
セッションタイトル
DAP332: Executive perpective: Risk management for generative AI workloads
はじめに
AWS の Jason Garman 氏と Mark Ryland 氏が、生成AIベースのワークロードにおけるリスク管理という、今最も注目されるテーマについて深く掘り下げました。
これは単なる講演ではなく、参加者との活発な対話を通じて、生成AIがもたらす新たなセキュリティ課題とその対処法を探る「チョークトーク」形式のセッションでした。このブログでは、その主要なポイントを皆さんに共有したいと思います。
主に3つのトピックについて話しいただきました。まず、AWSが定義する責任あるAIとは何か、その中核となる原則と要素についてです。次に、生成AIセキュリティに関するサービス視点の概要に移ります。AWSの生成AI技術スタックのあらゆる層にどのようにセキュリティを構築しているかについてです。そして最後に、このセクションのコアメッセージである、AIベースのアプリケーションを検討する際のリスク管理アプローチについてでした。
責任あるAIとは?AWSのアプローチ
生成AIセキュリティスコーピングマトリックス
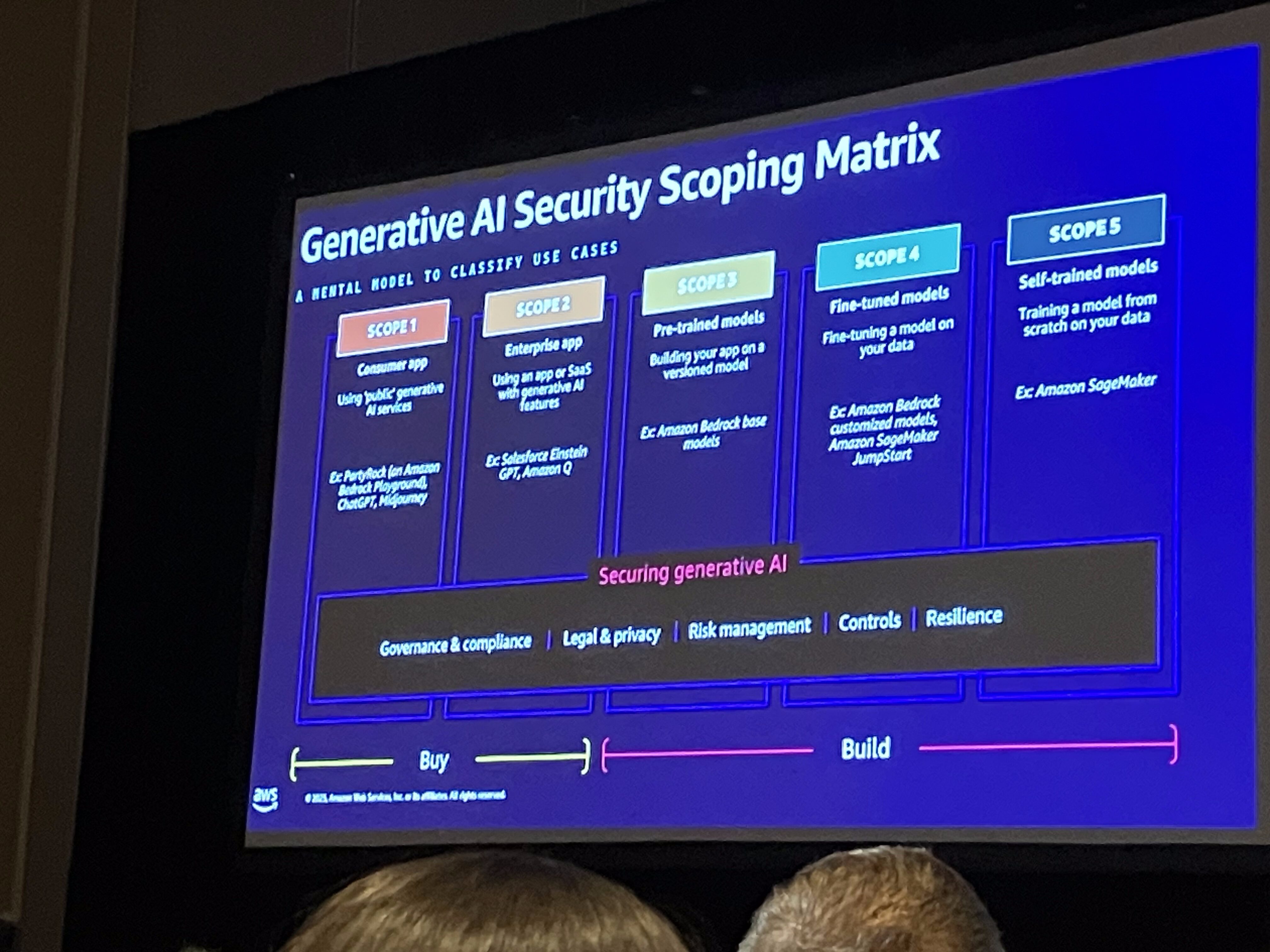
「生成AIセキュリティスコーピングマトリックス」は、AWSが顧客と生成AIのセキュリティについて会話する際に用いられるメンタルモデルです。このマトリックスは、顧客が生成AIを組織内でどのように利用しているか(消費の仕方)に応じて、セキュリティ上の懸念を具体的なユースケースにマッピングし、リスク管理のアプローチを整理するために役立ちます。
このマトリックスは、顧客が生成AIを消費する際の5つのスコープを提示しており、主に「購入(Buy)」と「構築(Build)」の視点からリスクを評価します。
例えば、従業員が企業所有のノートパソコンでChatGPTのような外部ツールを使用し、企業IP(知的財産)を入力してしまう「シャドーIT」のようなリスクが挙げられます。
責任あるAI
AWSは、「責任あるAI」を8つの要素で定義しております。

その中でも特に「ガバナンス」が重要であると強調されています。ガバナンスとは、他の責任あるAIの項目とは異なり、それらの目標を達成するためのメカニズム、プロセス、ポリシー、手続き、技術を指す「メタ概念」です。
セキュリティの観点からは、大きく分けて2つの側面が挙げられました。
古典的なセキュリティ
システムへの不正侵入を防ぎ、コントロールが回避されないようにする、従来のセキュリティ対策です。
生成AIベースのワークロードにおいても、この点は大きな差はなさそうです。
正確性 (Correctness)
AIシステムが不適切な回答や「幻覚」(ハルシネーション)を生成しないようにする、より難しく微妙な領域です。業界では、この「正確性」に関連して、「アラインメント(alignment)」「安全性(safety)」「信頼性(reliability)」「精度(accuracy)」といった様々な用語が使われています。特に「安全性」は、AIシステムが社会に重大な危害(化学兵器、生物兵器の製造など)を引き起こすことを防ぐ、という特定の意味合いで用いられることがあります。
AWSにおけるセキュリティレイヤーの構築
チョークトークの中での話題を、インフラとサービスの2つのレイヤーに分類してまとめてみました。
インフラ層
