
はじめに

イベント情報
| イベント名 | Datadog Summit |
| 開催日時 |
2024年10月16日(水)
|
| イベント開催時間 | 10:00〜17:00 |
| イベント会場 |
赤坂インターシティコンファレンス AICCホール&カンファレンスホールA
東京都港区赤坂1-8-1 赤坂インターシティAIR 4F
|
| 公式サイト | https://www.datadoghq.com/ja/summit/tokyo24/ |
アジェンダ
ワークショップ概要
APMってなに?
オブザーバビリティってなに?
「オブザーバビリティ(Observability)」とは、システムやアプリケーションの内部状態を外部から観測可能にすることです。
「オブザーバビリティ(Observability)」を向上させることにより、開発者や運用チームはパフォーマンスの問題を早期に発見し、効率的に対策することができるため、アプリケーションの信頼性とパフォーマンスを向上させることが可能です。
オブザーバビリティには以下の三つの柱があります。

- 1. メトリクス (Metrics)
メトリクスは、システムやアプリケーションのパフォーマンスやリソース使用状況を定量的に測定したものです。
通常、数値として収集され、時間ごとに記録されます。メトリクスはパフォーマンスのトレンドを把握したり、異常を検知するために使われます。
例: CPU使用率、メモリ使用量、ディスクI/O、リクエストの処理時間、エラーレート
- 2. ログ (Logs)
