
はじめに
前回の記事では、RAGシステム全体の構成設計と各AWSサービスの役割について解説しました。今回は、いよいよ実装編に入ります。
具体的には、PDFドキュメントをベクトル化してOpenSearchに格納するインデックス処理を実装していきます。この処理は、RAGシステムの「知識ベース構築」に相当する重要な部分です。
今回の実装では、S3に格納されるナレッジをPDFファイルに限定しています。PDFはPyPDF2というPythonライブラリで比較的簡単にテキスト抽出ができるためです。
今後の課題として、Word文書(.docx)、Excel(.xlsx)、テキストファイル(.txt)など、他のファイル形式にも対応できるよう拡張していきたいと考えています。
実装する機能の全体像
今回実装するのは、以下の2つのLambda関数とサポートするLambda Layerです。
- create_index – OpenSearchのインデックスを初期化
- indexing_handler – S3のPDFからテキストを抽出してベクトル化
- Lambda Layer – PyPDF2とrequestsライブラリを提供
indexing_handlerの処理フローは以下の通りです。
[S3バケット]
↓
[Lambda: get_s3_objects] PDFファイル一覧を取得
↓
[Lambda: fetch_object_text] PyPDF2でテキスト抽出
↓
[Lambda: chunk_text] テキストをチャンクに分割
↓
[Bedrock: Titan Embeddings] ベクトル化
↓
[Lambda: index_chunk] OpenSearchに登録
↓
[OpenSearch] ベクトル検索可能な知識ベース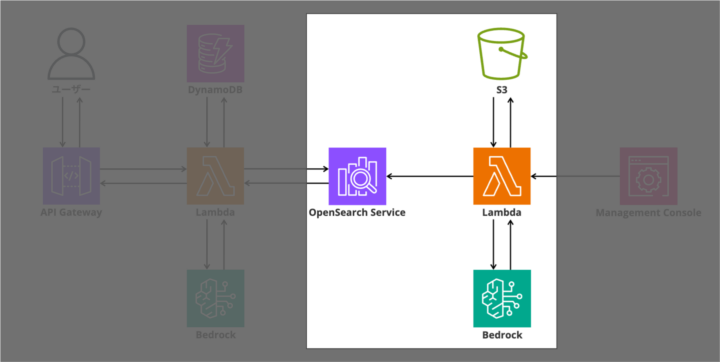
Step 1: OpenSearchインデックスの初期化 (create_index)
これから、OpenSearchのインデックスを初期化するcreate_indexというLambda関数を作成します。この関数は、CDKデプロイ時にCustom Resourceとして一度だけ実行され、ベクトル検索用のインデックスを自動で作成します。
import json
import os
import boto3
import requests
from requests_aws4auth import AWS4Auth
def lambda_handler(event, context):
region = os.environ["AWS_REGION"]
service = "es"
# AWS認証情報を取得
session = boto3.Session()
credentials = session.get_credentials().get_frozen_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
region,
service,
session_token=credentials.token,
)
# 環境変数から設定を取得
endpoint = os.environ["OPENSEARCH_ENDPOINT"]
index_name = os.environ["OPENSEARCH_INDEX"]
dimension = int(os.environ.get("VECTOR_DIMENSION", "1536"))
url = f"https://{endpoint}/{index_name}"
headers = {"Content-Type": "application/json"}
# インデックス定義
index_body = {
"settings": {
"index": {"knn": True} # k近傍法を有効化
},
"mappings": {
"properties": {
"content": {"type": "text"}, # テキスト内容
"vector": {
"type": "knn_vector",
"dimension": dimension, # Titan Embeddingsは1536次元
},
}
},
}
response = requests.put(url, auth=awsauth, headers=headers, data=json.dumps(index_body))
print("Index creation response:", response.status_code, response.text)
if not response.ok and response.status_code != 400: # 400 = already exists
raise Exception(f"Failed to create index: {response.text}")
return {
"Status": "SUCCESS",
"PhysicalResourceId": index_name,
}
ポイント
knn: True を設定することで、OpenSearchでベクトル検索を有効化します。dimension: 1536 は Amazon Titan Embeddings Text v1の次元数です。AWS4Authを使用することで、OpenSearchへの署名付きリクエストが可能になります。CDKのCustom ResourceからこのLambdaを呼び出すことで、自動初期化を実現しています。
Step 2: 初期化とインポート (indexing_handler)
次に、S3に保存されたPDFファイルを処理してOpenSearchにベクトル化されたドキュメントを格納するindexing_handlerというLambda関数を作成します。まずは、必要なライブラリのインポートと初期化処理から見ていきましょう。
