
はじめに
Ingest Data(取り込みデータ)は New Relic のコストと運用品質を最も左右します。
取り込み量が増えるほど見た目は豊かになりますが、不要データが混ざると判断が鈍り、費用も膨らみます。
本ガイドは、現場で回しやすい最小構成を 見える化 → 入口で落とす → 保持調整 → 運用 の順でまとめたものです。
Ingest Dataとは?
New Relic に取り込む メトリクス / イベント / ログ / トレース(スパン) の総称です。
価値は「たくさん入れる」ではなく「必要十分だけ入れる」で決まります。
つまり、(1) 現状把握、(2) 入口での抑制、(3) ビジネス要件にあわせた保持期間の調整、が肝になります。
設計方針
- 見える化:Usage データで全体と内訳、今月見込みを把握。
- 入口対策:Pipeline Control(Cloud/Gateway ルール)で不要ログを削減。トレースは送信側(エージェント / OTel)でサンプリング。
- 保持調整:Retention は短めに。監査や証跡は Logs Live archives に分離。
- 運用:月次レビューで増やさない仕組みを継続。
1. 見える化:Ingestの“見取り図”を出す
まず取り込み状況を数値で把握します。以下をそのままコピペで使えます。
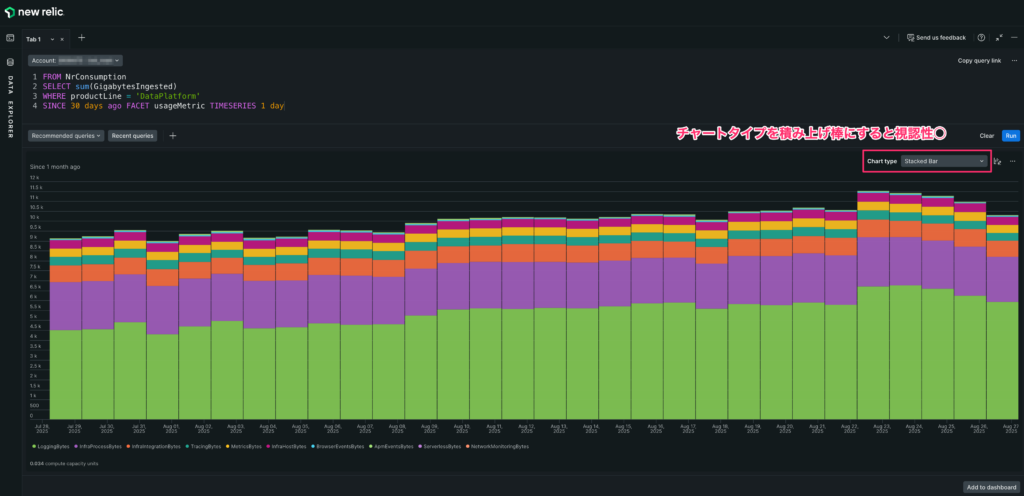
Tip: Usage は傾向把握用途です。請求は課金画面/明細を確認。急増検知のアラートは「Event timer」集計が安定です。
2. 入口対策:不要データを“入れない”
先に痩せる化。副作用が少ない順に進めます。
2-1. ログは Pipeline Control で入口ドロップ
- Cloud ルール:New Relic 側で実行。短時間で全体に効かせられます。
- Gateway ルール:自社ネットワーク外へ出る前に抑止したい場合に有効。
