
こんにちは!MSPの小野瀬です!
AWS Summit Japan 2025で「企業内に分散したデータの分析と AI 活用を推進する:AWS で実現するデータ活用の民主化 」セッションにオンラインで参加しました。
本記事では、その内容と私の学び・感想をまとめました。
(オンライン参加は初めてだったのですが、AWS Summitのマイページ上から簡単にアクセスでき、スライドも見やすくとても快適でした!)
セッション「企業内に分散したデータの分析と AI 活用を推進する:AWS で実現するデータ活用の民主化」
| 日時 | 6/25(水) 13:50 – 14:30 |
| 登壇者 | アマゾン ウェブ サービス ジャパン合同会社 サービス & テクノロジー事業統括本部 Data & AI ソリューション本部 プリンシパルアナリティクススペシャリストソリューションアーキテクト 下佐粉 昭 氏 |
| ジャンル | データベース、データレイク・分析・BI |
なぜこのセッションを選んだのか?
私がこのセッションを選んだのは、タイトルの「データ活用の民主化」と「AI」というキーワードが、まさに日々の業務で直面している課題と当てはまっていたからです。
データ活用の民主化とは?
ここで少し、「データ活用の民主化」という言葉について掘り下げてみます。この言葉は、「組織内の誰もが、自身の役割や専門性に関わらず、必要なデータに容易にアクセスし、それを分析・活用して意思決定や業務改善に役立てられる状態」を指します。
なぜ「民主化」が必要なのでしょうか?
多くの企業では、データが部門ごとに分散し、サイロ化しているのが現状です。これにより、データが見つけにくい、信頼性に欠ける、部門間で共有されないといった課題が発生し、迅速な意思決定やイノベーションの妨げとなります。
データ活用の民主化が進むことで、組織の誰もが必要なデータにアクセスすることができ、最大限に活用され企業の成長を加速させることができます。
私は最近の業務で特に「データ管理と情報連携の課題」と「AI活用の難しさ」を強く感じていました。
- データ管理と情報連携の課題 … ほしい情報がどこにある?生きている情報なのか?部門間で持っている情報や認識が違う、、etc..
- AI活用の難しさ … 生成AIへのデータの見せ方、軌道修正、AIへの回答をどう評価する?
このような問題を解決していくヒントが得られたらと思い、このセッションを選びました。
次世代のAmazon SageMaker
このセッションの主役は、まさにこの「データのサイロ化」と「運用負担の増加」という課題に対応するためにリリースされた「次世代のAmazon SageMaker」でした。
Amazon SageMakerとは
Amazon SageMakerとは、AWSが提供する機械学習(Machine Learning: ML)に特化したフルマネージドサービスです。
一言で言えば、「MLモデルの構築、トレーニング、デプロイ、管理、そして運用まで、MLライフサイクルの全てをサポートする統合開発環境」といえます。
セッションでは、Amazon SageMakerが分散するデータを管理する仕組みや統合する環境を提供するということが示されました。
本記事ではこのセッションで特に印象に残った「①分散するデータをまとめる基盤」「②データの信頼性」「③データ処理の運用負荷」について、紹介します。
①分散するデータをまとめる基盤
企業内の「データのサイロ化」は、AI活用の大きな障壁です。セッションでは、これを解決する「Lakehouse(データレイクハウス)」アーキテクチャが強調されました。
Amazon S3やAmazon Redshiftと連携させ、多様なデータソースを一元的に集約。これにより、データがどこにあるか分からない、という課題を解消し、分析やAI活用に必要なデータへのアクセスを効率化していました。
