプルであるため、Cloud Run Functionsのみで行っています。
取得したデータはCloud Storageに保存しています。
一度、Cloud Storageに保存することで、以降のデータ保存の再試行ロジックなどを制御しやすくしています。
データ保存
こちらは、Cloud Storageのバケットにデータが作成された際に、BigQueryのテーブルにinsertします。
Eventarc トリガーとしています。
Pub/Subなど別の機構が不要で簡単にイベント駆動を構築でき、今回のコンセプトである「シンプルな実装」を実現できます。
イベント駆動にすることにより、機能同士を疎結合にでき、拡張性、メンテナンス性などが向上します。
(参考)公式ドキュメント
https://cloud.google.com/eventarc/docs/run/create-trigger-storage-gcloud?hl=ja
BigQuery
SaaS APIから取得したデータは、できるだけそのままELTとして、テーブルに保存しています。
理由としては、ダッシュボードの連携先として、Lookerを使用しており、その際に自由に作りやすいように、データ自体はあまり加工せず保存しています。
BigQueryでは、SQLなどを利用することでデータ変換などを簡単に実行できるため、ETLとしないことで、データ保存量の圧縮などにも繋がります。
また、当初の課題の1つとして「組織構造の管理」があったため、組織構造をマスタテーブルとして作成し、組織変更にも強い仕組みとしています。
また、今後、データソースが増える場合でも、BigQueryは、Google Cloudの他サービスとシームレスに連携しやすい、
かつ、BigQuery Omniを利用することで、マルチクラウドなアーキテクチャも実現しやすいのも魅力です。
(余談ですが、大規模な分析の場合でも、Bigtableなどと組み合わせることで、高速にシームレスなクエリが可能です)
Looker
Google Cloudでは、言わずと知れたスタンダードなBIツールであるため親和性が高いことはもちろん、そもそもアイレット内部で利活用されているためナレッジも溜まっています。
使い慣れたツールのため導入コストが低いというのもあり、Lookerをダッシュボードとして採用しています。
また、Looker Extensionを使用し、Geminiでのアシスト機能を入れています。
Geminiアシストにより、データからのインサイト取得などを効率化をすることが可能です。
(参考)公式ドキュメント
https://cloud.google.com/looker/docs/extension-overview?hl=ja
まとめ
Google Cloudを利用することで、シンプルで拡張性の高い分析基盤をスピーディに届けることができました。
また、サーバレスサービスも多く、管理コストがかからないため、人間にもやさしい作りを実現できます。