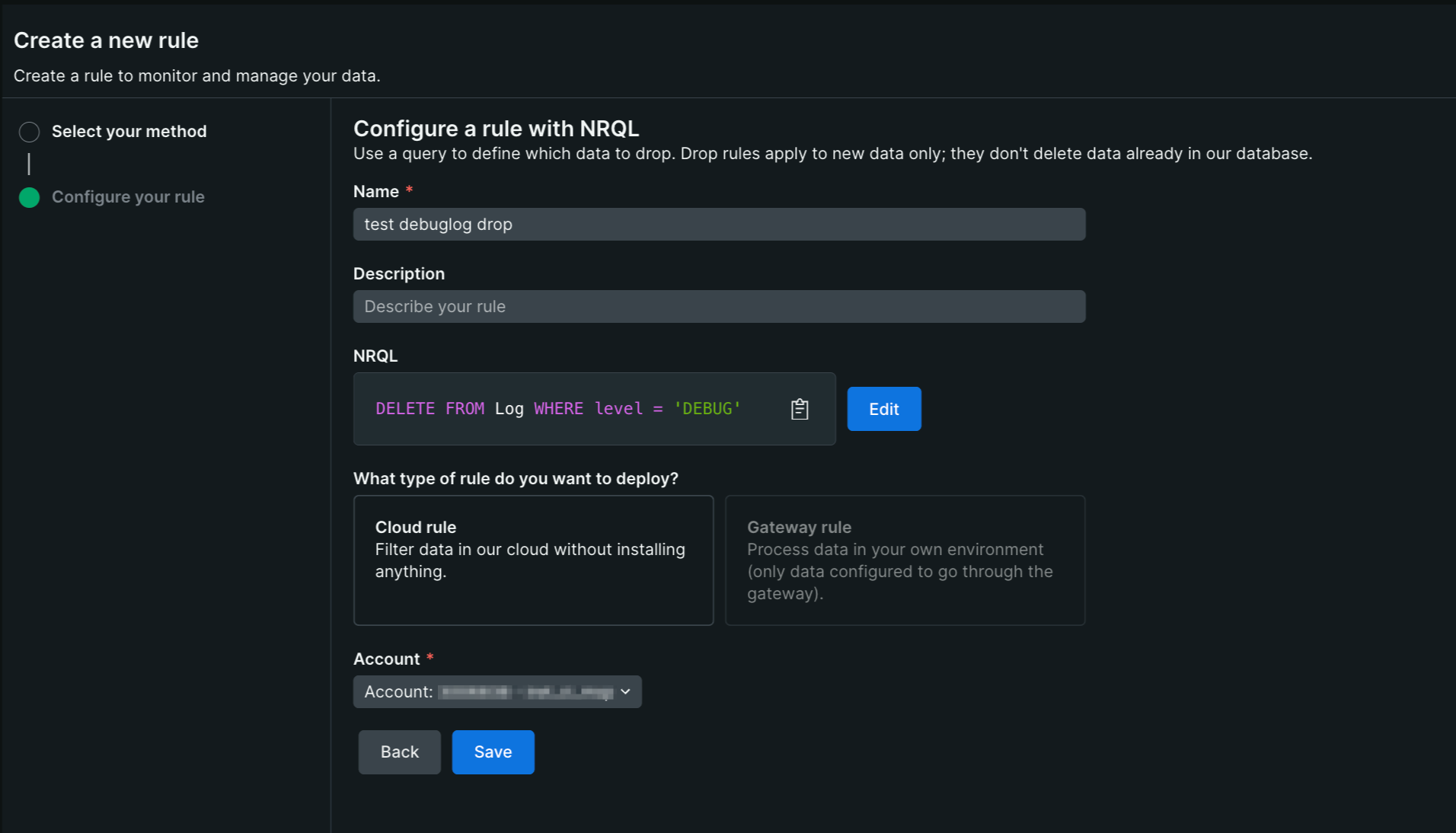
注意: 適用後に到着した対象データは保存されません(復元不可)。
まず検索で命中条件を確認し、限定スコープで段階的に適用してください。旧来の NRQL Drop ルールが残っている場合は、計画的に Pipeline Control へ移行します。
コストの考え方(Compute / CCU の要点)
- Advanced compute(CCU):New Relic がデータを処理・変換・評価する際に使う計算リソースの課金単位。保存量(GB ingested)とは別軸で計上されます。
- Core compute:ダッシュボード表示、クエリ実行などUI 操作系で消費する CCU。Pipeline Control の一部 UI 操作はここに含まれます。
Pipeline Control 特有の計上
- Gateway ルール:ゲートウェイが受け取った 非圧縮GB が Advanced compute に計上(ドロップしても受信分は対象)。
- Cloud ルール:削除されたGB と スキャンしたイベント数 が Advanced compute に計上。
- Ingest 課金:最終的に NRDB に保存されたサイズのみが GB ingested に計上。
参考:How New Relic pricing works(Compute の整理) /
Pipeline Control のコスト(Cloud/Gateway の計上内訳)
2-2. トレース/スパンはサンプリング前提
- 送信側で制御: まずは APM/OTel など発生源でヘッドサンプリングを設定します。トレースの連続性を保ちやすく、後段の近似ドロップによる“鎖切れ”を避けられます。
- 比率の決め方: 影響の大きい系(例:フロント/課金)は 50–100% を目安、周辺・バッチは 5–10% 程度に抑えるなど、役割ごとに明示します。
