
こんにちは。DX開発事業部の鹿嶋です。ねこ、吸ってますか?
昨日、Gemini 2.5 Flash-Lite の正式版が一般提供(GA)開始されました。
今回の記事では、主要な特徴を簡潔にまとめてご紹介します!
特徴
※画像出典(https://developers.googleblog.com/ja/gemini-25-flash-lite-is-now-stable-and-generally-available/)
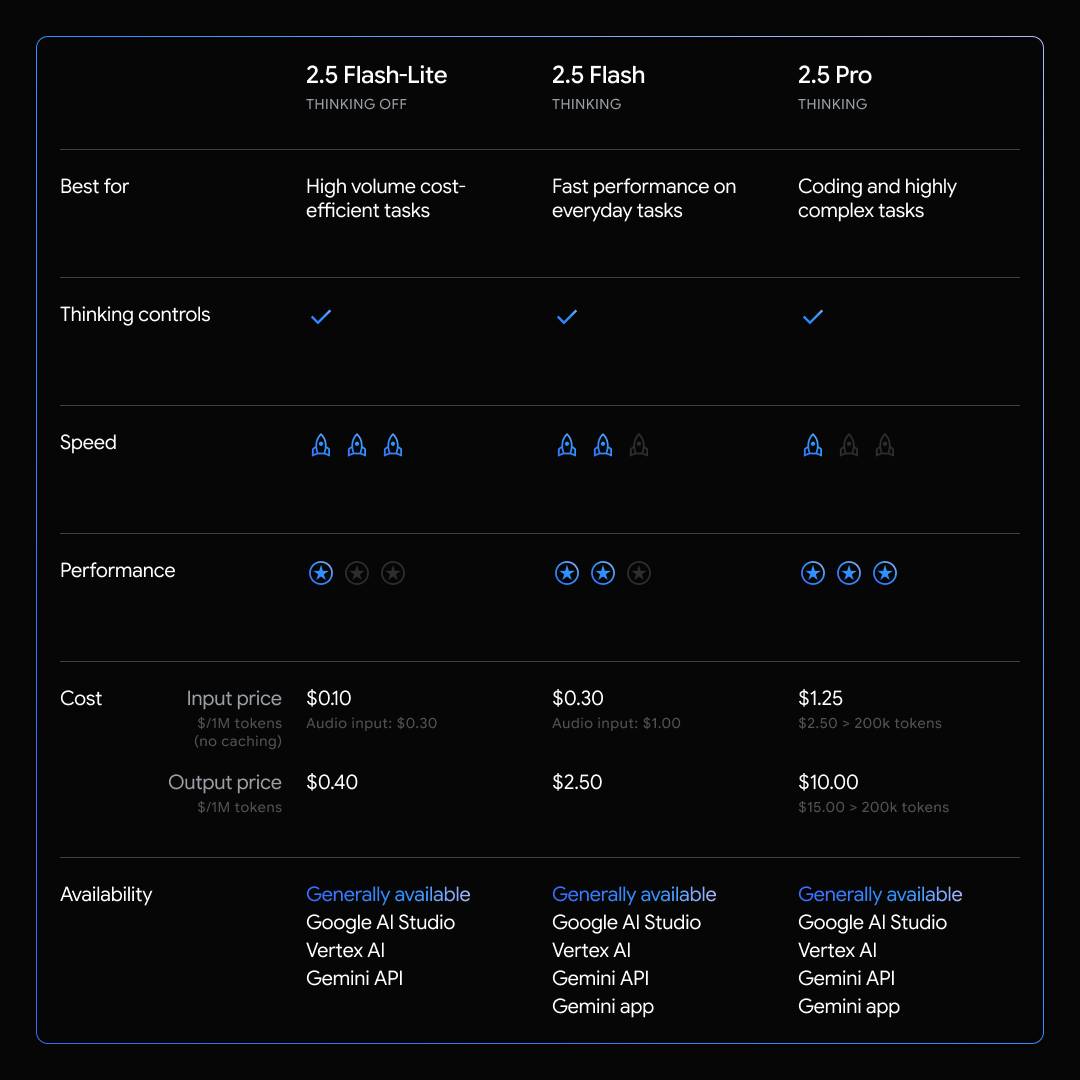
Gemini 2.5 Flash-Lite は、従来の 2.0 Flash-Lite や 2.0 Flash よりも低レイテンシでの利用が可能となっています。そのため、翻訳や分類などの応答速度が重要なタスクに最適となります。
また、2.5系のモデルの中で、最も低コストで大量のリクエストを処理することが可能であり、音声入力のコストも、プレビュー版提供時より40%抑えられています。
- 入力トークン: $0.10 / 100万トークン
- 出力トークン: $0.40 / 100万トークン
前バージョンの 2.0 Flash-Lite との比較においては、特に以下の分野での品質向上が見られているとのことです。
- コーディング
- 数学分野
- 科学分野
- 推論
- マルチモーダル理解・処理
最後に、最も軽量なモデルでありながらも、他の2.5系のモデルと同様に以下の機能も利用可能です。
- 100万トークンのコンテキストウィンドウ
- 思考時の利用トークン数制御
- Google 検索との連携
- コードの実行
- URL コンテキストへの対応
利用方法
コード内のモデル指定箇所で、gemini-2.5-flash-lite を指定することで、Flash-Lite 2.5 を利用することができます。
プレビュー版を利用している場合、gemini-2.5-flash-lite に切り替え可能です。
※ Flash-Lite のプレビュー版エイリアスは、8月25日に削除される予定です
実際に使ってみた
Google AI Studio または Vertex AI Studio から利用可能とのことなので、後者にて利用してみました!