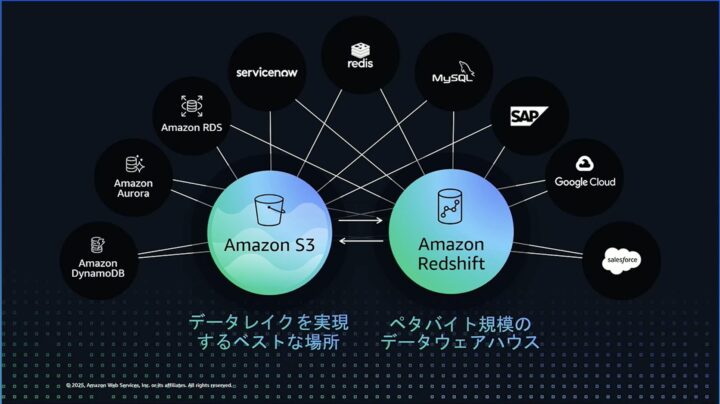
この話から、まずは分散している多様なデータ全てを一つの場所にまとめることが、サイロを壊すための一歩だと思いました。そして全ての膨大なデータを保有でき、安全に管理できるだけの基盤が重要であると感じました。
②データの信頼性
データ活用の民主化には、データの「信頼性」が不可欠です。
セッションでは、未加工データをAI対応の資産に安全に変換するプロセスが示されました。未加工のデータから前処理とメタデータ付加を行い、データが何を意味し、どう使えるかを明確にします。
この中核を担うのが、「SageMaker Catalog」という機能です。
これは様々な「データ」の情報(メタデータ)を「カタログ化(目録化)」し、一元的に管理する機能のことです。データがどこにあり、どんな内容なのか、誰がアクセスできるかなどの情報を示す「目録」や「検索システム」のような役割を担います。
さらに、生成AIの「ガードレール機能」などのガバナンス機能も強調されていました。
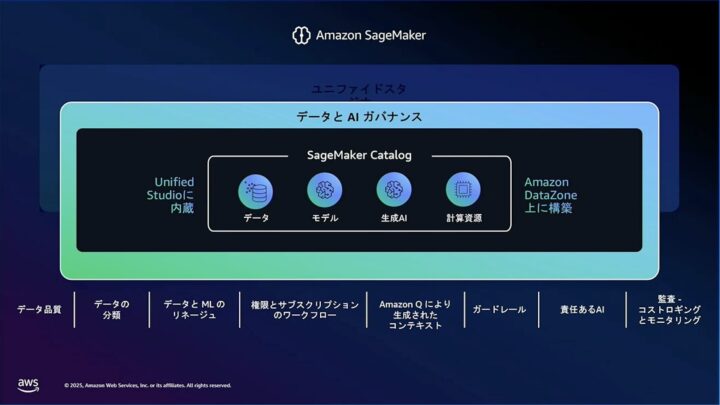
これにより、データの検索や共有が容易で迅速になり、組織内のデータを最大限に活用できることが示されていました。
③データ処理の運用負荷削減
データ統合・活用に伴う運用負荷は大きな課題ですが、次世代SageMakerはここにもフォーカスします。
- Zero-ETL統合: アプリケーションからLakehouseへのデータ移動におけるETLプロセスを劇的に簡素化・自動化。Rocheの事例では、データ統合時間を最大70%短縮し、コストも削減。
- Amazon Q Developer: スライドでも示された「Amazon Q Developer」は、自然言語での質問応答、データ検索、コード生成、クエリ生成支援といった機能を提供し、データ分析やAI開発の障壁をさらに低減し、データ活用の民主化を強力に推し進めるAIアシスタントとして注目されます。
- フェデレーテッドクエリ: データストアからデータを移動させずに直接クエリ実行が可能になり、手間や管理負荷を軽減。
- 高パフォーマンスとコスト効率: SageMaker Hyperpodによるトレーニング時間短縮、S3 Intelligent-TieringやRedshift Serverlessなどによるコスト最適化機能で、大規模なAI・分析活用を経済的に実現します。トヨタの事例では、既存ツールを活かしつつデータ環境を強化できる柔軟性も示されました。
データの管理には、 データの加工・統合・分析・保存におけるコスト最適化など、さまざまな処理が必要で、いかにこの作業を自動化するかで大きな差がつくと思いました。
まとめ・感想
このセッションでSageMakerの機能の素晴らしさはもちろん、データ活用における大切な視点を学ぶことができました。
特に公演の中でも強調され印象に残っているのが、「データを完全に把握することから本当のビジネスインパクトが生まれる」という言葉です。
企業にとってデータは最大の資産であり、それと同時にただ置いておくだけでは意味がなく、その価値を最大限に引き出すためには、より多く、そして信頼性の高いデータを活用することが不可欠であると強く感じました。
また、「データのサイロ化」を打ち破っていくためには、データ上だけでなく、組織全体の繋がりをもっと強くして、組織面からサイロを壊していく必要があると思いました。
そして、AI活用においては、AIが提供してくれる多様な情報に対し、私たち人間が「どう判断し、どう活用するのか」という力を養う必要があると感じました。
日々障害の一次対応をする私たちMSPは、色々な部門やお客様と連携しやりとりを行います。そんな各所と接点の多い私たちだからこそ、得られる情報や解決できる課題があるのではと思います。
日々の業務で目にするたくさんのデータにもっと目を向けて、価値を見出していきたいと思いました。