import io
import json
import os
import boto3
import requests
from PyPDF2 import PdfReader
from requests_aws4auth import AWS4Auth
# AWSクライアントの初期化
s3 = boto3.client("s3")
bedrock = boto3.client("bedrock-runtime")
session = boto3.Session()
credentials = session.get_credentials().get_frozen_credentials()
region = os.environ["AWS_REGION"]
service = "es"
awsauth = AWS4Auth(
credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token
)
# 環境変数から設定を取得
S3_BUCKET = os.environ["S3_BUCKET"]
OPENSEARCH_ENDPOINT = os.environ["OPENSEARCH_ENDPOINT"]
OPENSEARCH_INDEX = os.environ.get("OPENSEARCH_INDEX", "documents")
TITAN_MODEL_ID = os.environ["BEDROCK_TITAN_MODEL_ID"]
ファイルの冒頭では、必要なライブラリをインポートし、AWSクライアントと認証情報を初期化しています。特に、AWS4Authの初期化はOpenSearchへのアクセスに必須です。環境変数から各種設定を取得することで、環境ごとに異なる値を柔軟に設定できます。
Step 3: Lambda関数のエントリーポイント (indexing_handler)
def lambda_handler(event, context):
"""Lambda関数のエントリーポイント"""
try:
objects = get_s3_objects(S3_BUCKET)
for obj in objects:
process_s3_object(obj)
except Exception as e:
print(f"Error in lambda_handler: {e}")
return {"status": "done"}
lambda_handlerは、S3バケット内のすべてのオブジェクトを取得し、1つずつ処理していきます。エラーが発生しても処理を継続し、最後にステータスを返します。
Step 4: S3オブジェクトの取得 (indexing_handler)
def get_s3_objects(bucket_name):
"""指定したバケット内のすべてのオブジェクトを取得"""
response = s3.list_objects_v2(Bucket=bucket_name)
return response.get("Contents", [])
この関数は、指定したS3バケット内のすべてのオブジェクトをリストアップします。list_objects_v2を使用することで、1000件を超えるオブジェクトにも対応できます。
Step 5: S3オブジェクトの処理 (indexing_handler)
def process_s3_object(obj):
"""S3オブジェクトを処理し、インデックスに追加"""
key = obj["Key"]
try:
text = fetch_object_text(S3_BUCKET, key)
index_text_chunks(text)
print(f"Indexed {key} successfully")
except Exception as e:
print(f"Error processing {key}: {e}")
各S3オブジェクトに対して、テキストを抽出し、チャンクに分割してインデックスに追加します。エラーが発生した場合もログに記録して次のファイルに進みます。
Step 6: PDFからテキストを抽出 (indexing_handler)
def fetch_object_text(bucket_name, key):
"""S3のPDFファイルからテキストを抽出"""
obj = s3.get_object(Bucket=bucket_name, Key=key)
body = obj["Body"].read()
pdf_reader = PdfReader(io.BytesIO(body))
text = ""
for page in pdf_reader.pages:
text += page.extract_text() or ""
return text
PyPDF2を使用してPDFの各ページからテキストを抽出します。S3から取得したバイナリデータをio.BytesIOでラップすることで、ファイルのようにPyPDF2で読み込めるようにしています。
extract_textがNoneを返す場合に備えて、or “”でフォールバックしています。
Step 7: テキストのチャンク分割処理 (indexing_handler)
def index_text_chunks(text):
"""テキストをチャンクに分割し、インデックスに追加"""
for chunk in chunk_text(text):
vector = get_embedding(chunk)
if not vector:
print(f"Embedding failed for chunk: {chunk[:50]}...")