基盤となるインフラレベルから、セキュリティが深く組み込まれています。
GPU(グラフィックス処理ユニット)
AWSでは、GPUは常にシングルテナントとして割り当てられ、共有されることはありません。これは、マルチテナンシー環境におけるセキュリティリスクを防ぐためです。
GPUの仮想化技術については、現時点では十分に安全であるとは見なされておらず、AWSでは採用していません。
EC2 Nitroアーキテクチャ
EC2のNitroシステムは、「機密コンピューティング(confidential computing)」を提供する機能として設計されています。
これにより、クロステナントアクセスが防止されるだけでなく、AWSの従業員であっても、計算中またはストレージ上の暗号化されていないデータにアクセスすることはできません。
サービス層(Amazon Bedrock)
Amazon Bedrockは、従来のセキュリティコントロールに加え、「正確性(correctness)」といった新しい側面を含む、多くのセキュリティ機能を提供します。
モデルのオンボーディングと隔離
Bedrockに取り込まれるファウンデーションモデルは、厳格なセキュリティチェックを受けます。
サポートされるのは「安全なテンソル形式(safe tensor formats)」のみであり、これによりリモートコード実行のリスクが排除されます。
モデルは完全に隔離されたVPC(Virtual Private Cloud)内で動作し、外部のデータソースやモデルプロバイダーへのインターネットアクセスは一切ありません。
プロンプトと応答の隔離
顧客のプロンプトやモデルからの応答は、AWSによって保存されることはなく、人間によるアクセスもありません。
モデルプロバイダーも、モデル改善のために顧客のデータにアクセスすることはできません。この点に関して、AWSは顧客に強力な保証を提供しています。
ガードレール機能
Guardrailsは、機械学習に基づく確率的なチェックを通じて、望ましくない振る舞いを最小限に抑えることを目的としています。
これにより、アプリケーションが複数のモデルを切り替えて利用する場合でも、異なるモデル間で一貫した動作を確保できます。
特に注目すべきは、「自動推論チェック(automated reasoning checks)」機能です。これは、許容される出力形式を正式に定義し、それに合致しない場合は出力を拒否する機能であり、非決定論的なLLMの上に決定論的なエキスパートシステムを重ねてフィルタリングするようなイメージです。
悪用検知メカニズム(モデルプロバイダー側)
モデルプロバイダーは、顧客による悪用(例:生物兵器の製造試行)を検知するために、ソフトウェアベースの機械学習モデルを運用できます。
このプロセスには、人間がコンテンツにアクセスすることはありません。
悪用が検知された場合、その情報はAWSに通知され、AWSが必要に応じて顧客と対話する仕組みになっています。モデルプロバイダーには、顧客の情報ではなく、特定の期間における悪用トリガーの回数などが匿名で提供されます。
この仕組みは、顧客を悪意のある行為から保護するだけでなく、モデルプロバイダーを悪用から守る役割も果たします。
ファインチューニング保護
ファインチューニングによってモデルの安全性が損なわれることを防ぐため、モデルプロバイダーはソフトウェアベースのテストをファインチューニングジョブに対して実施できます。
もしファインチューニングがモデルの安全性を低下させると検知された場合、そのバッチジョブは拒否されます。