- 計測・監査の扱い: SLO/KPI や監査に使う経路はサンプリング対象から外すか、別メトリクス/ログで補完します。
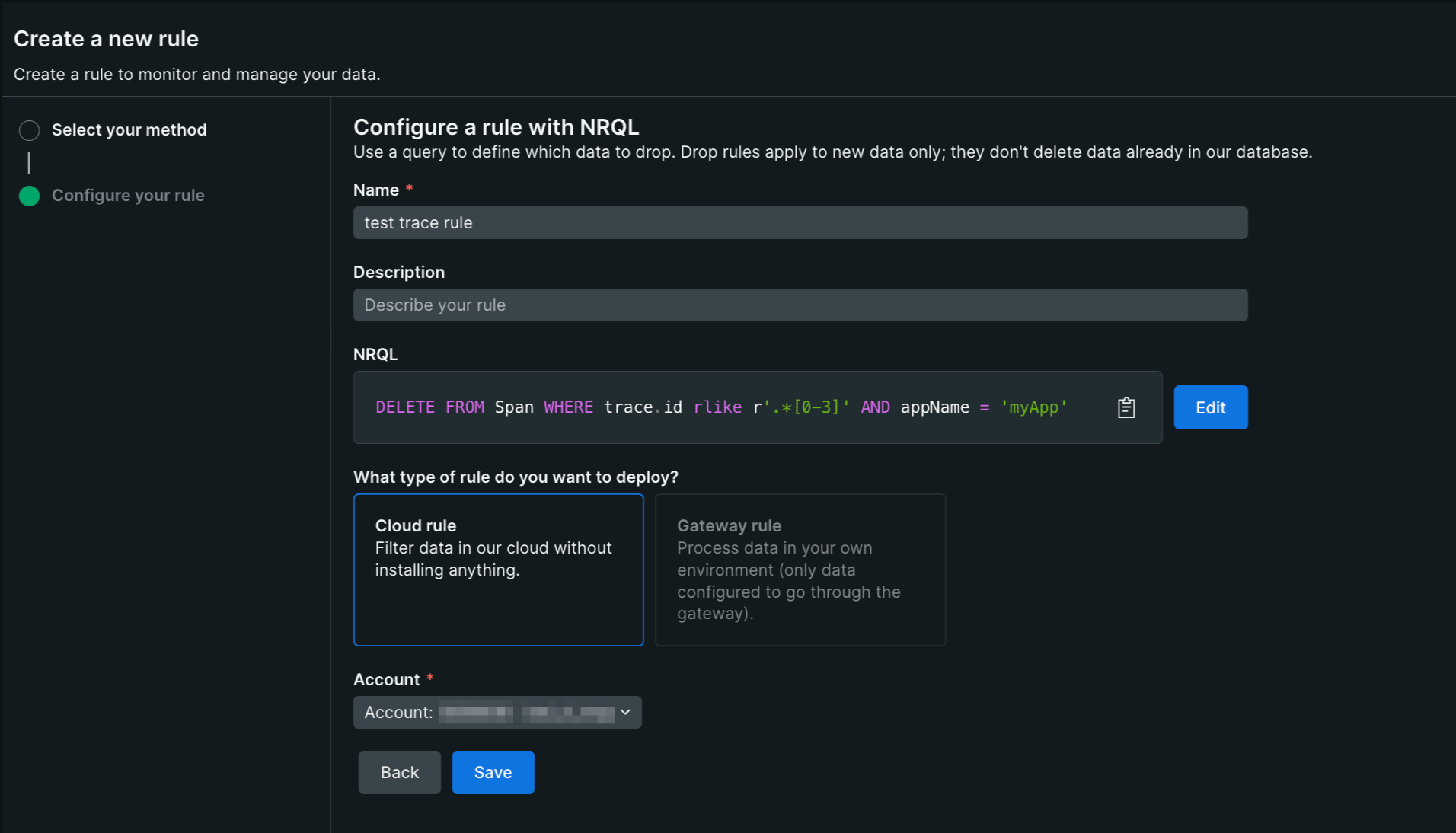
注意: 上記は近似的な間引きであり、トレース全体の一貫性は保証されません。完全な分析が必要な場合は送信側でのサンプリングを優先してください。
3. 保持と長期保管(費用 × コンプライアンス)
保持日数は Data retention で制御し、ログの長期保存が必要なら Logs Live archives(オプトイン)を併用します。
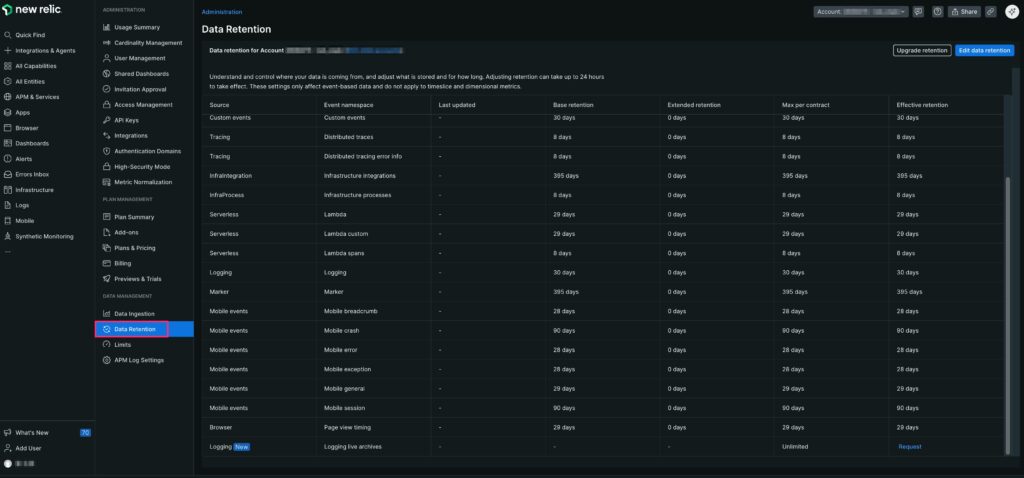
3-1. 設定画面の開き方(Data retention / Live archives)
- 右上のアカウントメニュー → Administration
- Data management から Data Retention
- Edit data retention でデータ型ごとに日数を入力 → Save
- Logging live archives はページ最下部から Request(初回申請)→ 承認後 Enable と保持「月数」設定
Tips: 変更の際には右上の Account ドロップダウンで対象アカウント/サブアカウントを確認を忘れず。反映には最大 24 時間程度かかります。
3-2. 保持(日数)の設定:Data retention
- 各データ型(Logs / Traces / Browser など)について必要な日数を入力し、Save を押します。
- 画面の Effective retention は契約上の上限などを加味した最終適用値です。入力値と異なる場合でも、実際に効くのはこの列の値になります。
- 保持の短縮は保存以後に取り込まれるデータから適用されます。過去データが延長・復活することはありません。