ログは、システムやアプリケーション内で発生したイベントの詳細な記録です。
通常、タイムスタンプ付きで保存され、システムの状態やアクションを記録します。
ログはエラーや障害が発生した際に問題の根本原因を特定するのに不可欠です。
例: エラーログ、アクセスログ、デバッグログ、ユーザーアクションの履歴
- 3. トレース (Traces)
トレースは、リクエストがシステム全体をどのように通過するかを追跡し、特にマイクロサービスや分散システムで重要です。
分散トレーシングは、1つのリクエストが複数のサービスやコンポーネントを通過する際に発生する遅延や障害の箇所を特定するのに役立ちます。
ワークショップの進め方

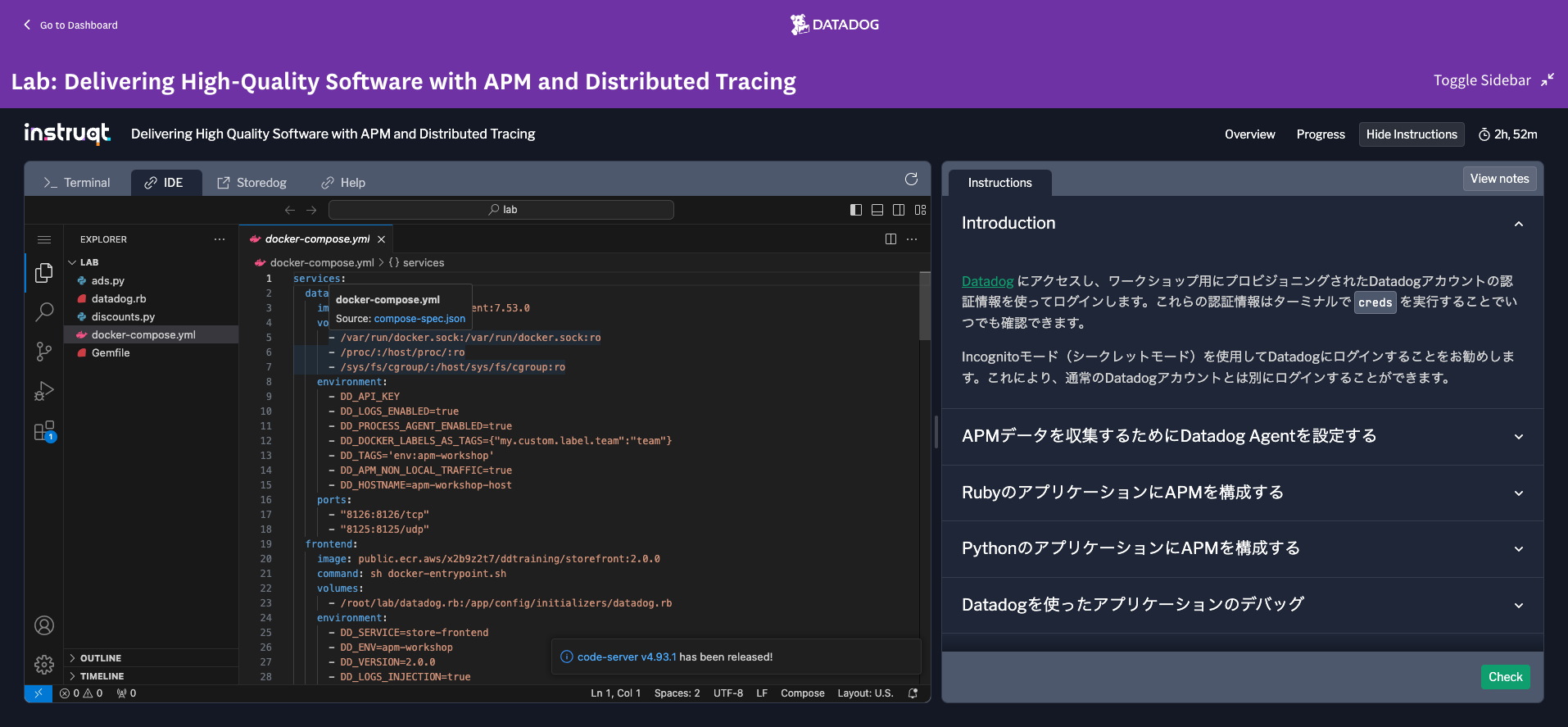