continue
index_chunk(chunk, vector, OPENSEARCH_INDEX, OPENSEARCH_ENDPOINT)
抽出したテキストをチャンクに分割し、各チャンクをベクトル化してOpenSearchに登録します。ベクトル化に失敗した場合は、そのチャンクをスキップして次に進みます。
Step 8: テキストをチャンクに分割 (indexing_handler)
def chunk_text(text, chunk_size=500, overlap=100):
"""テキストをチャンクに分割"""
return for i in range(0, len(text), chunk_size - overlap)]
なぜチャンク分割が必要なのでしょうか。主な理由は以下の3つです。
- LLMのコンテキストウィンドウに収めるため
- より精密な検索を実現するため
- オーバーラップにより文脈の断絶を防ぐため
今回は、500文字のチャンクに100文字のオーバーラップを設定しています。chunk_size – overlapでステップを計算することで、前のチャンクの最後の100文字が次のチャンクの最初の100文字と重複します。
Step 9: Bedrockでベクトル化 (indexing_handler)
def get_embedding(text: str) -> list[float]:
"""テキストの埋め込みを取得"""
response = bedrock.invoke_model(
modelId=TITAN_MODEL_ID,
body=json.dumps({"inputText": text}),
contentType="application/json",
accept="application/json",
)
body_raw = response["body"].read()
print("Bedrock response raw:", body_raw)
body = json.loads(body_raw)
return body.get("embedding", [])
Amazon Titan Embeddings Text v1を使用して、テキストを1536次元のベクトルに変換します。このベクトルが、後の類似度検索の基準となります。
デバッグのために、Bedrockからの生のレスポンスをログに出力しています。これにより、問題が発生した際の原因特定が容易になります。
Step 10: OpenSearchに登録 (indexing_handler)
def index_chunk(chunk, vector, index_name, endpoint):
"""チャンクをインデックスに追加"""
doc = {"content": chunk, "vector": vector}
url = f"https://{endpoint}/{index_name}/_doc"
res = requests.post(url, auth=awsauth, json=doc, headers={"Content-Type": "application/json"})
print("Indexing response:", res.status_code, res.text)
res.raise_for_status()
テキストとベクトルのペアをOpenSearchに保存します。OpenSearchの_docエンドポイントにPOSTすることで、自動的にドキュメントIDが生成されます。
raise_for_statusを呼び出すことで、HTTPエラーが発生した場合に例外を発生させ、process_s3_object関数でキャッチされます。
全体の処理フロー (indexing_handler)
ここまでで実装した関数の呼び出し関係を整理すると、以下のようになります。
lambda_handler
└─ get_s3_objects # S3バケット内のファイル一覧を取得
└─ process_s3_object # 各ファイルを処理
└─ fetch_object_text # PDFからテキスト抽出
└─ index_text_chunks # チャンク分割とインデックス登録
└─ chunk_text # テキストをチャンクに分割
└─ get_embedding # ベクトル化
└─ index_chunk # OpenSearchに登録この一連の処理により、PDFドキュメントが検索可能な「知識ベース」に変換されます。
Step 11: Lambda Layerの準備
外部ライブラリをLambdaで使用するため、Lambda Layerを作成します。
必要なライブラリ
- PyPDF2: PDFからテキストを抽出
- requests: HTTPリクエスト
- requests-aws4auth: AWS署名付きリクエスト
Layerの作成方法
# {プロジェクトTOP}/lambda に移動
cd lambda
# PyPDF2レイヤー
mkdir -p python
pip install PyPDF2 -t python/
zip -r pypdf2-layer.zip python/