3-3. Logs Live archives(オプトインの長期保管)
Live archives はログの長期保管用ストアです。既定では無効のため、Data retention ページ最下部の
Logging live archives 行から申請・有効化します。
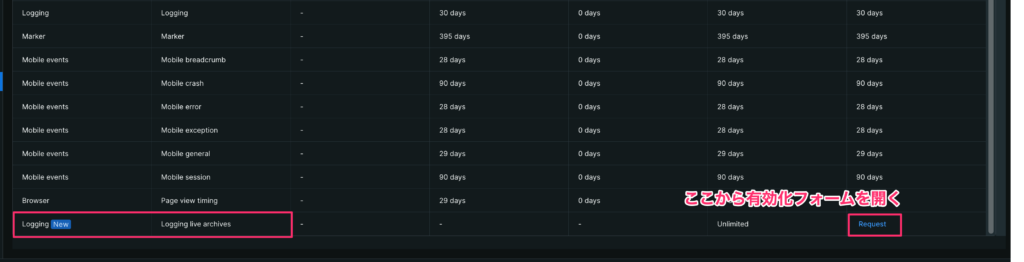
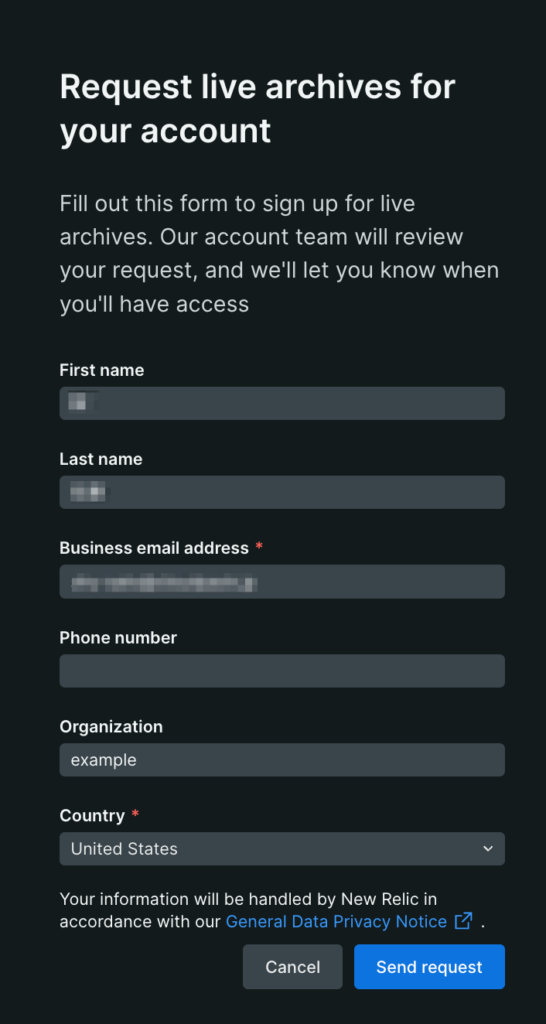
- Request をクリックして申請(連絡先・組織情報を入力)。
- 承認後に Enable を有効化し、保持「月数」(例:12 か月)を指定します。
- 以降、ホット保持(例:14 日)を過ぎたログが自動でアーカイブへ移動し、必要に応じて検索できます。
代表的な用途: 監査・法令順守・不正調査など、後から原本参照が求められるケース。
運用上の利点: ホット側の保持を短くして検索性能と費用を抑えつつ、古い期間は低コストに確保できます。
3-4. 目安(コスト最適化の初期値)
- トレース/スパン: まずは 8 日 を基準に開始し、必要なサービスのみ延長。
- ログ: 14–30 日 が目安。監査要件がなければ短めにし、長期は Live archives を利用。
- Infra / Integration: おおむね 30 日 程度から検討。
- Browser / Mobile(エラー・クラッシュ): 28–90 日 の範囲で要件に合わせて調整。
3-5. 運用ルール例(保持 × アーカイブの併用)
- 基本方針は「ホット保持は短く、長期要件は Live archives に任せる」。
- 例:本番(prod)は Logs を 14 日+Archives 12 か月、ステージング/開発(stg/dev)は 7 日のみ。
- 毎月 Effective retention を確認し、要件とのズレがあればその場で修正します。
3-6. 注意事項