Datadog Agentの導入
datadog:
image: gcr.io/datadoghq/agent:7.53.0
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /proc/:/host/proc/:ro
- /sys/fs/cgroup/:/host/sys/fs/cgroup:ro
environment:
- DD_API_KEY
- DD_LOGS_ENABLED=true
- DD_PROCESS_AGENT_ENABLED=true
- DD_DOCKER_LABELS_AS_TAGS={"my.custom.label.team":"team"}
- DD_TAGS='env:apm-workshop'
- DD_APM_NON_LOCAL_TRAFFIC=true
- DD_HOSTNAME=apm-workshop-host
- DD_REMOTE_CONFIGURATION_ENABLED=true
ports:
- "8126:8126/tcp"
- "8125:8125/udp"
| DD_LOGS_ENABLED=true |
ログ有効化
|
| DD_PROCESS_AGENT_ENABLED=true |
プロセスエージェント有効化
|
| DD_TAGS=’env:apm-workshop’ | Datadogのenvタグを設定 → 閲覧するデータをフィルタリングできるようにするため |
| ports: |
トレースライブラリからのトラフィックを許可するポート
|
アプリケーションの動作を監視するための仕組み(APM)を設定する
Datadog.configure do |c|
c.tracer enabled: true
# This will activate auto-instrumentation for Rails
c.use :rails,
service_name: 'store-frontend',
cache_service: 'store-frontend-cache',
database_service: 'store-frontend-sqlite'
c.use :active_record,
service_name: 'store-frontend',