rm -rf python/
# requestsレイヤー
mkdir -p python
pip install requests requests-aws4auth -t python/
zip -r requests-layer.zip python/
rm -rf python/CDKでLayerをデプロイする際は、以下のように定義します。
# Lambda Layer(requests・requests-aws4auth)
requests_layer = _lambda.LayerVersion(
self,
"RequestsLayer",
code=_lambda.Code.from_asset("lambda/requests-layer.zip"),
compatible_runtimes=[_lambda.Runtime.PYTHON_3_11],
description="Layer with requests and requests-aws4auth",
)
# Lambda Layer(PyPDF2)
pypdf2_layer = _lambda.LayerVersion(
self,
"PyPDF2Layer",
code=_lambda.Code.from_asset("lambda/pypdf2-layer.zip"),
compatible_runtimes=[_lambda.Runtime.PYTHON_3_11],
description="Layer with PyPDF2",
)
ハマったポイントと対処法
インデックスが存在しないエラー
問題: indexing_handlerを実行すると、index_not_found_exceptionエラーが発生
原因: OpenSearchのインデックスを事前に作成せずにドキュメント登録を試みた
対処: create_index関数を先に実行してインデックスを初期化する。CDKでCustom Resourceを使用することで、デプロイ時に自動的にインデックスが作成され、この問題を回避できる
実装時、OpenSearchはインデックスを事前に作成しておく必要があることを知らず、いきなりドキュメント登録を試みたためこのエラーに遭遇しました。RAGシステムの実装では、必ず以下の順序で進めることが重要です。
- OpenSearchのインデックス初期化(create_index)
- ドキュメントの登録処理(indexing_handler)
- 検索処理(次回実装)
OpenSearchの認証エラー
問題: 403 Forbiddenエラーが発生
原因: IAMロールのアクセスポリシーが不足
対処: CDKでOpenSearchのアクセスポリシーを明示的に設定
# アクセスポリシー
access_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {"AWS": lambda_role.role_arn},
"Action": ["es:ESHttpPost", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpDelete"],
"Resource": f"arn:aws:es:{self.region}:{self.account}:domain/rag-search/*",
}
],
}
Bedrockのリージョンエラー
問題: Titan Embeddingsが利用できないリージョンがある
対処: ap-northeast-1(東京リージョン)では利用可能なことを確認
Lambda Layerのインポートエラー
問題: ModuleNotFoundError: No module named ‘PyPDF2’
原因: Layerのディレクトリ構造が誤っている
対処: python/ディレクトリ配下にライブラリをインストール
PDFからのテキスト抽出が空になる
問題: 一部のPDFでextract_textが空文字を返す
原因: スキャンされた画像PDFなど、テキスト情報が埋め込まれていないPDF
対処: OCR処理の追加を検討(Amazon Textractなどを使用)
まとめ
今回は、RAGシステムの「知識ベース構築」部分を実装しました。
実装した内容は以下の通りです。
- OpenSearchインデックスの初期化
- S3からPDFファイルの取得
- PyPDF2によるテキスト抽出
- テキストのチャンク分割(オーバーラップ付き)
- Bedrockを使った埋め込みベクトル生成
- OpenSearchへのドキュメント登録
- Lambda Layerの準備と設定
create_indexによるインデックス初期化、indexing_handler/main.pyの全8つの関数によるPDF処理パイプライン、そしてPyPDF2とrequestsのLambda Layerを実装し、PDFドキュメントを検索可能な知識ベースに変換する完全なシステムが完成しました。
次回の記事では、ユーザーの質問を受けて、ベクトル検索を行い、LLMで回答を生成する処理を実装していきます。いよいよRAGの核心部分です!