- 適用対象: Retention は イベントに対する設定です。メトリクスは別の保持体系で管理されます。
- カバレッジ: Live archives の対象は Logs に限られます(トレース等は対象外)。
- 適用時点: アーカイブは有効化後に到着したログから開始され、過去分の自動移行は行われません。
- Dropとの関係: Pipeline Control で削除したデータは、アーカイブにも残りません。
- 検索特性: アーカイブ検索はライブより遅延が発生します。リアルタイム検知には向きません。
- 反映タイムラグ: 画面の設定変更が有効になるまで、最長で 24 時間かかる場合があります。
4. 運用の型(現場で回る最小セット)
ここでは誰が・いつ・何を見る/変えるまで落とし込んだ運用のたたき台を示します。
4-1. 月次レビュー(30分ルーチン)
狙い: 使い過ぎの早期検知と、無駄を増やさない運用サイクルの維持。
進め方(例):
- 今月の累計を確認:
NrMTDConsumptionと予算を突き合わせ、超過/未達の見込みを把握する。 - 増加源を特定:
usageMetricまたはサービス単位で内訳を比較し、前月比で伸びた要因を洗い出す。 - 品質チェック: 属性(attribute)の欠落や、CloudWatch × on-host などの重複取り込みを点検する。
- アクション決定: やめる/減らす/維持/増やすを具体化し、担当と期限を割り当てる。
4-2. 重複収集の排除(例:CloudWatch × on-host / KSM × Prometheus Agent)
同じデータを複数経路で送ると、コストもノイズも増えます。次の順で整理すると進めやすいです。
- 経路の棚卸し: 監視対象ごとに送信元(エージェント/連携)を一覧化し、役割を明確にする。
- どちらを残すか決める: 例)RDS は CloudWatch からのみ収集し、on-host の該当収集は無効化。
