
アイレット株式会社 クラウドインテグレーション事業部所属の森 柾也です。
Google Cloud Next において、「Compute Engine best practices: Optimizing cost, workload management, and scalability」というセッションに参加しました。このセッションでは、様々なワークロードにおいての Compute Engine のベストプラクティスについて新機能も含めて紹介されました。
この記事では、セッション内で解説された AI/ML and HPC ワークロードに影響のある新機能をご紹介します。
(Google Cloud Next の期間中にiPhoneカメラが壊れてしまい、画質が荒く見づらいものがございますがご了承くださいmm)
ワークロードのカテゴリ

アプリケーション全てに共通する単一のベストプラクティスを見つけるのは難しいと述べられていました。
アプリケーションは、以下の3つのカテゴリに分類され、それぞれ異なる要件とベストプラクティスを持つとのことでした。
- AI/ML and HPC
- Cloud-native
- Traditional
セッション内で解説された AI/ML and HPC ワークロードに影響のある新機能をご紹介します。
AI/ML and HPC ワークロード
AI/ML and HPC ワークロードのジョブには、いくつかの特徴があります。多くのGPUやTPUを必要とし、計算リソースを集約する必要があります。また、ジョブは開始から終了まで継続して実行されます。
Google Cloud では、様々な種類のGPUを搭載したVMインスタンスを提供しています。しかし、必要なGPUのキャパシティをどのように確保するかが大きな課題となっています。
Dynamic Workload Scheduler の利用可能なマシンタイプが追加

Dynamic Workload Scheduler (DWS) は、Google Cloud が提供するリソース管理およびジョブスケジューリングプラットフォームです。
DWSを利用することで、GPUやTPUなどのアクセラレータリソースを効率的に管理・利用することが可能になります。
DWSの主な特徴:
- 必要なGPU容量と利用期間の柔軟な指定が可能
- リクエストしたGPUリソースが利用可能になった時点で一括起動
Dynamic Workload Scheduler (DWS) は、アクセラレータに簡単かつ手頃な価格でアクセスできるようにするリソース管理およびジョブスケジューリングプラットフォームです。本日、DWSでのアクセラレータサポートの拡張を発表しました。
これには、Flex Startモードでのプレビュー提供によるTPU v5e、Trillium、A3 Ultra (NVIDIA H200)、A4 (NVIDIA B200) VMのサポートが含まれ、TPU向けのCalendarモードサポートは今月後半に提供予定です。
さらに、Flex Startモードでは、リソースを即時にプロビジョニングし動的にスケーリングできる新しいプロビジョニング方式がサポートされ、長時間実行される推論ワークロードやより広範な学習ワークロードに適しています。
これは、すべてのノードを同時にプロビジョニングする必要があるFlex Startモードのキュー型プロビジョニング方式に加えて提供されます。
引用: Introducing Ironwood TPUs and new innovations in AI Hypercomputer
今回のアップデートでは、以下の主要な機能拡張が発表されました
1. 新規アクセラレータのサポート(プレビュー提供)
- TPU v5e
- Trillium
- A3 Ultra (NVIDIA H200)
- A4 (NVIDIA B200)
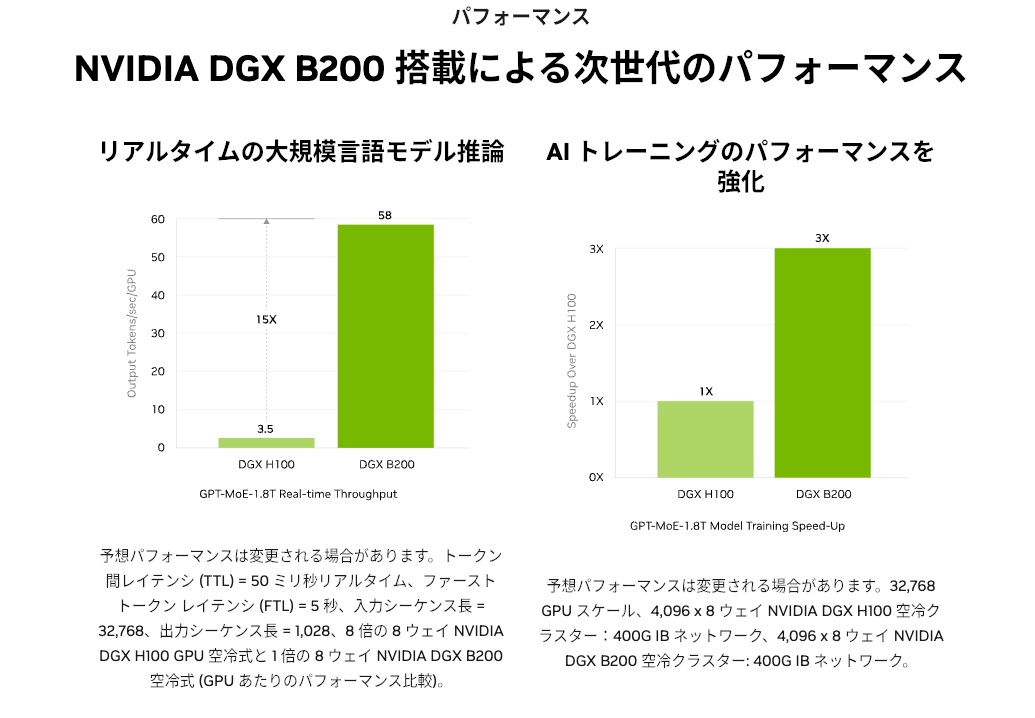
引用: https://www.nvidia.com/ja-jp/data-center/dgx-b200/
サポートされたA4 インスタンスに搭載されている、NVIDIA B200 GPUは、A3インスタンスに搭載されている H100 GPUよりも、3倍のAIトレーニングのパフォーマンスがあるそうです。最新のGPUをすぐにクラウドで利用できる点に、Google と NVIDIA の強固なパートナーシップを感じました。
感想
現在、AIモデルの開発が急速に進展する中で、Dynamic Workload Scheduler(DWS)が最新のTPUやGPUをサポートするようになったことは非常に重要だと思います。
AI/ML and HPC ワークロードにおいてTPUやGPUリソースの確保が課題ですが、DWSにより解決することができ、特にクイックな実験やプロトタイピング、モデルの微調整などが容易になるため、AIモデル開発がより活発になることが期待できます。
また、最新のGPU/TPUは従来のものと比較して処理速度が大幅に向上しており、これらを即座に利用できることはAIモデル開発の速度と品質向上に直結します。
高価なハードウェアを自前で用意する必要なく、従量課金モデルで利用できるクラウドならではの点と、NVIDIAとのパートナーシップから最先端の計算リソースを利用できる点は、Google Cloudの大きな強みだと思います。このような柔軟性は、特にスタートアップや研究機関にとって重要な意味を持つと感じています。
今後、クラウド上で最新のGPUやTPUをオンデマンドで利用できる環境が、AIモデル開発やHPCの新たなスタンダードになっていくことは間違いないと思います。Google Cloudがこの分野でリーダーとして牽引する未来が楽しみです。