orm_service_name: 'store-frontend'
# Make sure requests are also instrumented
c.use :http,
service_name: 'store-frontend'
end
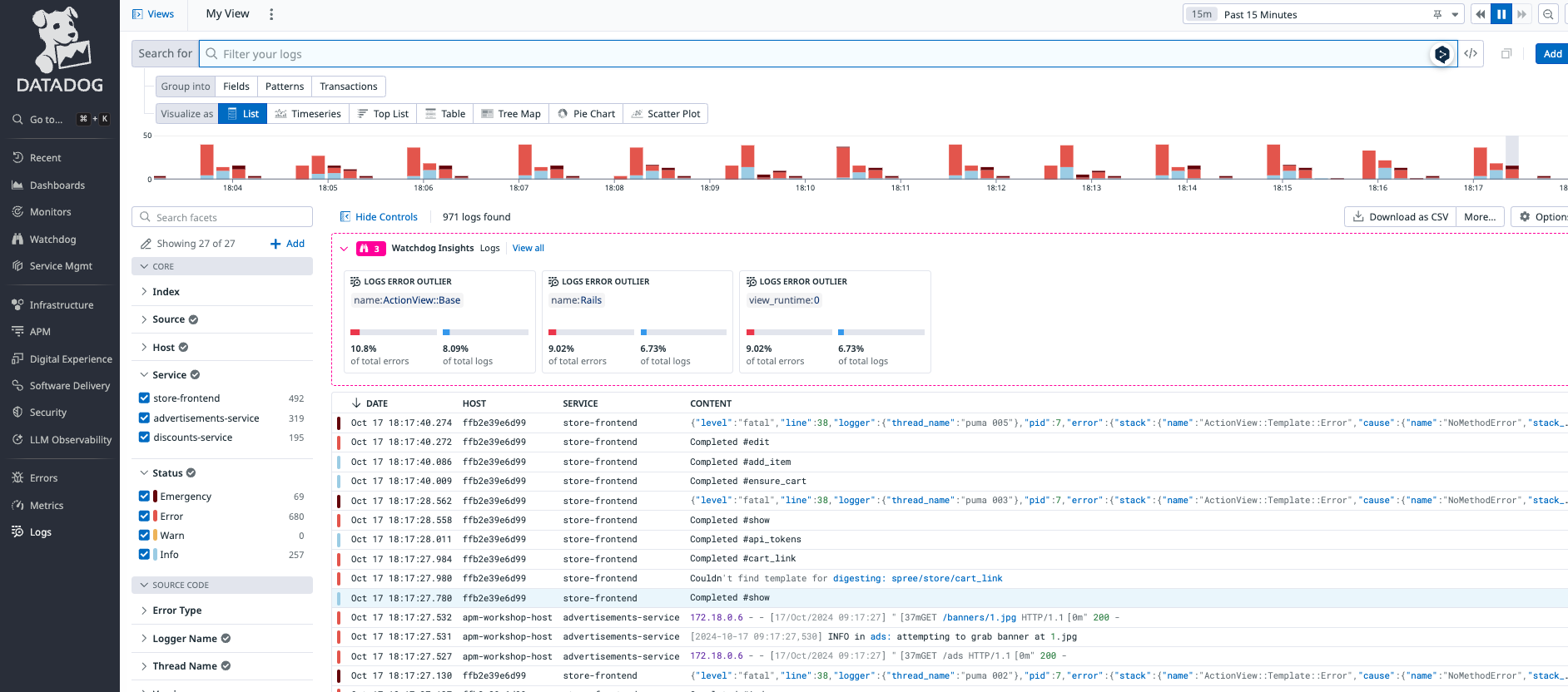
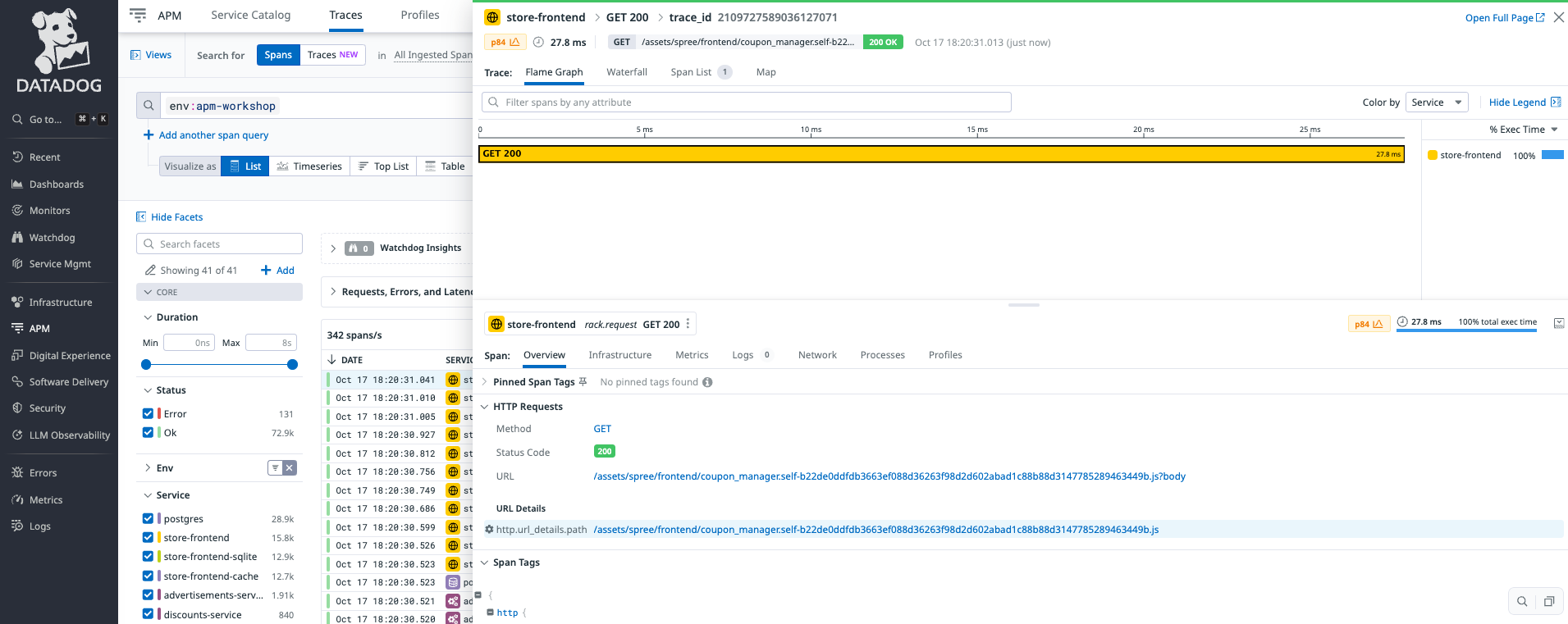
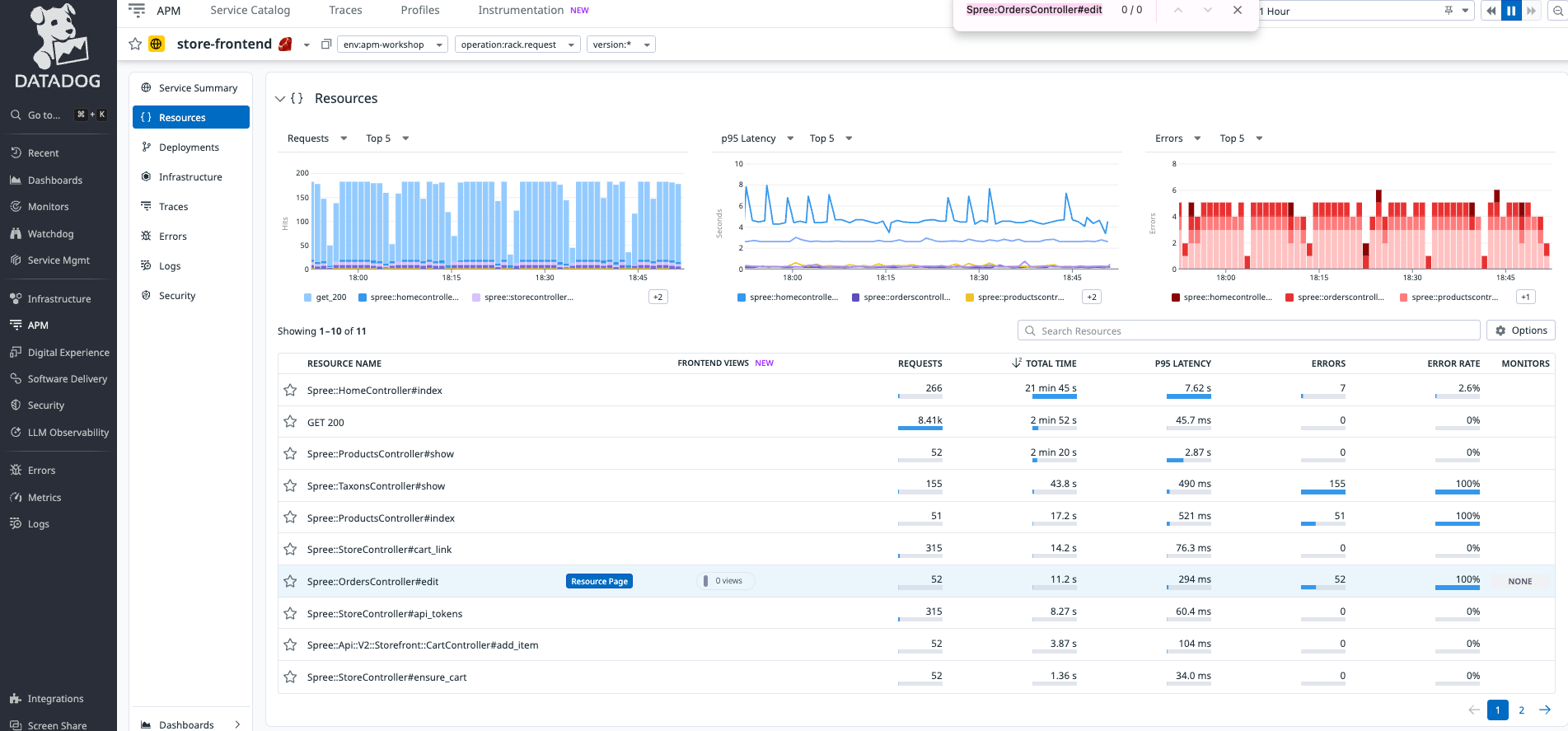
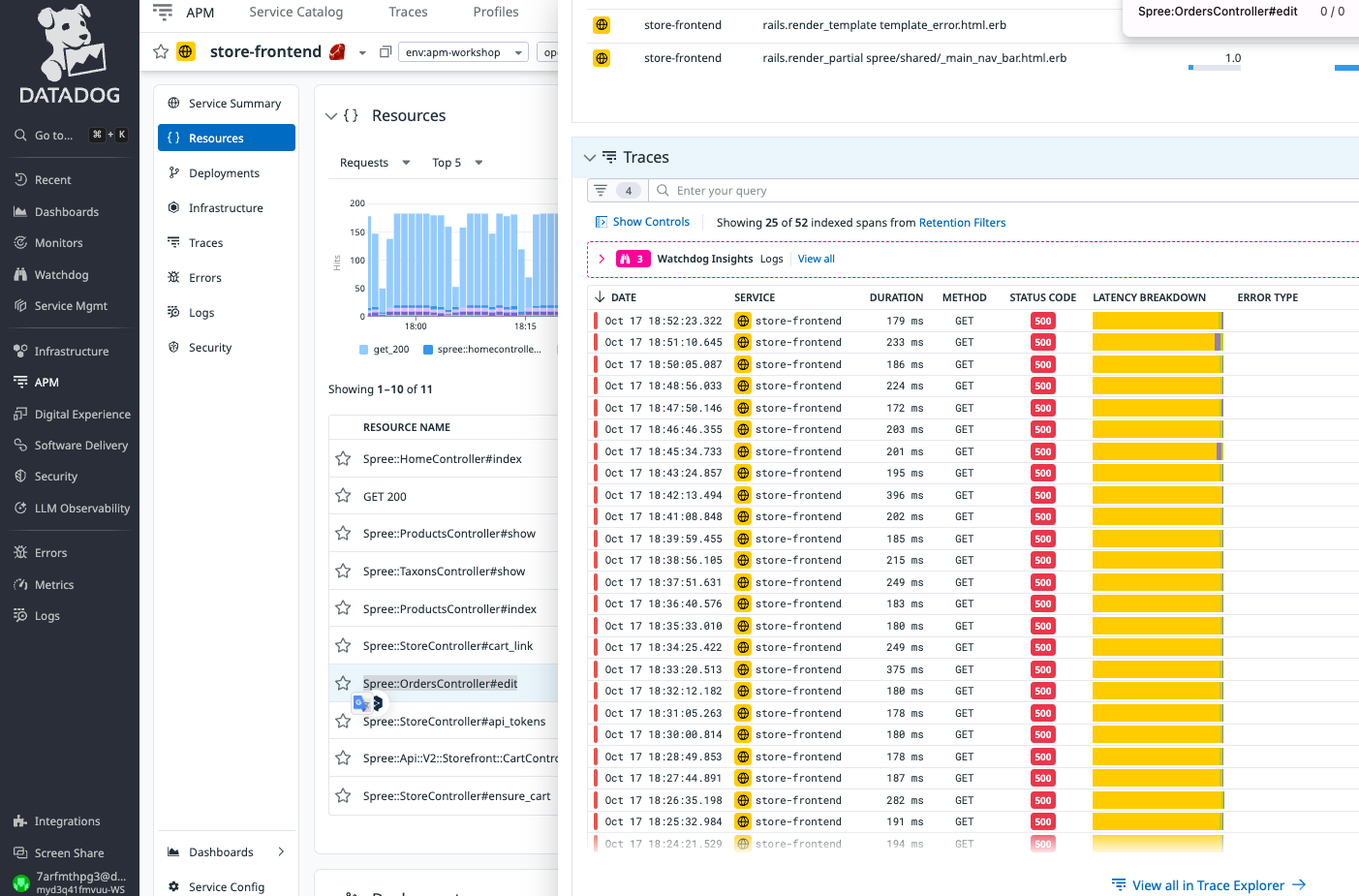
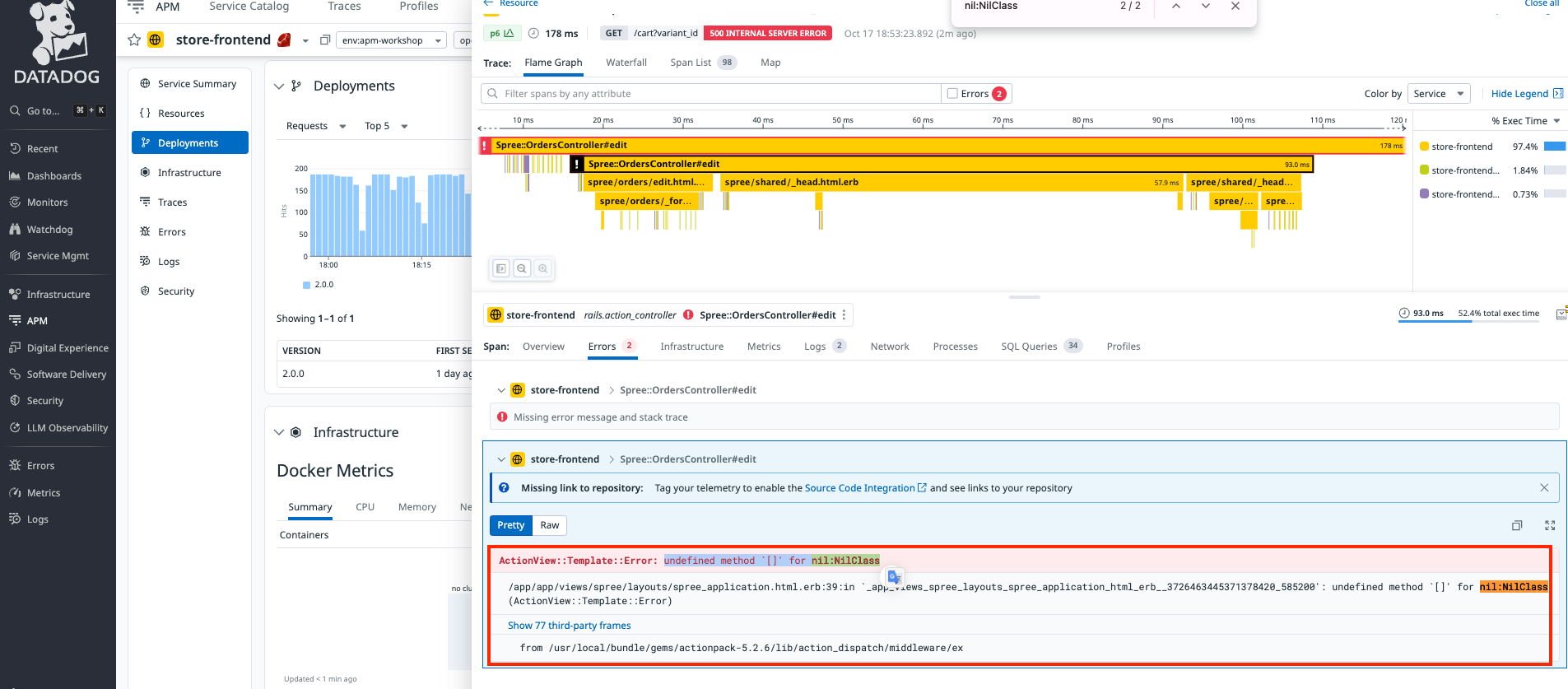