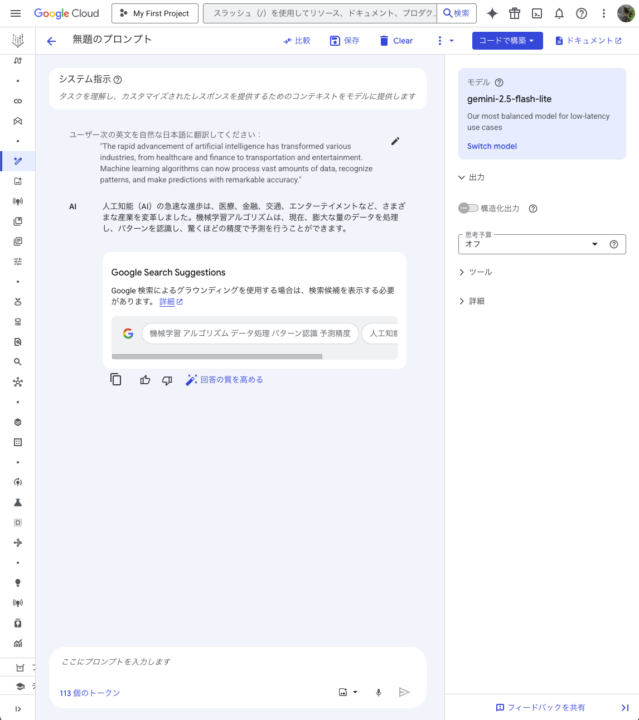
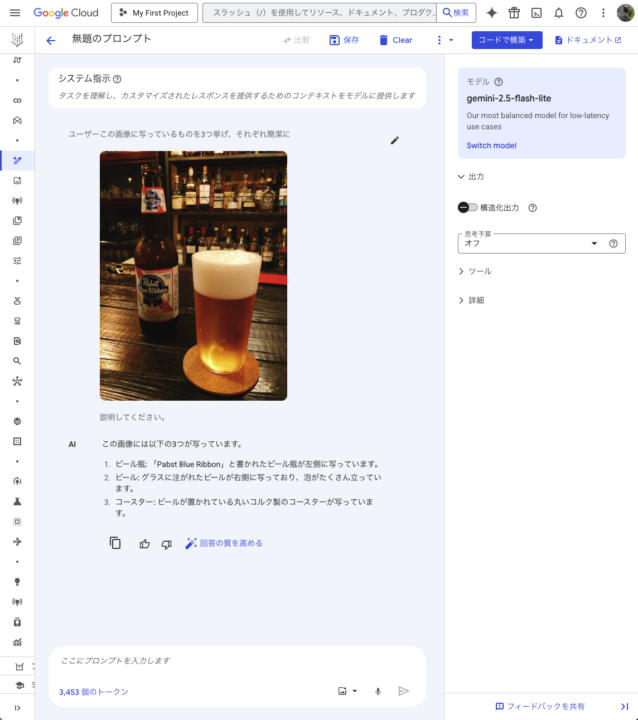
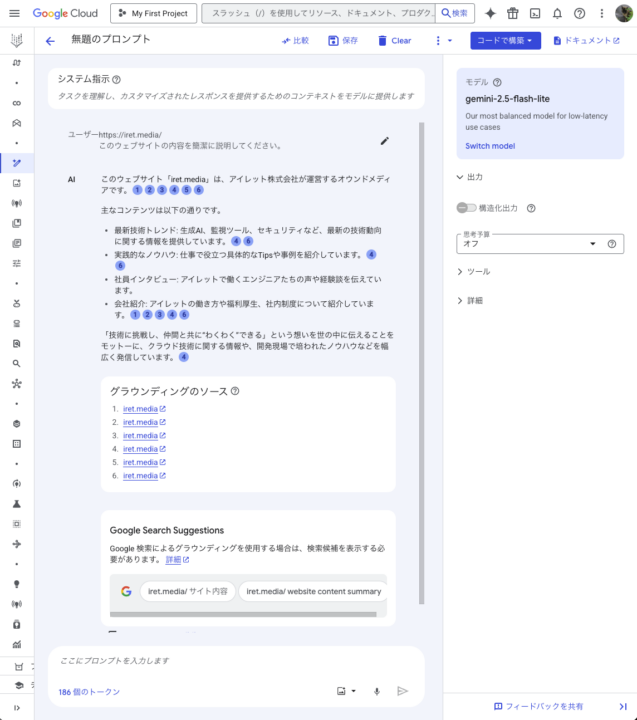
今回は翻訳タスク、画像生成(説明)タスク、URLの要約タスクの3つを行なってみましたが、どれも3秒以内に全てのレスポンスが返ってきました。
Thinking を OFF にした 2.5 Flash と比較しましたが、特に画像生成(説明)などはレスポンスまで5,6秒弱かかったため、高速化が目に見えて実感できました。
おわりに
Gemini 2.5 Flash-Lite の登場により、用途に応じた最適なモデルの選択肢がさらに広がりました!
特に今回実際に試してみて、レスポンス速度の違いは想像以上に体感できるレベルでした。
リアルタイム性が求められるアプリケーションや、大量のリクエストを処理する必要があるサービスでは、その真価を発揮してくれるものと思います。
皆さんのお手元でも簡単に試せますので、ぜひ体験してみてください!