- Prometheus の重複対策: 明示ラベルのみをスクレイプし、KSM と重なる系列は ignore で除外する。
- 効果確認: ダッシュボードで取り込み量が想定どおり下がっているかを確認する。
4-3. 変更手順(Safe rollout & ロールバック)
Drop/サンプリング/保持の変更は小さく始めて安全に広げます。
- 事前検証: 検索で命中条件を確認し、対象が過不足ないことを確かめる。
- 限定適用: まずは
env=devや特定サービスのみに適用する。 - 前後比較: 30–60 分は差分(取り込み量・エラーレート等)を観察し、異常がないかを見る。
- 本番展開: スコープを段階的に拡大。万一に備えて「ルール無効化」の即時手順を共有しておく。
前後比較の一例(ダッシュボード貼付用):
※ すべての変更は PR/チケットに紐づけ、「いつ・誰が・何を・なぜ」 を記録してください。
よくある落とし穴
- 「見える化」先行: 入口で止めずに可視化だけを増やすと、ノイズとコストが膨らむ。
- Usage と請求の混同: Usage は傾向を見る指標。請求は課金画面/明細で確認する。
- 不可逆な Drop: 適用後に到着した対象データは保存されない。段階適用と命中検証が必須。
- 関数の選び方:
bytecountestimate()は調査用途向けで、アラート集計には不向き。 - ルールの分散: 旧 NRQL Drop ルールを新規に増やさず、Pipeline Control に統一する。
設定例(Infrastructure Agent)
最後にホスト側 Newrelic Agentの設定についてです。
サンプル間隔を調整すると、取り込み量のブレを抑えられます。
まとめ
まず“痩せる化”。入口でノイズを落とせば Usage の傾向が読みやすくなり、ダッシュボードもアラートも機能します。あとは月次レビューで微調整を回し、費用と可視性のバランスを整えていきます。