AWS自身も、サードパーティモデルをBedrockのマーケットプレイスにオンボーディングする前に、安全性評価などのテストを実施しています。
エンタープライズ機能
Bedrockは、組織のサービスコントロールポリシー(SCPs)によるモデル使用制限など、エンタープライズ顧客が必要とする基本的なフックと機能を提供します。例えば、特定のDevOpsエンジニアのみが特定のモデルを使用できるように制限することも可能です。
データ統合パターンとAIシステムへの「代理権」
生成AIと企業データの統合には、RAG(Retrieval Augmented Generation)、ファインチューニング、エージェンティックAIといった一般的なパターンがあります。ここで重要なのは、RAGやエージェンティックAIが基盤モデル自体を変更しないのに対し、ファインチューニングはモデルを直接変更するという点です。この違いは、特に組織内の法務部門など、技術に詳しくない関係者にとって、データがモデルのトレーニングに使用されるか否かを理解する上で非常に重要です。
AIへのセキュリティ決定の委譲の危険性も理解する必要があります。
LLMは一般的に非決定論的なシステムであるため、セキュリティに関わる決定(例:データ認可)をLLMに完全に委ねるべきではありません。システムプロンプトは、悪意のあるユーザーによって容易に回避される可能性があります。
この課題に対処するためには、「AIシステムのエージェンシー(代理権)」という概念が提唱されています。これは、AIシステムにどの範囲の意思決定を委譲するのかを明確に定義し、管理・制御することで、セキュリティ目標を達成するという考え方です。AIシステムに許可する意思決定の範囲を明示し、その範囲外からのアクセスを制限することが極めて重要です。
生成AIワークロードのリスク評価7ステップ
生成AIワークロードのリスクを評価するための、実践的な7つのステップが提案されました。

- Shared Responsibility Modelの理解: 自身の責任範囲と、AWSやモデルプロバイダーに委譲する責任を明確に理解します。
- 脅威モデリング: AIシステムを「信頼できない」ものとして、最悪の意思決定を想定して脅威モデルを作成します。
- エージェンシーの特定: AIシステムに委譲する意思決定の範囲を具体的に特定します。
- ターゲットメトリクスの定義: 毒性、無関係なコンテンツ生成、幻覚など、「正確性」に関連する具体的なターゲット指標を定義します。現状の技術では100%の達成は難しいものの、目標値を設定することが重要です。
- 決定論的なセキュリティメカニズムの導入: AIシステムと外部データセット間の相互作用を脅威モデリングした後、決定論的なセキュリティ制御を配置します。これには、Bedrock Guardrailsの「自動推論チェック」のように、許容される出力形式を正式に定義し、満たされない場合は拒否する技術も含まれます。これはLLMの上に「エキスパートシステム」を重ねるようなイメージです。
- セーフティメカニズムの追加: Bedrock Guardrailsのようなセーフティメカニズム(「正確性」や「精度」の観点から)をさらに追加します。
- メトリクスの継続的な評価: 定義したメトリクスが満たされているかを継続的に評価・監視します。
RAGの例で言えば、ユーザーの権限に基づいてデータベースから結果を取得することで、LLMがユーザーに許可されていないデータにアクセスするのを防ぐことができます。これは、決定論的なアクセス管理とLLMの創造性を組み合わせることで、データアクセスに関するリスクを低減できる良い例です。