Datadog APMを活用したアプリのデバック
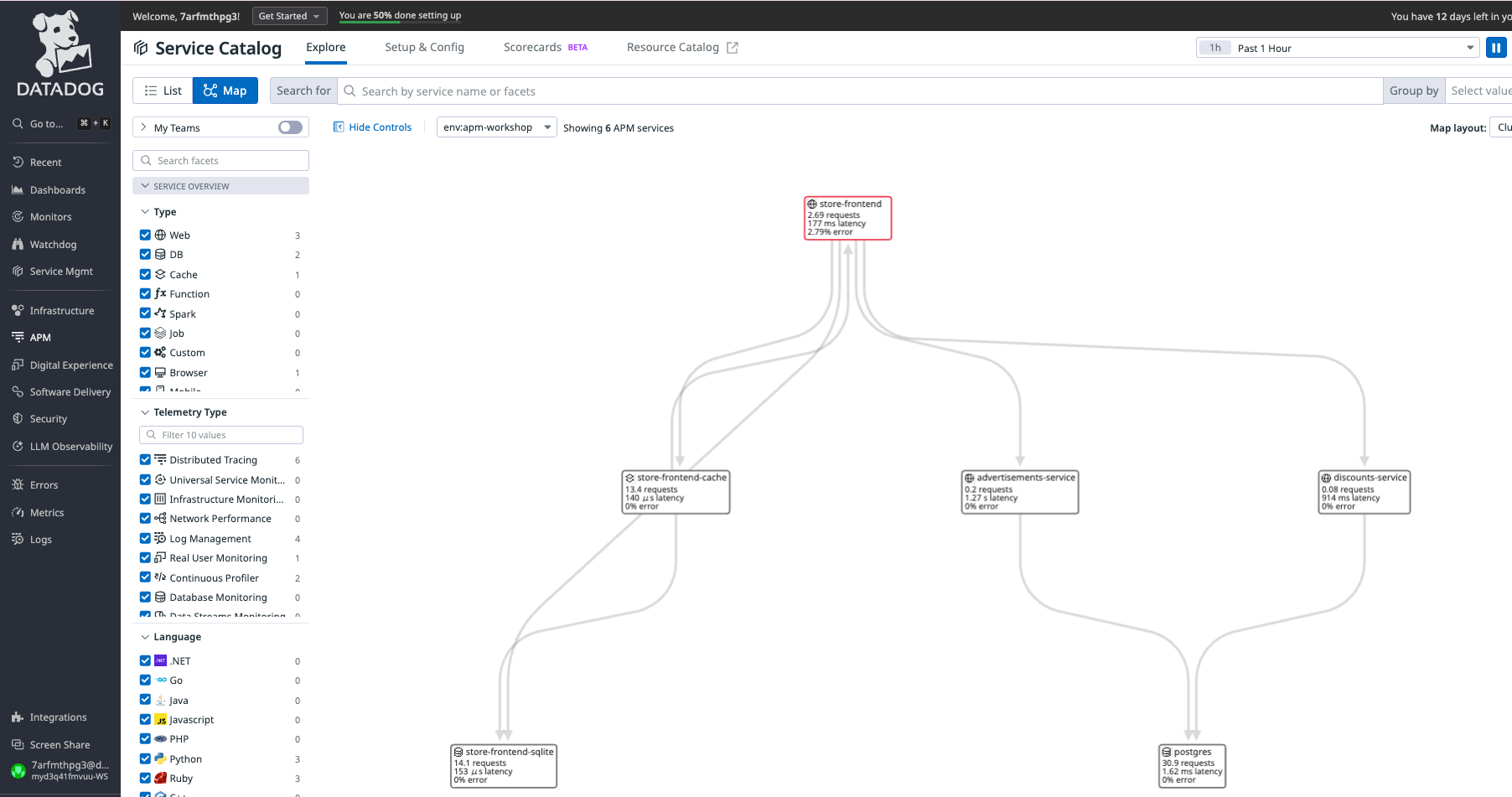
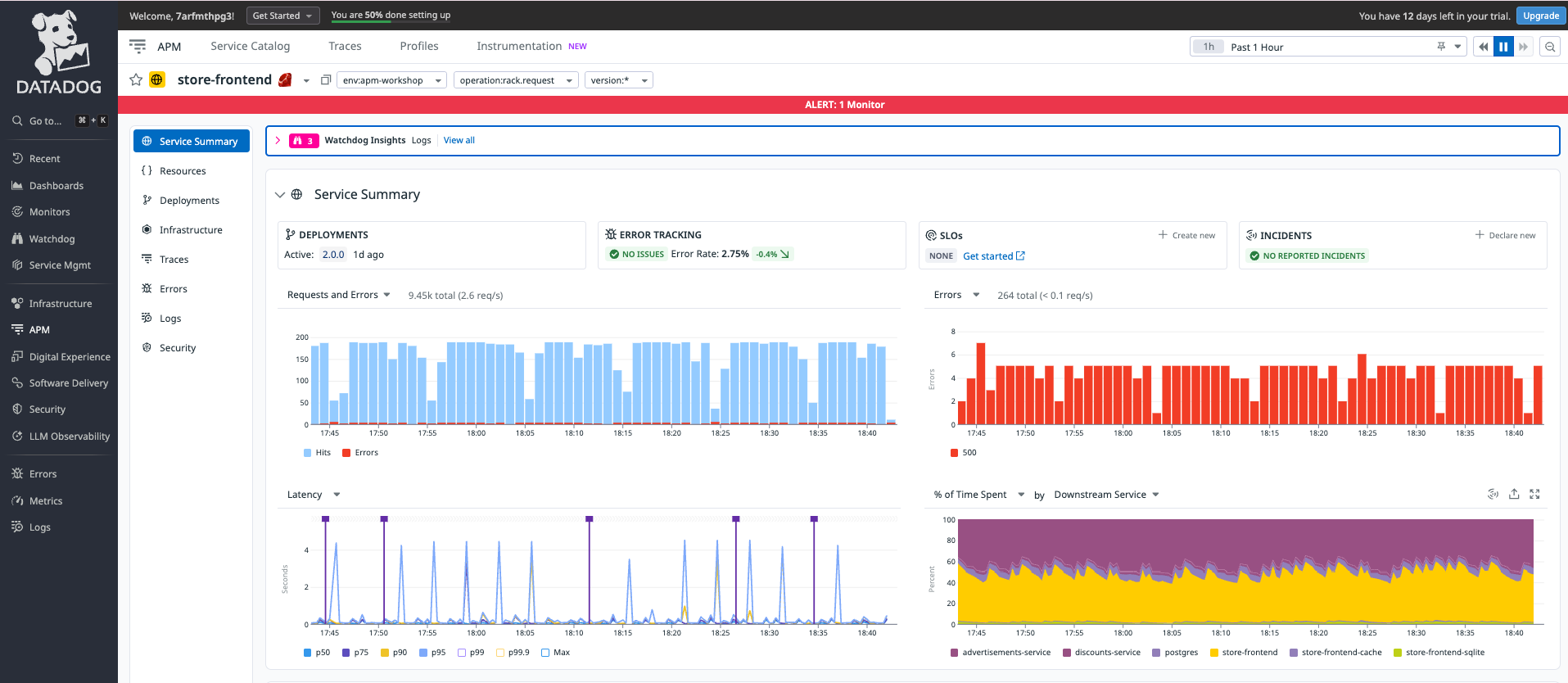
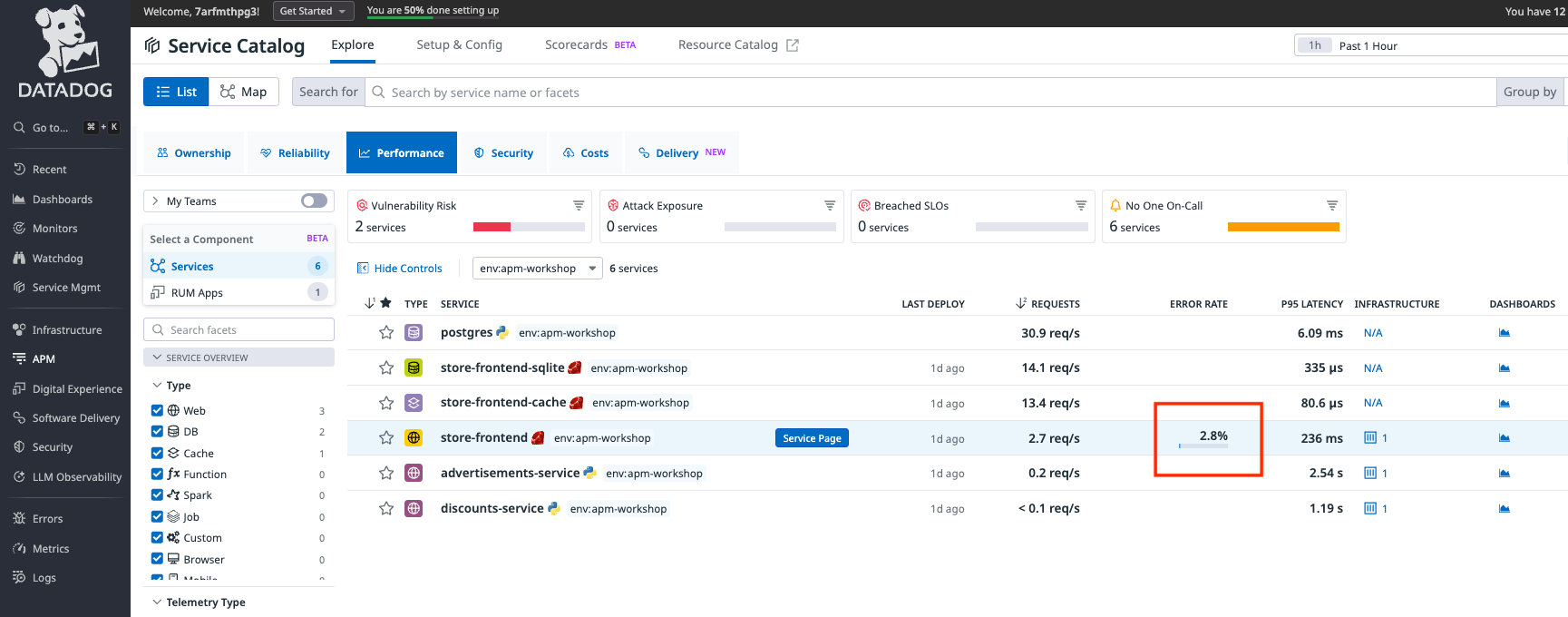
サービスの一覧画面(List)
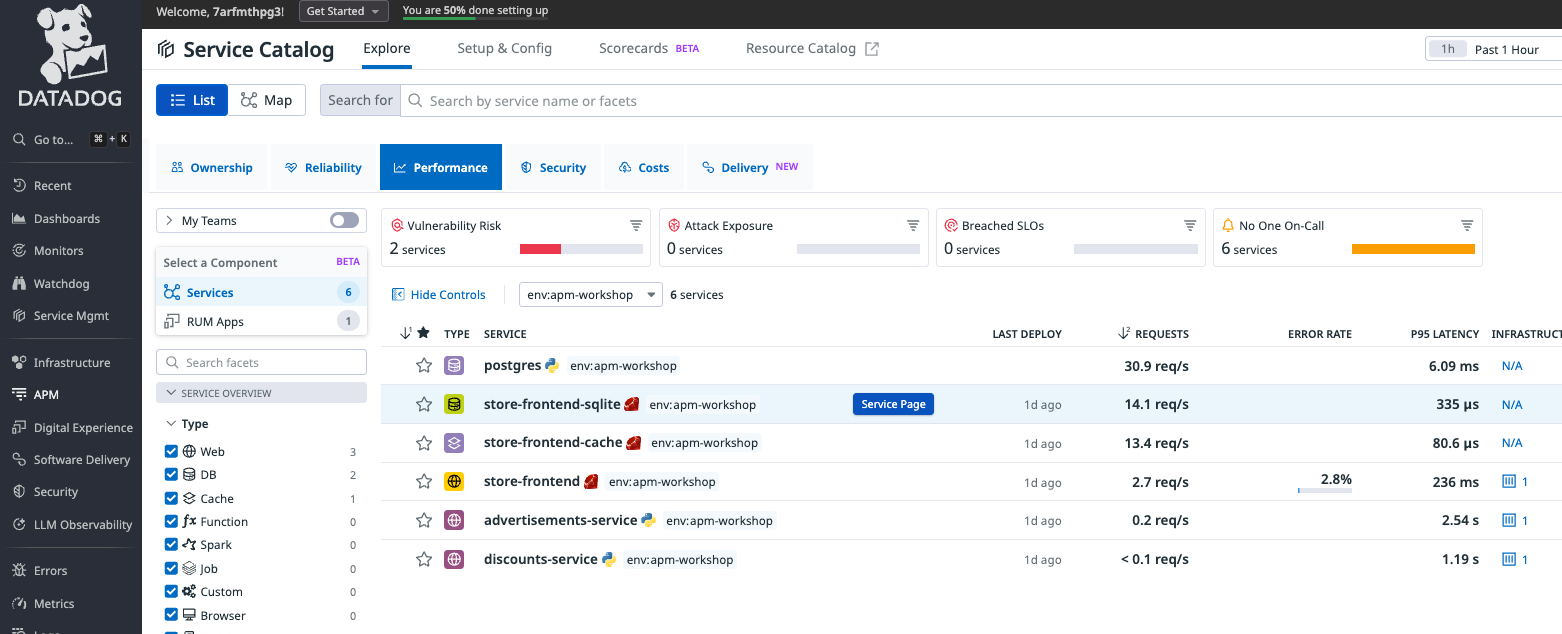
各メトリクスを確認
最後に
弊社は、PagerDutyやAMS、オブザーバビリティツールなどを用いた次世代監視基盤と24/365の体制での運用保守サービス、およびSaaSの調達から運用高度化の支援まで幅広いサービスを提供しています。ぜひ一度ご相談ください。
お問い合わせはこちらから

