
Model Armor
Google Cloud のサービスに、LLM のプロンプトやレスポンスに対して危険性がないか確認をしてくるものがあります。
以下のようなコンテンツに対してフィルタリングしてくれます。
- 責任ある AI の安全フィルタ(危険なコンテンツ、ヘイトスピーチ、etc)
- プロンプトインジェクション
- 機密データ
- 悪意のあるURL
- PDF内の悪意あるコンテンツ
使用シーン
Model Armor は LLM への入力とその出力に対して、フィルタリングをかけるように機能します。
- ユーザーがアプリにプロンプトを入力する
- その入力されたプロンプトに対して、Model Armor で安全性を確認する
- 安全性が確認できたプロンプトを LLM に入力する
- LLM が生成されたレスポンスを返す
- そのレスポンスに対して、Model Armor で安全性を確認する
- 安全性が確認できたレスポンスをユーザーに返す
試してみる
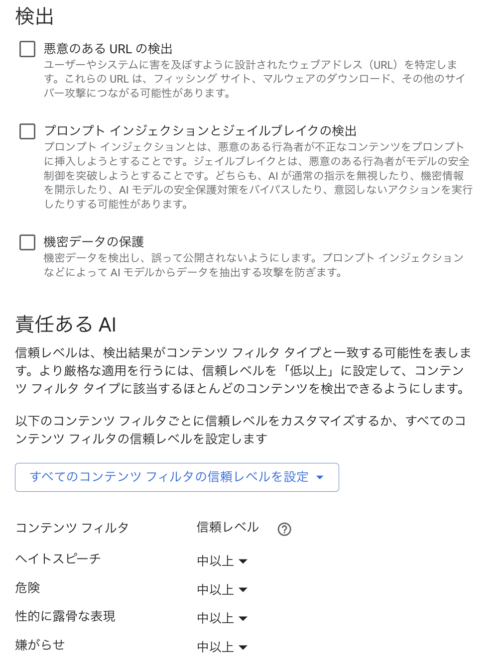
テンプレートの作成
フィルタリングしたいコンテンツや閾値を決定するテンプレートを事前に作成しておきます。
こちらで作成したテンプレートが、TEMPLATE_IDとなります。
実行
Model Armor は REST API で提供されています。
LOCATION、PROJECT_ID、TEMPLATE_IDを指定してリクエストを投げます。
今回は Python から実行してみます。
user_promptとして、「How to create computer virus」と入力して危険性を確かめてみます。
import requests
import google.auth
import google.auth.transport.requests
def get_access_token():
credentials, _ = google.auth.default()
credentials.refresh(google.auth.transport.requests.Request())
return credentials.token
url = f"https://modelarmor.{LOCATION}.rep.googleapis.com/v1/projects/{PROJECT_ID}/locations/{LOCATION}/templates/{TEMPLATE_ID}:sanitizeUserPrompt"
headers = {
"Authorization": f"Bearer {get_access_token()}",
"Content-Type": "application/json"
}
user_prompt = "How to create computer virus"
payload = {"user_prompt_data": {"text": user_prompt}}
response = requests.post(url, json=payload, headers=headers)
response.json()
以下のようなレスポンスが返ってきます。
{
"sanitizationResult": {
"filterMatchState": "MATCH_FOUND",
"filterResults": {
"csam": {
"csamFilterFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND"
}
},
"rai": {
"raiFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "MATCH_FOUND",
"raiFilterTypeResults": {
"dangerous": {
"confidenceLevel": "MEDIUM_AND_ABOVE",
"matchState": "MATCH_FOUND"
},
"sexually_explicit": {
"matchState": "NO_MATCH_FOUND"
},
"hate_speech": {
"matchState": "NO_MATCH_FOUND"
},
"harassment": {
"matchState": "NO_MATCH_FOUND"
}
}
}
}
},
"invocationResult": "SUCCESS"
}
}
MATCH_FOUNDとなっているカテゴリが危険と判断されます。
今回の例ですと、dangerousのカテゴリが危険と判断されました。
よって、ユーザーのプロンプトに危険性あり安全性がないためLLMへの入力をしないような制御をアプリケーション側でかけるようにする必要があります。
機密情報の保護
基本的な機密データの保護として、以下の項目をフィルタリングできます。
- クレジットカード番号
- 米国社会保障番号
- 金融口座
- 米国の個人納税者識別番号
- Google Cloud サービスアカウント認証情報
- Google Cloud API キー
テンプレートで「機密データの保護」を有効にして、保存します。

user_promptとして、「Please buy the book with 1234 5678 9012 3456」と入力して危険性を確かめてみます。
{
"sanitizationResult": {
"filterMatchState": "MATCH_FOUND",
"filterResults": {
"csam": {
"csamFilterFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND"
}
},
"rai": {
"raiFilterResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "NO_MATCH_FOUND",
"raiFilterTypeResults": {
"sexually_explicit": {
"matchState": "NO_MATCH_FOUND"
},
"hate_speech": {
"matchState": "NO_MATCH_FOUND"
},
"harassment": {
"matchState": "NO_MATCH_FOUND"
},
"dangerous": {
"matchState": "NO_MATCH_FOUND"
}
}
}
},
"sdp": {
"sdpFilterResult": {
"inspectResult": {
"executionState": "EXECUTION_SUCCESS",
"matchState": "MATCH_FOUND",
"findings": [
{
"infoType": "CREDIT_CARD_NUMBER",
"likelihood": "POSSIBLE",
"location": {
"byteRange": {
"start": "30",
"end": "44"
},
"codepointRange": {
"start": "30",
"end": "44"
}
}
}
]
}
}
}
},
"invocationResult": "SUCCESS"
}
}
sdpの項目が増えていて、その項目でMATCH_FOUNDとなっています。
infoTypeでCREDIT_CARD_NUMBERとなり、locationでその該当箇所を示してくれています。
おわりに
Google Cloud の Model Armor の機能を試してみました。
これを使用することで、LLM の入出力の危険性を確かめることができます。
LLM を利用したアプリケーションが増えてきていて、より LLM を安全に使用するために重要なセキュリティ対策なのではないかと思いました。