セッションでは、「ブランドの評判リスク」など、「安全性」に関する許容範囲を定めることの難しさについても議論されました。また、リスクだけでなく、システムがもたらす「メリット」も同時に考慮することの重要性が強調されました。リスクがゼロのシステムは存在せず、得られる大きなメリットに対して、どの程度のリスクを許容するかはビジネス上の決定となります。
Bedrockによる具体的なリスク管理機能の例
モデルのオンボーディング時のセキュリティチェック
安全なテンソル形式のみをサポートし、リモートコード実行のリスクを排除します。
完全なモデル分離
モデルは孤立したVPC内で実行され、インターネットアクセスや外部データソースへのアクセス、モデルプロバイダーへの逆接続はできません。
プロンプトと応答の厳格な分離
顧客のプロンプトと応答はAWSによって保存・人間がアクセスされることはなく、モデルプロバイダーにも共有されません。
ガードレール機能(Bedrock Guardrails)
LLMの振る舞いを特定のプロパティに基づいてフィルタリングし、許容される出力形式を定義することで、望ましくない振る舞いを最小限に抑えます。これは非決定論的なLLMの上に確定的なエキスパートシステムを重ねることで、出力の正確性を高めます。
ファインチューニング保護
ファインチューニングの結果がモデルの安全性を損なわないように、モデルプロバイダーがソフトウェアベースのテストを実行し、問題がある場合はファインチューニングジョブを拒否できます。
不正行為検出メカニズム
モデルプロバイダーは、顧客のプロンプトや応答の内容にアクセスすることなく、APIを介して不正行為(例:生物兵器の製造方法を尋ねるなど)の可能性を示す確率的なスコアを受け取ることができます。
LLMゲートウェイの役割と進化
LLMゲートウェイは、監査、ロギング、インジェクション検知、API呼び出しの制御、可観測性(observability)、多重化といった点で多くのメリットを提供します。しかし、セキュリティの観点から見ると、LLMゲートウェイはAIシステムと下流のデータソースとの相互作用を完全に可視化できないため、データ認可の問題をすべて解決するわけではありません。
これに代わるパターンとして、「ゲートウェイゲートウェイ」や「MCP(Model Context Provider)ゲートウェイ」が提案されています。これらは、AIシステムがデータにアクセスする前に、効果的な認証と認可を一元的に管理し、強制するためのものです。現在、業界では、エージェントとユーザーが対話する「チェーン操作」における権限を定義するためのオープン標準が積極的に開発されています。
まとめ
生成AIは、企業に計り知れない可能性をもたらしますが、同時に新たなセキュリティとリスク管理の課題も提起します。AWSの専門家たちが強調したのは、AIシステムを「信頼できない」ものとして扱い、その「代理権」を明確に定義し、決定論的なセキュリティコントロールと組み合わせるという、構造化されたアプローチの重要性です。この点は個人的に非常に印象的でした。
単に技術的な側面に留まらず、組織全体のガバナンス、ビジネス上のメリット、そして業界標準の進化までを見据えた多角的な視点が必要です。
この記事が、皆さんの生成AIベースのワークロードにおけるセキュリティとリスク管理の考察の一助となればこれ幸いです。
