
アイレット株式会社 クラウドインテグレーション事業部所属の森 柾也です。
Google Cloud Next において、「Compute Engine best practices: Optimizing cost, workload management, and scalability」というセッションに参加しました。このセッションでは、様々なワークロードにおいての Compute Engine のベストプラクティスについて新機能も含めて紹介されました。
この記事では、セッション内で解説された AI/ML and HPC ワークロードに影響のある新機能をご紹介します。
(Google Cloud Next の期間中にiPhoneカメラが壊れてしまい、画質が荒く見づらいものがございますがご了承くださいmm)
ワークロードのカテゴリ

アプリケーション全てに共通する単一のベストプラクティスを見つけるのは難しいと述べられていました。
アプリケーションは、以下の3つのカテゴリに分類され、それぞれ異なる要件とベストプラクティスを持つとのことでした。
- AI/ML and HPC
- Cloud-native
- Traditional
セッション内で解説された AI/ML and HPC ワークロードに関連のある新機能をご紹介します。
AI/ML and HPC ワークロード
AI/ML and HPC ワークロードのジョブには、いくつかの特徴があります。多くのGPUやTPUを必要とし、計算リソースを集約する必要があります。また、ジョブは開始から終了まで継続して実行されます。
Cluster Director

物理的に近いVMの展開や、VMのメンテナンスを制御できる Cluster Director が発表されました。
Cluster Director の種類としては、ジョブスケジューラーである Slurm 向けの Cluster Director (Cluster Director for Slurm) と、GKE 向けの Cluster Director (Cluster Director for GKE) が発表となりました。
Cluster Director の特徴
- 高速なクラスターのセットアップとデプロイ
- 高密度配置による最大パフォーマンス
- チェックポイント設定、再起動、ジョブの自動復旧による回復力
- オブザーバビリティ(可観測性)と容易な診断
- 計画的なメンテナンスの制御
Cluster Director(旧Hypercompute Cluster)を使用すると、
物理的に同一場所に配置されたVM、ターゲットを絞ったワークロード配置、高度なクラスタメンテナンス制御、トポロジーを考慮したスケジューリングにより、アクセラレータのグループを単一ユニットとして展開・管理できます。
今年後半に提供予定のCluster Directorの新しい更新を発表します:
– Slurm向けCluster Director – 完全マネージド型のSlurmサービスで、簡素化されたUIとAPIによりSlurmクラスタのプロビジョニングと運用が可能です。一般的なワークロード用のブループリントと事前設定されたソフトウェアを含み、デプロイメントの信頼性と再現性を確保します。
– 360°の可観測性機能 – クラスタの使用率、健全性、パフォーマンスを可視化するダッシュボードに加え、AI Health PredictorやStraggler Detectionなどの高度な機能により、個々のノードレベルまで障害を事前に検出して修復します。
– ジョブ継続性機能 – フリートを継続的に監視し、不健全なノードを事前に交換するエンドツーエンドの自動ヘルスチェックなどがあります。その結果、性能が低下したクラスタでもトレーニングが中断されず、マルチティアチェックポイントによる高速な保存と復元が可能になります。
引用: Introducing Ironwood TPUs and new innovations in AI Hypercomputer
上記発表のように、Cluster Director によって、高速化されたVMクラスターを管理できるようになりました。
物理マシンの近接性について、Google Cloud ではもともとプレースメントポリシーという機能があり、コンパクトプレースメントポリシーやスプレッドプレースメントポリシーという物理的なマシンの配置をある程度指定できる機能がありました。
これまで A3 インスタンスなど強力なGPU(貴重なGPU)を積んだインスタンスでは、コンパクトプレースメントポリシーを指定できなかったですが、このアップデートによって物理的マシンを集約することが可能となり、これまでよりも高速なHPC構成を作ることができるようになると思います。
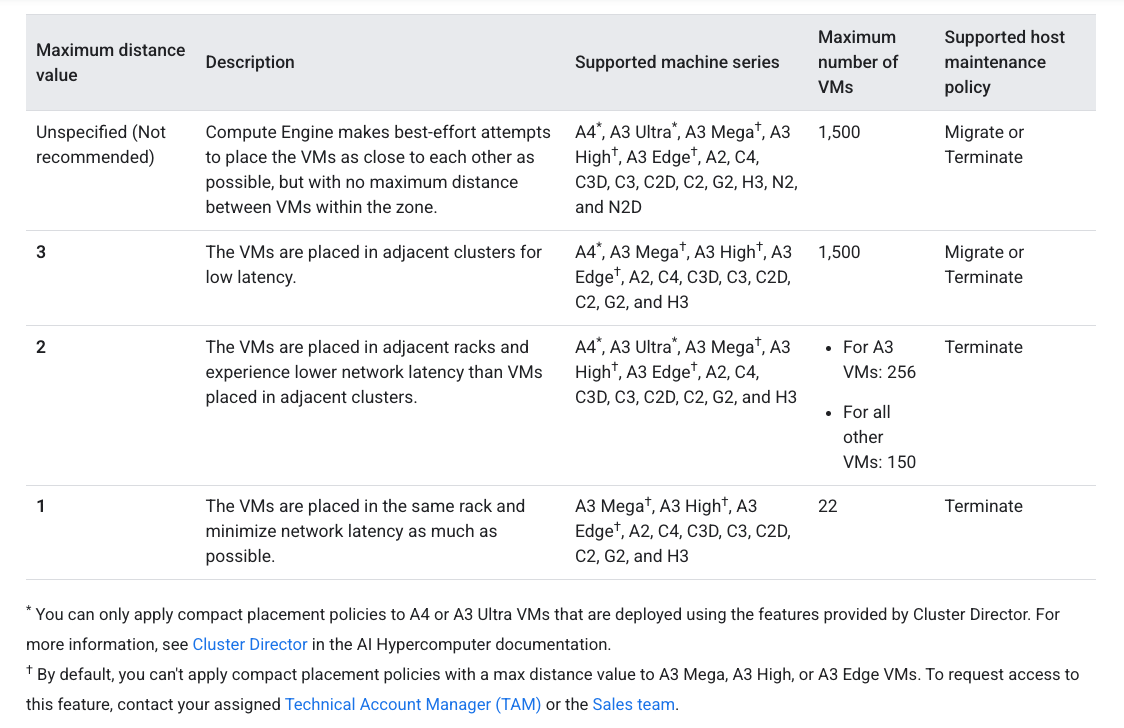
コンパクトな配置ポリシーは、Cluster Director によって提供される機能を使用してデプロイされた A4 または A3 Ultra VM にのみ適用できます。
引用: About compact placement policies
また、プレースメントポリシーのドキュメントを確認すると、A4 と A3 Ultra については物理的な位置を集約する場合は Cluster Director の利用が必須のようですのでご注意ください。
所感
今回の Cluster Director の発表はクラウド上で HPC 構成を組む方にとっては非常に嬉しい発表だったと思います。
AI モデルの学習では、NVLink プロトコルを利用してGPU間で高速に通信を行うため、物理的な位置が遠いことですら学習のボトルネックになってしまうため、Cluster Director によって物理的に近い位置に配置できることは、HPC構成の組みやすさや世の中の AI モデル開発をより加速させると思います。
また、Cluster Director の計画的なメンテナンスの制御の機能については、VM のメンテナンスイベントを検知することができるため、学習の中断や手戻りを減らせると思います。
今後 AI モデル開発以外にも Cloud 上で HPC を組んで研究を行う大学の方々がいると思いますので、世の中を先に進めるようなソリューションだと思います。




